一种面向深度信念网络的故障诊断加速方法
2022-10-09宋旭东杨杰陈艺琳
宋旭东,杨杰,陈艺琳
(大连交通大学 计算机与通信工程学院,辽宁 大连 116028)
随着新型传感技术和智能制造的发展,现代机械设备可以实时采集到大量的反应机械运行状态的数据,利用这些实时采集的状态数据和基于数据驱动的机器学习方法等人工智能方法可以有效对机械设备运行状态及其故障进行诊断.由于可能存在的设备故障呈现出多源异构性、海量性、多样性等特点,对于故障诊断的鲁棒性、实时性、泛化能力等方面提出了更高要求.大量实验表明,与传统机器学习方法相比,深度学习(Deep Learning,DL)具有更强大的特征提取、数据压缩、故障分类等能力,而且不需要过多的专业知识和人工干预,最大程度地减小了故障诊断的难度.近些年来的研究成果表明,以深度学习为代表的故障识别技术,极大丰富了故障诊断的技术,进而保证机械设备的正常运行[1-2].
深度信念网络(Deep Belief Network,DBN)是深度学习中最为代表的一类深度学习神经网络,它是在受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)的基础上设计出的一种无监督逐层训练算法,能够实现数据特征的有效表达,有效实现模式识别[3-4].DBN具有两个很大的优点,它们很有吸引力并且适用于故障诊断.首先,DBN可以近似任何连续函数,可用于建模和控制多变量非线性系统[5-8].其次,DBN是非参数数据驱动的模型,它不需要对生成数据的基础过程进行限制性假设.因此,DBN可以准确有效地识别振动信号,判断滚动轴承早期的故障特征[9-10].
虽然现有的各种深度信念网络学习模型可以通过大量的训练得到有效的故障诊断结果,但是许多计算模型在进行训练时具有计算复杂度高、训练时间长等问题.现有的解决该问题的方法一般是特征提取或者数据降维等数据预处理方法,但这种方法本质上是通过减缩数据量来达到效率提升的目的,这种方法在数据减缩的同时也同样会存在部分数据特征的丢失,进而影响故障诊断的准确率.本文提出一种通过修改模型本身的损失函数来减少计算量、加快训练、提升效率的方法,同时提出的方法不会降低故障诊断的准确率.
1 深度信念网络模型
深度信念网络模型结构如图1所示,它是一种概率生成模型,由多个受限玻尔兹曼机RBM堆叠而成.网络模型结构的最下层是输入层,最上层是输出层.从输入层到输出层,可包括多个相邻层的RBM层和一个BP层.
图1 深度信念网络模型结构
深度信念网络模型训练过程包含两部分:一是使用贪心无监督方法逐层构建网络,由低层到高层的前向RBM逐层学习;二是基于反向传播的BP层监督学习,在BP层完成后向微调学习.
2 提出的故障诊断加速方法
为加速深度信念网络模型训练,本文构造的指数损失函数如下:
(1)
这里,选用均方误差损失函数作为基本损失函数,式中Y是标签,DN是输出层的节点个数,hN是模型的输出.
用于深度信念网络模型训练的代价函数的梯度计算可表示如下:
(2)
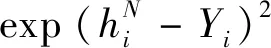
由此,本文构造的新代价函数可以获得更大的梯度来达到加速模型训练速度的效果.
提出的新的深度信念网络故障诊断加速模型训练的流程如下:
输入:数据集X,标签集Y
隐藏层h,层数N,每一层的单元个数D1,D2,…,DN,迭代次数Q1,Q2
参数空间W={w1,w2,…,wN},偏置a、b,冲量θ,学习率η
标注数据的个数L,未标注数据的个数U
输出:包含训练后参数空间的DBN网络
处理:
(1)使用贪心无监督方法逐层构建网络
fork=1;k fori=1;i forj=1;j 计算非线性正向和反向状态 CD算法更新权重和偏置 (2)基于反向传播的监督学习 计算代价函数并反向微调网络参数以寻找模型最优解 fori=1;i 损失函数: 目标函数: θ*=arg minθL(f(X;θ)) NAG算法更新权重: 为验证本文提出的故障诊断加速方法,选用美国凯斯西储大学提供的轴承故障数据集[11].该数据集是世界公认的轴承故障诊断标准数据集.提供的数据集包括了正常、滚动体、内圈和外圈等4种不同轴承部位状态;对于不同部位又分别提供了0.018、0.036和0.053 mm三种直径尺寸故障;同时包括四种工 作 负 载1、2和3hp, 转速为C=1 797、1 772、1 750、1 730 r/min. 为了便于提高训练速度和分类精度,对每段信号均做标准归一化处理,标准归一化处理如式(3)所示: NewX=(X-mean)/std (3) 式中,X为信号数据集,mean为其均值,std为其标准差.NewX是得到的标准归一化数据,其均值为0,标准差为1,符合标准正态分布. 本文实验是基于Python语言,采用以WTensorFlow为底层代码实现,计算机硬件基本配置为i7-8750H处理器,8GB内存,Windows系统. 设定输入端节点数为800,为了便于学习和减少计算量,本文使用的两层隐藏层节点数为500、500,输出端为10.小批量mini-batch的大小设置为50,学习因子设置为0.01,每个RBM的预训练次数为2.使用动量(Momentum)的随机梯度下降法加速训练过程,动量因子设置为0.9.对于数据集A、B和C,训练次数上限15 000次.由于神经网络的初值是随机的,为了验证每次训练结果的可靠性,对于每个数据集,多次测试,取其最接近平均值的单次训练作对比,如图2所示. 图2 加速前后故障诊断模型训练过程对比图 从图中可以看出,改进后的模型具有明显的加速效果,使用更少的训练次数就可以到达很高的分类准确率.并且因为计算复杂度与迭代次数成正比,实际模型获得稳定的故障诊断结果所需的训练时间不到改进前模型所需时间的一半.并且加速后的模型在整个训练过程中训练集和测试集的最大差值不超过0.035,具有良好的泛化能力. 图3 改进前故障诊断模型训练过程可视化图 图4 改进后故障诊断模型训练过程可视化图 为了更好地理解训练数据的效果,本文利用T-sne可视化技术展示部分实验结果.图3、图4显示了由迭代次数下的训练样本训练的DBN模型中测试样本的最后一个隐藏层表示. 从图3、图4可以看出,大约在迭代1 800次左右,改进后的模型就可以达到稳定的高分类正确率,而原始模型需要大约迭代4 000次才能得到稳定的高分类正确率.在不同的迭代次数下,改进后的模型可以更快地获得明显的区分、更好的故障诊断准确率,这使得模型可以更快地得到很好的诊断故障类别. 本文提出了一种面向深度信念网络故障诊断加速方法,通过模型实验表明提出的DBN故障诊断加速方法的实验结果十分稳定,均能在迭代2 000次以内获得最大的分类准确率.比原有效果提升了一半以上的效率.并且分类结果清晰,不同的故障诊断类型间具有较大的分类间隔,不容易出现误判.实验说明了本文提出的模型训练加速方法具有更快、更强的寻优能力,具有一定实际意义和应用价值.3 实验验证
3.1 加速前后故障诊断对比实验

3.2 加速前后故障诊断的可视化分析
4 结论
