基于GRU和Attention的微博情感分析研究
2022-10-11王英明
王英明, 谢 进
(1. 马鞍山学院 腾讯云大数据学院,安徽 马鞍山 243002;2. 合肥学院 人工智能与大数据学院,安徽 合肥 230601)
随着移动互联网技术的快速发展与广泛应用,以微博、微信、抖音为代表的新媒体平台得到快速发展。微博作为中国最大的社交媒体平台之一,截至2021年四季度末,微博月活跃用户达5.73亿,日活跃用户达2.49亿。伴随着微博用户的日益增长,网上的各种微博评论信息不断涌现,这些评论信息中蕴含着丰富的情感信息,分析这些情感信息的特征和极性对社会舆情分析以及相关政策制定都有很重要的作用。
分析文本的情感特征和极性主要使用深度学习的方法。目前,很多学者对一些网络模型进行组合或者在现有网络模型的基础上进行改进,都取得了较好的效果。结合双向长短时记忆网络(Bi-directional Long Short-Term Memory Network,Bi-LSTM)和自注意力(Self-attention)机制提取文本的深层特征,能够更精确地捕捉文本情感倾向,提高了模型分析的准确率[1-2]。双向门控循环单元(Bi-directional Gated Recurrent Unit,Bi-GRU)和注意力(Attention)机制融合的模型,提高了情感分析的性能[3-4]。将多头注意力(Multi-Head Attention)机制融入文本情感分析模型,模型先利用LSTM等方法进行初步特征提取,再结合多头注意力机制从不同的维度和表示子空间里提取相关的信息[5-7]。尼格拉木·买斯木江等[8]提出基于BERT(Bidirectional Encoder Representation from Transformers)和Bi-GRU模型对用户评论进行情感倾向性分类,提高了用户情感倾向性分析的准确率。王根生等[9]提出基于词嵌入特征、词情感特征、词权重特征融合的GRU神经网络文本情感分类模型,该模型具有更好的泛化能力,在较少训练数据量时也能获得较好的分类效果。
1 基于GRU和Attention的模型
为提高模型情感分析的准确率和训练效率,本研究将Bi-GRU模型和Attention机制结合起来,设计一个新的模型,模型结构如图1所示。
首先,利用jieba库对文本进行分词,通过嵌入层对分词结果进行词向量化并加入位置信息;然后,将分词向量和位置向量传入Bi-GRU层提取文本特征,引入Attention机制关注文本序列中的重要特征;最后,经过池化层、Dropout层、全连接层构建微博文本情感分类模型。
1.1 词向量输入层
在文本进入网络分类前,一般需要将其转换为词向量。本研究先利用keras.layers提供的Embedding进行词嵌入。此时一次性传入所有词向量会丢失每个词的位置信息,所以除词向量外,输入信息中还需加上一个表示每个词位置的信息,本研究在词嵌入后增加了一个位置嵌入层,将位置信息添加进来。位置信息的计算公式如下:

(1)

(2)
其中,pos表示当前词在句子中的位置;dmodel为词向量的长度,本研究中为128;i表示对应的词向量的维度,PE(pos,2i)表示偶数维度的计算公式,PE(pos,2i+1)表示奇数维度的计算公式;sin和cos为三角函数,通过在不同维度上使用不同周期的函数来控制词的位置编码,使每个词的位置编码重复的概率大大降低。词向量和位置向量相加后传入下一层。
1.2 Bi-GRU层
GRU是一种特殊类型的循环神经网络(Recurrent Neural Network,RNN),相较于LSTM,消耗资源较少,但能获得几乎相同的效果。GRU更新门有助于捕捉时间序列里短期的依赖关系,重置门有助于捕捉时间序列里长期的依赖关系。GRU模型存储单元结构如图2所示。

图2 GRU存储单元结构图Fig.2 GRU storage unit structure diagram
首先,t时刻的重置门rt和更新门zt的输入均为当前时刻的输入xt和上一时刻的隐藏状态ht-1,输出由激活函数为sigmod函数的全连接计算得出,计算公式如下:
zt=σg(Wzxt+Uzht-1+bz)
(3)
rt=σg(Wrxt+Urht-1+br)
(4)
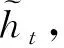
(5)
(6)
其中,Wz、Wr、Wh、Uz、Ur、Uh是权重参数,bz、br是偏置参数,由训练得到。
为充分利用评论信息中的过去时刻和将来时刻的上下文信息,本研究采用双向的GRU算法,即Bi-GRU。模型结构如图3所示。

图3 Bi-GRU结构图Fig.3 Bi-GRU structure diagram
1.3 多头注意力机制层
为关注评论信息文本序列中的关键部分,使用多头注意力机制,捕获文本间的权重大小,模型结构如图4所示。

图4 多头注意力机制模型结构图Fig.4 Structure diagram of multi head attention mechanism model
多头注意力机制的计算公式如下:
(7)
(8)
(9)
(10)
M=concat(M1,…,Mi,…,Mh)WO
(11)
其中,X为输入词向量,Q′、K′、V′为输入向量X乘以3个不同的权值矩阵WQ、WK、WV得出的,Mi为第i头注意力,最后通过拼接多头注意力乘以权值矩阵WO计算产生多头注意力的输出。
经过对比,多头注意力层选用的注意力头数为8,每头的大小为16。
2 实验与结果分析
2.1 准备数据集
本研究采用的微博评论数据集是weibo_senti_100k数据集,一共有119 988条带情感标注的新浪微博评论,其中正负向评论均为59 994条,是非常平衡的一个数据集。
先提取关键词,生成一个词云图(图5),观察该数据集的热门词的分布可知,本研究采用的数据集没有明显的领域偏向,训练生成的模型可用于一般文本的情感预测。

图5 热门关键词词云图Fig.5 Word cloud of popular keywords
2.2 实验环境
实验环境是在Windows 10操作系统下进行的,设备运行内存32G,CPU为Intel(R) Core(TM) i7-11700 @ 2.50 GHz,开发工具为PyCharm 2021.3.3,开发过程中使用了TensorFlow、Keras等相关组件,具体如表1所示。

表1 实验相关组件Table 1 Related components of the experiment
2.3 实验模型参数设置
实验参数对于训练结果有很大影响,本研究通过固定参数的方法对模型参数进行调整,最终词嵌入层大小为200,批尺寸(batch-size)为128,epoch为8,丢弃率(Dropout)为0.5,L2正则值为0.2,隐藏节点数为128(表2)。
2.4 评价指标
使用准确率(Accuracy)、精准率(Precision)、召回率(Recall)、F1值(F1-Measure)以及运行时间对模型进行评价。
准确率是指分类正确的样本数占总样本的比例;精准率是指该模型预测的正向情感数据集中正向情感的比例;召回率体现该模型对正向情感数据集的识别能力;F1值为精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率越接近F1值越大,说明该模型越稳健。计算公式如下:
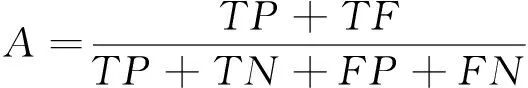
(12)
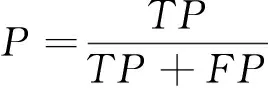
(13)

(14)
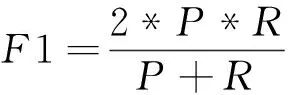
(15)
2.5 实验对比分析
在微博评论文本情感分析中将多头Attention机制融合在Bi-GRU中,在LSTM、GRU、Bi-LSTM、Bi-GRU、Bi-GRU+M-Attention、Bi-LSTM+M-Attention模型上对数据集中的微博评论进行实验,结果如表3所示。

表3 实验结果Table 3 Experimental result
由表3可知,几种模型在准确率、精准率、召回率、F1值方面差距不大,说明当数据集较大时,GRU模型、LSTM模型的功能接近;添加了Attention层的模型要优于未添加Attention层的模型。
虽然Bi-LSTM+M-Attention模型的准确率较高,但其F1值相对低一些,且模型的训练时间明显长于其他模型,综合来看,Bi-GRU+M-Attention模型的效果更好。
3 结论
本研究提出一种新的基于Multi-Head Attention机制和Bi-GRU的情感分类模型。首先利用词嵌入层和位置嵌入层,从文本信息中获取词向量作为特征提取和模型输入,随后在Bi-GRU模型中融入注意力机制组成新的网络模型,从而更好地提取文本特征、分析情感极性,最后使用softmax分类器输出分类结果,能够获得较好的分类效果。结果表明,注意力机制的引入让模型更有效地捕获数据中关键词的重要性,提高模型的情感分析性能。
