基于近邻回归的Spark性能优化方法
2022-10-08张威
张 威
(湖北中医药大学,湖北 武汉 430065)
0 引 言
现阶段,移动互联网服务、电子商务、感知网络等技术广泛地应用于人们的日常生活,大量的应用系统的业务以及运行过程都产生了海量的数据。国际数据中心相关报告指出,当前人们已经处于大数据时代。随着大数据技术需求的增加,很多大数据分布式框架产生,其中Apache Spark因其出色的性能和丰富的应用支持成为当下最流行的大数据分布式计算框架。
随着Spark的应用越来越广泛,一些Spark应用的问题也暴露了出来。其中最为重要的一个问题就是Spark的性能优化问题。由于Spark在运行过程中很容易受到不同因素的影响,很难发现其理论的最佳性能,因此,如何优化配置提升Spark的性能,成为一个热门的研究问题。
配置分为功能性配置和非功能配置两种。其中,非功能性配置中有相当数量的配置参数对Spark的性能有着非常大的影响。Apache Spark官网提供了很多默认配置。这些配置在大多数情况下可以得到相对良好且正确的性能表现。但是,GOUNARIS A[1]和PANAGIOTIS P等人[2]提出,有一些参数会根据实验数据规模的大小和应用程序的差异对性能产生影响。BEI Z D等[3]人主要研究了参数配置对Spark工作负载的影响,研究表明,通过改变默认参数配置,Spark性能的变化可能高达20.7倍[4]。这个数据也说明参数对于性能优化有着举足轻重的作用。
1 算法设计动机
Spark平台有多种优化方式,其中,通过调整Spark的配置参数值获得最优执行时间的方式最为简便有效。通过大量的日常工作实践能够发现,Spark平台的执行时间除受到配置参数影响之外,还与平台执行的应用类型以及处理的数据规模有关。其中,应用类型是按照在Spark平台执行应用程序对于平台的系统和硬件资源依赖进行分类。
通过实验观察发现,Spark集群在运行过程中会受到运行环境动态变化的影响而产生执行时间的波动。这种波动在某些特殊情况下产生较大的异常波动,但是经过统计,大量的样本都会集中在“合理”的运行时间周围,个别样本会产生离群现象。基于密度的方式可能将小规模样本误判为异常,因此采用基于近邻的模型构建方法一方面可以保证近邻样本能够为邻域的异常样本判定提供信息,同时也能够识别小规模样本,也保证这些数据不会被作为异常数据处理。因此,首先通过K最邻近(K-NearestNeighbor,KNN)分类算法计算出每一个样本的5个邻居,近邻样本用于训练循环神经网络(Rerrent Neural Network,RNN)构建当前样本的近邻模型,近邻模型的信息与该样本通过一同训练全连接网络。最终通过粒子群(Particle Swarm Optimization,PSO)算法搜索模型的配置定义域,从而获得最佳配置,获得任务的最佳模型。整体方案如图1所示。
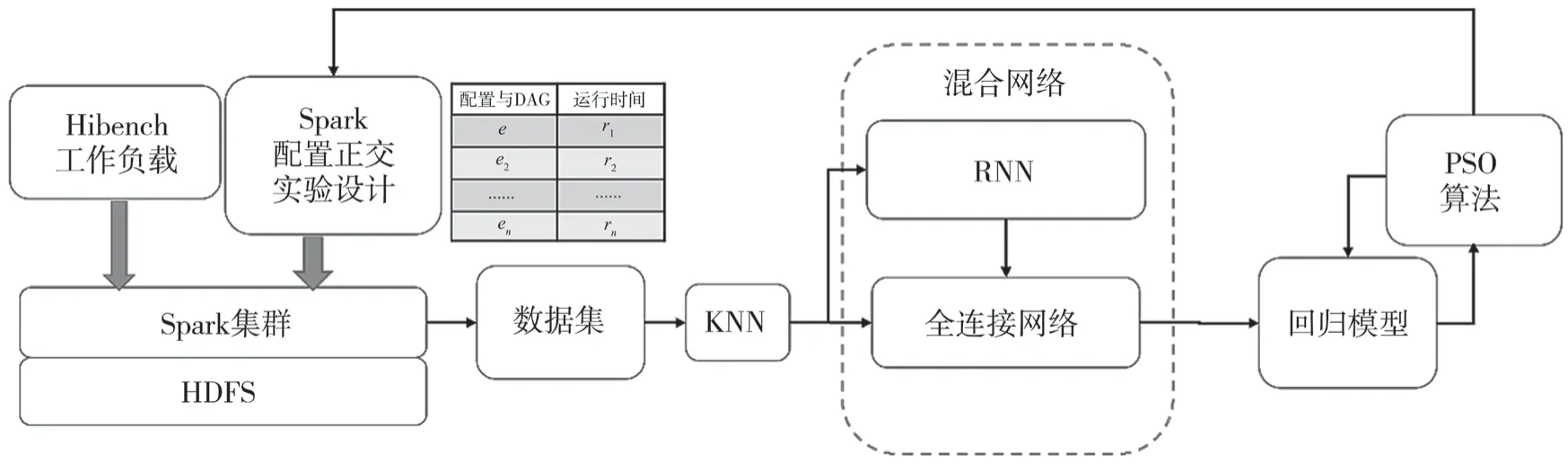
图1 基于近邻的Spark参数优化方案
2 优化方案设计
为了获取全面且准确的工作负载,本文采用Hibench软件生成工作负载。Hibench内部集成了6大类、29种工作负载。为了能够获取充足的Spark平台的配置性能样本,本文通过不同的Hibench配置,将各类标准负载存储于Hadoop分布式文件系统(HDFS)上。接下来用改进的正交设计方法构建的出10因素10水平的正交实验方案。
所谓10因素10水平正交实验,不是用一个正交实验设计一次完成10水平实验,而是利用10因素3水平实验方法完成一轮实验,接下来,对正交结果进行分析。正交分析倾向实验结果极差大的情况,所以算法会保留实验结果中的极大值和极小值做下一轮实验,被去掉的中间值样本会由没有试验过新的水平替换,迭代前面的过程直到所有的水平都按照正交组合的方式进行了实验。
因为在Spark的配置参数样本是含有单位字符串类型的数据,所以数据收集模块获取数据后首先去掉参数上的单位,进行数据类型转换。所有的数据中包含值域为True或者False的布尔类以及数值型两类参数。为了便于后面构建配置性能模型,需要将布尔型参数转换为1和0。
此归一化结果将通过KNN算法计算样本集合的5个近邻。近邻计算结果分别用来训练RNN[5]和全连接网络。首先用近邻数据对RNN进行训练,RNN模型可以有效描述样本点的紧邻信息。其次,RNN输出结果与当前样本信息共同对全连接网络进行训练。如果只是使用全连接网络构建模型,模型容易受到异常样本的影响,而RNN模型中含有的近邻信息能够有效降低异常样本对于预测结果的影响。最后,通过PSO粒子群算法搜索样本空间求解预测模型的最小值。这个最小值就是Spark执行类似类型应用的最短时间,而对应的配置样本就是优化Spark的配置。
3 基于RNN的近邻混合设计
即使在相同的样本条件下,Spark应用的执行时间仍然有一定的波动性。利用算法对近邻样本提取上下文信息,能够提升模型的质量。近邻算法易于实现,不易受到低概率异常数据影响。本文设计的混合网络模型对近邻算法进行了改进。这种改进将克服数据对于模型的负面影响,同时利用近邻算法的优势降低异常数据对模型训练产生的干扰。网络结构如图2所示。

图2 基于RNN的近邻混合网络结构
由图2可见,算法由三个部分构成。第一部分是计算含有n个样本的模型训练集Xtrain={x(i)},1≤i≤n中每一个样本的5个近邻,并将近邻按照距离由远及近的规则构建序列其中1≤t≤5表示x(i)样本的近邻元素。第二部分,利用近邻构建的序列对循环网络进行训练,应用LeakyRelu激励函数处理数据。此部分的更新方程如式(1)所示。

式中:W和U表示连同权重矩阵,b表示偏置向量,z(t)表示当前样本的第t个近邻。h(t)输出值作为第三部分3层全连接网络的输入,最终计算获得回归结果。
4 算法评估
实验平台构建在基于Intel(R)Xeon(R) CPU E5-2699的物理服务器集群上。在集群上创建8个虚拟机服务器,每个虚拟机服务器拥有16核CPU、16 GB内存以及256 GB的存储空间。
实验方案如表1所示。

表1 实验方案
Hibench软件提出的Wordcount负载负责计算输入数据中单个单词出现的频次,代表了一种比较典型的MapReduce作业。Hibench中的micro Benchmarks的sort负载是对文本输入数据进行排序,数据是由RandomTextWriter生成的。Hibench提出的PageRank负载中,数据源主要通过Web数据获得,提供了包含数据和需要大量迭代计算的搜索引擎,又提供了用来测试大规模搜索子系统的Nutchindexing,所以这种负载属于混合型负载。
利用本文模型建模后,利用PSO算法对模型配置空间进行搜索,将获得的最优配置作为Spark的配置参数,执行所需时间与Spark默认参数配置的执行时间进行对比,如图3所示。
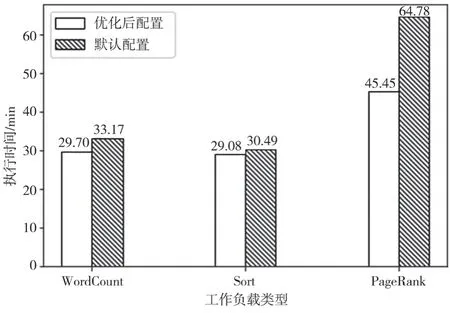
图3 优化配置与默认配置性能对比
在Wordcount负载中,优化算法用时29.7 min,性能提升了约10.5%;在Sort负载中,优化算法用时29.08 min,执行效率提升了约4.6%;在混合型PageRank负载中,优化算法用时45.45 min,运行效率提升了约30%。
5 结 语
本文利用RNN网络对Spark样本进行性能建模,并采用粒子群算法获取最佳配置,以此优化Spark的执行效率。RNN对近邻样本的分析,有效地降低了异常样本对于模型的影响,提升了算法的鲁棒性。然而,对于近邻的分析,增加了模型构建过程的算法开销。在后面的工作中,将对此进行改进。
