分数阶微分预处理及PCA-SRDA的多模型融合对红富士苹果产地溯源
2022-10-09南梦迪李政浩陈秋颖李廷杰郭俊先
黄 华,南梦迪,李政浩,陈秋颖,李廷杰,郭俊先
1.新疆农业大学数理学院,新疆 乌鲁木齐 830052 2.新疆农业大学机电工程学院,新疆 乌鲁木齐 830052
引 言
我国是世界上最大的苹果栽培国家,也是产量最多的国家。据《2021年中国苹果行业分析报告》显示,2019年—2020年度,我国苹果产量约4 266万吨。在众多苹果品种中,红富士具有体积大,遍体通红,形状圆,果肉紧密,口感甜美、清脆等主要特点,备受消费者的广泛喜爱。红富士苹果多产于山东、甘肃、陕西、山西、河北、辽宁、河南、新疆等地,因受到环境、气候等众多外界因素影响,不同产地的红富士苹果主要成分含量存在差异,苹果的口感、水分、糖分等也存在明显的差别[1],市场价格也随之不同。因此,从市场和消费者的需求出发,探索一种简单、快捷、无损的识别算法实现苹果产地溯源具有重要的应用价值和现实意义。
近红外光谱技术作为一种高效、快速的现代分析技术,随着计算机技术、光谱技术和化学计量学的不断发展,其以独特的优势在农业、化工、制药、石油等领域得到日益广泛的应用[2-5]。Zhang等运用近红外光谱及偏最小二乘回归对8个苹果品种的可溶性固形物和果实干物质含量进行无损预测[6];马永杰等基于深度学习数据降维方法,结合近红外透射光谱研究了苹果产地溯源问题[7]。然而,在近红外光谱的实际应用中,采集的近红外光谱原始数据往往是高维的、复杂的,并且存在大量冗余信息和噪声,通常会面临光谱数据预处理、光谱数据的特征提取和特征选择、高精度的回归或判别模型建立等关键核心问题[8-9]。基于此,许多学者进行了广泛的研究。赵启东等将分数阶微分(fractional differential,FD)技术分别与极限学习机、随机森林、多元自适应回归样条函数、弹性网络回归和梯度提升回归树相结合,实现土壤有机碳含量的估算。结果表明,FD的预处理效果优于整数阶微分[10]。通常情况下,FD预处理除了能消除干扰、突出谱线的差别、增强信息量外,还可以挖掘光谱数据的FD层面信息,有助于提高模型精度。杨璐等利用红外光谱结合主成分分析(principal component analysis,PCA)-线性判别分析(linear discriminant analysis,LDA),构建胶料种类判别模型,并对嘉峪关戏台文物胶料种类进行判别,其模型稳定有效[11];Wu等利用PCA和核fisher判别分析结合近红外光谱分析对苹果进行分级[12];Lv等提出一种基于近红外光谱和PLS-DA鉴别阿克苏红富士苹果品种[13]。PCA作为一种无监督算法,在实现降维的过程中能尽可能多的保留方差信息,原始数据信息损失较少。LDA作为一种有监督算法,也可用于数据降维,但是会面临复杂的广义特征分解问题,特别是当样本量和变量指标过大时,LDA算法的计算量和内存占用较大。Gui在LDA算法的基础上,基于谱图分析理论和回归模型提出了谱回归判别分析(spectral regression discriminant analysis,SRDA)算法,极大地简化了计算过程[14]。在光谱数据建模过程中,除了研究预处理技术、特征提取和特征选择算法外,基于模型融合、集成学习思路建立高精度的回归或判别模型也是建模研究的重点。已有研究预示利用近红外光谱,结合分数阶微分技术及PCA,LDA和SRDA算法可应用于苹果产地溯源,但是利用近红外透射光谱,基于分数阶微分技术及PCA-SRDA进行多模型融合构建集成学习模型,实现红富士苹果产地溯源的研究还未有相关报道。
因此,以红富士品种为研究对象,以新疆阿克苏、山东烟台、陕西洛川三个产地的红富士苹果为试验对象,利用近红外透射光谱,基于分数阶微分技术及PCA-SRDA进行多模型融合,构建红富士苹果产地溯源的集成学习模型,以期为苹果产地溯源的实际应用提供新思路。
1 实验部分
1.1 材料
本试验选取三个产地的红富士苹果,包括新疆阿克苏(产地经纬度:80°29′E,41°15′N)、山东烟台(产地经纬度:121°20′E,37°33′N)、陕西洛川(产地经纬度:109°42′E,35°76′N)。苹果试材于2019年1月6日和10日分两批购买于新疆乌鲁木齐市北园春水果批发市场。由经验丰富的果商对同批次同品牌苹果拆箱挑选大小适中、尺寸均匀、无明显损伤的苹果,套网套并打包装箱转运回无损检测实验室,然后开箱平铺、室温20 ℃静置 24 h,擦净苹果表面浮土并逐个编号,共671个,其中,新疆阿克苏红富士苹果241个,山东烟台红富士苹果215个,陕西洛川红富士苹果215个。
1.2 设备
近红外透射光谱采集系统由苹果托架、配备小型风扇的光源套件(JCR12V 100 W 卤钨灯)、近红外光谱仪(美国海洋光学公司,USB 2000+型)、大芯径双包层石英光纤(SMA905接口)、铝合金机架、暗箱与计算机等组成。光纤探头一端连接光谱仪,另一端固定在苹果托架圆心正下方,实现对近红外透射光谱的高效采集。数据分析用MATLAB 2019b软件。
1.3 方法
1.3.1 光谱采集及校正
近红外透射光谱数据采集由配套软件美国海洋光学公司USB 2000+型近红外光谱仪实现,使用前开机预热1 h,之后通过测试采样设置 SpectraSuite 软件界面参数,最后确定样本光谱采集参数为:平均次数3;平滑度5;积分时间 120 ms;波段数512(波长范围:590~1 250 nm)。采集光谱时,将苹果置于光谱采集仪器的果托上,苹果与果托之间不留光缝,确保光纤接收光信号的点完全屏蔽光源,使其只能接收到透过苹果的光。待软件界面显示的光谱稳定后,保存光谱;然后将苹果分别顺时针旋转120°两次,并分别采集光谱,最后将其平均光谱作为该样本的原始光谱。共采集671个苹果的近红外透射光谱信息。同时,为了消除因USB2000+光纤光谱仪预热不充分,导致暗光谱发生微小变化所产生的试验误差,每测量10个样本就需保存一次该时刻的暗光谱,用于后续光谱校正。
因苹果形状差异、摄像头中的暗电流噪声等会对苹果近红外透射光谱数据产生噪声影响,因此,采集原始光谱后,对获得的近红外透射光谱进行校正[7]。
1.3.2 分数阶微分技术
分数阶微分是由整数阶微分直接扩展而来的,它的定义包括Cauchy积分公式、Grünwald-Letnikov分数阶微积分定义、Riemann-Liouville分数阶微积分定义和Capotu定义等。本研究采用的是Grünwald-Letnikov分数阶微积分定义。根据该定义,可利用分数阶微分的数值近似求解公式进行计算,实现光谱数据的分数阶微分预处理[14]。
1.3.3 谱回归判别分析
SRDA是在LDA算法的基础上,基于谱图分析理论和回归模型提出的,可用于有监督、半监督和无监督学习。其主要思想是通过类别标签或无类别标签的数据点来构建连接图,基于连接图可表征数据集内部的判别式结构,还可获得类别标签或无类别标签的数据点的学习响应,根据学习响应,利用回归模型可得嵌入函数,而通过向嵌入函数投影,则可以实现数据的降维。相比LDA算法,SRDA算法在计算量和内存占用方面更具优势。
1.3.4 多模型融合
结合不同阶次的分数阶微分预处理及PCA-SRDA进行多模型融合,构建一种集成学习算法。多模型融合的具体流程如图1所示。基本思路为:(1)采用不同阶次(取0~2阶,步长为0.1)的分数阶微分预处理训练集原始光谱;(2)基于不同阶次的分数阶微分预处理及PCA-SRDA算法构建基学习器,并输出相应的预测结果;(3)将基学习器的预测结果组成一个新训练集,并采用决策树算法完成模型融合,得到最终的分类预测模型;(4)采用对应阶次的分数阶微分技术预处理测试集原始光谱,然后基于已建立的基学习器,输出相应的预测结果;(5)将测试集的基学习器预测结果构成一个新测试集,并基于已建立的分类预测模型,输出最终的预测结果。
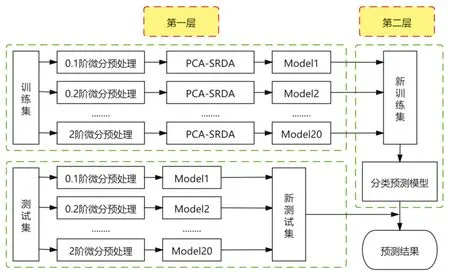
图1 多模型融合流程图
2 结果与讨论
2.1 不同产地红富士苹果重量、物理特性及可溶性固形物含量分析
对三个产地红富士苹果的重量、物理特性(横径、纵径)和可溶性固形物含量进行常规统计(见表1)。
从表1,可以得出,三个产地苹果重量的均值排序为新疆阿克苏>陕西洛川>山东烟台;三个产地苹果横径的均值排序为新疆阿克苏>陕西洛川>山东烟台;三个产地苹果纵径的均值排序为新疆阿克苏>山东烟台>陕西洛川;三个产地苹果可溶性固形物含量的均值排序为新疆阿克苏>山东烟台>陕西洛川,且三个产地的苹果可溶性固形物含量具有极其显著的差异。由此可知,新疆阿克苏红富士苹果的糖分明显高于其他两个产地的苹果,市场上也更受消费者喜爱,但仅从苹果重量、外形、物理特性等难以准确判断苹果产地。

表1 三个产地红富士苹果的常规数据统计
2.2 不同产地红富士苹果的平均透射光谱曲线
将采集的671个苹果的近红外透射光谱,经过光谱校正后,计算每个产地的苹果平均透射光谱曲线,如图2(a)所示。可见,三条平均光谱曲线的形状、趋势非常一致,但是新疆阿克苏苹果在600~900 nm波长范围与其他两个产地的苹果光谱存在差异性分离,山东烟台与陕西洛川苹果之间的光谱吸光度差异较小而难以区分。
进一步,利用Grünwald-Letnikov分数阶微积分定义,计算三条平均光谱曲线的分数阶微分,如图2(b)—(f)所示(仅列出0.6阶、0.9阶、1.2阶、1.5阶、2阶微分曲线)。可见,平均光谱曲线基于不同阶次的分数阶微分计算,不同产地的苹果光谱曲线呈现不同的变化。据此,可以从不同分数阶微分层面获取更多光谱数据的深层信息,比如光谱曲线的几何信息,所以利用分数阶微分技术,可挖掘光谱数据的分数阶微分层面的更多数据信息,这势必有助于提高苹果产地溯源模型的精确性和稳健性。
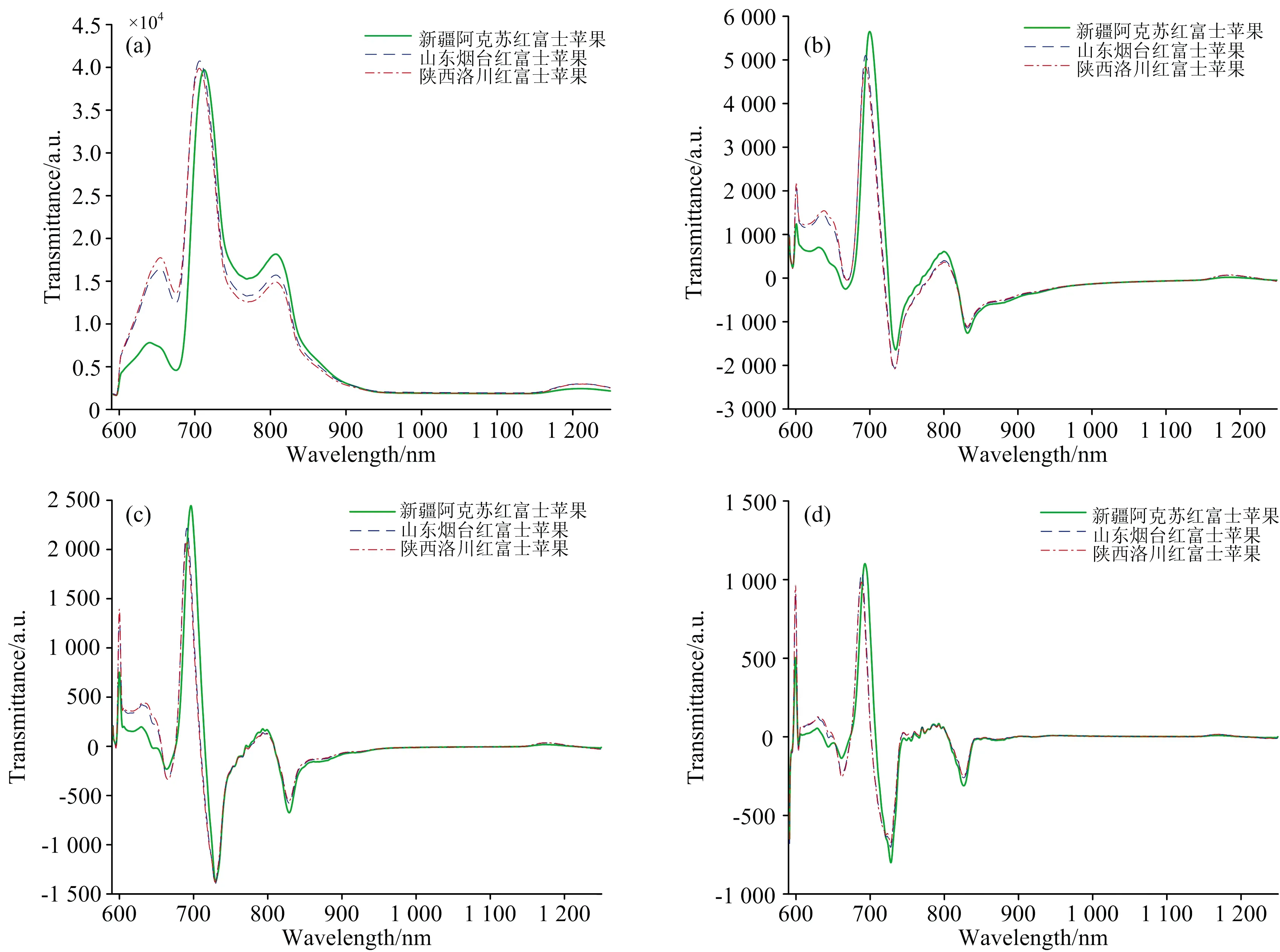
图2 不同产地红富士苹果的不同分数阶次的近红外透射光谱
2.3 光谱数据的分数阶微分预处理与PCA-SRDA特征提取
光谱数据通过分数阶微分预处理,除了能挖掘分数阶微分层面的光谱曲线信息外,还可以消除干扰、突出谱线的差别、增强信息量。因此,按照多模型融合流程,对原始光谱的训练集和测试集分别进行分数阶微分预处理。如图3所示,为训练集和测试集的(0.6阶)分数阶微分预处理结果。
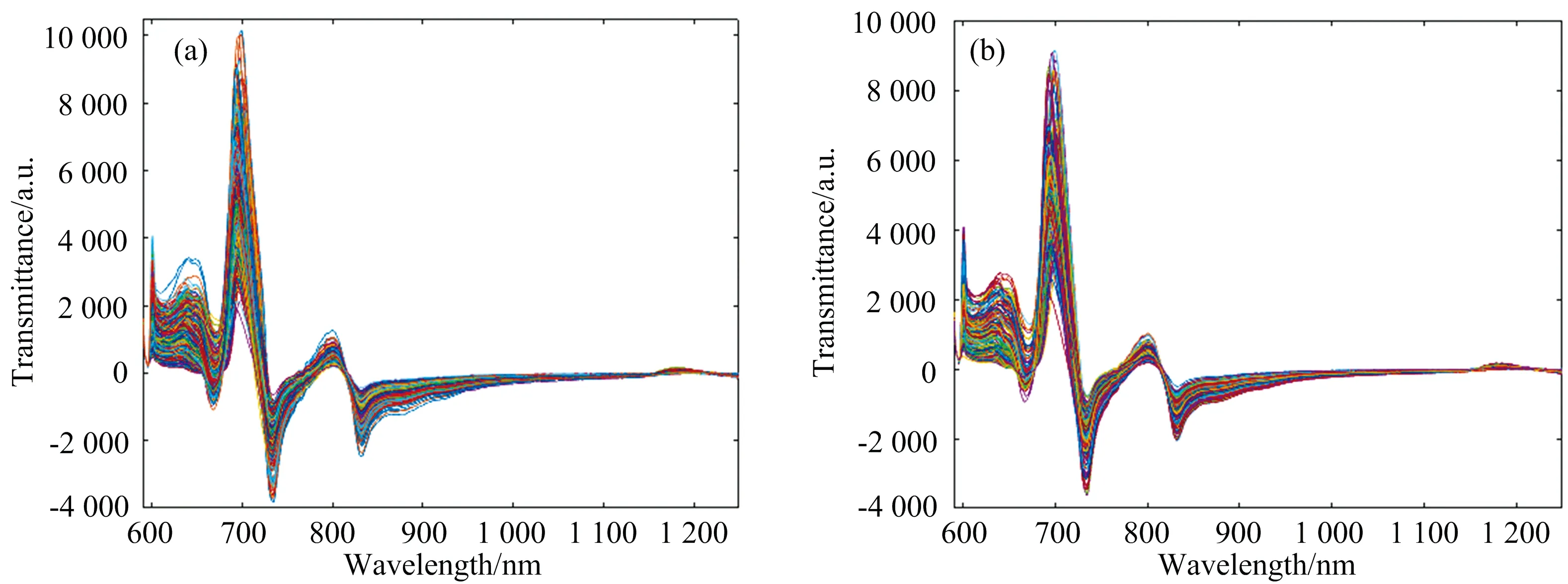
图3 训练集(a)和测试集(b)的(0.6阶)分数阶微分预处理结果
在获取的分数阶微分光谱基础上,需要进一步降维和特征提取。利用PCA-SRDA进行特征提取。如图4所示,为训练集和测试集经过(0.6阶)分数阶微分预处理的PCA降维结果(主成分个数取16)。从图4可以看出,通过PCA降维处理后,新疆阿克苏苹果与山东烟台、陕西洛川红富士苹果具有较好的区分度,但是山东烟台与陕西洛川苹果之间仍有较多重叠,较为混淆。
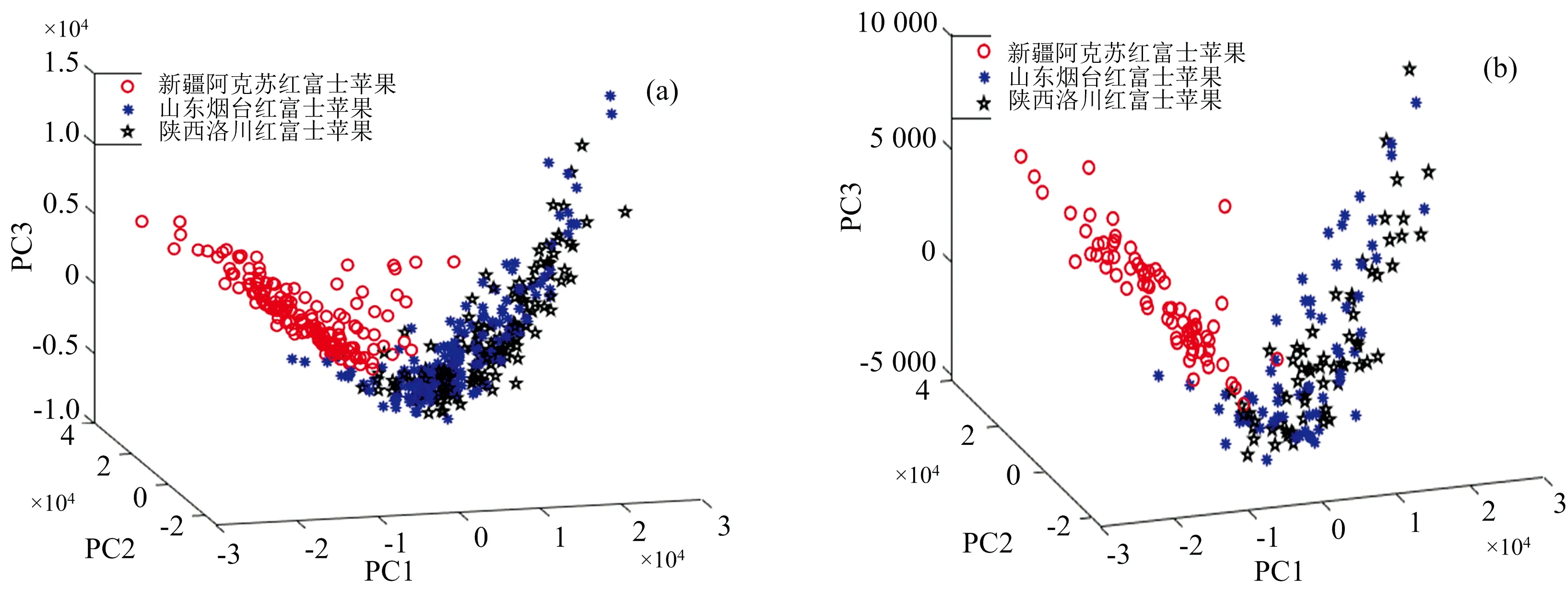
图4 PCA降维结果的可视化图
如图5所示,为训练集和测试集经PCA降维后的SRDA特征提取结果。从图5可以看出,经过PCA-SRDA特征提取后,新疆阿克苏、山东烟台、陕西洛川苹果彼此之间的区分度显著提高。由此获悉,采用PCA-SRDA算法对本试验的苹果光谱数据进行特征提取是一种切实有效的技术。

图5 PCA-SRDA特征提取结果的可视化图
2.4 多模型融合算法实现苹果产地溯源
将样本数据按7∶3比例随机划分训练集和测试集,然后根据多模型融合步骤予以实现。为比较多模型融合集成学习算法的优劣,同时给出基于LDA,SRDA和PCA-LDA的预测结果。如表2所示,为200次重复实验的结果,如图6为对应的箱图。
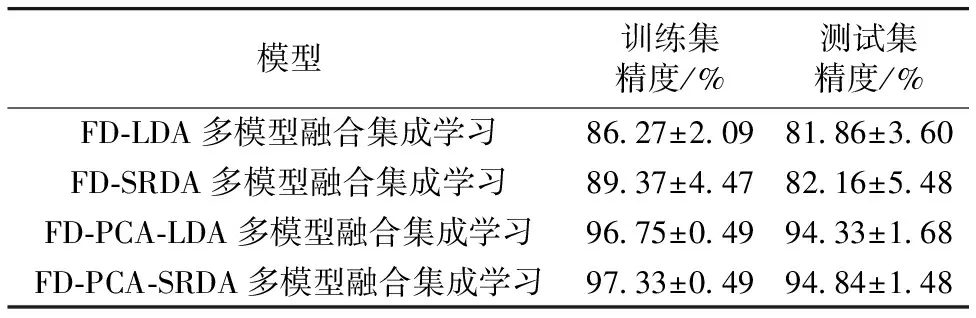
表2 多模型融合集成学习模型的苹果产地溯源结果(200次重复实验)

图6 苹果产地溯源结果的箱图(200次重复实验)
从表3和图6的结果可得,结合不同阶次的分数阶微分预处理及LDA,SRDA,PCA-LDA和PCA-SRDA算法建立多模型融合集成学习模型,具有较好的鉴别效果和较强的鲁棒性,其中,FD-PCA-SRDA多模型融合集成学习模型为最优,其训练集的平均精度为97.33%,标准差为0.49%,测试集的平均精度为94.84%,标准差为1.48%。此外,FD-PCA-SRDA多模型融合集成学习模型与FD-PCA-LDA多模型融合集成学习模型在精度上没有显著差异,但在模型的运行时间上具有一定差异,单次实验的运行时间平均减少约3.2 s。综上说明,分数阶微分技术及PCA-SRDA多模型融合结合近红外透射光谱技术对苹果产地溯源具有可行性。
3 结 论
结合近红外透射光谱,基于分数阶微分预处理技术及PCA-SRDA进行多模型融合构建集成学习模型,实现红富士苹果的产地溯源,得到如下主要结论:
(1)利用分数阶微分预处理光谱数据,除了能消除干扰、突出谱线的差别、增强信息量外,还可以通过计算光谱曲线不同阶次的分数阶微分,挖掘出分数阶微分层面的更多深层数据信息,比如光谱曲线的几何信息,这有助于提高模型的识别精度。
(2)利用PCA-SRDA算法对光谱数据进行特征提取,可以很好地将新疆阿克苏、山东烟台、陕西洛川苹果彼此分离开,区分度很好,说明PCA-SRDA算法是一种切实有效的特征提取技术。
(3)结合近红外透射光谱,基于分数阶微分技术及PCA-SRDA进行多模型融合,构建的苹果识别集成学习模型,取得了预期的识别效果,可成功、有效地实现苹果产地溯源。200次重复实验结果表明,提出的多模型融合集成学习模型具有较好的鉴别效果和较强的鲁棒性,其中,FD-PCA-SRDA多模型融合集成学习模型为最优,其训练集的平均精度为97.33%,标准差为0.49%,测试集的平均精度为94.84%,标准差为1.48%。
(4)本方法具有较强的适用性、较高的识别精度和泛化能力,可为红富士苹果产地溯源提供技术支持和科学支撑,还可以拓展到近红外光谱技术的其他应用领域。
