基于深度阴影特征增强的任意至任意重光照
2022-10-11胡钟昀NsampiNtumbaElie王庆
胡钟昀 Nsampi Ntumba Elie 王庆
(西北工业大学计算机学院,陕西西安 710072)
1 引言
任意至任意重光照(Any-to-Any Relighting)是指给定源图像和引导图像,利用隐含在引导图像中的光照对源图像进行重新照明[1-2]。其中,任意至任意是指源图像和引导图像中的光照都是任意的,即能够对任意光照下的源图像进行任意光照的重新照明。与传统重光照[3-5]不同的是,任意至任意重光照中的目标光照是通过引导图像间接给出,而非直接给出。这将极大降低图像编辑[6-7]的使用门槛,普通用户无需专业的光照知识,通过选定合适的引导图像即可完成源图像的重新照明。
基于逆向绘制的重光照方法[8-10]明确地恢复场景的光照、几何和材质属性,然后给定新的光照,重新渲染以实现重光照。然而,这是一个不适定问题,不同物理属性的组合可能产生相同的图像[11]。相比之下,基于学习的方法[4,12-13]没有明确的逆向绘制步骤来重新照明。相反,他们训练单个重光照网络,从一个或多个输入图像生成重光照图像。特别是,Sun 等人[12]和Zhou 等人[13]提出直接从隐式神经表征重新照明单张输入图像,而不需要显式地恢复本征属性。然而,由于光源假设不同,且只面向单个物体(肖像或人体),这些方法并不能直接应用于任意至任意重光照。
最近,研究人员提出了一些基于学习的任意至任意重光照方法[14-16]。但是这些方法由于采用端对端的学习方式,导致阴影特征与色温特征高度耦合,进一步影响了阴影生成的准确性。因此,本文从真实感渲染中的关键要素——阴影入手,设计额外的阴影生成任务,学习深度阴影特征,以生成更加准确的阴影。同时,为了有效利用学习到的深度阴影特征,我们引入基于注意力机制的特征融合模块,实现深度阴影特征与重光照深度特征的自适应融合。另外,我们实验性地发现,利用多项式核函数把源图像映射到高维特征后,再作为网络输入,能进一步提升性能。最终,本文提出了一种基于深度阴影特征增强的任意至任意重光照方法。
2 相关工作
2.1 基于图像的重光照
基于图像的重光照方法通过对光传输函数进行密集采样来重新照明物体,而无需明确估计物体的物理属性。Debevec 等人[3]构建了第一个光照球(Light Stage)系统,通过采集数千张不同光源下的图像以实现物体的重新照明。后续大量研究[17-19]主要聚焦于光传输函数的相干性以降低采样数量,从而实现同等质量的重光照。然而,这些方法仍然需要数百张图像,并且整个采集过程非常耗时。最近,随着深度学习的突破性进展,Xu 等人[4]利用深度神经网络学习跨场景光传输函数中的相干性,仅用五张采样图像实现了物体的重光照。Meka 等人[5]提出使用深度神经网络直接从两张球面梯度图像重建光传输函数的方法。但是,这类基于图像的重光照方法往往需要专门设计的采集系统以模拟所需的光照,这大大限制了其应用范围。因此,受益于深度学习强大的非线性拟合能力,Sun 等人[12]和Zhou 等人[13]几乎同时提出了一种基于编码-解码结构的深度神经网络,能够实现对单张非受控光源图像的重新照明。尽管如此,这些方法通常只关注特定类别的物体(如肖像或人体),尚未考虑场景级的重光照。更重要的是,它们通常使用环境贴图(Environment map)或球面谐波(Spherical harmonics)表示入射光,一般只适用于无穷远光源情形。对比之下,本文瞄准面向点光源的场景重光照问题,需重点考虑近场光照效果,尤其是复杂的阴影。因此,本文通过增强深度阴影特征来进一步提高近场光照效果。
2.2 基于逆向绘制的重光照
逆向绘制(Inverse rendering)是根据观测的单张或多张图像来估计场景的物理属性(如几何形状、反射率和光照)。一旦估计出反射率和光照,并辅以一个额外的物理渲染管线,任意至任意重光照都可以被视为逆向绘制的直接应用。传统的逆向绘制方法[20-25]通过大量的先验知识来联合优化物理属性,以获得最能解释观测图像的一组值。然而,直接优化所有物理属性往往是一个严重欠约束的问题,这会导致严重的伪影。在过去的数年里,研究人员专注于数据驱动的逆向绘制方法[26-28],从而避免手工设计先验的局限。虽然这些方法估计场景物理属性的准确率大大提高,但是仍然受限于其对应的物理渲染方程,图像真实感需进一步提升。
相比之下,其他一些基于学习的重光照方法[8-10,29-31]已将神经渲染(Neural rendering)引入到重光照中。在逆向绘制网络[27]的基础上,Yu 等人[10]进一步提出了一种针对室外场景重光照的神经渲染框架。Bi 等人[31]利用多张非结构化的手机闪光图像,训练一个带有场景外观表征的神经渲染框架,可实现重光照。Wang等人[29]和Nestmeyer等人[30]提出使用神经网络从若干估计的本征量直接渲染新图像,可用于单张人脸图像的重光照。Sang 等人[9]提出了一种级联神经网络来同时进行逆向绘制和渲染,从而实现了单幅图像的重新照明。然而,这些方法要么需要精确的反射率真值,要么需要多视图数据进行监督训练,这些在实践中很难获得。此外,它们往往关注单个物体,而不是复杂的场景。相比之下,本文提出的方法不但面向场景级的重光照问题,而且不需要显式估计反射率。
2.3 任意至任意重光照
任意至任意重光照首先由Helou 等人[1-2]提出,其目的是通过隐含在引导图像里的光照设置来对源图像进行重新照明。Hu 等人[14]提出了一种带有自注意力机制的编码-解码网络,以改善全局光照效果。最近,Hu 等人[32]又将物理先验知识引入神经渲染框架,以保留局部阴影细节并进一步抑制任务混叠效应。Yang 等人[15]将任意至任意重光照视为图像到图像的转换,通过使用单流网络将源图像和引导图像直接映射到重光照图像。Yazdani 等人[16]提出通过学习一个权重图,将基于本征分解的重光照结果与直接映射的重光照结果进行融合,以提升性能。与上述方法不同,本文从真实感渲染中的关键要素——阴影入手,通过引入额外的阴影生成任务,进一步增强深度阴影特征,从而改善视觉效果。
3 阴影标注
目前,现有的任意至任意重光照数据集[33]尚未包含阴影图像。为了获得训练阴影生成任务时所需的阴影真值,我们设计了一种简单的阴影标注算法对该数据集进行阴影标注。
首先,我们将数据集中的所有彩色图像转换为灰度图像,把转换后的灰度图像记为t。对于t中的像素x,其对应的二值阴影图像s(x)生成如下:

其中,T是决定阴影的阈值。因为不同图像中的场景内容和光照有时差异很大,所以T往往是随着图像的变化而发生变化。因此,对于每张图像,我们设置不同大小的T,得到多张阴影图像,再依据主观判断选取一张最合理的阴影图像作为最终的阴影真值图像。如图1 所示,我们展示了不同T下的阴影标注结果。一般而言,T的取值范围为[10-25]。

图1 不同T下的阴影标注结果Fig.1 Shadow labeling results under different T
4 方法
本节中,我们首先概要介绍提出的方法,接着给出具体的网络结构实现,最后说明损失函数和模型训练细节。
4.1 方法总览
给定输入图像I及其对应光照L,我们将重光照建模为:

其中Zi和Zl是图像的隐式表征,分别对应着图像的本质表征和光照表征。φ1和ψ1分别是输入图像I的重光照编码器和重光照解码器。φ2和ψ2分别是Zl的光照编码器和光照解码器。特别地,基于上述公式,任意至任意重光照可以按照图2 解决。具体而言,将源图像IS和引导图像IG同时输入到重光照编码器φ1,分别得到对应的隐式表征,即和。将输入到光照编码器φ2和光照解码器ψ2,进一步得到ψ1的光照表征输入。联合和,利用重光照解码器ψ1将其解码为重光照图像。
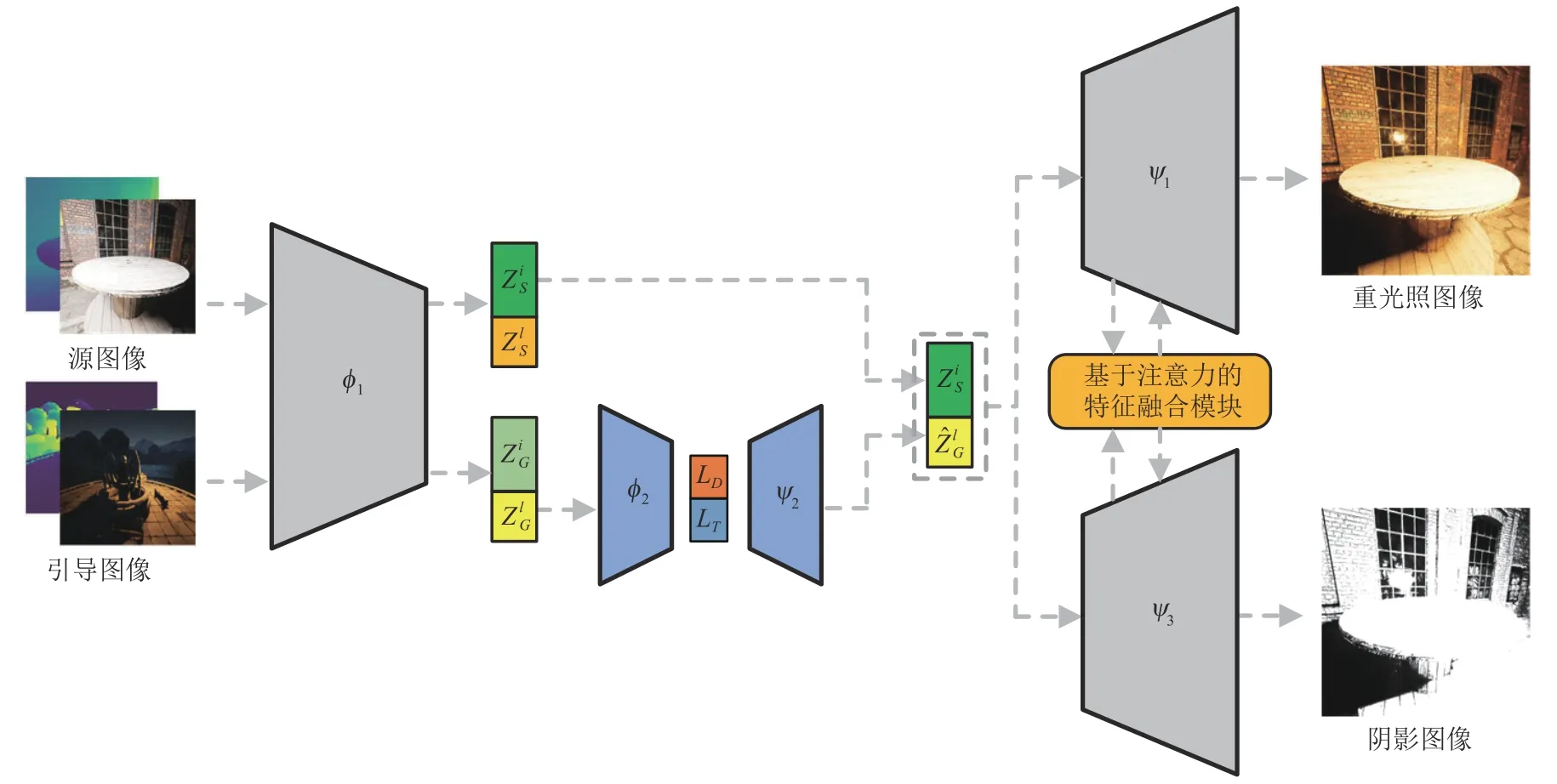
图2 方法原理图Fig.2 Schematic diagram of the method
阴影特征增强:为了进一步增强阴影的视觉效果,我们对重光照解码器ψ1中的重光照特征FR进行阴影特征增强。为此,我们引入了一个额外的阴影解码器ψ3,从隐式表征生成出对应的阴影图像。同时,在阴影生成任务的驱动下,ψ3也将学习丰富的阴影特征FS。进一步,利用可学习的权重{wR,},自适应融合FR和FS,得到增强后的重光照特征,如下公式所示:
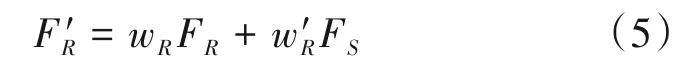
同理,利用可学习的权重{wS,},也可得到增强后的阴影特征。最终,FR和FS互为补充,相互增强。具体细节可见4.2.3小节。
在本文中,我们将所有的编码器{φ1,φ2}和解码器{ψ1,ψ2,ψ3}都建模为深度前馈神经网络,具体的网络结构见4.2小节。
4.2 网络结构
如图3 所示,我们提出的任意至任意重光照网络由数个编解码器{φ1,φ2,ψ1,ψ2,ψ3}组成。其中,{φ1,ψ1,ψ3}遵循U 形网络结构的设计,{φ2,ψ2}则由数个全连接层和激活层组成。
4.2.1 重光照编解码器
对于重光照编解码器{φ1,ψ1}而言,φ1包括一个输入预处理模块和四个下采样模块。其中,输入预处理模块由一个卷积层组成,每个下采样模块则由一个下采样层(即最大池化)和一个卷积模块组成。卷积模块主要由卷积层、组规范层和激活层组成,并包括一个残差连接,具体细节可见图3中的卷积模块。相应地,ψ1包括一个输出模块和四个上采样模块。其中,输出模块由一个卷积层构成,第一个上采样模块仅包含一个上采样层(即缩放卷积),后三个上采样模块皆由一个卷积模块和一个上采样层组成。对于任意给定的图像I,我们将其输入重光照编码器φ1,输出一组特征图,即为其对应的隐式表征{Zi,Zl}。在具体实现中,我们取前256 维特征图作为Zl,剩下的512维特征图作为Zi。

图3 网络结构Fig.3 Network structure
核函数映射:对于输入图像I的三个RGB 通道图像{IR,IG,IB},利用三阶多项式核函数K将其映射到高维特征Fp:
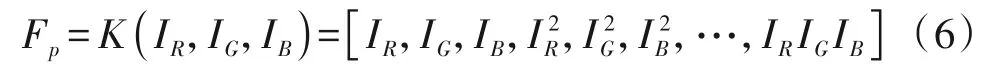
最终,联合高维特征Fp和深度图像作为重光照编码器φ1的输入,进一步提高输入的特征多样性。
4.2.2 光照编解码器
为了确保Zl光照可感知,我们需要利用光照编码器φ2将Zl编码为实际光照L,再通过光照解码器ψ2解码为。光照编码器φ2由两个全连接层组成,以预测光照L。其中,第一个全连层后接一个激活层。考虑到现有的任意至任意重光照数据集[33]包含光源方向真值LD和光源色温真值LT,故本文中的φ2由两个相同的全连接网络构成,分别用来预测光源方向和光源色温。光照解码器ψ2由两个全连接层组成,每个全连接层都后接一个激活层。注意,光照解码器ψ2仅由一个全连接网络构成,输入是,输出是。最后,本文采用One-Hot编码来分别表征LD和LT。
4.2.3 阴影解码器
阴影解码器ψ3的输入与重光照解码器ψ2的输入一样,都是。另外,阴影解码器ψ3的网络结构也和重光照解码器ψ2保持一样。不同的是,阴影解码器ψ3需从隐式表征中恢复阴影图像。在阴影生成任务的驱动下,阴影解码器ψ3将从隐式表征中学习丰富的多尺度阴影特征FS。为此,我们将利用学习到的深度阴影特征FS进一步增强重光照特征FR。
基于注意力机制的特征融合模块:如图3所示,我们利用可学习的权重需对不同空间尺度上的重光照特征FR和阴影特征FS进行自适应融合:

4.3 损失函数与训练细节
本文中,考虑到现有重光照数据集的特性,我们分别将重光照与光照估计视为回归任务和分类任务。对于光照估计损失函数ℓc,我们使用交叉熵损失函数H来训练光照估计相关的网络:

其中,LT和LD分别是光源方向真值和光源色温真值。对于重光照,均方误差损失函数作为图像的重建损失函数监督网络的训练。受启发于[34],我们也采用基于SSIM的损失函数来训练网络。最终,重光照的损失函数ℓr定义如下:

其中,在我们的实验中,λ1和λ2都设置为1。本文中除了重光照与光照估计任务之外,还额外引入了一个阴影生成任务。因此,对于阴影生成损失函数ℓs,我们使用基于平均绝对误差的损失函数来训练阴影解码器:

其中,S是阴影图像真值。最终,总的损失函数ℓtotal定义为上述三个子任务损失函数的和:
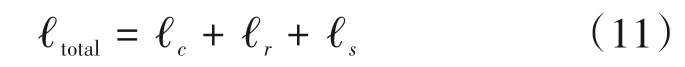
我们使用Adam 优化器[35]来更新整个网络的参数。其中,学习率设置为1e-5,β=(0.9,0.999)。整个网络参数的初始化采用Kaiming 初始化[36]。我们在Pytorch 框架下实现整个网络。实验是在基于Titan RTX的图形处理服务器上运行。
5 实验
5.1 数据集与评价指标
VIDIT 数据集[33]:由Helou 等人构建,分别在AIM 2020[1]和NTIRE 2021[2]挑战赛上用于场景重光照(包括任意至任意重光照)和光照估计等赛道上的性能评价。该数据集一共包括390 个场景,其中300个场景用于训练集,45个场景用于验证集,剩下的45 个场景用于测试集。每个场景预定义8 个光照方向(北,东北,东,东南,南,西南,西,西北)和5个色温(2500 K,3500 K,4500 K,5500 K,6500 K),这导致每个场景将有40个不同的光照设置。因此,整个数据集一共有15600张图像。每张图像的分辨率是1024*1024。另外,AIM 2020 中的每个场景仅包括RGB 图像,而NTIRE 2021 中则进一步提供了额外的深度图像。注意,测试集只应用于挑战赛,为主办方私有,而训练集和验证集是公开的,用于学术评估。
评价指标:任意至任意重光照的性能评估除了常见的PSNR、SSIM 和LPIPS[37]等评价指标外,Helou等人[1]还专门为其定义了一个MPS(Mean Perceptual Score)指标:
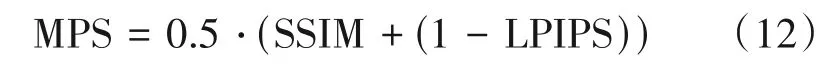
不难看出,MPS 是基于SSIM 和LPIPS 的综合评价指标,被Helou 等人作为重光照赛道的排名指标。因为对于重光照这类任务,SSIM 和LPIPS 相较于PSNR 指标更接近于人的主观评价。另外,为了验证本文光照估计模块的有效性,我们采用了Helou等人[1]所提的基于预测准确率的光照估计评价指标TotalLoss,其定义如下:
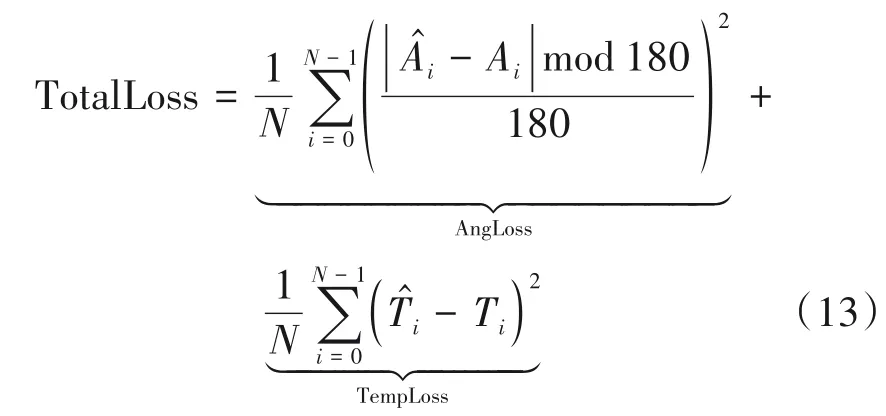
其中,AngLoss 和TempLoss 分别是光源方向估计和光源色温估计的评价指标。
5.2 比较实验
在本文的比较实验中,我们除了比较现有的任意至任意重光照方法(SA-AE[14]和AMIDR-Net[16]),还比较了面向人脸的重光照方法DPR[13]。但是由于DPR 采用了球谐光照表征,与本文的光源假设不同,故我们将球谐光照替换为本文所用的光照表征,其他模型配置保持不变。我们按照作者提供的训练超参数将DPR 在NTIRE 2021 任意至任意重光照训练集上重新训练,当损失函数收敛时,我们报告了DPR在验证集上的结果。
5.2.1 任意至任意重光照性能比较
在NTIRE 2021任意至任意重光照验证集上,我们与先前的工作进行了比较。NTIRE 2021 任意至任意重光照验证集一共包括90 个源图像和引导图像对。表1中展示了不同方法在该验证集上的定量对比。可以看出,我们的方法在MPS 上取得了最佳的结果,比AMIDR-Net 的方法提高了0.013。AMIDR-Net 取得了最高的PSNR,这主要是因为它利用了集成技术,将多个模型组合在一起,但同时也会带来模糊的副作用。在图4 中,我们展示了定性结果。就重光照中的色温改变而言,以图4 中的第二列图像为例,引导图像中的色温偏低,相比较于其他方法,我们方法的结果(尤其是方框部分)恢复了更低的色温,与真值更接近。就重光照中的光源方向改变而言,以图4中第三列图像为例,由于引导图像中的光源方向来自于图像右下角,我们方法不仅去除了图中方框处的阴影,而且在石头左侧(即方框左侧的石头)生成了丰富的阴影。AMIDRNet 没有去除方框处的阴影,而其他方法则在石头左侧生成了有限的阴影。

图4 不同方法在NTIRE 2021任意至任意验证集上的定性比较Fig.4 Qualitative comparison of different methods on the NTIRE 2021 Any-to-any Relighting validation set
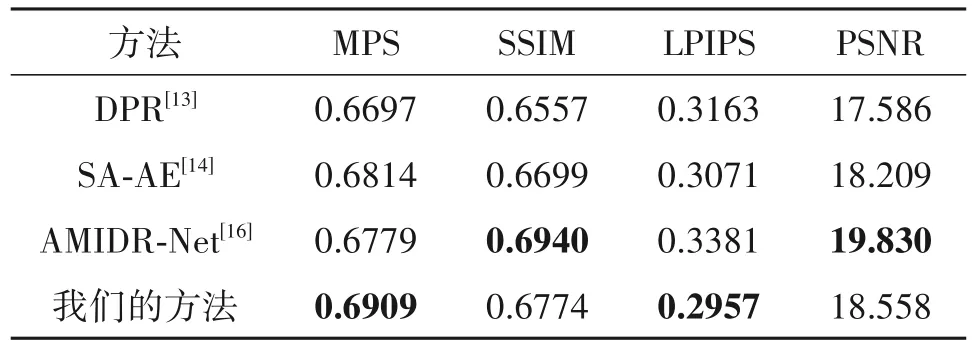
表1 不同方法在NTIRE 2021任意至任意验证集上的定量比较Tab.1 Quantitative comparison of different methods on the NTIRE 2021 Any-to-any Relighting validation set
另外,图5 展示了同一幅源图像在不同引导图像下的重光照结果。从图中可以看出,源图像中的光源方向为图像的右方,而引导图像中的光源方向依次为图像右上方,正下方以及左上方。相应地,我们的方法在重光照结果1 和重光照结果3 中,分别在石头的左下方(即红色方框处)和右下方(即蓝色方框处)生成了合理的阴影。而在重光照结果2中,我们的方法则去除了石头左处(即黄色方框处)的阴影。同时,我们也注意到,该区域由于阴影的消除而出现了模糊,如何填充阴影消除区域的纹理细节仍是未来值得进一步研究的问题。最后,对于重光照中的色温迁移而言,源图像的色温为5500 K,引导图像1 和2 的色温为2500 K,引导图像3 的色温为3500 K。从图5 中的重光照结果可以看出,我们的方法准确恢复了相应的色温。

图5 同一幅源图像在不同引导图像下的重光照结果Fig.5 Relighting results of the same source image under different guide images
5.2.2 光照估计性能比较
在AIM 2020光照估计验证集上,我们比较了不同方法中光照估计的性能。如表2 所示,我们方法的TotalLoss 为0.0957,比SA-AE 的降低了0.06 左右。比较所有方法的AngLoss 和TempLoss,不难发现,我们的方法在AngLoss 取得了大幅提升。实际上,阴影的生成依赖于光源的方向。这意味着额外的阴影生成任务有助于光源方向估计准确率的提升。

表2 不同方法在AIM 2020光照估计验证集上的定量比较Tab.2 Quantitative comparison of different methods on the AIM 2020 Lighting Estimation validation set
5.2.3 模型参数量与推理时间比较
表3 报告了不同方法的模型参数量与推理时间。注意,所有方法都是在NTIRE 2021 任意至任意验证集上使用单个RTX Titan GPU 进行测试的。我们报告了不同方法下单张1024*1024图像的平均处理时间。尽管具有最少参数量的DPR 取得了最短的推理时间(0.886 s),但是它只能处理人脸重光照,无法直接扩展到场景重光照上。AMIDR-Net 的推理时间最高,为1.383 s,这主要是由于它集成了多个模型。对比之下,虽然我们的方法推理时间比SA-AE 低了0.22 s,但是视觉效果上却更好,有着更低的MPS。
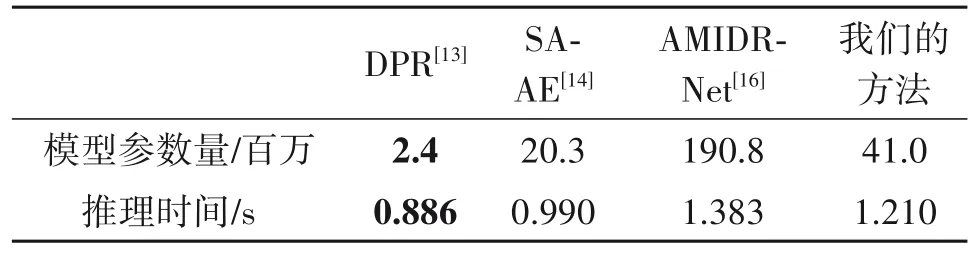
表3 模型参数量与推理时间的对比Tab.3 Comparison in terms of model parameters count and inference time
5.3 消融实验
为了验证各个模块的有效性,我们在NTIRE 2021 任意至任意重光照验证集上报告了不同模型配置下的结果。注意,因为NTIRE 2021 任意至任意重光照训练集中的图像分辨率为1024*1024,一次完整训练的时间成本很高。为了加快网络的训练速度,我们将训练集和验证集中的图像都缩放到256*256。表4 中报告了我们的消融实验结果。其中,基线方法(即配置1)仅由重光照编解码器{φ1,ψ1}和光照编解码器{φ2,ψ2}组成,并对重光照图像只采用基本的均方误差损失函数,其MPS 结果最差,仅为0.5519。在配置1 上添加基于SSIM的损失函数(即配置2),则将基线方法的SSIM 值提高了近0.171。在配置2 的基础上进一步加入多项式特征(即配置3),则将MPS 提高了0.0052。从图6 中的绿色方框部分可以看出,配置3 的结果相比于配置2 的结果恢复了更加准确的色温。当深度阴影特征也融入配置3 中(即本文方法)取得了最高的MPS,为0.6601。从图6 中的红色方框部分可以看出,我们的结果具有更加准确的阴影。

图6 不同模型配置下的定性比较Fig.6 Qualitative comparison of different model configurations

表4 消融实验Tab.4 Ablation Study
我们也研究了不同阴影阈值对于重光照结果的影响。在本文标注的阴影阈值T的基础上,我们加上±Δ 的扰动,得到不够精确的阴影,作为阴影真值,来训练整个模型。在本实验中,Δ 的取值为10。注意,若扰动后的阴影阈值小于0,则直接置为0。如表5 所示,精确阴影阈值T下的重光照性能最好,MPS 最高,为0.6601。对比之下,扰动后的阴影阈值T-Δ和T+Δ 都出现了不同程度的性能下降,MPS 分别下降了0.0052 和0.0118。这主要是因为,错误的阴影标注势必降低阴影生成的准确性,干扰深度阴影特征,并最终影响重光照的性能。
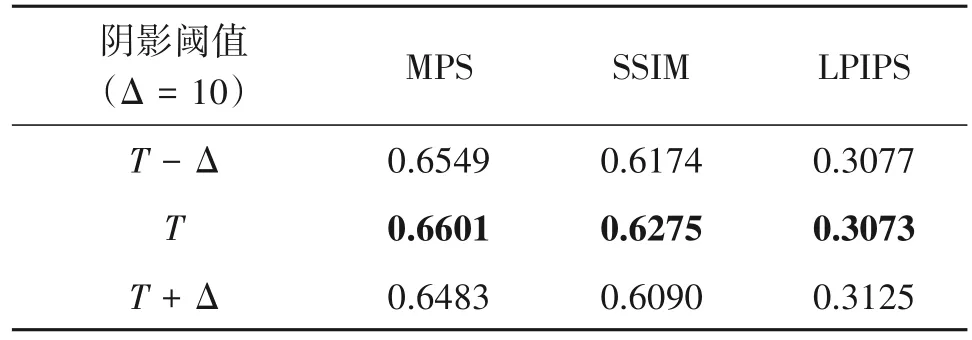
表5 不同阴影阈值的影响Tab.5 Effects of different shadow thresholds
最后,我们研究了公式(9)中λ1和λ2的取值对于重光照结果的影响。本实验中,我们对λ1和λ2按比例取了五组值,即(1.0,0.0),(0.7,0.3),(0.5,0.5),(0.3,0.7)和(0.0,1.0)。如表6 所示,在(0.5,0.5)的取值下,重光照的性能最好,MPS 为0.6599。对比之下,(1.0,0.0)取值下的重光照的性能最差,MPS 仅为0.5791,比(0.5,0.5)取值下的MPS 下降了12%左右。其中,MPS 的下降主要是由于SSIM 过低导致,这说明基于SSIM 的损失函数能显著提升图像的生成质量。

表6 λ1和λ2的影响Tab.6 Effects of λ1 and λ2
6 结论
本文提出了一种基于深度阴影特征增强的任意至任意重光照方法。该方法引入一个额外的阴影生成任务,通过设计对应的阴影解码器,明确学习重光照中的阴影特征。同时,利用基于注意力机制的特征融合模块,自适应融合阴影特征与重光照特征,提高阴影生成的准确性。为了训练阴影解码器,我们结合人的主观评价设计了一个简单的阴影标注算法,获取阴影图像真值。我们在VIDIT 数据集上进行了大量的实验,实验结果验证了本文所提方法的有效性。
