基于自建表情数据集和深度神经网络的人脸表情识别方法*
2022-10-08卢晋
卢 晋
(深圳职业技术学院 职业教育大数据智能广东省重点实验室,广东 深圳 518055)
人脸表情是人类情绪最主要的输出通道,对于互相交流具有极其重要的意义,准确的表情识别有助于有效地交换信息.文献[1]通过大量的跨文化研究定义了6类基础表情:愤怒(Angry)、悲伤(Sad)、高兴(Happy)、恐惧(Fear)、厌恶(Disgust)、惊讶(Surprise).因此,行业大都基于以上定义的6类基础表情作为表情分类的标准进行人脸表情识别(Facial expression recognition,FER)的探索.人脸表情识别技术应用广泛,包括课堂教学效果识别,服务业顾客满意度识别,电影分类,个人性格研究,抑郁自杀倾向分析等,一直是最近10几年机器学习与深度学习研究的热点问题[2,3].
自A. Krizhevsky等提出AlexNet[4]以来,深度学习迅猛发展,大量应用任务受益于深度学习取得了重大突破.深度学习的突破依赖于计算机计算能力的摩尔定律以及互联网的广泛普及让大数据成为可能.人脸表情识别任务同样也受惠于深度学习,近年来很多相关研究取得了不错成绩[5-8],但是采用深度学习的人脸表情识别方法面临数据集严重不足的问题.人脸表情识别目前运用较成熟的数据集有日本 Advanced Telecommunications Research Institute International(ATR)的专门用于表情识别研究的基本表情数据库JAFFE[9]和Cohn-kanade表情数据库(CK),以及Lucey[10]等人在2010改进的数据集CK+.这类采集自实验室的人脸数据集虽然质量高,但是成本高且数量极少,比如JAFFE总量只213张,这与深度学习的识别方法对数据的需求量比是远远不足的.针对这个问题,一些方法提出采集互联网的人脸数据代替实验室拍摄比如 ExpW[11],ExpW 具有91793张采集自互联网的人脸,使用人工标注好表情分类.使用爬虫采集数据可以解决实验室拍摄数据量不足的问题,但是采集自互联网的数据受到用户上传的偏置影响,也受到爬虫关键词的影响,往往会导致极严重的类别不平衡问题.互联网上存在很中性或者积极情绪的人脸图片,但是很少消极情绪的人脸,导致爬虫最后爬取的人脸数据标注清理后在分类极其不平衡.
针对以上问题,本文提出一个基于融合开源人脸表情数据集和网络爬取数据集的方法,通过降采样平衡不同分类,去除噪声数据构建了当前最大的人脸表情识别数据集;在此数据集基础上,通过修改网络结构,实验不同的神经网络基础模型,并调节各个分类在损失目标函数的权重,以有效提高表情识别准确率.
1 表情数据集的建立
为了构建表情数据集,首先收集了行业现有的人脸表情公开数据集.开源人脸表情数据集分2大类:一类是实验室聘请人员表演对应的表情;第二类是从互联网上爬取的人脸图片,清洗后,使用人工标注给人脸打上对应的表情标签.前者创建的表情数据质量高,分类均衡平等,但是成本相当高,数量少.后者能比较容易获得大量数据,但是数据分类严重不平衡,也有可能出现错误标注的数据.我们分别收集了2个类别的代表性数据集.然后在百度和谷歌等搜索引擎中,使用7个表情分类(即愤怒、中性、厌恶、恐惧、快乐、悲伤、惊讶,及其对应近义词)作为关键词进行图片搜索,与现有公开数据集合并得到初始表情图像数据集;在解决了数据集的类别不平衡和数据集合噪声问题后,得到总量586712张的人脸表情数据集.
1.1 收集公开数据集
共收集包含以下7个来源的公开数据集,得到180255张人脸表情数据集:包括ExpW(91793张,来源网络,包含6个基础表情和中性表情)、Fer2013(35887张,来源网络,包含6个基础表情和中性表情[12])、Raf(29672张,来源网络,,包含6个基础表情和中性表情数据[13])、KDEF(4900张,来源实验室,包含6个基础表情和中性表情[14])、AffectNet(450000张,来源网络,包含6个基础表情和中性表情[15])、CK+(327张,来源实验室,包含6个基础表情和中性表情[16])、MMI(740张,来源实验室,包含6个基础表情和中性表情[17]).
1.2 使用关键词爬取网络图片
使用愤怒、中性、厌恶、恐惧、快乐、悲伤、惊讶七个表情以及他们的近义词以及关联词作为关键词,在百度和谷歌搜索引擎爬取图片.
对爬取的人脸图片使用人脸检测模型检测是否存在人脸,并把人脸使用检测出来的关键点对齐,把人脸保存至对应的分类.
人工检查,移除与文件夹分类不匹配的人脸图片,最终创建了一个272842总量的人脸表情数据集.
1.3 分析和解决初始表情图像数据集存在的问题
1.3.1 类别不平衡问题
几乎所有数据集均存在类别严重不平衡,数量多的类别和数量少的类别的比例甚至超过了20,如图1所示.
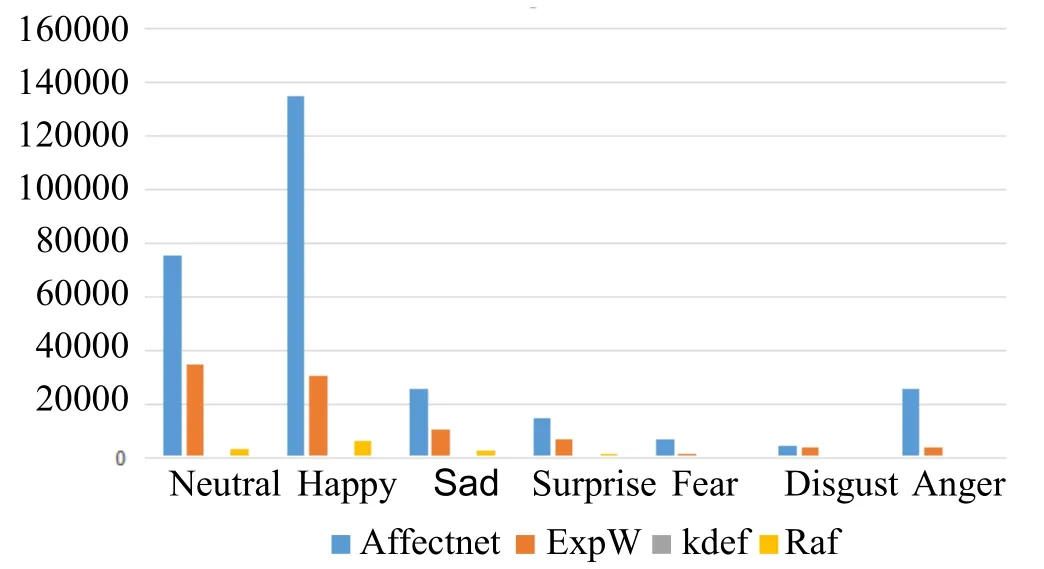
图1 数据集类别严重不平衡统计
解决方案:
1)对数量多的类别采取降采样,对数量少的按照类别间的目标比例重复采样,使用图像增强技术增加数据[18];
2)对类别目标函数配置不同的系数,给予数量少的类别更高的损失,让其学习更多.
1.3.2 数据集合噪声问题
几个公开数据集存在噪声多的问题,比如affectnet存在非人脸的图片数据,存在大量错误标注表情类别数据.解决方案:
1)使用人脸检测模型检测图片是否存在人脸,抛弃不存在人脸图片.
2)使用基准人脸表情识别模型判断表情分类是否正确,如发现错误人工确认.
3)在解决了数据集的类别不平衡和数据集合噪声问题后,得到总量586712张的人脸表情数据集,见表1.

表1 自建人脸表情数据集
对上述数据清洗,剔除错误无效人脸,修改错误标注后获得总量586712的数据集,各个分类上的数量(表2).

表2 最终数据集在各个分类上的数量
2 调整网络结构以优化人脸表情识别方法
2.1 MTCNN人脸检测算法
本文训练使用的人脸检测算法是MTCNN模型[19],该模型主要采用了3个级联的卷积神经网络架构:P-Net、R-Net和O-Net网络结构.P-Net作为级联网络的第一层负责产生初步的候选框,中间层次R-Net甄别存在的误识别的候选框,将检测的候选框和筛选的候选框输送到最终的网络结构O-Net中,生成最终边界框与输出最终的人脸特征关键点.
2.2 人脸表情分类模型基础网络
本文针对2类基础网络:ResNet和DenseNet进行了实验(图2,图3).ResNet通过引入残差连接,使信息能直接流动到后面的层次,在进行逆向梯度求导时候,误差信息能直接传递到早期的层次,这种方法使更深的网络训练成为了可能,解决了网络的退化问题.这种神经网络被称为残差网络(ResNets),ResNet引入了residual结构(残差结构)来减轻退化问题,residual结构使用了一种shortcut的连接方式,也可理解为捷径.让特征矩阵隔层相加,注意F(X)和X形状要相同,所谓相加是特征矩阵相同位置上的数字进行相加[20].

图2 ResNet基础网络

图3 DenseNet基础网络
相对ResNet,DenseNet引入了密度更大的残差连接,把残差的思想发挥到了极致,只需要更少的参数即可达到相同的分类准确率,也能更稳定地训练更深的网络[21].
2.3 网络结构调整方法
1)调节超参数训练.本文使用SGD优化算法对2种基础模型进行训练,分别尝试了0.001,0.0003,0.0005的学习率进行训练.
2)调节数据增强方法训练.本文分别使用了随机水平翻转、随机角度旋转(5°以内)、随机色彩抖动、随机微调亮度4种方法增强人脸表情数据,在两组模型上使用控制变量法测试不同增强方法对实验结果的影响[22].
3 实验结果
所有实验均在联想工作站上进行,该工作站配备intel I9-10900k,64GB内存,2*RTX3090,1T pcie3.0 SSD.所有实验都在Tensorflow平台上进行.
3.1 测试数据集
测试数据集Fer2013,CK+,MMI,3个数据集均处理静态人脸图片并打上对应的标签.将训练模型在这3个数据集上进行推理打上标签后,与数据集的ground truth进行比对得到准确率,准确率越高则模型越好.
3.2 SOTA(state of the art)
目前在静态图片表情上,在CK+表现最好的是以下2个模型:
1)Facial Expression Recognition by De-Expression Residue Learning (thecvf.com)[23],最高准确率 97.3%.
2)Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition[24],最高准确率97.25.
3.3 超参数实验
本文对模型的超参数进行探索,使用不同组合的超参数训练模型,控制变量包括学习率,正则化Regularization系数等.结果见表3,4.
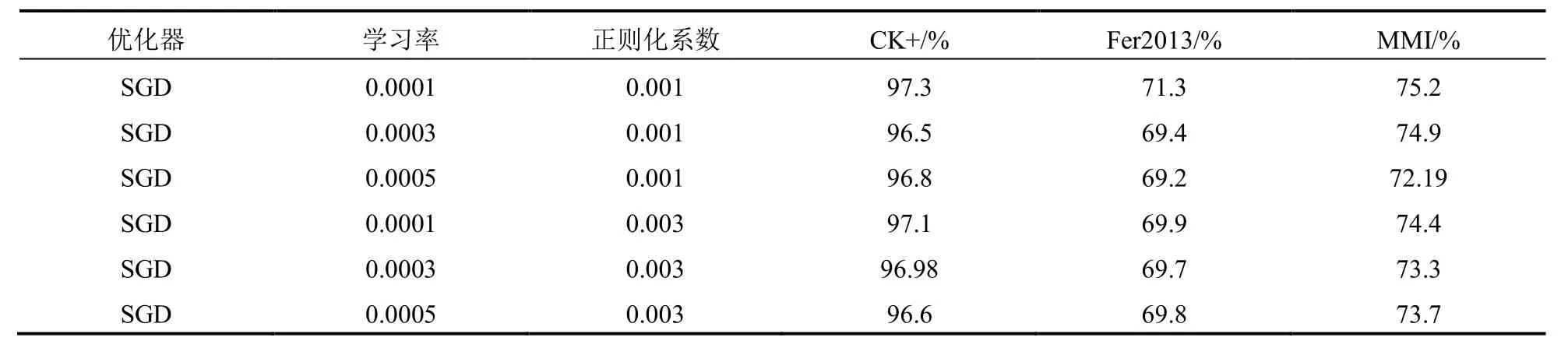
表3 Resnet超参数结果

表4 Densenet超参数结果
从测试结果来看,使用SGD的优化方法,采用万分之一的学习率,千分之一的正则化参数获得最稳定的模型训练效果.
3.4 增强方法实验
本文在2种类型模型(Resnet,Densenet)上探索了4种数据增强方法,每次实验只启动一个增强方法,其它全部关闭,以测试哪种增强方法表现更有影响,结果见表5,6从测试结果来看,使用SGD的优化方法,采用万分之一的学习率,千分之一的正则化参数获得最稳定的模型训练效果.

表5 Resent数据增强实验结果

表6 Densenet数据增强实验结果
3.5 增强方法实验
本文在2种类型模型(Resnet,Densenet)上探索了4种数据增强方法,每次实验只启动一个增强方法,其它全部关闭,以测试哪种增强方法表现更有影响,结果见表5,6.
实验结果发现采用水平翻转以及随机角度旋转能比较好提高模型的稳定性,其它2种方法影响不大.
3.6 比对结果
我们观察到在训练Resnet模型时候,学习率为0.0001,正则化因子为0.003,采用随机水平翻转的数据增强方式能获得最好的表情识别准确率,在MMI测试集上达到了75.2%的成绩.训练更高残差连接密度的 Densenet,我们观察到采用同样的学习率0.0001,正则化率设为0.001,只采用水平映射数据增强方法获,在MMI测试集上获得75.17%的准确率,超过了文献[24]在MMI上的73.23%,见表7.

表7 本研究方法和SOTA识别准确率对比结果(%)
4 结 语
人脸表情识别是人类情感识别的基础,是近年模式识别与人工智能领域研究的热点问题.本文介绍了表情识别常用的数据集与存在的问题,并针对这些问题提出了一种自建表情数据集和深度网络结构改进相结合的方法,解决了表情数据集存在的类别不平衡和数据集合噪声问题;然后通过修改网络结构,实验不同的神经网络基础模型,并调节各个分类在损失目标函数的权重,在CK+数据集上的验证实验表明,所提出的数据集和基于此数据集训练的模型获得超过SOTA的人脸表情识别准确率,达到97.5%.
