基于特征增强的对抗哈希跨模态检索*
2022-10-09卢光云
何 沛,王 萌,王 卓,卢光云
(1.广西科技大学理学院,广西柳州 545000;2.广西科技大学数字启迪学院,广西柳州 545000;3.柳州工学院,广西柳州 545616)
随着多媒体技术的发展,网络上每天都会产生大量的多媒体数据。由于不同类型的数据表现形式不同,如何使用一种类型的数据去灵活检索其他不同类型但包含了相同对象的数据成为了一个巨大的挑战。
不同模态的特征投影具有异质性差异,跨模态哈希方法通过将其映射到同一汉明空间去度量其相似性,是当前最普遍的跨模态方法之一。其中比较关键的一步是如何提取具有代表性的特征。早期哈希方法一般是根据数据集来手工设计特征[1,2],此类方法泛化性较差,导致其在实际应用中无法达到较好的检索性能。深度学习的发展带来了更优秀的特征提取方式,近年来出现了很多深度跨模态哈希(Deep Cross-Modal Hashing,DCMH)方法[3-5],其中包括很多具有代表性的方法[6,7]。比如,深度跨模态哈希方法[6]将特征学习和哈希码学习集成到同一个框架中,用端到端的深度神经网络将不同模态的数据变换到一个公共空间来实现跨模态检索,但是这些深度跨模态哈希方法依旧存在许多需要解决的问题。首先,许多哈希方法在从特征提取到生成哈希码的过程中使用了深度网络,在这个过程中可能会丢失部分语义信息,如何增强哈希码中包含的特征信息是一个需要解决的问题。其次,不同模态的数据具有异质性差异,如何更好地弥合异质性差异,也是值得注意的一点。另外,许多哈希方法都在更加有效地利用标签信息,使得数据中的语义信息能够被充分利用。
针对以上问题,本文提出了一种特征增强对抗跨模态哈希(Feature Boosting Adversarial Hashing for Cross-Modal,FBAH)方法,采用子空间学习和对抗学习相结合的方式来学习特征表示和哈希码。首先,受到JFSSL方法[8]的启发,选择网络末端的哈希空间作为子空间,利用线性网络去学习投影矩阵,将不同模态的特征映射到哈希空间,通过最小化差异来保持特征表示在不同模态间的分布一致性。其次,受到残差网络[9]和一些语义增强策略[10]的启发,FBAH方法构造了一种类残差结构来实现特征增强,使得后续生成的哈希码包含更多语义信息。此外,为了保证能够生成高质量的哈希码,在哈希空间通过对抗学习来保证不同模态哈希码的一致性,引入余弦三元组约束[11]来保证特征间的相似性以及可区分性,采用一个带有分支的线性分类器进行两个维度的标签判别,以保证模态内语义不变性。
1 相关工作
子空间学习是跨模态检索方法的主流方法之一,其核心是将不同模态的数据映射到一个公共子空间来进行特征学习。近些年来,出现了很多基于子空间学习的跨模态方法,比如典型相关分析(CCA)[12]、偏最小二乘(PLS)[13]等方法。这些方法力求寻找一个合适的子空间[8,13],比如具有标签信息的标签空间[8]或者将图像模态映射到文本模态之中[14],通过映射到同一空间来减少不同模态数据的异质性差异。不同于上述子空间方法,本文尝试选择哈希空间作为子空间。哈希空间可以包含文本和图像的特征信息,通过子空间学习能够使不同模态的特征表示尽可能近似,以便进行跨模态检索。
解决不同模态数据的异质性是跨模态检索中的核心问题之一。对抗性跨模态检索(Adversarial Cross-Modal Retrieval,ACMR)[15]首次将对抗学习思想引入到跨模态检索之中,通过构建特征投影器和模态分类器来进行对抗学习,去尝试解决模态间数据的异质性,当模态分类器无法分辨特征投影器输入特征的归属模态时,则训练结束。因为对抗学习的有效性,Li等[16]也尝试利用对抗学习来解决跨模态哈希问题。自监督对抗哈希(Self-Supervised Adversarial Hashing,SSAH)将自监督语义学习与对抗学习相结合,利用语义信息和不同模态子网络输出特征的对抗过程,来实现自监督过程,最终达到提升跨模态检索精度的目的。Bai等[17]也在深度对抗离散哈希(Deep Adversarial Discrete Hashing,DADH)中,将对抗学习同时应用于特征学习模块和哈希学习模块之中,进行两次对抗学习,来保证跨模态特征表示的分布一致性。研究表明,通过充分利用对抗学习可以有效地弥合异质性差异[18]。本文将对抗学习引入哈希空间,来保证模态间数据的一致性。
相对于无监督的跨模态检索方法[19,20],有监督的跨模态方法[11,17,20]能够利用标签信息来区分具有不同语义的特征,并保证具有相同语义特征的结构不变,来进一步提高检索性能。比如,Gu等[11]提出的对抗引导非对称哈希(Adversary Guided Asymmetric Hashing for Cross-Modal Retrieval,AGAH)方法,采用对抗学习引导的多标签注意模块去学习特征表示,并且利用多标签二进制码映射,使哈希码具有多标签语义信息,获得了很好的检索效果。Zhen等[21]提出的深度监督跨模态检索(Deep Supervised Cross-modal Retrieval,DSCMR),通过线性分类器预测并判别投影特征的语义类别,来保证特征投影的语义结构不变,并根据语义对特征投影的余弦距离进行放缩,来提高特征间的辨识度。不同于一般有监督的哈希方法,本文使用带有分支的线性分类器进行标签预测,从两个维度实现模态内的语义保持。
2 FBAH模型
2.1 问题定义

2.2 FBAH方法的框架
FBAH方法的整体框架如图1所示,可以分为特征学习和哈希学习两个部分。

图1 FBAH方法的框架
在特征学习部分,首先对输入的原始高维图像特征X和文本特征Y进行子空间学习。在保持哈希码与高维特征一致性的同时,通过稀疏投影矩阵选择其中具有较大区分度的特征和my。主网络则将两种高维特征通过3层全连接层和1个哈希层将高维特征映射到哈希空间。
在哈希学习部分,首先将通过主网络输出的低维特征fX和fY与通过特征选择投影过来的特征信息mX和mY结合,形成被增强的特征hX和hY。为了生成二进制码的一致性,引入对抗学习来消除模态间的异质性差异。然后,采用带有分支的线性分类器,通过两种维度预测并判别标签信息,来保证模态内语义的一致性。最后,引入余弦三元组约束来保证哈希空间中相同语义特征的相似性以及不同语义特征的区分性。
2.3 特征增强与子空间学习
首先使用在ImageNet上预训练好的CNN-F模型[22]提取原始图片的4 096维高维特征,然后将3个全连接层和1个哈希层作为图像特征学习的主网络,将高维特征映射到哈希空间。对于文本特征,使用Bow模型提取原始高维文本特征,同样使用3层全连接与1个哈希层作为文本特征学习的主网络。函数fX=FX(X;θX)和fY=FY(Y;θY)分别表示图像和文本的特征投影。其中fX和fY分别表示图像和文本主网络的输出,θX和θY是两个函数的参数。如图2所示,本节可以分为子空间学习和特征增强两个模块。

图2 特征增强与子空间学习
2.3.1 子空间学习
为了缩小不同模态数据的异质性以及保证最终所产生的哈希码与原始特征具有一致性,FBAH方法选择将最终生成的统一哈希码所在的空间作为一个哈希子空间。接下来,学习每个模态的投影矩阵,将不同模态的数据映射到哈希子空间。在哈希子空间中,可以测量不同模态数据与最终生成哈希码的相似性。也就是说,这是一个最小化问题,将不同模态数据映射到哈希空间的投影矩阵的目标函数定义
如下:
(1)
其中,B是哈希子空间中的哈希码,Ux和Uy分别是图像模态和文本模态的投影矩阵。随着哈希码的不断更新,哈希子空间也会随之更新。哈希子空间学习使得模态间异质性缩小,生成质量更高的哈希码,而高质量的哈希码也会生成更好的哈希子空间,二者形成一个良性循环。
2.3.2 特征增强
经过主体网络的非线性变换,语义信息不可避免地会出现一部分丢失,为了解决这个问题,FBAH方法通过两步去解决。首先,采用L21范数获得稀疏的投影矩阵,同时对不同的特征空间起到特征选择的作用[8]。
方程(1)中的目标函数可以进一步写成
(2)
其中,μ1和μ2用来控制矩阵稀疏性参数。
接下来,需要考虑的是如何将选择出来的有区分度的特征融合进主网络输出的特征之中。受到Resnet方法[9]的启发,本文设计了一个类残差结构,FBAH方法将全连接层和哈希层视为一个主网络,将通过稀疏投影矩阵筛选出来的特征与主网络生成的低维特征融合,来达到特征增强的目的。
2.4 哈希学习
经过特征增强后的特征记为h*=f*+σm*,*∈(X,Y),哈希码通过sign函数生成:BX=sign(hX),BY=sign(hY),其中信号函数被定义为
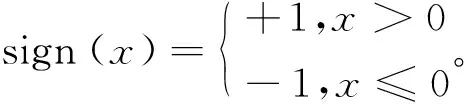
(3)
同时,为了在模态间生成一致的哈希码,获得一个包含文本和图像两个模态信息的哈希子空间,引入B=BX=BY,其中,B=sign(hX+hY)。最后通过最小化量化损失来保证哈希码与h*的一致性,量化损失Lq被定义为
(4)
高质量的哈希码应该保证模态内部的判别性和模态间的一致性。接下来采用3个损失函数对哈希码进行约束。
2.4.1 对抗学习
为了消除不同模态增强后特征投影之间的异质性,FBAH方法选择引入对抗学习。在对抗学习过程中,构建一个由3层前馈神经网络构成的判别器D。将一个未知特征投影输入判别器D,D会尝试去区分输入特征投影的模态种类,即尽可能去区分输入的特征投影来自图像模态还是文本模态。同时两种来自不同模态的特征投影则尽可能去混淆判别器D,即使其无法判别输入特征所归属的模态种类。将对抗性损失定义为Ladv,即
(5)

2.4.2 双重标签预测
通过双重标签预测来保证模态内不同样本特征具有语义区分性。在图像和文本模态主网络的末端连接一个带有Softmax函数分支的线性分类器,该分类器会在公共空间中为每一个样本生成两种不同维度的c维预测标签向量。
其中,分类器生成的标签投影矩阵与真实标签的误差可以被定义为
(6)
其中,‖ ‖是Frobenius范数,P是线性分类器的投影矩阵。
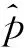
(7)
总的标签预测损失为Ll=η1Ll1+η2Ll2。
2.4.3 余弦三元组损失
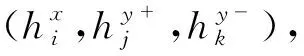
(8)
同样地,文本模态的余弦三元组损失被定义为
(9)
其中,m为边缘参数。
2.5 优化
优化的总体目标函数为
γLadv,s.t.B*∈{-1,1}N×K,
(10)
其中,参数θ是主体网络的参数,θX和θY是参数θ的一部分,分别表示图像模态和文本模态网络的参数;θD是对抗网络的参数;P代表标签预测分类器的参数;U表示稀疏投影矩阵的参数,UX和UY是参数U的一部分,分别表示图像模态和文本模态网络的参数。本文采用Adam优化算法[23]来优化总体目标函数,优化过程的细节在以下算法中总结。
算法FBAH模型的算法
输入:图片集合X,文本集合Y,标签集合L;
输出:网络参数θ,判别器参数θD,线性分类器参数P,稀疏投影矩阵U和二进制码B。
①初始化参数和二进制码B;
② 重复
③ fortiteration do
④ 通过后向传播算法更新参数θD:
⑤ 通过后向传播算法更新参数P:
⑥ 通过后向传播算法更新U:
⑦ 通过后向传播算法更新θ:
⑧ end for
⑨ end
⑩ 通过(4)更新B
3 验证实验
采用MIRFlickr25K[24]和NUSWIDE[25]两个被广泛应用于跨模态检索任务中的数据集进行实验,来验证FBAH方法的有效性。实验在PyTorch环境使用 GeForce RTX 2080 Ti GPU进行,batch_size设定为128,学习率为5e-5,η1=1.5e+3,η1=1.5e+4,β=γ=1。
3.1 数据集及评价标准
MIRFlickr25K数据集[24]包含24个类别,共计25 000个图像-文本对。其中每个实例最少具有1个标签。在实验中,笔者选择的20 015个实例至少有20个文本标签。文本模态中的每个实例被表示为1 386维的词袋向量(BOW)。本文的测试集为2 000幅图像-文本对,均为从MIRFlickr25K数据集中随机选择。另外,本文将其余的样本作为检索数据库,然后将从中随机抽取的10 000个实例作为训练集。
NUSWIDE数据集[25]包含81个类别,共有269 648个图像,每张图片均带有相关的文本描述。每个实例至少有1个标签。与AGAH方法[11]一致,本文选择了包含最多样本的21个类别,共195 834个图像-文本对。本文的测试集包含2 100个图像-文本对,均为从数据集中随机抽取。另外,本文将其余的样本作为检索数据库,并从中随机抽取10 000个实例作为训练集。其中,每个实例的文本用1 000维词袋向量表示。
评价标准:本文采用跨模态检索中广泛应用的两个指标作为评价标准。
平均查准率均值(mean Average Precision,
mAP):对查询样本和所有返回的检索样本之间进行余弦相似度的计算,综合考虑了排序信息和精度。
基线:与7种当前先进的哈希方法作比较,包括SePH[26]、DCMH[6]、PRDH[7]、CHN[27]、SSAH[16]、AGAH[11]、DADH[17]。
3.2 对比实验
详细实验结果见表1和表2,FBAH方法在这两个数据集上的mAP值明显优于所比较的哈希方法,这证实了它的跨模态检索的有效性。

表1 不同编码长度下在MIRFlickr25K数据集上的mAP比较

表2 不同编码长度下在NUSWIDE数据集上的mAP比较
在MIRFlickr25K数据集上,对于Image2Text任务,FBAH比其他方法中表现最好的方法在16 bit、32 bit、64 bit 3种不同的哈希码位数上,分别提升了1.14%、2.31%和2.26%;对于Text2Image任务,FBAH方法则分别提升了1.08%、2.40%和2.63%。总体而言,随着哈希码位数的增加,FBAH方法的检索效果也随之增加,这可能是因为较长的哈希码能够容纳更多的特征信息。
FBAH方法在NUSWIDE数据集上的mAP值有明显的提升,对于Image2Text任务,在16 bit、32 bit、64 bit 3种不同的哈希码位数上,FBAH方法分别提升了3.93%、2.59%和3.11%,对于Text2Image任务在则分别提升了5.67%、4.83%和4.83%。总体而言,FBAH方法在NUS-WIDE数据集上有着更显著的提升。另外,在哈希码为16 bit和64 bit上的提升大于32 bit。可能是其他方法的哈希码在16 bit时,由于不能容纳足够的有效信息导致哈希码质量不高。同样地,在更长的64 bit位时,其他方法因为哈希码包含的特征信息稀疏而导致哈希码质量不高,而FBAH方法可以在不同位数时都生成较高质量的哈希码。
3.3 消融实验
为了验证FBAH模型各个模块的有效性,设计了4个消融实验来进行验证:(a)FBAH-1表示不进行特征筛选,但保留类残差结构,将未经筛选的特征与主网络输出的特征进行融合。(b)FBAH-2表示不进行特征增强,即去掉类残差结构。(c)FBAH-3表示去掉标签分类器。(d)FBAH-4表示去掉特征学习部分子空间学习的损失。
表3展示了4个消融实验的结果。对于FBAH-1来说,去掉特征筛选,导致许多无关信息被融合进新的特征之中,所以精度会有所下滑。FBAH-2的结果说明了设计的特征增强模块的有效性。FBAH-3的结果表明,去掉标签预测模块,可能会导致部分特征与标签无法对齐,使精度有所下滑。而FBAH-4的结果则说明了以哈希码构筑的子空间学习的有效性。

表3 64位哈希码下消融实验中mAP结果对比
4 结论
本文提出了一种新的跨模态哈希方法,被称为特征增强对抗跨模态哈希(Feature Boosting Adversarial Hashing for Cross-Modal,FBAH)方法。FBAH方法不仅可以消除模态间的异质性差异,还能够通过特征增强来弥补主网络造成的特征损失。笔者将包含了文本和图像两个模态信息的哈希子空间作为一个学习对象进行子空间学习,在减少模态间差异的同时,还能够使得生成的哈希码与高维特征的相似度更高。此外,笔者设计了一个类残差结构去弥补特征在深度网络中损失的信息,使得提升后的特征包含更多高维信息。为了生成高质量的哈希码,使用3种约束来保证生成哈希码模态间的一致性、模态内的判别性以及项目间的相似性。在两个基准数据集上进行验证,结果表明,在跨模态检索任务中,FBAH方法优于当前7种先进的方法(表2)。当然,本文还存在一些尚待改善的部分,比如特征融合和特征提取的方法尚待完善,后续将采取效果更好的特征提取和特征融合方式来提升精度、完善方法。
