基于机器视觉的生鲜牛肉冷藏时间识别研究
2022-10-04张茹张奋楠周星宇俞经虎
张茹,张奋楠,周星宇,2,俞经虎,2*
1(江南大学 机械工程学院,江苏 无锡,214122)2(江苏省食品先进制造装备技术重点实验室,江苏 无锡,214122)
近年来,随着国民膳食结构的改变和人们对健康饮食的重视,食品安全健康问题逐渐得到关注,牛肉营养丰富且口感随部位及烹饪方法的不同呈现多样化,可适应不同饮食爱好者需求[1]。但因外界环境及微生物酶作用,生鲜牛肉在生产、流通及存储中易出现新鲜度下降甚至变质的问题[2],这不仅对生产企业造成重大损失,严重则会影响食用者身体健康,因此对生鲜牛肉冷藏时间进行高效准确识别的研究尤为重要。
传统的图像识别方法通过对图像中尺寸不变特征变换[3]、方向梯度直方图[4]、颜色和纹理等特征进行提取来实现图像识别,在此基础上部分学者使用多种特征组合表达图像[5]。如马佳佳等[6]提出一种基于支持向量机的虫害图像识别方法,模型对复杂背景下的虫害图像识别准确率为93%。随着对图像识别任务要求的提高,传统图像识别方法效率不高、泛化能力不强等弊端也逐渐突出。于是学者们开始将卷积神经网络应用于图像识别检测,卷积神经网络的卷积层可自行提取图像特征以达到分类效果,泛化能力和自学能力较强,多应用于人脸识别[7]、语音识别[8]等领域,便利人们的日常生活。目前卷积神经网络在食品领域得到了广泛应用,可实现食品外形尺寸高效识别,如乐万德等[9]设计基于机器视觉的西红柿尺寸分级检测算法,对具有阴影干扰的西红柿尺寸测量准确度达到95%以上。但面对图像颜色纹理高相似的情况,时卷积神经网络的识别效果有待改进,如肖旺等[10]使用卷积神经网络检测鸭蛋表面缺陷,对比实验中AlexNet模型的准确率为85.43%。故在卷积神经网络基础上,学者将可重叠混淆树[11]、多通道融合[12]等概念引入神经网络模型,进行模型结构的优化或训练机制的改进来提高准确率,如徐文龙[13]使用双分支深度融合卷积神经网络对不同品质红枣的整体分类识别准确率达到了99.3%,相比于对比实验中的LeNet、AlexNet、SqueezeNet模型提升了4%~13%。
结合传统图像识别和卷积神经网络图像识别已有成果分析可知:(1)依靠人工提取图像特征的识别方法,由于数据误差及数据表述信息量有限,识别准确率通常在75%~90%[14];(2)采用图像分割和神经网络模型相结合的算法需要依赖大量的手工处理图像信息,增加了实验的额外成本;(3)目前大多数食品识别检测研究都是基于西方图像数据集,如PFID[15]和Food-101[16],这些图像集在特定场景中拍摄,目标物品的区分度高且背景简单,难以适应现实场景复杂图像区分要求,特别是对食品图像的细粒度识别要求[17]。
针对以上问题,对于本研究保证在一般生活场景下进行生鲜牛肉的存储、图像拍摄,根据GB 20799—2016《食品安全国家标准 肉和肉制品经营卫生规范》中对于冷鲜肉的定义:畜禽屠宰后经过冷却工艺处理并在经营环境过程中环境温度始终保持0~4 ℃,且冷鲜肉在0 ℃存储环境下约在5~6 d发生变质,变为二级新鲜度[18],故采集了在冰箱0 ℃的环境下,存储了0、1、2、3 d的生鲜牛肉样本图像,利用Tensorflow框架搭建基于GoogLeNet神经网络的改进模型,实现生鲜牛肉冷藏时间的识别。
1 材料与方法
1.1 实验数据准备与数据集构建
用于本实验的样本肉品于上午6∶00在生鲜超市购得,样本选取不考虑是否注水等背景因素。选取新鲜黄牛后腿肉350 g,将其切成100块大小厚度为60 mm×50 mm×20 mm的规整均匀切片,按序放置在干燥清洁的冰箱托盘上,冷藏过程中使用保鲜膜封存并清空冰箱其他物品,保证冰箱温度的同时避免冰箱中其他气味对样品的影响。实验采集时间为上午6∶30,2次检测间隔时间为24 h,每个时间点采集100张,共400张原始生鲜牛肉图像作为后续分析处理对象,图像样本示例如图1所示。

图1 图像样本示例
1.2 仪器选择与设备调试
硬件的选择以及图片采集环境直接影响到图片的质量以及机器视觉算法的难易程度,为提高图片采集的质量,使用工业相机和镜头将目标转换为图像信息,为规避不均匀光源的影响,采用前向照明和背光照明相结合的方法设置光源位置。如图2所示,图示采集系统由传输设备、上光源、摄像头、支架、下光源构成。其中摄像头型号为EF 50 mm f/1.8 STM(Canon)。

图2 图像采集系统
1.3 模型构建与环境准备
GoogLeNet结构如图3所示,主要由前端3个卷积层、9个Inception模块、1个全连接层、1个主分类器以及2个辅助分类器构成。相比于VGG模型,其在保证网络深度和宽度的同时优化了参数量和计算量[19],可将目标识别错误率降低到6.67%,综合来说性能更为优越,目前主要运用于医疗影像领域[20],在食品领域鲜见报道。
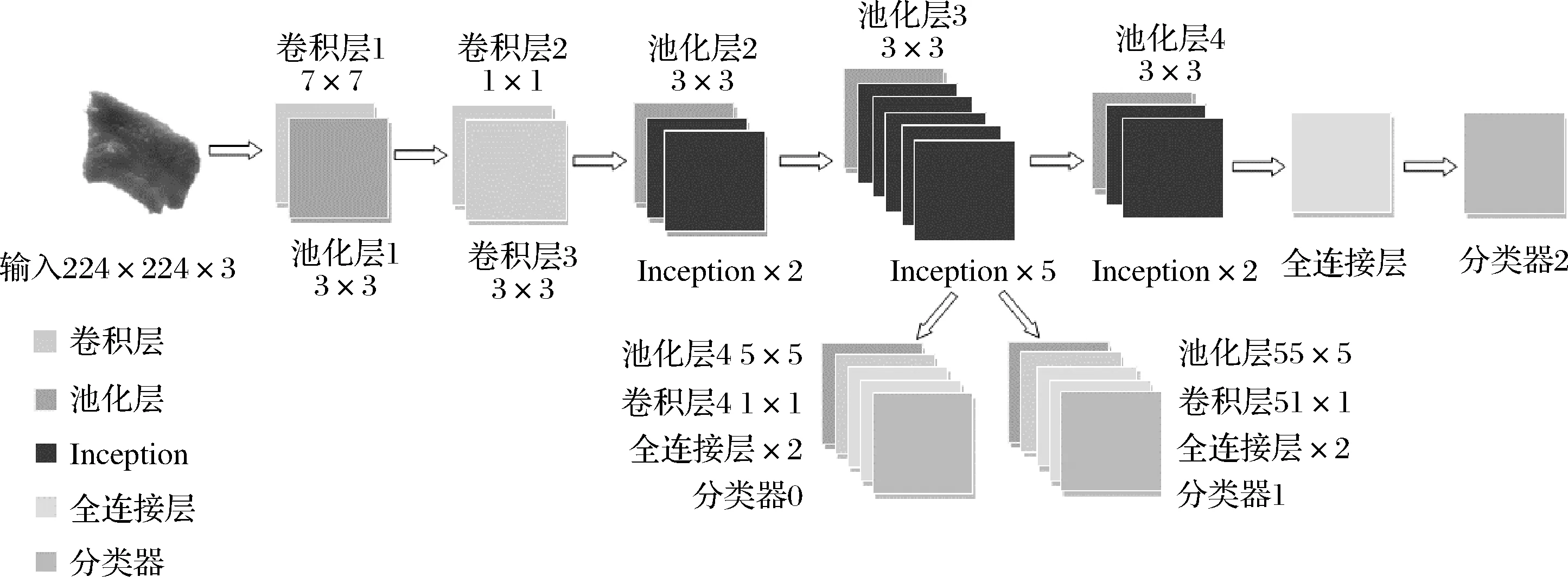
图3 原始模型结构图
Inception是构成模型的基础模块,本文采用的Inception模块结构如图4所示,分别在3×3卷积层和5×5卷积层前、3×3池化层后加入1×1卷积层[22],通过1×1的卷积层达到降维减少参数和削参降维的目的,卷积计算如公式(1)所示:
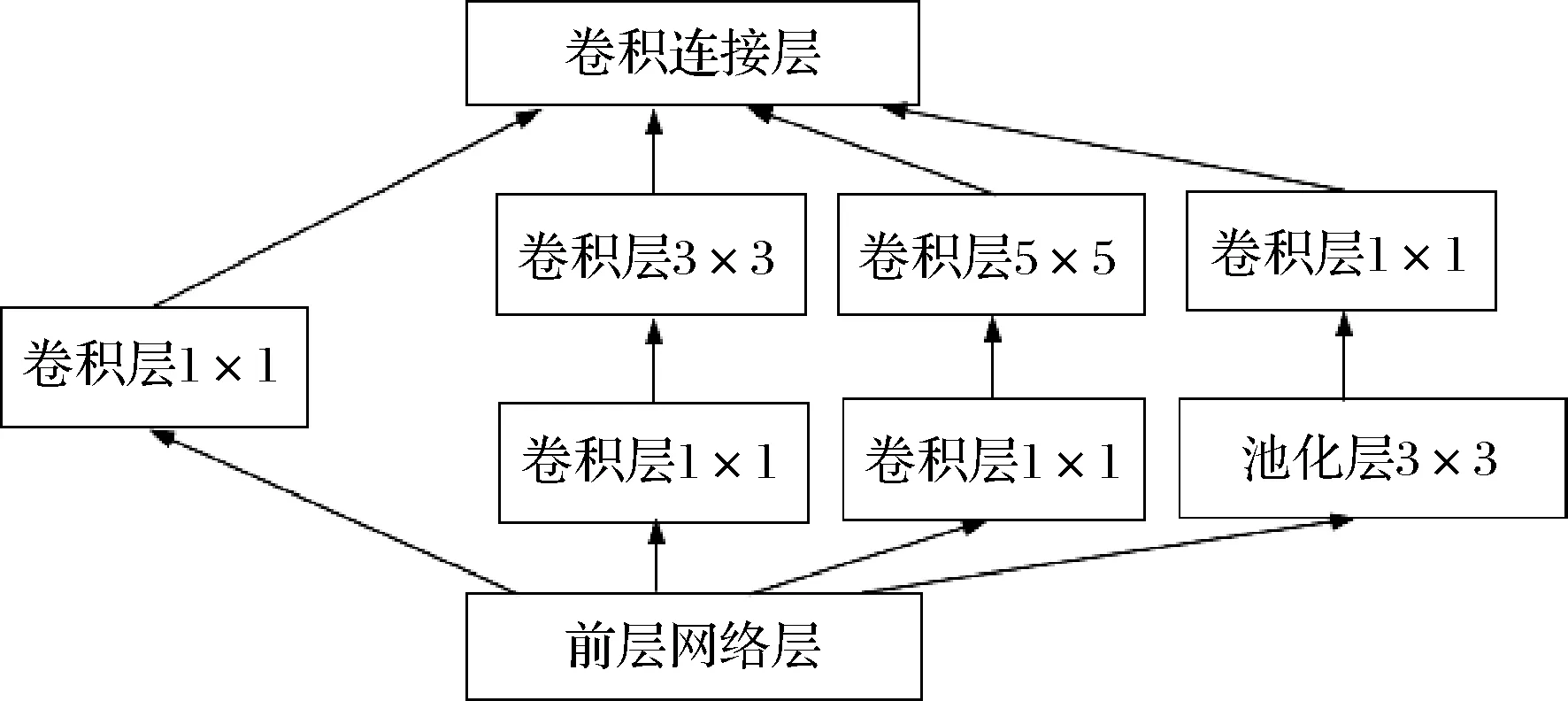
图4 Inception结构图[21]
(1)
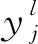
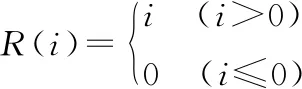
(2)
式中:i为神经元输入,R(i)为神经元输出。
本文以GoogLeNet V1为原始模型,由于本实验图像背景简单易区分,故简化模型结构。如图5所示,将前3层卷积层缩减为1个卷积层,Inception模块个数缩减为7,并将结构简化后的模型命名为GoogLeNet-M,以此模型开展生鲜牛肉冷藏时间的识别研究。
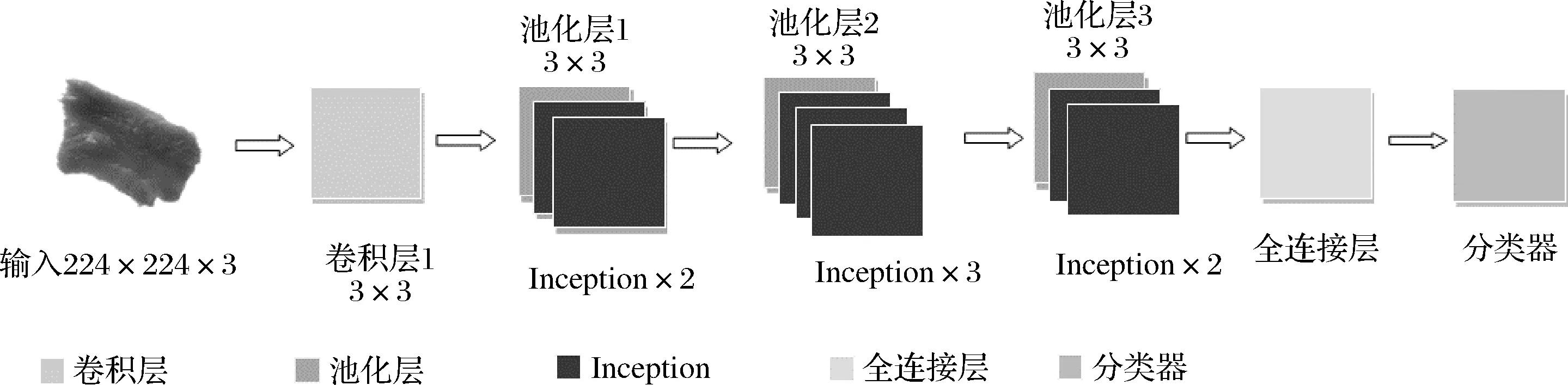
图5 GoogLeNet-M结构图
模型的搭建与训练在江南大学高性能工作站上进行,工作站操作系统Windows 10,采用Anaconda3、Python3.5、PyCharm2019进行环境的配制,使用TensorFlow框架进行模型搭建。
1.4 基于迁移学习的实验方法
1.4.1 图像数据的预处理与增强技术
图像预处理包括对像素的重新定义使之满足模型输入需求。GoogLeNet网络模型要求固定维度输入,故将像素尺寸统一转换为224×224,经过像素标准化的图像去除了大量冗余信息,有效减少了计算量。
图像增强包括直接对原始图像进行裁剪、旋转、翻折等操作来改变图片的形态,使得原数据集增加一定的倍数。使用MATLAB中的Imcrop函数对图像进行特定区域裁剪,指定位置坐标和大小分别为(400,400),224×224。使用旋转变换将图像绕中心点顺时针旋转θ角度,本实验分别取θ为90°、180°、270°,变换公式如公式(3)所示:
(3)
式中:x0和y0表示旋转前各像素坐标值,x和y表示旋转后图像像素坐标值。
每张原图可旋转为3张不同角度的图像。使用翻转变换分别以图像水平中线和垂直中线为轴将图像上下左右对调,每张原图经过翻折变换为3张不同图像。具体变换结果如图6所示,最终图像集由3 200张图像构成,按照8∶1∶1划分训练集、验证集、测试集,即训练集为2 560张、验证集和测试集均为320张图像,对模型进行训练与测试。
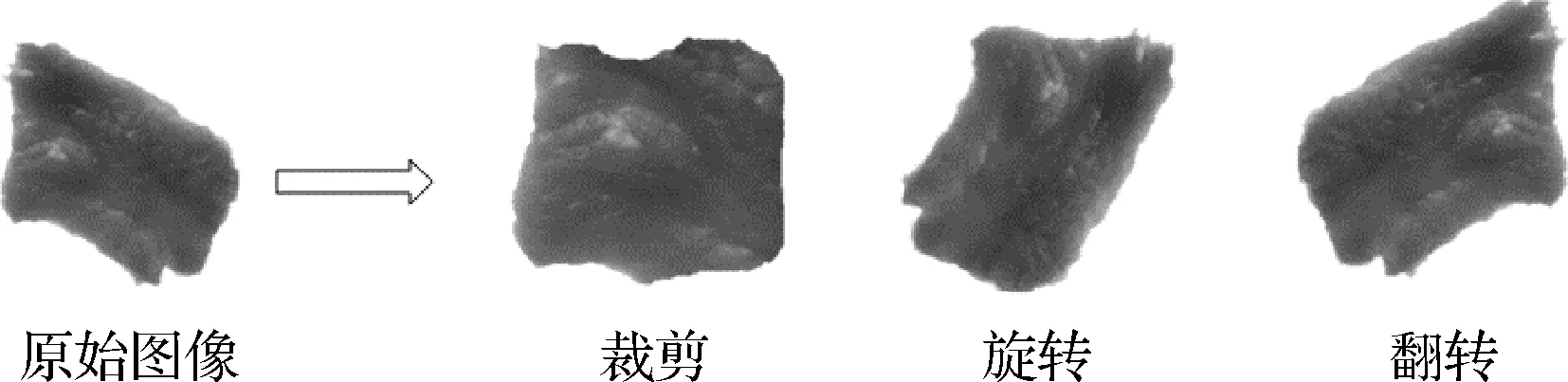
图6 图像增强示意图
1.4.2 迁移学习的训练机制
卷积神经网络的训练需要一个庞大的数据集,但是经常由于数据集的规模不够大、所覆盖信息范围不够完整完善,而难以训练出理想模型,造成小数据集在复杂网络结构上的过拟合问题。基于以上问题,迁移学习理论被引入并应用到模型训练方法中,迁移学习机制是在一个任务上训练好的初始模型通过简单调整使其适用于新任务的一种机器学习方法[23]。
1.4.3 模型的构建与训练
本文将迁移学习理论引入GoogLeNet-M模型训练中,首先使用ImageNet图像集对改进模型训练得到初始化模型,保存此时模型各层的权重和偏置,然后在此基础上分别使用2种模式对模型进行训练,一是冻结模型卷积层1,二是冻结模型全连接层。设置初始学习率为0.000 1,每次处理的数据15个,按照4分类任务将输出层改为4维向量,其余参数值为默认。
2 结果与分析
2.1 基于迁移学习的训练结果分析
由表1可知,冻结全连接层的准确率低于冻结练卷积层的准确率,原因是卷积神经网络主要使用卷积层对图像进行特征提取,所以经过迁移学习的权重及偏置可以在对新图像特征提取时发挥更大作用,更为精确的表达图像特征。而全连接层不直接参与图像信息的提取,其主要作用是对提取的数据降维后分类,因此迁移训练卷积层能够达到更理想的效果。
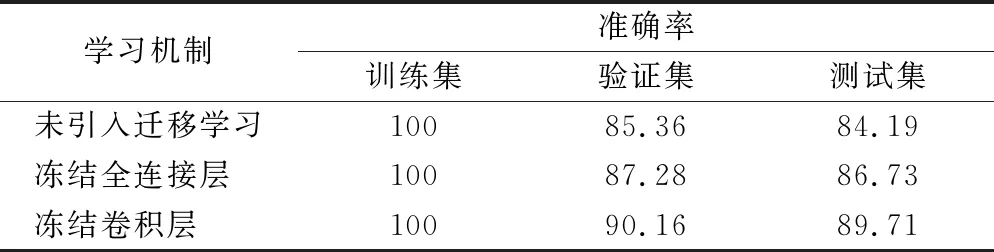
表1 不同训练机制下准确率 单位:%
由图7可知,未引入迁移学习的模型收敛速度慢且收敛后不稳定,冻结全连接层的收敛速度较未引入迁移学习机制的训练快一些,冻结卷积层收敛速度最快且收敛后趋向稳定,表明迁移学习可有效缩短模型收敛时间。
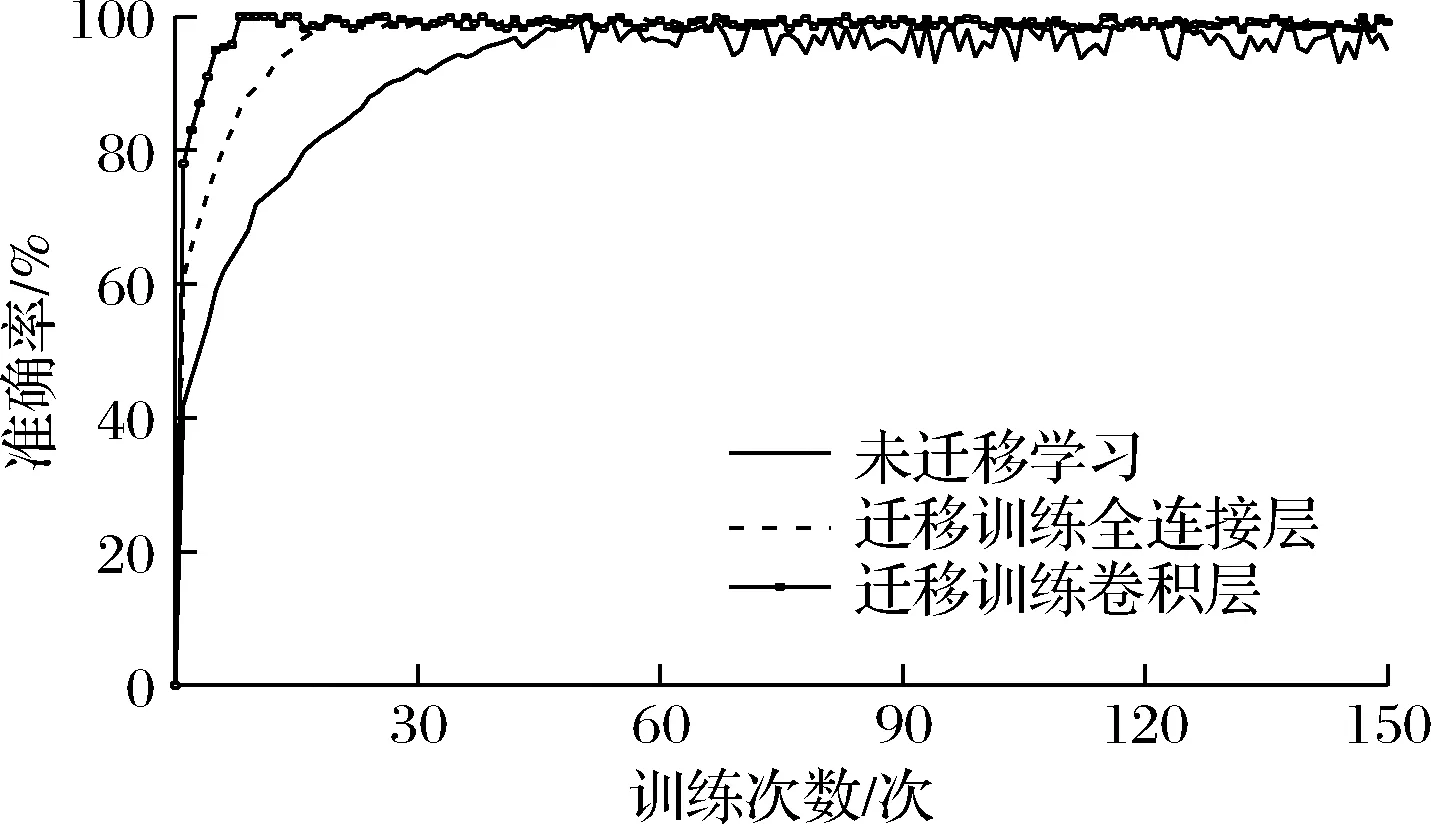
图7 准确率收敛情况图
2.2 基于数据增强的训练结果分析
由表1可知,各组准确率在训练集上的表现都要优于验证集,模型出现了过拟合。这是由于原始数据集太小,而构造的模型结构复杂,拥有出色的非线性拟合能力,可以拟合出更加复杂的函数,使网络模型在训练集上的表达能力较好,在测试集上泛化性能较差,说明迁移学习虽然可以缓解过拟合问题,但一定程度的数据扩充还是必不可少。
由表2可知,在迁移学习的基础上辅以数据增强技术后,这2组不同学习机制的识别准确率都有了1到2个百分点的提升,说明对数据集的扩充有利于缓解模型过拟合问题。

表2 基于数据增强的准确率 单位:%
2.3 识别模型对比实验
为进一步验证模型的识别效果,相同实验条件下对比了BP(back propagation)神经网络、VGG模型及GoogLeNet V1模型对牛肉新鲜度的识别效果。
由表3可知在识别生鲜牛肉准确率方面,本文研究识别方法的平均准确率高于BP神经网络、VGG卷积神经网络模型和GoogLeNet经典模型。
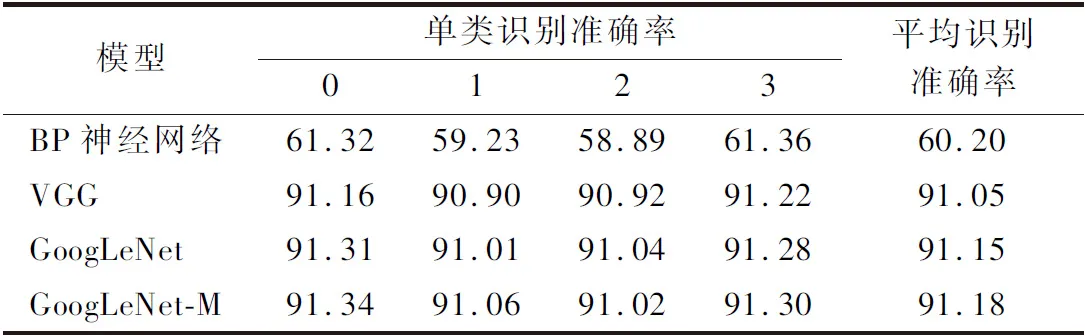
表3 模型对比实验 单位:%
传统的BP神经网络首先对牛肉图像集进行了感兴趣区域圈定、去噪、背景分割等图像预处理后,将特征矩阵作为神经网络的输入,实现牛肉冷藏时间的识别。
VGG模型复杂的网络结构使其可以拟合出复杂的数据特征,但由于其第1个全连接层的参数量大且多,对计算环境要求高,耗费大量的计算资源,与本研究模型相比而言,本研究模型的计算机资源占有率低,能够实现更快收敛速度。
GoogLeNet经典模型与本研究模型在识别准确率上相差不多,但2个模型的运行时间差异明显,GoogLeNet 模型的训练时间需3 h,GoogLeNet-M模型的训练时间需1.5 h,降低50%,表明改进后的模型在保证准确率的基础上,大幅度降低模型运行时间,提高识别效率。
3 结论
本研究在GoogLeNet模型基础上进行结构改进,缩减模型前端卷积层数量及Inception模块个数,引入迁移学习理论辅以图像数据增强技术进行模型训练,主要得到以下结论:
(1)基于迁移学习理论的模型实验结果表明,引入迁移学习理论能够使模型在训练中能更快达到稳定状态,有效缩减了模型收敛时间,且经过迁移训练的卷积层权值和偏差使模型在测试上达到更理想的效果。
(2)基于图像增强技术的模型实验结果表明,使用数据增强技术在一定程度上能够缓解小数据集在复杂网络结构上产生的过拟合问题,体现了数据集规模在模型训练中的重要作用。
(3)识别模型的对比实验结果表明,本研究所建立模型与BP神经网络相比能对牛肉新鲜度达到更好的识别率,与VGG深度卷积网络及GoogLeNet经典模型相比,在保证平均准确率的基础上,本模型耗费相对较少的计算资源。
