基于隐马尔可夫模型的分词算法的设计与实现
2022-10-13林游龙
◆林游龙
(福州数据技术研究院有限公司 福建 350019)
1 研究背景
汉语的自动分词问题是计算机处理汉语时面临的基础性工作,是诸多应用系统不可或缺的重要环节[1-3]。基于规则的切分算法[4-5]又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串。常用方法:最小匹配算法,正向(逆向)最大匹配法,逐字匹配算法,神经网络法、联想回溯法,基于N-最短路径分词算法。目前机械式分词占主流地位的是正向最大匹配法和逆向最大匹配法。基于理解的分词方法[6-7]又称之为知识分词,知识分词是一种理想的分词方法。不管是基于理解的切分方法,还是基于统计的或基于规则的切分方法,每一种方法都有各自的优点和一定的局限性[8-9]。
目前基于统计的分词方法是研究的热点,主要包括,最大熵模型,条件随机场,隐马模型,最大熵隐马模型。为了弥补条件随机场与最大熵模型的缺点,出现了基于多层次混合模型,如最大熵隐马尔可夫模型,其原理是通过一种模型进行粗切分,然后用另一种模型进行细切分[10-12]。目前的基于隐马尔可夫模型的分词工具很少,复杂的代码结构限制了它的普及。本文针对隐马尔可夫模型的特点与中文分词相结合,设计并实现了基于隐马尔可夫模型的分词算法,总代码不超过70行,而且简单易理解,对以后基于此模型的词法分析研究有很大的参考价值。
2 传统的方法
2.1 背景
因为先切分后标注的方法虽然简单,效率较高,但是这种方法的词语切分与词语标注是相互独立的关系,而实际上词语与词性是密不可分的关系,一个词语有特定的若干个与之对应的词性。因此实现分词与词性标注同时进行的方法比单纯的使用分词方法的正确率要高。
又因为使用二元语法进行自动分词的主要问题是,词与词的转移概率矩阵非常庞大。自动分词的词表一般都在4万词以上,转移概率矩阵规模就有16亿以上。即使假定概率大于0的词对只占4%,也将有6400万个数据[2];训练所需的语料规模非常巨大,因此往往为了降低概率矩阵的规模,仅用一元语法来求词串的概率。使得分词的正确率受到了影响[1-2]。受到基于类的分词方法的启发,如果用词性来代替类,则以上方法可以看作有基于词性类的分词方法,由于自动分词的词性一般在80个左右,转移概率矩阵的规模就在6400个,假定概率大于0的词性对为占100%,6400个数据的规模所需的训练语料规模,计算复杂度等都非常的小[1-2]。这也就是隐马尔可夫模型的分词算法的思想[13]。
2.2 隐马尔可夫模型概述
如图1所示,一个随机过程的变量不是并不是相互独立的,每个随机变量的值依赖于这个序列前面的状态。随着时间的推移,该系统将从某一状态转移到另一个状态。该过程就称为马尔可夫模型。但这限制了模型的适应性。如果不知道模型所经过的状态序列,只知道状态的概率函数,也就是说,观察到的事件是状态的随机函数,因此,该模型是一个双重的随机过程。其中,模型的状态转换过程是不可观察的,即隐蔽的。如图1所示。一个HMM记为一个五元组(S,K,A,B,π),其中,S为状态的集合,K为输出符合的集合,π,A和B分别是初始状态的概率分布、状态转移概率和符号发射概率[14-16]。

图1 隐马尔可夫模型
2.3 背景隐马尔可夫模型分词理论
本文将基于词性的二元统计模型的分词与词性标注一体化模型视为隐马尔可夫模型。将词性视为隐马尔可夫模型中的状态,将分词前的候选词视为隐马尔可夫模型中的观察值。如图2所示:
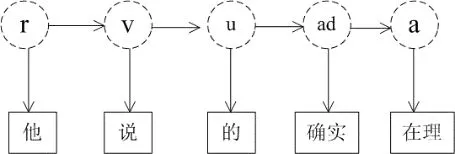
图2 中文分词隐马尔可夫模型
假设句子S是由单词串组成,W=w1w2…wc(c≥1),单词wi(1≤i≤n)的词性标注为ti,即句子S相应的词性标注符号序列可表达为T=t1t2…tn。那么,分词与词性标注的任务就是要在S所对应的各种切分和标注形式中,寻找T和W的联合概率P(W,T)为最优的词切分和标注组合。
根据隐马尔可夫的思想,即应用隐马尔可夫链来描述一个完整句子的词性变化,每种词性对应一种状态,状态的转移概率代表词性之间的搭配关系。这样,在生成一个句子时,系统不断地由一个状态转移到另外一个状态,每一个状态产生一个输出符号-单词,直至整个句子输出完毕[1-3]。
P(W,T)可以由HMM近似地表示为等式(1):

其中,P(W|T)可以称为生成模型,P(wi|ti)表示在整个标注语料中在词性ti的条件下,单词wi出现的概率;P(T)为基于词性的语言模型,采用二元语法,P(ti|ti-1)表示在前一个单词的词性是ti-1的情况下,当前词的词性是ti的概率。当i=1时,取P(ti|ti-1)=P(ti)。
因此,在分词过程中,只要列出所有可能的切分,用单词出现的概率与词性的连接概率,计算每种切分概率总和,概率指最大的一个即为输出结果[1-3]。
2.4 隐马尔可夫模型分词例子
假设有一中文句子”他说的确实在理”需要划分,如图3所示。词性如表1所示,这个句子有三种意思:

图3 中文分词例子
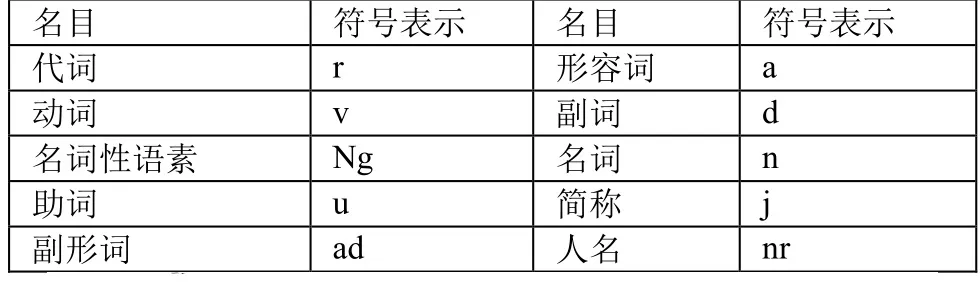
表1 词性的符号表示
1、他 说 的 确实 在理
2、他 说 的确 实在 理
3、他 说 的确 实 在理
2.5 隐马尔可夫模型分词算法的参数估计
为了获取P(wi|ti)及P(ti|ti-1),事先用大规模的已切分和标注了词性的汉语语料做训练,计算单词的频度信息,统计每个词的不同词性出现的次数C(wi,ti)及每种词性ti在文本中出现过的总次数C(ti),用最大似然估计算法计算得等式(2):

同理,统计训练文本中前后词性组合的频度C(ti-1,ti)及C(ti-1),用最大似然估计算法计算得等式(3),假设等式(4)成立,则得到等式(5),同时易知等式(6)成立:
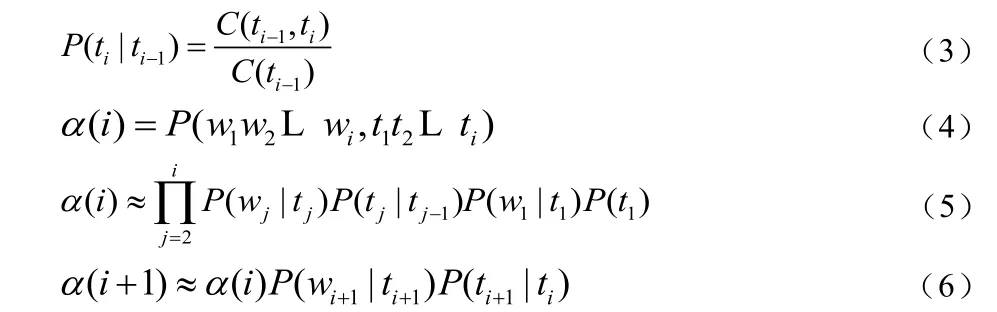
如果把P(ti+1|ti)看作词性的转移概率,则可以使用动态规划算法来求P(W,T)。因为如果穷尽所有可能的状态序列,那么设具有N个不同的状态,时间长度为T,那么有NT个可能的状态序列。相反如果每一状态能够记录前面所有输出符号的概率,即等式(6),那么时间复杂度变为O(N2T),这种方法即称为动态规划[1-3]。
3 系统设计
3.1 数据结构
如图4所示,(a)为候选单词的数据结构[3],本文使用候选字符串中的偏移整数量offset与length表示一个候选单词。tag表示词性,goodprev表示最佳前趋词,它也是一个candidate数据结构。fee表示概率,sumfee表示目前为到候选单词为止的概率的总和。(b)为字典设计,freq代表频率即训练集中出现的个数。

图4 候选单词结构与字典
3.2 函数设计
3.2.1 取候选单词
设此函数为gettmpwords(str)[3]:即从需要未分词的字符串str中找出候选单词。其中str是需要切分的汉语字符串,函数的返回值为候选单词列表,如图5所示:

图5 取候选单词函数
其中函数getdicfreq函数表示从字典中取相应的单词对应的频率。
3.2.2 取最佳前趋词
设此函数为getprev(i,list)[3]:填写第i个候选词的最佳前趋词的序号,并且计算到第i个候选词为止,路径上的最小累计费用。其中i是候选单词列表list中的序号,list为候选单词列表。如图6所示。

图6 取最佳前趋词函数
3.2.3 分词函数设计
设此函数为str_fengchi(str)[3]:将汉语字符串str分词,其中str是需要切分的汉语字符串,函数返回值为已切分好字符串str的字符串,如图7所示。

图7 分词函数
4 实验验证
训练数据:北京大学开发的免费版PFR人民日报切分标注语料库(1998年1月数据)[17]。
测试数据:第二届国际中文分词评测(SigHan 2005)的语料库,msr_test,pku_test[18]。由于其他的基于隐马尔可夫模型的分词工具如TnT,Citar等需要标记训练集,而且标记的方法不是以词性为标准如词头、词尾、词中等,而本文所使用的隐马尔可夫分词工具实现的是基于标准词性集的标记方法,因此不能与TnT以及Citar做比较。得到的实验结果如表2所示。
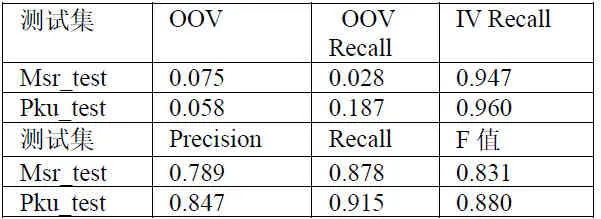
表2 实验结果
根据实验结果可知,本文设计的隐马尔可夫模型的分词算法达到了实用的水平。
5 结束语
本文设计的隐马尔可夫模型算法不仅用于分词领域,还可以用到其他词法分析领域,如未登录词发现,人名、地名识别,词性标注等其他可用隐马尔可夫模型的地方。今后需改进模型参数的存储方式,使用双数组Trie等存储模型参数以提高程序的处理速度。另外研究基于三语法模型的分词与词性标注一体化方法,解决搜索空间问题。
