基于聚类匹配的煤层气压裂效果主控因素识别
2022-10-05代博仁石咏衡杨兆中李小刚张馨慧
闵 超,代博仁,石咏衡,杨兆中,李小刚,张馨慧
(1.西南石油大学理学院,四川 成都 610500;2.西南石油大学人工智能研究院,四川 成都 610500;3.西南石油大学油气藏地质及开发工程国家重点实验室,四川 成都 610500;4.国家管网集团油气调控中心,北京 100022)
0 引 言
煤层气是一种重要的非常规油气资源,但其储层物性较差,需要采用水力压裂技术进行储层改造来获得工业产能[1]。煤层气压裂效果受地质条件和压裂施工等诸多复杂因素的影响,客观准确地从中筛选影响压裂效果的主控因素,对优化压裂设计、提高产能具有重要的研究意义。目前,国内外学者围绕煤层气的压裂效果评价[2-4]与主控因素分析[5-6]等问题做了大量的研究。王玉海等[7]利用压降曲线的形态特征对压裂效果进行了评价分级。计勇等[8]将影响因素与产气指标的数据关系进行可视化处理,更直观地分析了两者之间的关系。李玉伟等[9]应用模糊综合评判和灰色关联度分析相结合的方法,对多级压裂水平井的压裂效果进行了评价。谢诗章[10]利用统计分析、数值模拟方法对煤层气储层日产水量进行了分类与成因分析。Wu等[11]基于数据挖掘和渗流理论,提出了一种改进的煤层气井分类评价方法。檀朝东等[12]采用主成分分析法研究压裂效果的主要影响因素。然而,上述方法均存在局限性,一方面,这些方法多以定性分析为基础来评价压裂效果,阈值的设定方法带有一定的主观性;另一方面,以单变量分析方法来筛选主控因素,没有系统地考虑各影响因素的冗余性,难以挖掘影响因素与压裂效果之间潜在的非线性关系。为此,提出了一种基于聚类匹配的主控因素识别方法,以挖掘影响因素之间的内在联系。首先,采用凝聚聚类方法对样本井压裂后的产气效果进行分类评级;然后,对潜在的压裂效果影响因素进行聚类筛选;最后,基于聚类匹配的思想,将压裂效果分类与基于主控因素的样本聚类结果做匹配,检验筛选出的影响因素和压裂效果之间的吻合程度。该方法可有效减少人为主观判断带来的干扰,克服随机森林等有监督学习方法只考虑因素与标签之间的重要性而忽视因素间冗余性的缺点,减少基于树的分类算法的初始输入数据量。
1 基于聚类分析的煤层气压裂效果分级
利用无监督学习的聚类技术对压裂后产能数据进行划分,得到的簇类按照平均日产气量进行分级,并以此作为样本井压裂效果的标签,其目的是与后文基于主控因素的聚类结果作对应匹配。基于聚类技术的评价分级方法,可以根据相似性度量或邻近性标准,按压裂后产能数据的内在联系对样本井进行自然划分,避免了采用单一产能指标按阈值划分范围的主观性和片面性。
1.1 数据预处理
选取中国某煤层气田某区块196口井的压裂施工相关数据为研究对象,基础数据包括23个影响压裂效果的因素(包括地层因素数据和施工因素数据)与2个压裂后的产量评价指标。为了便于数据分析,对其进行编号,其变量符号与属性名对应关系如表1所示。
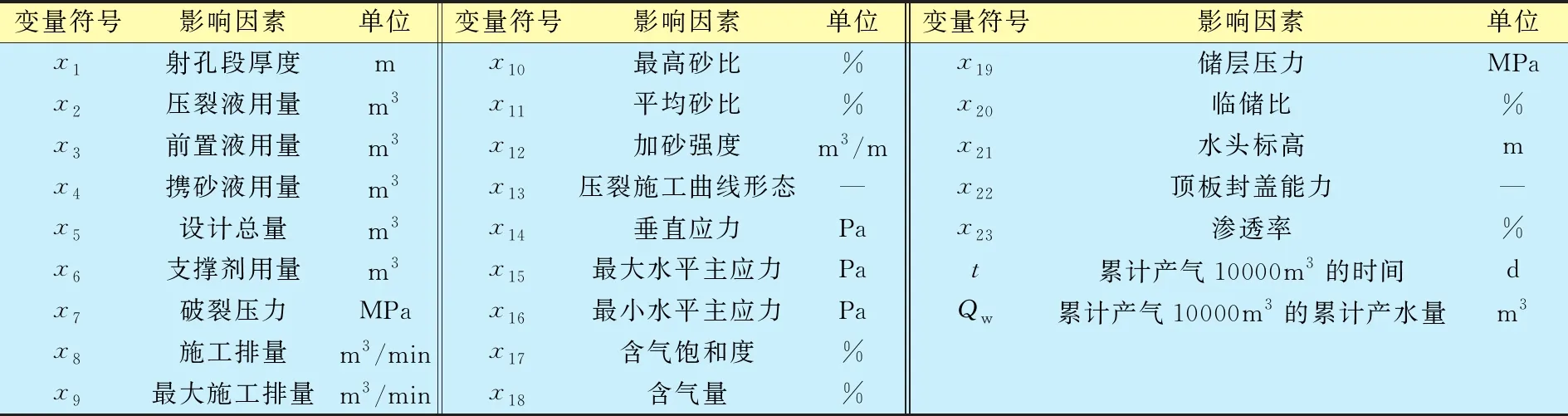
表1 压裂井基础数据
现场采集的196口井的数据中存在缺失和异常现象,故需对数据进行处理以提高其可用性。首先将缺失率较高的样本数据删去,部分缺失的数据则采用插值法进行填补;然后利用Epanechnikov密度估计法对数据进行异常值检测[13],剔除阈值以下的异常点;最后,对数据进行标准化处理,最终得到167口井的压裂数据作为有效样本。
为综合分析样本井压裂后的产气能力与排液效果,根据统计的累计产气10 000 m3的时间和累计产水量,可以计算出日均产气量和日均产水量,进而推导出平均日产气水比、日产气贡献率,以便后续压裂效果的评价分级。
平均日产气量:
Q=10000/t
(1)
平均日产水量:
W=Qw/t
(2)
平均日产气水比:
(3)
日产气贡献率:
(4)
式中:Q为平均日产气量,m3/d;W为平均日产水量,m3/d;T为平均日产气水比,%;C为日产气贡献率,%;Qi为第i个样本井的日均产气量,m3/d。
整理得到的压裂后产能数据共包含6个指标:t、Qw、Q、W、T、C,作为压裂效果评价的有效数据属性集合。
1.2 基于压裂后产能数据的压裂效果分类
由于产能指标数据具有一定的层次结构,故选用凝聚聚类法,根据指标t、Qw、Q、W、T、C对样本井进行分类。凝聚聚类法属于层次聚类的一种,该算法将每个样本初始归为单独簇类,再在每个步骤中合并2个簇类,直至生成一个包含所有数据集的单块[14]。首先,采用欧氏距离作为样本间差异的距离度量;然后,综合考虑压裂后产能数据在不同聚类下4种链方法的同表型相关性系数和轮廓系数,确定利用平均链将样本井聚类为4个簇类。同时,为了对样本井的压裂效果进行评价分级,根据凝聚聚类的结果分别统计了各簇类样本井的平均日产气量(图1)。
由图1可知:4类样本井的平均日产气量以60 m3/d为界呈现明显的两级区分,其中1、2簇类共101口样本井,3、4簇类共66口样本井;1、2簇类样本井的产气量明显低于3、4簇类样本井的产气量。为消除随机性造成的干扰,分别对1、2簇类样本井与3、4簇类样本井进行合并,实现信息粒度的粗化。将各簇类的平均日产气量从低到高排序,产能较低的第1、2簇类样本井标记为“0”,第3、4簇类样本井则标记为“1”,并将167口煤层气井的压裂效果对应分为4级(表2)。
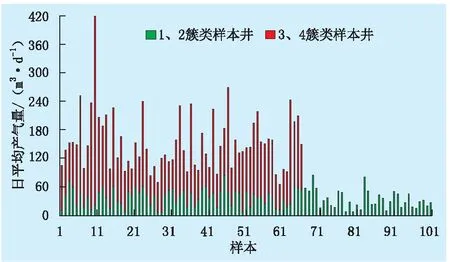
图1 各簇类平均日产气
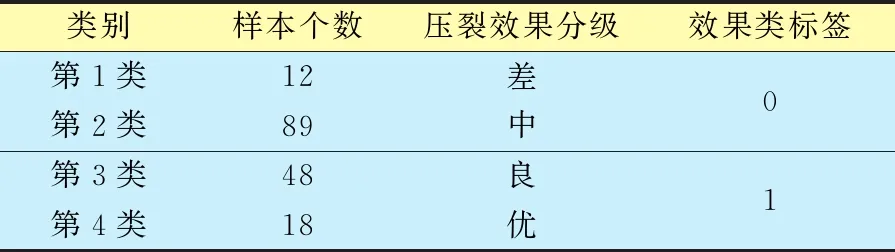
表2 压裂效果分类
为检验上述压裂效果分级标签的有效性,采用t-SNE算法对167口井的其他因素数据进行可视化处理,如图2所示。每口样本井的23个地层、施工因素数据可看作一个23维行向量,利用t-SNE算法向二维平面投影过程中,各样本之间的相对距离保持不变;然后再根据压裂效果标签,将投影后的点以不同的颜色标记。
由图2可知:大部分效果类标签为1的样本均位于y>0的半平面内,标签为0的则位于y<0的半平面内,说明基于压裂效果的类标签可以将表1中样本井的地层、施工因素数据分离,间接证明了根据压裂效果指标进行聚类分级的方法的可靠性。
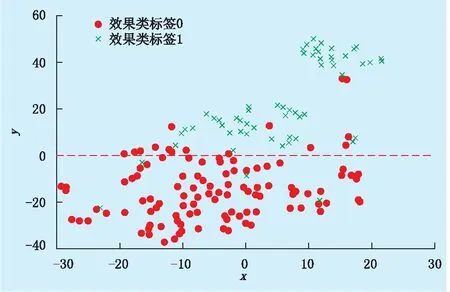
图2 带类标签的压裂影响因素数据集的t-SNE图
2 压裂效果影响因素筛选
根据表1中的23个地层、施工因素对167口样本井的基础数据进行聚类和相关性分析,实现对煤层气压裂效果影响因素的初步筛选,步骤如下:①对样本的23个地层、施工数据进行因素聚类。②计算不同簇类中各个因素的信息增益,以此衡量其对类标签的重要程度,并设置阈值,去除重要性较低的因素。③对每个簇类中余下的因素做相关性分析,去除与其他因素相关性高、与类标签相关性低的因素。
2.1 基于K-means算法的影响因素聚类
通过比较K-means算法、层次聚类算法和DBSCAN算法(具有噪声的基于密度的聚类方法)对167口样本井的23个因素数据的聚类结果及评估指标,选取效果最佳的K-means算法对数据进行聚类。
首先,输入归一化处理后的地层、施工数据,利用手肘法确定因素聚类的最优k(分类数目)值为4。再利用K-means算法进行聚类,得到的4个簇类包含的因素个数分别为6、3、8、6。具体聚类结果如表3所示。
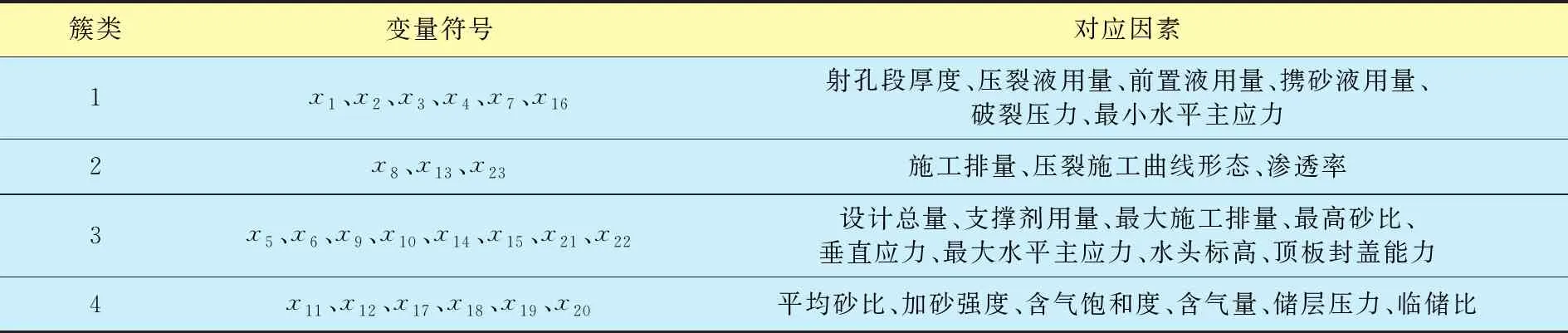
表3 基于K-means算法的因素聚类结果
利用轮廓系数对因素聚类的结果进行评估,绘制出相应的轮廓图,如图3所示。由图3可知,当k=4时,每类因素的分布较为均匀,表明簇内间距较接近其平均值,而相邻簇类间又有明显的分离。
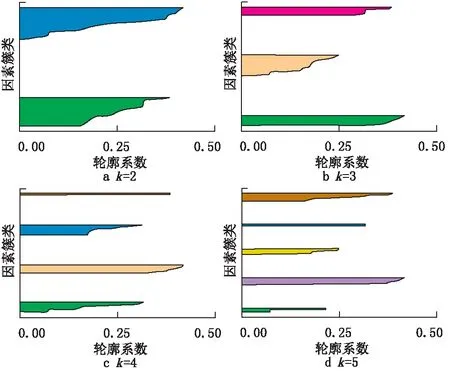
图3 因素聚类的轮廓系数
2.2 聚类后因素的重要性排序
为了对因素做进一步筛选,需要对各簇类中包含的因素进行重要性衡量与相关性分析,去除与压裂效果标签关联性低、与同类其他因素相关性高的因素。
在因素选择中,信息增益常用来衡量因素带给分类标签的信息量,其值越大,代表该特征越重要。为了衡量各类因素对压裂效果类标签的重要程度,分别计算因素xi的信息增益:
G(D,xi)=H(D)-H(D|xi)
(5)
式中:G(D,xi)为信息增益;D为23列地层、施工数据加上类标签组成的数据集;H(D)为数据集D的经验熵;H(D|xi)为因素xi对数据集D的经验条件熵。
将压裂效果类标签集表示为Y={0,1},pj表示第j类样本所占比例,则:
(6)
设因素xi有n个不同的可能取值{ai1,ai2,…,ail,ain},则p(ail)表示因素xi取值为ail的样本占总样本的比例;pj(ail)表示第j类样本中因素xi取值为ail的样本所占比例,于是:
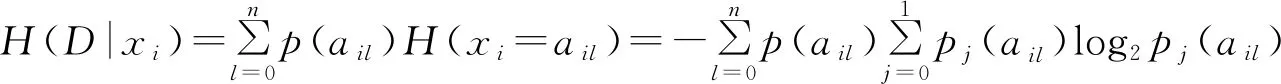
(7)
通过计算得到每个因素对应的信息增益,设置适当的阈值,对聚类后的每类因素进行初筛选,留下对标签重要性较大的因素。此处根据总体因素数量以及其对应的信息增益取值,将阈值设为0.7,剔除阈值以下的因素,如图4所示。
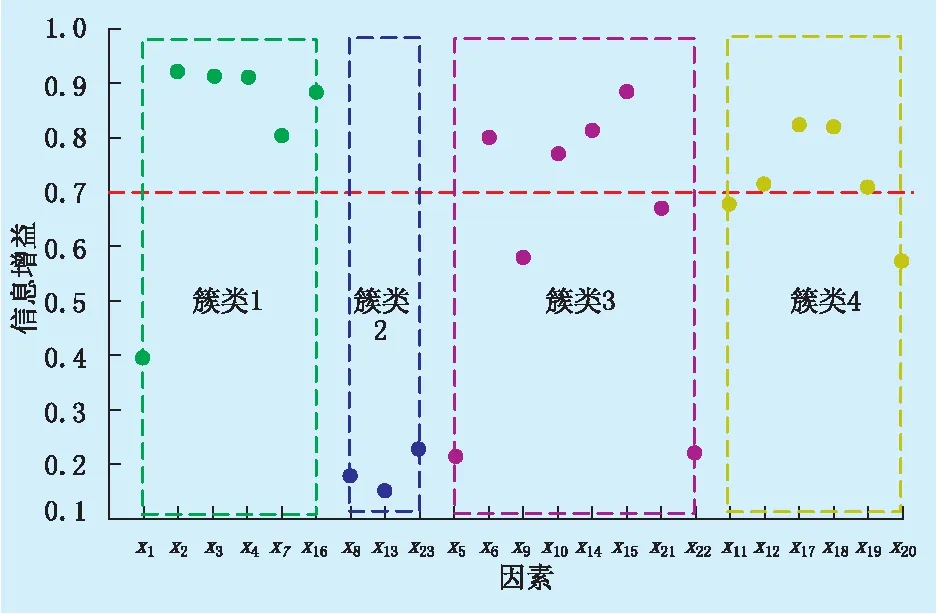
图4 各聚类中因素的信息增益分布图
由于簇类2中各因素的信息增益均低于0.7,故全部移除。最后,簇类1、簇类3、簇类4共剩余13个因素。簇类1对应的因素为:压裂液用量、前置液用量、携砂液用量、破裂压力、最小主水平应力;簇类3对应的因素为:支撑剂用量、最高砂比、垂直应力、最大主水平应力;簇类4对应的因素为:加砂强度、含气饱和度、含气量、储层压力。
2.3 基于相关性分析的簇内因素冗余性消除
将余下的13个因素按类别分别进行相关性分析,以消除簇内因素间的冗余性,进一步提炼影响煤层气压裂效果的主控因素。
簇类1余下的因素为:压裂液用量(x2)、前置液用量(x3)、携砂液用量(x4)、破裂压力(x7)、最小主水平应力(x16)。首先利用python对这5个因素进行相关性分析,得到各因素间的相关系数(表4)。由表4可知:有2组因素的相关系数值较高:corr(x2,x3)=0.68,corr(x2,x4)=0.78。其中,压裂液用量x2等于前置用量x3与携砂液用量x4之和,即因素x2可由因素x3与因素x4综合体现,故剔除因素x2。
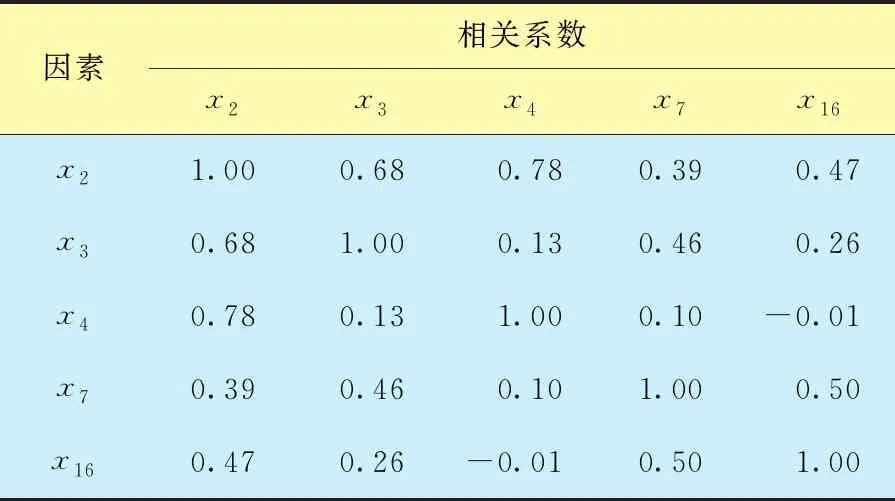
表4 因素间的相关性系数
结合类标签,对各因素本身以及因素之间的分布关系进行可视化处理(图5)。其中,图5a—d和图5f—i表示因素x4和x16与同簇类其他因素之间关于类标签的散点分布关系,图5e、j表示因素x4和x16自身关于类标签的概率分布(2个曲线分别对应类标签0和类标签1)。由图5可知,因素x4与其他因素在类标签0/1下具有明显的区分度,且该因素的密度分布无明显重合现象(图5a—e);而因素x16与其他因素在类标签0/1下的散点分布重叠率高,区分度较差,且在类标签0/1下的密度分布较为相近(图5f—j),说明该因素的取值对产能影响较小,故剔除因素x16。利用该分析方法,最终可以确定簇类1中的3个因素为x3、x4、x7。
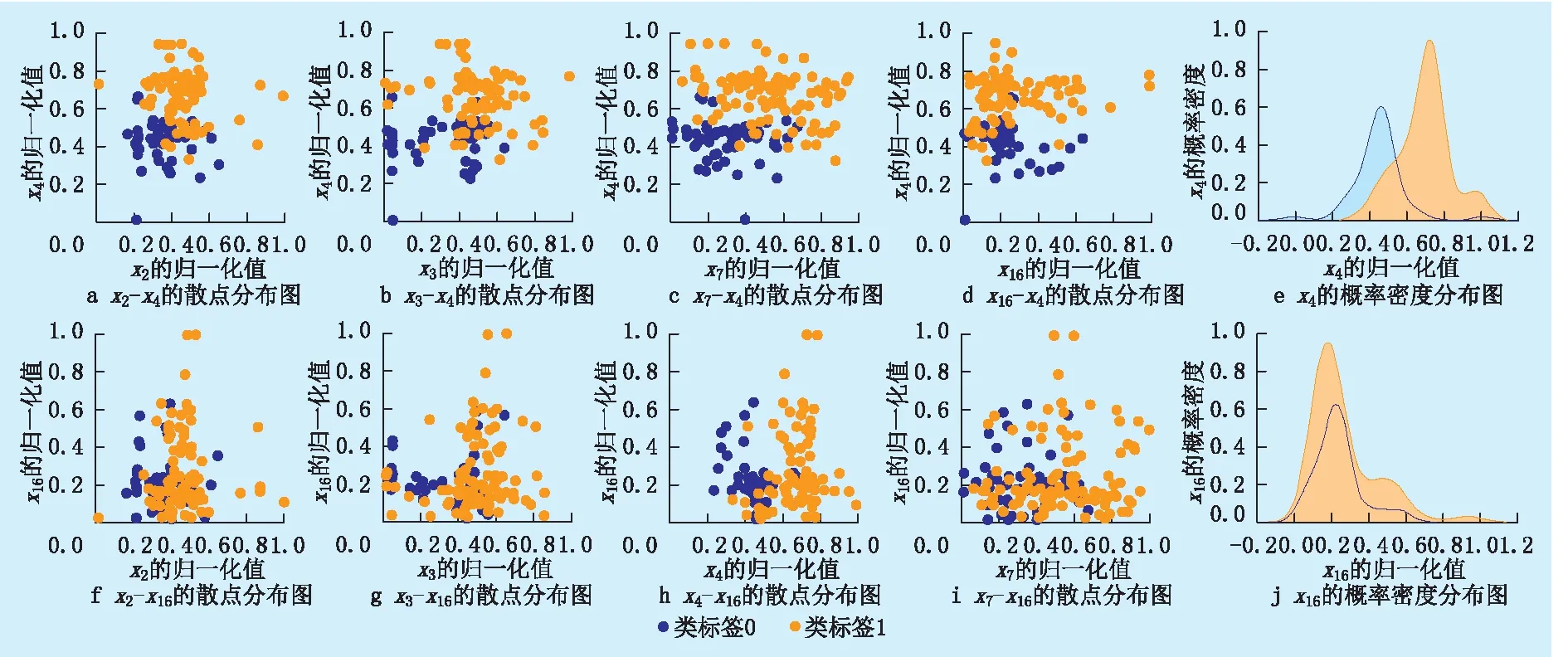
图5 各因素间的相关性散点分布图
对其他簇类进行类似分析,簇类3的最终因素有2个:支撑剂用量(x6)、垂直应力(x14);簇类4的最终因素有3个:加砂强度(x12)、含气饱和度(x17)、含气量(x18)。
综上,筛选得到8个影响压裂效果的因素,按重要程度降序排列依次为:前置液用量(0.91)、携砂液用量(0.91)、含气饱和度(0.83)、含气量(0.82)、垂直应力(0.81)、支撑剂用量(0.80)、破裂压力(0.80)、加砂强度(0.72)。
3 基于聚类匹配的主控因素识别与检验
第1节中基于压裂后产能数据的分级与第2节中基于影响因素的聚类,这二者计算过程是相互独立的。按照图6所示的聚类匹配方法的思路,在“背靠背”的情况下,如果这2种分类结果之间存在对应关系,则可以认为筛选出的因素与产能效果之间具有潜在的非线性关系。
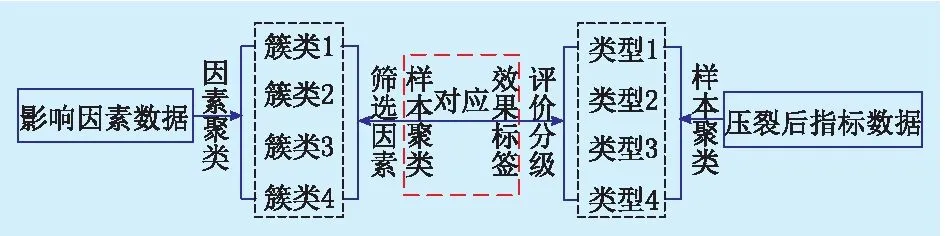
图6 聚类匹配方法的示意图
以筛选出的8个因素对应的样本数据为输入,对167口井进行重新聚类。由于得到的分类结果需要与样本井的压裂效果类标签相对应,故确定聚类数为2。其聚类效果如图7所示。
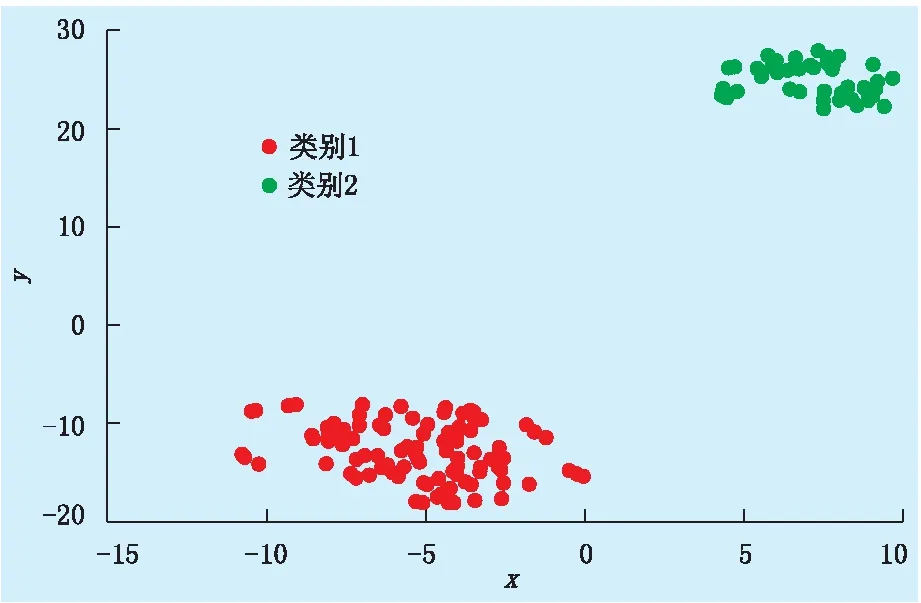
图7 基于主控因素数据集的样本聚类可视化
由图7可知,基于这8个因素得到的样本井聚类效果较好,可以很好地区分簇类。同时,基于主控因素的聚类结果与基于压裂后指标的效果分类进行匹配统计(表5)。其匹配度达到79.7%,查准率为81.9%,查全率为85.1%。说明该特征识别方法有效可行,所选出的8个因素确定为影响压裂效果的主控因素。
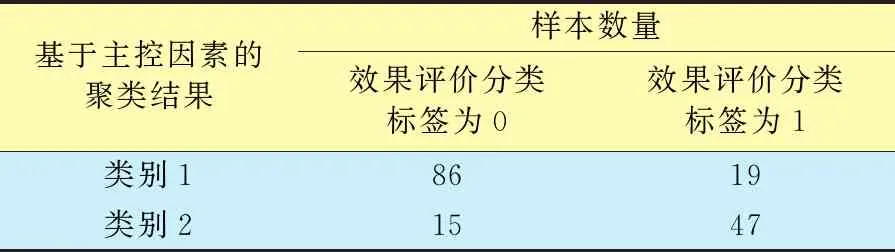
表5 样本井类别的匹配矩阵
此外,选取的8个主控因素与其他特征选择方法进行主控因素识别的结果进行对比,如表6所示。由表6可知,基于聚类匹配的特征识别方法与随机森林、递归特征选择法所选的因素有6个重合,与Apriori关联分析法[15]所选的因素有5个重合。其中,4种方法共有的主控因素有5个,分别为:x3(前置液用量)、x4(携砂液用量)、x6(支撑剂用量)、x14(垂直应力)、x18(含气量)。

表6 不同方法的主控因素识别结果对比
基于聚类匹配的方法所选的主控因素与其他特征选择方法的结果重合率较高,个别的差异主要源于该方法去除了相关性较高的因素,降低了因素间的冗余性,保证了所选因素具有独立性和代表性。筛选出的主控因素中:①含气饱和度和含气量直接反应了煤储层的含气性;②垂直应力则与裂缝的形态有关(是否为水平缝、是否穿层);③破裂压力反应了施工的难易程度;④前置液用量、携砂液用量、支撑剂用量、加砂强度则一定程度上反映了压裂后的改造体积。
4 结 论
(1) 利用聚类算法对某区块196口井压裂效果进行了评价分级,考虑压裂施工条件的复杂性,研究了各因素对压裂效果的影响程度。对压裂后指标和地层-施工因素分别独立地进行聚类,并根据聚类结果的匹配,筛选出8个主控因素:前置液用量、携砂液用量、含气饱和度、含气量、垂直应力、支撑剂用量、破裂压力、加砂强度。
(2) 基于聚类匹配的主控因素识别方法避免了因素选取的主观性,克服了常规方法只考虑变量对分类的重要性而忽视变量间冗余性的缺点,可以为重复压裂施工设计优化提供参考依据。
