基于改进K-means 模糊聚类的区域健康大数据智能分析方法研究
2022-10-11陈娇花
陈娇花
(上海中医药大学附属第七人民医院,上海 200137)
区域健康数据分析指的是对某一区域人群的体检健康数据进行一定的统计分析,进而对整个区域内人群的健康情况和患某种特定疾病风险进行预估[1]。而随着医疗数据信息化时代的到来,医疗数据所呈现出的特点是海量化与复杂化,这些数据维度通常可以达到上千维。以上海市为例,当前上海常住人口约为2 400 万,在亚洲城市中位列第一,60 岁以上老人占据总人口的35%,其医疗健康数据也达到了较大的规模。使用常见的统计学方法进行数据分析效率过低,因此,需要深入研究智能化的区域健康数据分析方法。
目前,常见的区域健康数据分析方法为数据挖掘,其中典型的方法为聚类分析法。传统的K-means聚类方法难以处理与分析高维度健康数据,相对于误差和时间开销均不理想。因此该文对传统K-means聚类方法进行改进,使其能够对高维数据进行快速、准确的分析。
1 高维数据聚类方法
高维数据是指数据属性数量较多的数据,此时数据集合中的横向维度就会变得非常繁冗,这会对数据处理造成运算量的大幅激增。在聚类算法中,对高维数据进行聚类有三种方法:1)使用传统方法直接对数据进行训练;2)对冗余的属性进行相应的筛选,从而简化属性;3)利用收缩法,采用各种正则化因子对隶属函数进行约束。
在传统算法中,K-means、C-means 算法的使用均较为广泛。虽然传统算法简便快捷,而且这些算法对低维数据的处理程度较好,但是它们对于高维数据的处理通常会表现得比较吃力[2-3]。
属性简化算法中大多使用粗糙集理论[4],其通过已知的数据库对现有不确定样本数据库中的内容进行刻画,这种算法可以大幅度地缩短运算时间。
正则化因子的算法主要是确定回归变量,例如文献[5]中的算法,可以在一定程度上提升聚类的效果。但这种方法针对性较强,对不同类型的数据需要不同类型的正则化因子,且鲁棒性较差。
因此,该文将使用属性简化算法完成高维数据的智能化分析。
2 结合粗糙集模糊理论的K-means算法设计
2.1 K-means聚类算法
K-means 聚类算法是无监督聚类算法的代表,主要思想是将多个样本数据集聚类为K个簇[6-7],并将每个样本分配到距离其簇最近的集合中。样本值距离中心值越远,则意味着该值偏离平均值的幅度越大。
假设样本数据集合为X,该数据集合中包含有n个数据,则该集合如式(1)所示:

该文使用的数据为区域人群健康数据,因此每个样本均为高维数据,设其维度为m。然后确定数据集合的聚类中心,假设个数为k,则聚类中心集合为Ci={C1,C2…Ck}。最终,计算样本集数据到聚类中心集合间的欧氏距离D(xi,ci)为:

评价聚类效果的指标为误差平方和,该指标表示样本数据集簇中的数据与中心数据之间的密集程度,定义SSE 和误差平方的表达式为分别:

由式(2)和式(3)可以看出,当数据维数较低或数据每个维度的特征均较为重要时,K-means 聚类方法快速、有效。但当数据维度较高时,数据某些核心维度的特征就会被掩盖,这样不利于后续数据的处理。因此,需要对高维数据进行降维,或使用对应算法对数据进行处理。
2.2 模糊聚类理论
模糊聚类相比于K-means 聚类算法多加入了隶属度函数[8-9],这可以有效地提高K-means 算法在处理多维数据集时的特征掩盖问题。
假设样本数据集合为X={X1,X2,…,Xn},则设定最小化目标函数应为:

式中,F为最小化目标函数,C为聚类中心个数,||vi-Xm||表示样本数据中第m个数据到第i个聚类中心的欧氏距离,k为加权的系数,μim表示隶属度函数。模糊聚类算法的执行流程如图1 所示。

图1 模糊聚类算法执行流程
2.3 粗糙集模型构建
粗糙集理论算法的主要思想就是将现有不确定的样本数据库通过已知数据库中的内容进行刻画。从本质上来说,就是将不确定的数据确定化,这样就可以保证在系统分类效果恒定的基础上,对多维数据进行降维简化,从而解决问题[10-12]。
使用粗糙集对K-means 算法进行优化,则第i个聚类中心中的数据xi的密度函数如下所示:

式中,δ表示邻域半径,其表达式为:
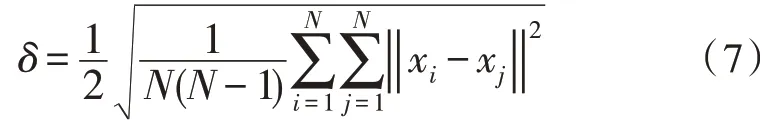
而样本数据xi的权重应为:
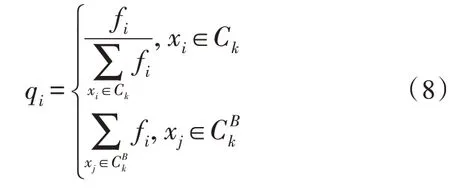
则可求得每个簇的中心点,如式(9)所示:

由此可以看到,使用粗糙集合理论对数据进行处理,可去除高维数据集合中的某些冗余属性。因此需要对数据属性中的权重值进行计算和确立,这样可以使数据聚类得到的结果更加客观,权重公式如下所示:

因此,若数据集合中数据的维度为b,则此时加权得到的欧式距离应为:

然后,从整体决策对多维数据进行属性简化,假设输入为b维的数据集合X,簇的个数为K,则简化步骤应为:
1)使用上述理论对b维数据集合进行数据清洗处理,此时即可得到b维的清洗数据集合X-Re,然后使用权重公式对b维数据集合的权重进行计算;
2)由式(11)计算出数据的加权距离,得到簇的个数K;
3)对每个维度数据的权重和簇中心点位置进行循环更新;
4)当簇中心点位置不变时,步骤结束,否则循环步骤3),直到簇中心点位置不变为止。
2.4 模型构建
该文构建的结合粗糙集模糊理论的聚类模型思想就是通过粗糙集确定多维数据的权重,进而提高聚类精度。同时,通过模糊理论提升了聚类模型的聚类效果。
首先,使用模糊聚类模型对样本数据集合的聚类中心个数进行确定;然后,对加权系数值进行初始化和计算。使用粗糙集理论对数据集合属性进行简化,同时结合模糊理论对隶属度函数进行更新。不断重复该过程,直到聚类中心位置不变即可停止。该文总体模型执行流程图如图2 所示。
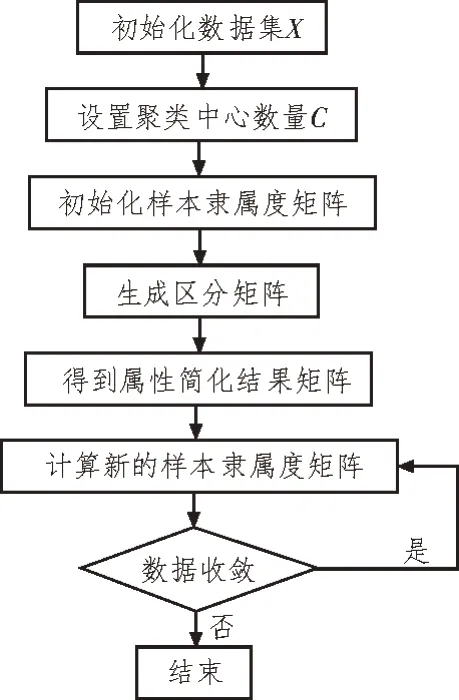
图2 总体模型执行流程图
2.5 效果指标
聚类分析中主要使用效果指标对模型性能的优劣进行评价。通常使用的指标为外部指标或内部指标,外部指标反映的是聚类结果与实际数据聚类之间的偏离程度;内部指标反映的是在实际数据聚类效果未知的情况下,模型聚类效果的优劣。
外部指标使用β指标[13-16],如式(12)所示:

内部指标使用S指标,该指标可以对数据的属性进行评价,指标的定义如式(13)所示:
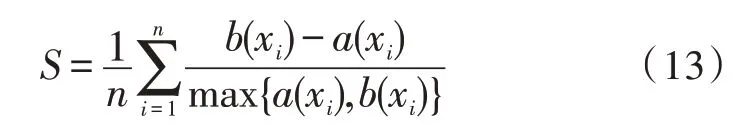
由式(13)可知,S的值越趋近于1,表征算法的聚类效果越好。
3 实验分析
文中构建的模型可通过分析区域人群的健康多维数据对数据进行聚类分析,并能够判断出区域人群患病风险,进而采取措施加强防范。
3.1 数据处理与环境配置
该文数据来源于开源的健康普查数据集合,数据环境的配置如表1 所示,该数据集合所包含数据的维度较大,对于慢性病的诊断与分析均有较好的应用价值。同时可以选择不同地区的人群进行分析,文中选择上海浦东新区的60 岁以上老年人口的健康数据进行分析。由统计资料显示,该地区60 岁以上老人数量约为100万人,约占上海老年人口的20%,因此分析该地区健康数据具有显著意义。

表1 数据环境配置
3.2 算法精确度测试
为了对该文模型算法的精确度进行验证,文中使用多个对比算法对准确度进行分析,对比算法为传统K-means 算法、传统模糊聚类算法以及DSSC 参数相似度算法。使用以上算法在相同的数据集合中进行50 次对比实验,最终取准确率的平均值。同时也对聚类效果指标进行计算,结果如表2 所示。

表2 算法准确率对比实验
由表2 中的结果可以看出,在准确率测试中,所有算法对于低维的数据集合聚类准确度均较高,但对于高维数据均偏低。该文算法在高维数据中有较好的表现,相较其他算法准确率提高了约5%。在聚类效果的测试中,指标β值和S值也有较大的优势。这说明文中算法模型在处理高维数据时,具有较好的准确度和优良的效果。
3.3 算法时间测试
除了准确度之外,算法所花费时间也是算法性能的重要衡量指标之一。在聚类算法中,算法所花费时间主要是簇中心的位置更迭。在处理维度较高的数据时,算法的执行时间会大幅度增加。该文使用对比算法对花费时间进行测试,模型运行次数为50 次,取运行时间的平均值,得到的结果如表3所示。

表3 算法运行时间对比
从表3 的实验数据可以看出,无论数据集的维度如何,该文算法在数据处理效率方面均较为理想。可以看到,虽然在处理低维数据集时,由于所提算法中的属性简化需要耗费一定的时间开销,故而造成运行时间略长。但在高维数据执行过程中,文中算法执行时间大幅度优于传统算法,这说明属性简化在算法执行时间中起着决定性的作用,使该文算法相较于传统算法在执行时间方面缩短了约50%。
由文中的准确率和执行时间实验可以看出,对于高维数据集合的聚类,引入模糊理论和粗糙集理论后,算法在聚类效果以及执行时间方面相较传统算法均有较为明显的提高,因此该文所提出的改进K-means 算法对高维数据的聚类更有针对性。
4 结束语
对区域人群的健康多维数据进行深入分析,可以判断出区域人群患病风险,进而采取措施加强防范。该文针对聚类分析方法的不足,基于模糊理论和粗糙集理论构建了区域健康数据分析模型,模型通过简化属性数量进而提高聚类效果。测试结果表明,文中模型的精度和效率指标均优于其他对比算法,表明该文所构建的模型满足系统需求。
