密码子偏好性的相关研究及方法分析
2022-10-10张晓明伊卫东
冉 然,张晓明,宛 涛,伊卫东
(内蒙古农业大学草原与资源环境学院/草地资源教育部重点实验室/农业农村部饲草加工高效利用重点实验室/内蒙古自治区草地管理与利用重点实验室,呼和浩特 010018)
生物信息系统的成功确立是以生命的诞生为标志的,也就是出现了DNA这种记载可重现个体发育信息的大分子,而这样构建生命的方式就是“遗传”[1]。遗传信息的传递经历了一个逐步进化的过程,其中非常必要的环节就是通过使用氨基酸,这个由三联体密码子编码蛋白质的结构单位必不可少。有20多种氨基酸可以构成为蛋白质,其中有大多数氨基酸包含2~6个不等的三联体密码。每一种氨基酸须对应至少一个密码子,当编码同一种氨基酸时,使用的不同密码子,互相称为同义密码子(synonymous codon),即简并现象[2]。
研究表明,生物体在演化和适应的过程中,如果没有任何突变基因的偏倚和选择压力,同义密码子的选择就是随机的[3]。对于某一个的物种或某一组的基因而言,会经常性的选择至少一种指定的同义密码子,而它们会频繁性的出现,称为是优化密码子,即最优密码子(optimal codon);而一部分密码子却很少能够被使用甚至于不会出现,称这样的密码子为稀有密码子,或者为非优化密码子。因此这种偏好性被研究者称之为密码子偏好性(codon usage bias)[4]。现如今这种同义密码子使用差异性已经普遍的存在于许多已知物种中,从某个单一物种的基因组中,不同一个物种所拥有基因组中的不同基因,是都能够通过研究去发现某些密码子是存在使用偏好这样的现象,尽管这种偏好性各不相同[5]。
1 密码子偏好性的影响因素以其研究意义
1.1 密码子偏好性的影响因素
在基因组中,不同样的基因之间具有不同样的密码子偏好性,其中,基因变异、选择、随机漂移因素是导致形成不同物种间密码子的偏好性的三个主要组成原因[6-9]。在实验中用生物学的相关方法对基因进行分析的研究显示,在初期密码子偏好性形成的原因可能是翻译选择。还有许多种可能会影响物种之间密码子偏好性的其它因素,如基因表达水平、基因长度、重组率、组分偏性(GC含量)、环境压力、种群大小[10-14]等。通过研究显示,密码子偏好性是一个比较丰富且复杂的现象,牵涉到了基因组内需要的密码子相关使用方式以及密码子偏好性程度的诸多因素。
1.2 密码子偏好性在分子生物学领域中的研究意义
在外源蛋白的表达和分子进化的研究中密码子偏好性显得尤为重要,对其进行分析是有着非常必要的意义和实用价值[15]。在研究密码子偏好性时,通过判定及筛选出一部分最优的密码子,把这部分密码子很大程度的融入到相关的基因表达载体设计中,一定的程度上说这是为了能够有效提升这个密码子目的基因的表达量。在全基因组扫描工作中,通过运用与基因组特征的差异进行相关的研究,针对在编码区和非编码区的密码子而言,可以探索并发现新的基因。大批的序列数据在研究与结构相关的基因组学中被获得,这些为开发和揭示功能基因开辟出一条宽阔的道路。通过实践证明,基于EST的电子克隆策略快速、简单。使用密码子偏好性和某种功能相互之间联系的复杂程度,可以帮助预测一些目前未知的某种功能基因,通过这些知识可以在初级阶段中判决出基因表达水平的高或低[16]。
1.3 密码子偏好性在草业科学中应用的重要意义
遗传信息载体DNA中还隐藏着许多未知的秘密,通过文中的概括可以得出密码子偏好性经历了初期分析方法的研究。密码子偏好性研究是一个不断丰富与递进的过程,从而促进了数据分析方法的多样性与开阔性发展。尽管存在一些不足,但随着基因组学和蛋白质组学的继续深入研究,密码子偏好性相关问题会涉及到更多的生物学领域。尤其是在草业科学方面的研究还处于初步阶段,对不同草种质资源基因组编码序列的密码子偏好性研究进行分析,有利于揭示相关草种质资源的系统进化地位,为其遗传多样性保护和群体遗传结构研究提供指导。同时,进一步为遗传育种理论研究和培育改良新品种的实践提供依据。并且通过比对相关草种质资源间的系统发生关系,可以进一步深入研究相关草种质资源的基因组学和系统进化分析提供重要的研究基础和参考意义。
2 密码子偏好性研究进展
早在20世纪60年代末期,人们就已经意识到密码子偏好性的重要性[17],于是对很多物种进行了大量深入的研究,结果发现不同物种的基因在使用密码子中差异明显[18-19]。之后又多次研究发现,不同密码功能的基因,其密码子的使用偏好性也会不同程度的存在较大的差异性[20]。
同义突变一直被认为是“沉默”突变[3]。在蛋白质翻译水平上发挥主要作用的被认为是自然选择,同义突变不会对氨基酸造成任何影响,因此被认为是选择上的中性突变;随着序列资料的丰富,说明同义密码子的应用在真核和原核生物的基因中都是非随机的(所以密码子的偏好性同样地也预见了这些同义突变,至少在某个维度范围内的情况下并都不是“沉默”的)。在实际密码子研究中的结果也已经表明,这种同义突变通常可能直接导致蛋白质结构功能和其产量会相对应的发生很大改变[21]。
GRANTHAM提出了基因组假说,其认为对任何基因来说,当选取同义密码子时,均可以使用相同的编码方法,即在密码子应用上的偏性是物种特异的[22]。随后,Post等对酵母菌和大肠杆菌进行进一步的分析研究,发现大肠杆菌核糖体蛋白基因优先应用的同义密码子中tRNA种类含量最多,这被认为是自然选择的结果,因为使用此种密码子将会增加翻译的精确度和效率。后来,IKEMURA证明在这两个物种中,一个基因中同义密码子的相对频率与识别它们的tRNA种类的相对丰度间存在着正相关,且对于高丰度表达的基因这种相关性尤其强[23]。
基于上述研究成果,形成了关于选择优化密码子的两种理论可以互为基本假说,一个理论是关于翻译准确性的假说,其主要观点认为在整个演化过程中,选择的一些优化密码子及其原因主要是由于可以使得其在翻译过程中有效率地降低了被非匹配的tRNA所识别的概率,从而可以更有效地做到避免具有错误性的蛋白的产生[24]; 另一个理论观点则主要认为,选择优化密码子使其可以需要增加翻译解码的持续时间更短,因此就能够增加核糖体的使用效率,这个观点与翻译准确性假说不互相矛盾,被称为是翻译效率性假说[25]。由于在生物体内唯一能够准确识别密码子的主要物质是核糖体,从而对密码子使用偏好性作用的具体形式认知仅仅只能局限于在翻译过程中。而对于哺乳动物,密码子偏好性与具有的tRNA丰度的对应之间的关系相对较弱,而且由于tRNA的对应含量在不同种类的组织细胞中也可能同时呈现比较大的含量差异,因而其翻译效率并不能够全面合理的适合用来解释各种同义突变的密码偏好效应。
随后,研究者主要关注的核心问题为密码子偏好性与基因表达的相互关系方面。在过去的几十年中,又从分子生物学、遗传学、病理学、系统生物学和分子生物化学等诸多学科方面对这些同义突变和密码子偏好性展开了进一步的研究[3]。
3 实现密码子偏好性相关的生物学基础
在已知物种中同义密码子使用偏好性的现象广泛存在着,这一现象的产生在许多生物学领域中受到关注。尤其以基因异源表达、基因的翻译调控、tRNA丰度、基因长度、蛋白质结构功能等方面与其关系较为密切。
3.1 基因异源表达
20世纪后期基因异源表达技术逐步成为了重要的科学,相关性的研究出现了突飞猛进的发展。表达系统的核心是表达载体,而基因表达中的主要影响因素是密码子。通过分析不同物种和已知基因的密码子偏好性,可以预测外源基因的最适宿主或者通过基因工程手段采用最优密码子,提高其在宿主中的表达水平[21]。
3.2 tRNA丰度
在一个蛋白质的翻译过程中需要和携带对应反密码子的tRNA相互识别作用,只有两者达到相互匹配,方可实现把游离的氨基酰-tRNA复合体中的氨基酸残基旋转到多肽延长链上,实现多肽链的连续延长。因而蛋白质能否合成的主要资源就是由这些对应的tRNA的丰度所直接决定的。对于高表达的基因所对应的密码子来说,具备了偏好性的密码子所相应tRNA的含量也是比较高的,其中是通过减少与对应的tRNA相匹配的时间去加快了翻译的速度。此外非最优密码子由于所对应的tRNA含量相对于比较低,通常情况下会容易发生配对错误,从而就增加了基因纠错的能量成本和时间。因此,细胞内对于tRNA的含量越高,其偏好程度较大;含量越低,偏好程度较小[26]。
3.3 基因长度
基因组的长度越长则其可以进行编码的主要氨基酸种类和密码子的数量也就越多。在完全没有其他压力的条件情况下,同义密码子被选择的概率不会因为受样本容量限制而出现统计上的误差;相对应的是该基因长度可能越短,正常容纳的密码子就越少,还有一些密码子可能不出现,因此基因长度会影响容纳密码子的数量,而使用偏好性与进化压力无关[27]。
3.4 蛋白质结构功能
基因密码子的使用与很多因素是密切相关的,其中就包含有一些基因中被编码的合成蛋白的功能和结构这个重要因素。另外,mRNA序列与蛋白质的折叠方式之间也是具有着一定的相关联性质的,尤其是密码子的使用概率与蛋白质的三级结构有着紧密的联系,因此不同物种的同样类型的基因可能拥有相近的密码子偏好性[28-29]。
4 密码子偏好性的研究方法
4.1 相对同义密码子使用度
相对同义密码子使用度(relative synonymous codon usage, 简称RSCU)这个概念(RSCU)是用来检测全基因中所有同义密码子使用模式的变化,其反映等同于基因样本中某同义密码子在实际中观测到的使用次数值与其在理论中平均使用期望次数的比值[30]。此计算方法在实际使用中是较为广泛的。相对同义密码子使用值给每个密码子分配一个表示这些密码子使用度偏离随机期望值程度的数值,因此在同义密码子使用频率同样的前提下,一个密码子的RSCU值可以看作是密码子实际使用的观测频率与其期望频率的比值。单个密码子数值被研究用作测量有密码子偏好性的基因的自适应度[15]。
在上述计算公式中,xij是编码第i个氨基酸的第j个密码子的出现次数;ni是编码第i个氨基酸的同义密码子的数量(范围是1-6)。当RSCU<1时,显示这个密码子实际使用时的频率,是远小于其他同义密码子的;但是出现RSCU>1时,则显示密码子的使用频率,是大于同义密码子的;而RSCU=1时,表明这个密码子是没有偏好性的[21]。
4.2 密码子相对适应度
密码子适应度值(codon adaptation index,简称CAI)是一种普遍使用的几何方法,用于衡量单个密码子的相对适应度值[30]。在使用这个方法时需开始计算出每一个密码子的相对适应度值wij,一个密码子的相对适应度值wij值是编码同种氨基酸密码子的观测频率与最频繁使用的密码子频率的比值,使用频率最高的密码子的计算需要一个高表达基因来集中作为参考的。CAI方法被普遍的用于各个方面生物学的研究,但在现有的测试基因集合中,某些密码子缺乏相应的参考基因集使得CAI值为0。并且CAI不适合应用在不同物种之间的密码子偏好性比较中,也因此有研究者提出了扩展的CAI方法[15]。
式中:密码子相对适应度为wij(Tthe relative adaptiveness of a codon)。RSCUimax指编码第i个氨基酸的使用频率最高的密码子的RSCU值。Ximax指编码第i个氨基酸的使用频率最高的密码子的X值。
4.3 ENC-plot 优先密码数绘图分析
有效密码子数 (effective number of codon,简称ENC) 指密码子偏离随机选择的程度,也是衡量同义密码子不均等使用偏好程度的关键性指标。通常对于高表达基因其偏好性比较大,是因为其含有稍少种类的稀有密码子,因此ENC的值就相对比较小; 低表达基因的密码子偏好程度较小,因而导致了ENC取值比较大[31]。
这种分析方法主要是以GC3为横向坐标,ENC为纵向坐标而制作坐标图。其运用检测碱基组成对密码子偏好性的主要影响,在绘图中密码子偏好性是指通过碱基组成决定了基因位置所对应的标准曲线,具体计算方法和示意图如下:
如图1所示,基因位于某一条特定标准长度曲线附近或沿着一条标准长度曲线的某个方向进行分布,表示该基因的密码子偏好性只可能会直接受到突变的影响,而基因位于一条标准长度曲线下方较远的方位,就可以说明这一基因的密码子偏好性已经受自然选择的影响。

图1 ENC-GC3绘图
4.4 PR2-plot绘图分析
PR2-plot绘图分析 (PR2-bias plot analysis),PR2偏倚分析主要目的是为了有效避免密码子的第3位碱基腺嘌呤A与胸腺嘧啶 T以及胞嘧啶 C与鸟嘌呤 G之间的线性突变不平衡。根据偏倚规则PR2,假如这两条互补链之间不存在选择效应上的偏倚或任何突变,则碱基含量就具备A=T及C=G。分别分析这些碱基计算出基因A3/(A3 +T3)和G3/(G3 +C3),用其作纵向的坐标和横向的坐标来进行作图,其中A=T且C=G作为中心点,余下的点由这个点为中心点向单位点发出的矢量分别代表其基因的方向及偏倚程度[32]。如图2所示:
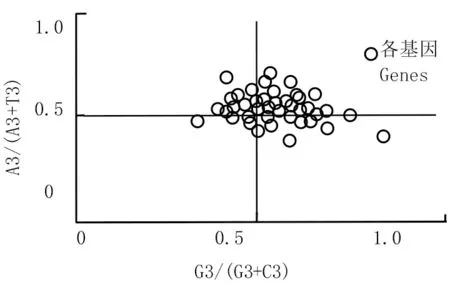
图2 PR2-plot分析
4.5 中性绘图分析
对于中性绘图的分析方法就是以得到GC12为一条线的纵向坐标,以得到GC3为一条线的横向坐标后再进行作图。通过对密码子第1、2位和第3位碱基组成的相关性进行分析,研究对密码子偏好性产生直接影响的主要因素。当GC12与GC3之间有显著相关时,可以表示3个不同位置上的碱基组成没有大的区别,应用密码子会被突变所影响。当GC12以及GC3的基因相关性差异不显著时,回归系数非常接近0,就可以表示第1、2位以及第3位的碱基组成不同,应用密码子较多的会被选择因素影响[33]。
如例图3所示,GC1和GC2的平均值表示的是GC12,密码子3个不同位置的GC含量分别表示为GC1、GC2和GC3。

图3 中性绘图分析
4.6 对应性分析
对应关系分析(correspondence analysis,简称CA)是用于分析基因间的同义密码子在研究中的使用偏好产生的主要原因的一种方法,这种方法在研究中普遍使用[22]。CA从一个多维空间中获得最具影响的方向或轴。通过对于CA轴分离得到的各种基因之间的相关关系进行分析,可以准确地识别和判断其偏好性产生的主要原因[15]。
通过分析变量之间的关系这一种多元相依的分析方法,就能发现不同变量各类别当中的对应关系,和同一变量类别中的差异。根据运用RSCU值进行的对应性分析,将每个样本中所有基因区别分布在一个58维的向量空间中,运用CodonW软件会使当中每个点就代表一个同义密码子。如图4所示,各点之间的位置可以表现出对于密码子的用法偏好。第1轴呈现最大差异的密码子使用变化,而副轴改变量是逐步下降的。将差异最大的第1、第2轴作为横纵向坐标作图,图中不同基因可以用不同点来表示,点的散布位置可以确定出密码子的使用偏好性[34]。
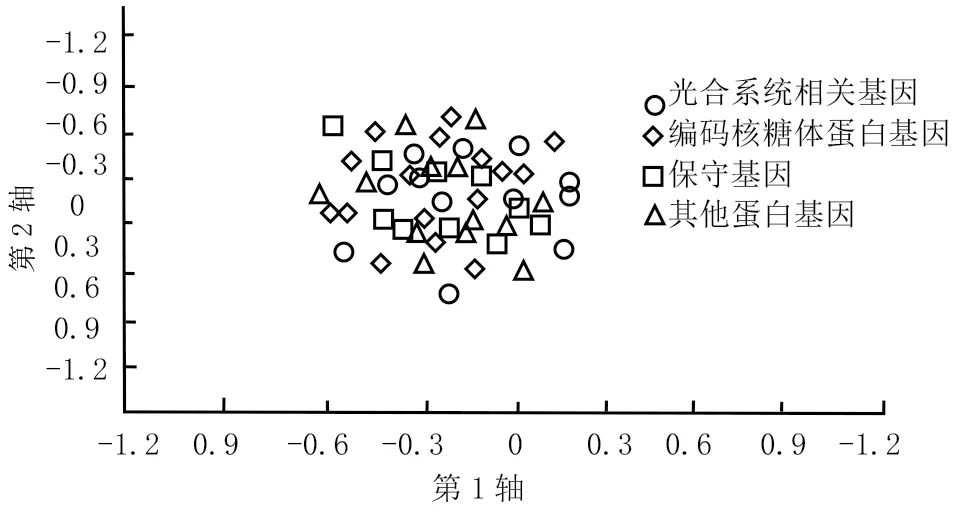
图4 对应性分析
4.7 最优密码子
最优密码子(frequency of optimal codons,简称FOC)使用频率(FOP)定义为在某物种高表达基因中使用频率最高的密码子。FOP是种特异性的, 都需要通过一组基因序列以及其相对应的表达信息来确定最优密码子[21]。
采用这种优越高表达的分析方法确定最优密码子,一般最开始需要通过计算方法得出所有表达基因的RSCU值和ENC值,然后再对其数值进行序列排序,取得前1 764个和后1 764个的基因数据,分别各占5%,然后形成高表达组和低表达组。
计算公式为:
ΔRSCU=RSCUhigh expression genes-RSCUlow expression genes
比较2个组的数值,当两者的RSCU差值>0.3,且在高表达组中RSCU>1,在低表达组中RSCU<1,即可得出判断该密码子为最优密码子,并通过计算最优密码子数目与总密码子数目的比例,所得到的结果是最优密码子使用频率[23]。
4.8 密码子偏差系数
密码子偏差系数(codon deviation coefficient,简称CDC)是通过考虑不相同位置下的背景核苷酸组成而对密码子偏好性分析估计的[35]。这种方法是不须进行参考基因前期实证知识来对偏好性进行量化的一种方法。CDC用嘌呤含量和GC含量来推演出氨基酸和密码子的组分,因而可以设计出相关的组分模型,并通过这种算法而量化密码子偏好性。与之前的方法不同,此方法充分考虑了各个序列的组分特异性,并用抽样的方法检测相关的显著性。
4.9 其它研究方法
此外,还有一些关于聚类的方法比如:聚类分析,主成分分析及相关的模糊统计学法也被用于进行分析密码子偏好性[36]。受基因表达水平或翻译效率影响的密码子偏好性程度,可通过使用同义密码子使用偏好性最大似然估计(SCUMBLE)这种方法进行量化,此方法是在分析密码子偏好时运用最大似然估计,而进行计算出密码子使用频率的似然值。虽然SCUMBLE和CA的方法对于识别密码子偏好性成因方面是有用的,但并不是最理想的方法去应用于量化密码子偏好性的个别物种[15]。
对于以上出现的密码子偏好性分析方法原理和估计过程的介绍,可以得出现如今的研究分析方法有很多种不同方向和角度,各有特色, 但也存在不足。可以根据不同的情况进行选择, 在使用时需要注意不同方法之间的区别以及侧重点,才能有效的分析数据。
5 用于分析密码子偏好性的软件及工具
目前已经有一部分用于分析密码子偏好性的工具,如 CodonExplorer、CodonW 可计算用户输入序列数据的CAI值,用SCUO公式可对基因组密码子偏好性进行比较,用 CodonO 能分析单个基因的密码子使用偏好性[15],此外,还有部分数据库被用于去分析密码子的偏好性。关于量化密码子偏好性的方法有很多种可通过计算机程序计算,有的是通过网站的形式可以在线分析数据。不同的研究方法都有各自的优点和缺点,使用的时候应该对这些软件和方法充分的分析,选择合适的方法分析需要解决的问题以及情况,以便于获得期望的效果。
