基于生成对抗网络的滚动轴承不平衡数据集故障诊断新方法
2022-10-11郭俊锋王淼生续德锋
郭俊锋,王淼生,孙 磊,续德锋
(兰州理工大学 机电工程学院,甘肃 兰州 730050)
0 引言
在现代工业中,机械设备正朝着高精度、高效率、自动化、复杂化的方向发展,故障甚至事故更加频繁发生[1],这对机械设备的可靠性和安全性提出了更高的要求。滚动轴承是旋转机械的重要支撑部件,其健康状况会影响整个设备的工作性能,一旦发生故障,轻则降低生产效率,耽误生产进度;重则造成影响恶劣的生产事故。因此,及时对滚动轴承进行状态监测以及可靠的故障诊断具有重要意义。
机器学习,尤其是深度学习[2]已经被广泛地用于旋转机械的轴承状态监测和故障诊断。与依赖于人工提取特征的传统方法相比,深度学习模型具有强大的深层次特征提取的能力[3-5],已经在机器状态监测故障诊断的最新应用中取得了巨大成功。沈涛等[6]提出一种卷积长短时记忆网络(Convolutional Neural Networks—Long Short Term Memory, CNN-LSTM)批标准化诊断模型,实验表明该方法优于传统的深度学习诊断模型。
对于深度学习模型,训练数据是影响其性能的重要因素。为了获得准确的故障诊断,需要大量的平衡数据对深度诊断模型进行训练。在实际情况下,机械设备在大多数时间里在正常的工作条件下运行,可以很容易地收集到足够多的机械设备在正常状况下工作的数据。然而,机械设备很少在故障状况下运行,故很难收集到足够多的故障样本[7]。因此,很难得到大量且平衡的数据训练深度学习模型,这极大地限制了深度学习模型实现准确故障诊断的能力。
为了解决不平衡数据集的故障诊断问题,现有方法主要分为算法优化和数据合成。算法优化的目的在于优化模型结构和损失函数,使分类器尽可能地关注少数类别。ZHANG等[8]提出一种基于原型学习网络的滚动轴承诊断的深度对抗半监督方法。JIA等[9]提出深度归一化卷积神经网络来改善训练过程,加权SoftMax损失有助于解决分类不平衡的问题。WU等[10]开发了一个加权的长循环卷积LSTM模型,并利用欠采样策略和加权的代价敏感损失函数来解决不平衡数据集故障诊断的问题。但是,基于算法优化的方法主要针对数据集各类别样本数量比例固定的情况,不能很好地解决数据集各类别样本数量比例变化的问题。而机械设备在运行过程中,数据集的不平衡率会发生变化[11]。因此,合成少数类别以平衡数据集是提高分类器性能的最优方案。
当使用设备运行中产生的数据解决数据集不平衡的故障分类问题时,生成对抗网络(Generative Adversarial Net, GAN)为生成少数类别样本提供了一个选择[12]。GAN最初被用作生成图像的框架,已被证明在图像生成方面具有强大的能力。但是,由于GAN训练不稳定,使用GAN生成的数据质量非常差。因此,已经有很多关于提高GAN性能的研究。ZHENG等[13]提出一种有监督的条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)模型用于生成大量的故障数据,并用生成的数据代替真实的故障数据,构成一个新的数据集来训练分类器。WGAN(Wasserstein GAN)[14]试图形成一个新的损失函数,以获得更好的稳定性和图像生成效果,但同时也给判别器网络带来了新的限制,这一限制使得网络存在训练困难的问题。李亚鑫[15]针对工业环境无故障样本的问题,结合有限长单位脉冲响应带通滤波器和深度卷积生成对抗网络,仅采用行星齿轮箱结构参数和健康的行星齿轮箱振动信号,搭建了行星齿轮箱关键零部件故障检测框架。ZHANG等[16]提出一种使用条件生成对抗网络解决数据集不平衡的问题,采用多个生成模块来进行少数类的数据扩充。SHAO等[7]开发了一个基于辅助分类器的GAN框架,从机械振动信号中学习并生成逼真的一维原始数据。但上述模型依旧存在着各自的问题,并未解决生成对抗模型梯度消失、模式崩溃、训练过程不稳定以及生成样本质量较差和没有指向性等问题。同时,GAN作为图像生成框架,只有将其用于生成图像样本,才能更好地发挥它在样本生成方面的优势。
本文利用小波分析(Wavelet Transform, WT)[17]将一维原始振动信号转换为二维时频图,并将其作为条件梯度惩罚生成对抗网络(Conditional Wasserstein GAN—Gradient Penalty, CWGAN-GP)模型的输入。通过将小波时频分析与CWGAN-GP相结合,充分利用了原始信号的时频域信息,同时将时频图作为生成目标也能更好地发挥CWGAN-GP图像生成的优势。此外,该方法也解决了原始GAN训练过程不稳定、梯度消失、生成样本质量差和训练一次只能生成一类样本的问题。实验结果表明,提出的方法能够生成高质量的样本,具有很好的鲁棒性,且在数据集不平衡的情况下也具有不错的诊断性能。
1 小波变换与GAN
1.1 小波变换
小波变换被称为信号分析显微镜,它可以大规模地全局显示低频信息,而在小范围内可以局部显示高频特性。虽然可以采用WV(Wigner-Vile)分布、短时傅里叶变换和小波变换等多种方法将原始信号转换为时频图像,但其中的一些方法存在一定的局限性。短时傅里叶变换的窗口大小是固定的。WV分布会受到交叉项的干扰[18]。在时域中,一般的小波变换可以表示为:
(1)
式中:x(t)为给定的时间序列,φ为母小波,φ*为φ的复共轭,a为可以控制小波展开的比例,b为标识其位置的平移因子。
本文采用小波变换,从一维原始信号中提取时频图像特征,使其作为生成对抗网络的输入。除此之外,Morlet是应用最广泛的小波基,并且非常适合于旋转机械的故障特征提取,因此选择Morlet作为小波变换的小波基。
1.2 CGAN
生成对抗网络是一种无监督的深度学习模型框架,最初由GOODFELLOW等[12]提出,框架中通常包括生成器和判别器两部分。该模型具有很强的学习数据表示的能力,其训练过程是一个零和博弈过程。简单的噪声分布,如高斯分布或均匀分布作为生成器的输入,生成器G将其映射到与输入的真实样本相同的数据空间,通过训练,尽可能生成与真实样本相似的样本。同时,判别器D被用来判别生成的样本和真实的样本,并训练判别器不被生成的样本所欺骗。当训练过程达到纳什均衡时,生成样本的分布将与真实样本的分布一样接近,GAN的目标函数如式(2)所示:
Ex~Pg[log(1-D(x)]。
(2)
式中:Pr是真实数据的分布,Pg是由两个隐式x=G(z)和z~p(z)定义的生成数据的分布,其中z是从简单的噪声分布中采样得到的。D的目标是最大化识别出输入样本来自真实样本的概率,G的目标是使生成样本的分布无限接近真实样本的分布。
在生成器和判别器中加入指导样本生成的辅助信息y就得到了GAN的变体CGAN,辅助信息y可以是类别标签,也可以是任何其他类型的信息。辅助信息的加入能够提高生成样本的质量[19]。CGAN的训练过程与GAN相同,目标函数如式(3)所示:
Ex~Pg[log(1-D(x|y))]。
(3)
式中Pr和Pg的意义与在GAN中的相同。
在式(2)和式(3)中,两项均值之和即为JS(Jensen-Shannon)散度。在每一次训练过程中通过最大化JS散度使判别器达到最优,然后固定判别器,最小化JS散度使生成器生成的数据尽可能真实。经过大量训练以后,使得判别器无法判别样本是真实样本还是生成样本。但是,实际训练过程是很不稳定的,很容易出现梯度消失、模式崩溃等问题,导致生成样本单一甚至训练无法继续,这是由于JS散度是离散的,即使两个分布不重叠或者当重叠部分可以忽略不计时,JS散度都恒为常数。
1.3 WGAN-GP
为解决JS散度不连续导致梯度消失的问题,提出了WGAN。WGAN使用EM(earth-mover)距离,也被称为Wasserstein-1距离作为衡量真实样本分布和生成样本分布之间距离的度量,且Wasserstein距离是连续的,这使得WGAN的训练过程更加稳定。WGAN的目标函数如式(4)所示:
Ex~Pg[D(x)]。
(4)
然而,在式(4)中,Δ表示1-Lipschitz函数集。因此,要实现WGAN,判别器D应该属于1-Lipschitz函数。这一限制可以通过乘以比例因子放宽,通过将判别器中每一层的权重裁剪到[-c,c]就可以使式(4)中判别器属于K-Lipschitz函数,也会使WGAN的训练过程更稳定。但是在某些情况下,WGAN会出现训练过程不收敛,生成样本质量差的问题。而这些问题的发生就是因为为了放宽Lipschitz约束而使用了权重裁剪。权重裁剪导致WGAN无法学习复杂样本的分布。除此之外,权重裁剪也将各层的权重限制在一个很小的范围内,而这很容易导致梯度消失。
为了解决上述问题,提出了WGAN-GP(WGAN with gradient penalty),该方法进一步改进了WGAN的损失函数,它用梯度惩罚满足Lipschitz条件。WGAN-GP的目标函数如式(5)所示:
(5)


(6)
在实际应用中,WGAN-GP具有更快的收敛速度以及更稳定的训练过程,并且可以在几乎不调整默认参数的情况下,获得高质量的生成样本。
1.4 CWGAN-GP
受到GAN的变体CGAN的启发,同时为了解决GAN在训练过程中梯度消失、训练过程不稳定以及生成样本单一以及WGAN-GP一次只能生成一类样本的问题,提出了CWGAN-GP。同时在WGAN-GP的生成器和判别器中加入条件辅助信息y,在这里y可以是任何类型的辅助信息,CWGAN-GP的目标函数如下:
(7)

判别器和生成器的目标函数最小化后,
(8)
(9)
在实际应用中,CWGAN-GP具有收敛速度快、生成样本质量高且一次训练就可以生成多类样本的数据生成能力,同时也不存在GAN和WGAN在训练过程中梯度消失,训练过程不稳定的问题,而且几乎不需要修改默认超参数就可以生成高质量的样本数据,解决了GAN训练困难的问题。
2 基于CWGAN-GP的轴承故障诊断方法
2.1 诊断方法与步骤
本文的目的是利用CWGAN-GP模型生成高质量的样本对轴承不平衡数据集进行扩充与平衡,然后将其用于轴承故障诊断。在实际应用中,不平衡数据集会严重制约故障诊断模型的性能,而基于CWGAN-GP模型生成的高质量样本能够丰富原始数据集,为模型训练提供更多有价值的信息,从而有助于实现准确的故障诊断。诊断过程如下:首先,利用小波变换对原始振动信号进行时频分析,将原始一维振动信号通过提取特征转换为二维时频图样本;其次,利用提出的CWGAN-GP模型进行样本生成,用于平衡数据集;最后,使用平衡后的数据集进行故障诊断。诊断方法如图1所示。故障诊断流程图如图2所示,具体步骤如下:

步骤1从试验台收集轴承原始振动信号进行信号预处理,并使用小波变换将其转换为时频图像。
步骤2将转换后的时频图像按一定比例分为训练集和测试集。
步骤3利用训练集中的样本训练生成对抗网络模型,对生成的样本进行相似度验证,从而生成更多的训练样本。
步骤4用生成的样本和原始训练集中的样本组成新的训练集用于训练故障诊断模型。
步骤5利用测试集测试训练好的故障诊断模型。
步骤6输出故障诊断结果。
2.2 基于CWGAN-GP的样本生成
本文采用CWGAN-GP模型用于样本生成,具体是将一维时域信号经过小波变换后得到的时频图输入CWGAN-GP模型。其中生成器采用反卷积结构,判别器采用卷积结构。如图3所示,生成器中有5个反卷积层。一个服从高斯分布的100维噪声随机变量被映射和整形为许多卷积表示的特征图,最后这些特征图被转换为64×64×3大小的图像。另外,判别器中有4个卷积层,输入为64×64×3的图像,随后被映射和整形为许多卷积表示的特征图。最后,一个全连接层作为输出层。在生成器中,前4层卷积核的大小为5×5,最后一层为3×3。在判别器中,卷积核的大小均为3×3。


3 实验与结果分析
3.1 数据集描述
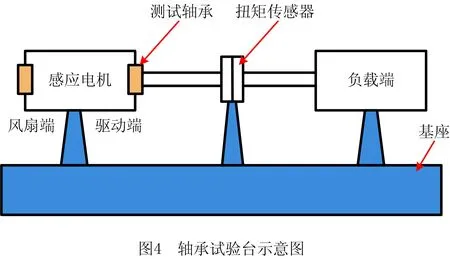
实验数据来源于凯斯西储大学(CRWU)轴承数据中心的开放数据集,该数据集在故障诊断领域得到了广泛的应用。利用电火花对轴承内圈、外圈和滚珠进行损伤,损伤直径分别为0.007英寸、0.014英寸、0.021英寸和0.028英寸。然后在0 hp~3 hp的不同载荷下采集各种振动信号。该数据集包含正常状况、内圈故障、外圈故障和滚珠故障4种工作状况。数据集的振动信号是由加速度计从轴承实验台收集的,实验台示意图如图4所示。在本实验中,选择实验台驱动端的深沟球轴承作为研究对象,采样频率为12 kHz。
3.2 实验数据预处理
在本实验中,以工作负载分别在0 hp和1 hp且故障直径在0.007、0.014、0.021英寸的故障轴承为研究对象。为了验证本文所提出的方法对不同类型的故障能够实现很好的诊断效果,采用表1数据集作为实验数据。在能够区分不同类型故障的基础上,为了进一步验证本文方法对同一类型不同故障程度的识别效果,又采用了表2数据集,其中既包括不同故障类型又包括同一类型不同故障程度的数据。本文研究遵循循序渐进的过程。实验轴承在每种不同的故障状况下有120 000个数据点,以600个数据点为一段,为了获得更多的样本,相邻的段之间有300个点重复。经过小波时频分析,在每种工作条件下,可以得到400张时频图像。然后随机的选择200张用于训练GAN和分类器,剩下的200张用于测试和评价模型。详细信息如表1和表2所示。

表1 四类数据集信息(0 hp)

表2 十类数据集信息(1 hp)

续表2
3.3 生成样本相似性的可视化评价
图5给出了在4类数据集下真实样本的时频图和利用CWGAN-GP模型生成的时频图样本。很明显,在图5中,生成样本与真实样本非常相似。虽然在一些地方有很小的差别,但是可以发现生成样本中的特征与真实样本的特征基本具有相同的分布。除此之外,这些细微的差别也可以说明生成对抗网络学习到了真实数据的分布,生成的样本是从真实分布中采样得到的,而不是对原始样本的简单复制,由此可以增强故障诊断模型的鲁棒性,提高分类模型的泛化能力。

本文采用t-分布随机领域嵌入(t-distributed Stochastic Neighbor Embedding, t-SNE)[20]验证生成数据与真实数据的相似性。t-SNE是一种用于降维和数据可视化的算法,该方法通常被用作验证数据相似性,它通过仿射变换将数据点映射到概率分布上。在映射的过程中,高维空间的点需与低维空间中的点一一对应,但低维空间的点存在一个随机的过程,因此在本文中会导致真实数据的位置不相同。
在本文t-SNE的实验结果中,只要各类别生成样本和真实样本可以聚合为一类以及各故障类别样本有清晰的边界,就可以说明本文所提方法的有效性,样本的位置并不影响实验结果。实验中所有对照实验使用的真实样本均为同一批。图6和图7展示了真实样本和生成样本在4类和10类数据集上的t-SNE图,为了验证两类样本的相似性,随机地从各类真实样本和生成的样本中分别选择50个样本。图6和图7分别展示了GAN、CGAN、WGAN、WGAN-GP、CWGAN-GP五种生成模型在4类和10类滚动轴承数据集上生成样本和真实样本的分布。结果表明,随着模型的改进,生成样本和真实样本的分布越来越趋于一致。同时,通过将两个分布之间的衡量标准由JS散度替换为EM距离也进一步使生成样本和真实样本的分布更加相似。在4类数据集的t-SNE图中可以发现,虽然前3种生成模型生成的样本能够与真实样本聚合为一类,并且4类故障之间有清晰的边界,但是这3类模型生成的样本没有分布在真实样本之间,而是自成一类分布在真实样本周围,说明这3种模型生成的样本与真实样本的相似性不足。虽然最后两种模型生成的样本和真实样本非常相似,但是可以发现本文中提出的模型生成的样本与真实样本有更好的相似性,其分布更接近真实样本的分布。


同时,在10类数据集的t-SNE图中可以发现,前3种模型生成的样本与不同类的真实样本和生成样本混叠在一起,没有清晰的分类边界。最后两种模型生成的样本与真实样本之间虽然存在分类边界,但是第4种模型的少数类别之间依旧存在着样本混叠,而CWGAN-GP模型生成的每一类样本基本与其他类别样本没有混淆。通过分析,本文提出的模型与第4种模型相比,由于加入了故障类别辅助信息,生成的样本与真实样本更相似。这说明条件信息对样本生成具有积极的指导作用。
为了说明本文使用的生成模型生成的样本数据对故障分类有积极的影响,将从10类数据集中随机选择50个真实样本得到的数据集和将使用该数据集训练不同的生成网络模型后生成的各类样本全部添加到该数据集中的得到的数据集分别进行t-SNE可视化展示,数据分布结果如图8所示。从图中可以发现未添加生成样本的10类故障的数据的分布之间没有明显的边界,存在混叠现象。而添加了全部生成样本的10类故障数据之间存在明显的边界,由此可以说明,生成样本与真实样本有着很强的相似性,同时,生成的样本对故障分类有着非常积极的作用。除此之外,与图7e对比也可以发现,添加的生成样本越多,各故障类别之间的边界越明显。这说明样本数量影响类别边界,从而影响故障分类的准确率。

3.4 基于统计指标的样本相似性评价
为了从统计的角度评估真实样本和生成样本的相似性,本文引入欧几里得距离和余弦相似性两个指标,这两个指标展示了生成模型样本生成的平均性能。
欧几里得距离,也称欧氏距离,它衡量的是空间中各点的绝对距离,跟各个点所在的位置坐标直接相关。它主要被用于评价在欧几里得空间中两个向量在位置上的差异性,其值越小,表明相似度越大。两个空间向量的欧几里得距离计算公式如下:
(10)
余弦相似性,也称余弦距离,是用向量空间中两个向量的余弦值作为衡量两个个体差异大小的指标。相比欧几里得距离,余弦距离更加关注两个向量在方向上的差异,其值越小,表明两个个体越相似。两个向量的余弦距离计算公式如下:
(11)
图9展示了4类和10类数据集上所有类别统计指标的箱线图。箱线图的中位数表示了样本数据的平均水平,箱线图的高度表示数据的波动程度,箱线图上方和下方的线表示指标的最大值和最小值。从图中可以发现,在4类数据集上GAN、CGAN以及WGAN生成的样本与真实样本之间的距离较大,样本相似性不足,且各类别生成样本的质量差异较大。而WGAN-GP虽然从图中表明其与CWGAN-GP模型的平均性能基本一致,但是两类指标箱线图的高度高于CWGAN-GP模型,这说明WGAN-GP模型生成的各类样本质量差异较大。在10类数据集上,GAN生成的样本相似性不足,且生成样本的质量波动较大。CGAN和WGAN模型生成样本的质量以及各类别样本质量差异较大。WGAN-GP和CWGAN-GP模型生成样本的质量以及各类别样本质量的差异性远远优于其他3种生成模型,且CWGAN-GP生成的样本质量明显优于WGAN-GP。综上所述,CWGAN-GP模型有更好的鲁棒性与多类别数据生成能力,其性能优于其他模型。

3.5 在不平衡数据集上的故障诊断实验
在实际的场景下,本文收集到的轴承各类故障数据是极不平衡的,即轴承处在正常状态的样本远远多于处在故障状态下的样本。这种情况下,传统的各种故障诊断方法的性能将会被限制。为了进一步验证本文所使用的生成对抗模型在数据增强方面的有效性,本文将4类和10类原始数据集中的各类别故障样本的数量缩减到原始规模的10%,得到不平衡数据集Origin,并使用各生成模型生成的数据平衡该数据集,基于上述两个数据集,使用其分别训练支持向量机(Support Vector Machine, SVM)、随机森林(Random Forest, RF)、多层感知器(Multilayer Perceptron, MLP)、卷积神经网络(Convolutional Neural Networks, CNN)、一维卷积神经网络(One Dimensional Convolutional Neural Network, CNN-1D),并使用测试数据测试两个数据集在5种分类器下的准确率,测试结果如图10所示。

由图10可知,无论使用何种样本生成模型扩充数据集,在4类和10类数据集上的故障分类准确率都明显地提高了。尤其是明显地提高了10类数据集上的故障分类准确率,这说明本文使用的数据扩充方法非常有效。数据扩充后,使用CNN和CNN-1D在4类数据集上进行故障分类,准确率达到了98%以上,在10类数据集上的准确率也达到了97%以上。其中,基于SVM和MLP的分类模型最为明显。此外,基于CWGAN-GP的样本扩充方法在所有的故障分类器上都具有最高的分类准确率。这说明基于CWGAN-GP的生成模型生成的样本能够用于替代真实样本平衡数据集。同时可以发现,基于CNN的分类方法在平衡后的数据集上都获得了最高的分类准确性,这也说明将一维数据转变为二维数据进行样本生成是非常合适的。
总之,基于CWGAN-GP的数据扩充方法为数据集不平衡的轴承故障诊断提供了一种非常有效的方法,并且它在分类模型上有着较高的故障分类准确率和较好的鲁棒性。
为了进一步验证本文所提方法的有效性,在10类数据集的训练集上设定了正常样本与故障样本的多种不平衡率,然后基于上述5种分类模型在测试集上进行了测试,结果如表3所示。

表3 不平衡率差异下10类数据集上的故障分类准确率
由表3可知,即使正常样本和故障样本的不平衡率达到100∶1,在利用本文所提方法生成的样本平衡数据集之后,轴承故障分类的准确率在两种卷积神经网络的方法下也保持在很小的范围内变化。这进一步说明生成对抗网络已经学习到了真实样本的分布,利用本文所使用的方法是解决不平衡数据集故障诊断问题的有效方法。此外可以发现,通过将训练集样本的数量扩大,无论哪种分类器,故障分类准确率都有所提高,尤其是基于SVM的方法最为明显。这说明样本数量也是制约分类器准确率的一个重要因素。总之,生成的样本已经可以与真实样本相媲美。
最后,由于本文使用的数据集是由图片样本组成的,并且CNN在各种数据集平衡模型上都得到了非常高的准确率,而且CNN在图像特征提取方面有很大的优势,为了评估模型在各个故障类别上的表现,本文选用CNN作为故障分类器,使用图8b所使用的数据集,训练100个Epoch之后绘制出了在10类数据集上的混淆矩阵,如图11所示,Ball1故障中很小的一部分被错误地分类到了Ball3故障,Ball2故障的很小一部分也被错误地分类到了Ball3故障,Ball3故障的很小一部分被错误分类到了Ball2故障,而且在图中可以发现所有故障类型的诊断结果均在99%以上,这说明本文所使用的数据扩充方法能够很好地生成各种类型的故障样本,对于解决不平衡数据集的故障诊断,本文提出的故障诊断方法是比较理想的选择。

3.6 故障诊断的及时性
为了进一步说明本文所提出的滚动轴承不平衡数据集故障诊断方法的及时性,分别统计了生成样本耗时、在图8b所使用的数据集下不同故障诊断模型的训练耗时以及每个样本的故障诊断耗时。实验电脑系统为Windows10;CPU为Intel Corei7-9700F,3.00 GHz;RAM为16 GB;显卡为GTX1660。编程软件为Python 3.6版本,深度学习框架为Keras。4类和10类数据集上的故障诊断耗时如表4和表5所示。

表4 4类数据集上不同诊断方法的耗时 s

表5 10类数据集上不同诊断方法的耗时 s
由表4和表5可以发现,所有方法中主要耗时为生成样本耗时,由于5种方法都采用了相同的样本生成方法,具有相同的生成样本耗时;在诊断模型训练耗时方面,本文所提方法CWGAN-GP+CNN耗时最长,这是由于为提高分类准确率采用了深层学习机制,模型参数多,导致训练时间长,在一些对训练时间要求较高的场合可以提前进行离线训练;从故障诊断耗时来看,本文方法耗时最长,但是也仅仅在微秒级,在实际应用中影响很小。结合诊断精度和诊断模型的鲁棒性来看,本文方法在耗时影响不大的情况下可以取得很好的故障诊断效果。
4 结束语
本文提出一种新的基于CWGAN-GP的不平衡数据集故障诊断方法。通过将一维原始振动信号换为时频图像,充分地利用了信号在时频域的信息。并且该方法结合了CGAN模型利用条件信息将无监督学习转变为监督学习生成多类别数据以及WGAN-GP模型在样本生成过程中避免模式崩溃、梯度消失、收敛慢和训练过程不稳定的优点。利用生成的高质量样本进行数据集扩充与平衡,能够解决分类模型在训练过程中因数据集不平衡导致的故障分类准确率低的问题。在CRWU数据集上的实验结果表明:
(1)本文所使用的方法能够在几乎不调节超参数的情况下生成质量更高的样本,并且有助于提高故障诊断的准确率。利用小波变换得到的时频图作为CWGAN-GP模型的输入能够取得不错的效果。
(2)t-SNE可视化方法以及分类模型的结果表明,数据量的大小会影响分类模型的准确率,数据量越大,分类模型越能够取得不错的分类结果。同时,在生成模型中添加类别辅助信息有助于提高生成样本的质量。
(3)10类数据集上的混淆矩阵表明,本文所使用的方法生成的样本用以平衡数据集可以在各故障类型的诊断中取得非常不错的效果,从而表明该方法具有较好的鲁棒性。
虽然本文所提方法在数据集不平衡的滚动轴承故障诊断问题上取得了不错的效果,但是由于本文所提出的样本生成方法在模型训练时耗时长,故难以实现对新的故障的快速诊断,在未来还需进一步研究如何缩短模型的训练时间,综合利用新的信息实现准确故障诊断的方法。
