乌兹别克斯坦留学生普通话声调习得的实验研究及建模*1
2022-09-30朱益琳厦门大学海外教育学院
朱益琳 厦门大学海外教育学院
王 杨 杭州电子科技大学理学院
刘掌才*2 杭州电子科技大学人文艺术与数字媒体学院、法学院
提 要 本研究通过声学实验的手段考察了乌兹别克斯坦留学生习得普通话声调的系统表现,并在此基础上构建了数学模型。实验结果表明:总体而言,乌兹别克斯坦留学生习得普通话声调情况不太理想,调值和调域都和标准普通话有一定的差距。同时,不同性别对留学生习得普通话声调的时长没有显著差异。最后,我们在总体实验数据的基础上构建了乌兹别克斯坦留学生习得普通话声调的数学模型,以期为乌兹别克斯坦留学生和汉语教师提供相应的学习和教学辅助。
一、引言
近年来,随着中国综合国力的增强,特别是“一带一路”倡议的大力展开,地处中亚交通要冲的乌兹别克斯坦与中国的交流更为紧密。无论是经济往来还是文化交流,语言相通是关键。乌兹别克斯坦国内掀起了一股“汉语热”,前往中国学习汉语的学生不断增加。这促使越来越多的学者关注针对乌兹别克斯坦留学生的汉语教学研究。
截至2020年3月,研究检索到与乌兹别克斯坦留学生汉语习得相关的论文共20篇。其中,研究教学发展现状的15篇、教材编写2篇、口语偏误3篇。较具代表性的研究有:李雅梅(2012)详细总结了乌兹别克斯坦汉语教学的发展历程、现状及不足,强调了目的语环境对汉语教学的影响;刘蒙(2017)通过访谈录音搜集语料,探究了乌兹别克斯坦中级汉语水平学习者口语中典型词句偏误,并分析了主要偏误的类型;汪启凯、杨新璐(2017)通过语音实验绘制出了乌兹别克斯坦留学生汉语一级元音格局图,对比研究了乌兹别克斯坦留学生和汉语母语者一级元音的发音状况,并提出了教学建议。这些都为了解乌兹别克斯坦汉语教学现状、研究具体的教学方法提供了有益参考。
总体来看,针对乌兹别克斯坦留学生的汉语习得研究较少,且大多集中于对教学经验的总结,科学实验的定量实证研究不足,特别是关于普通话语音习得的研究还有较大空间。因此,本文从声调入手,展开研究。另外,数学建模可以让我们更加科学地探寻事物的本质,分析其变化轨迹并做出假设。本文通过语音实验,建立数学模型,以期从更客观的角度发现乌兹别克斯坦留学生普通话声调习得的具体情况及相关规律,并为教学研究提供参考。
二、实验说明
(一)实验对象
本次参与实验录音的乌兹别克斯坦留学生共两男一女,其母语均为乌兹别克语。为方便分析,研究代称他们为M1号、F1号和M2号。他们的汉语学习时间分别为四年、一年半和五个月。另外,该研究还选择了一名汉语母语者参与实验,录制标准普通话声调数据进行对比分析。
(二)实验材料
考虑到实验对象的汉语水平,本文从留学生初级汉语词汇中选取阴平、阳平、上声、去声各声调单字10个(如表1所示)作为录音材料,录音时每个字重复三遍。为避免实验者有不认识的生字,影响录音效果与实验分析,我们为所有单字标注了拼音,并提前预留了1—2分钟给留学生准备。

表1 实验用字
(三)实验设备及数据处理
本次实验录音软件为Praat,16位单声道,采样率为11,025赫兹。语音分析软件采用由南开大学自主研发的Mini-Speech Lab,用于基频的提取和修改。最后通过Excel软件对声调T值进行整理、计算和制图。录音时,实验对象每个字读三遍,共得单字样本3×10×4×3=360个,有效样本3×10×4×3=360个。
我们采用石锋提出的T值计算方法,T值法可以建立声调的绝对音高和五度值之间的对应关系。其计算方法为:T=[(lgx- lgb)/(lga- lgb)]×5(石锋、王萍,2006)。其中,a为调域上限频率,b为调域下限频率,x为测量点频率。所得到的T值就是x点的五度值参考标度。
(四)T值和五度值的转化
我们得到每组实验数据十个采样点的原始基频数的平均数后,开始确定每个声调的五度值。T值范围只在0—5度之间,根据刘俐李(2006)提出调系规整的“界域”和“斜差”,我们在处理实验数据时,T值与五度值的对应关系如表2所示。

表2 T值与五度值对应关系
三、实验结果
我们将从声调格局、声调空间及单字音时长等方面展开分析。
(一)声调格局对比
首先,我们将实验对象与汉语母语者的声调五度值进行对比,如表3所示,并制得声调格局图,见图1、图2。
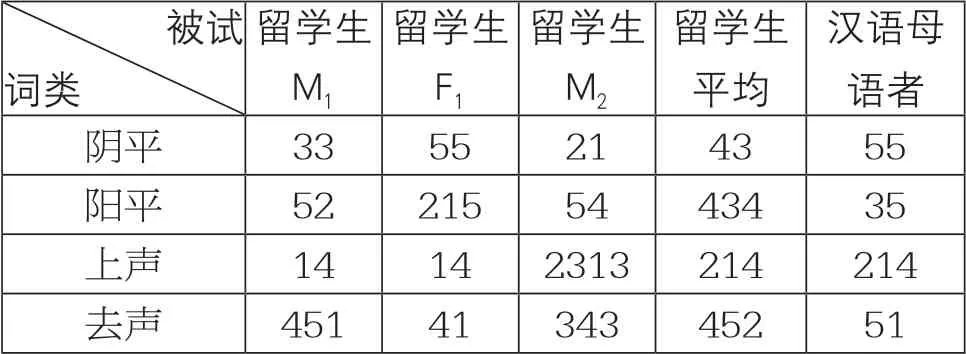
表3 乌兹别克斯坦留学生与汉语母语者五度值对比

图1 汉语母语者标准普通话声调格局
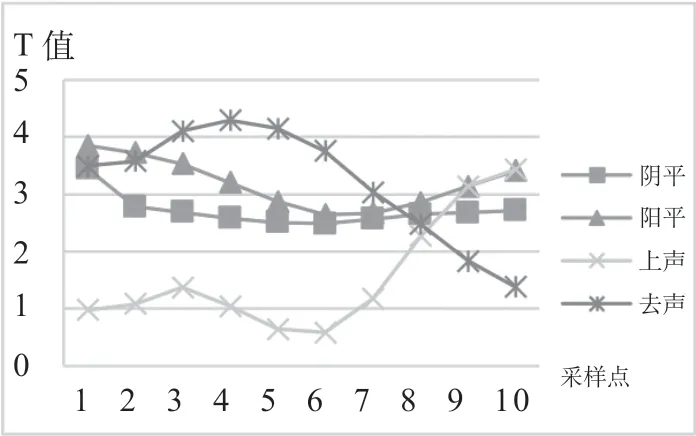
图2 乌兹别克斯坦留学生普通话声调格局
将三名实验对象的实验数据取平均值,我们发现乌兹别克斯坦留学生普通话声调有以下特征:乌兹别克斯坦留学生阴平调值较低,调域偏低,调型与标准调型有所出入,声调格局曲线没有保持稳定的水平状态;阳平调型问题较大,起调偏高,而调尾偏低,因此声调曲线呈现出向下的弯折,说明实验对象在语言习得时没有很好地将阳平和上声区别开;上声调型不标准,上声为“降升调”,实验对象在正常的弯折前多出现了个倒“V”弯折,这使得他们的上声发音听起来有些“洋腔洋调”;去声调型不正确,起调偏低,声调曲线末端值偏高,使得调型中间出现了向上的弯折,没有直接从5度降到1度,发音不彻底、不利落。
(二)声调空间图分析
为了形象地看出乌兹别克斯坦留学生声调在空间上的格局变化范围,我们通过下面两个公式计算出各声调平均值及单个声调的标准差。并在此基础上,制得实验对象声调在二维空间上的变化范围图,见图3、图4、图5、图6。
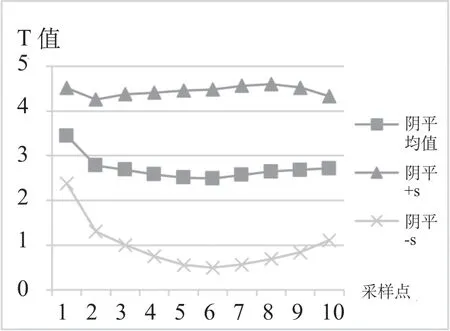
图3 乌兹别克斯坦留学生阴平声调空间
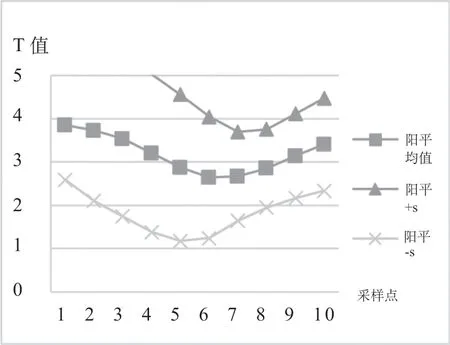
图4 乌兹别克斯坦留学生阳平声调空间

图5 乌兹别克斯坦留学生上声声调空间
公式(一):单声调平均值x=(n=1, 2, …9, 10)
公式(二):单声调标准差
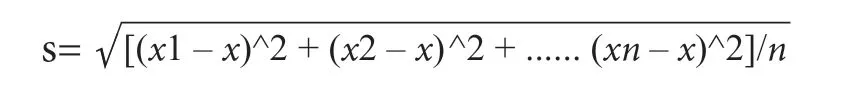
从乌兹别克斯坦留学生的单声调空间图可以清楚地看到其声调的二维平面曲线及变化波动的上下限空间范围。这些上下限之间的空白段,是我们研究乌兹别克斯坦留学生汉语声调习得的波动与演化的可能空间。尽管个体样本较少、样本间差异较大,但这些都是在声学空间范围内的,是可控的区间。
从乌兹别克斯坦实验对象的单声调空间图可以看出,去声和上声相对稳定,差距最小,阴平的变化波动范围最大。
乌兹别克斯坦留学生普通话声调习得的阴平空间波动范围大,上下限基本呈平行状,偏误主要体现在调域不够高。阳平的波动上下限也基本呈平行状,有很大的波动空间,这表明不同阶段学习者习得这两个声调的偏误差距较大。
上声声调在后段差异较小,说明留学生能基本掌握上声“降升调”的特点。去声的调尾波动较大,具体到声调调值的表现就是他们去声的51很难从5准确降到1,有较大的波动空间。
(三)单字音时长分析
声调偏误的形成除了与音高有关外,还可能受时长的影响。由图7可知,三名实验对象的单字音绝对时长中,上声用时最长,接下来依次是阴平、阳平、去声。这反映了面对难度较大的“降升调”——上声,学习者会下意识地放慢语速、花费更多的时间来发音。

图7 乌兹别克斯坦留学生单字音绝对时长
实验对象学习阶段的不同,可能也会对单字音的发音时长带来影响。其中M1学习汉语时间最长(四年),并且通过了HSK4级,因此他对普通话声调相对较熟悉,阳平、上声和去声单字音用时最短。M2学习汉语时间最短(五个月),对普通话声调的熟练度较低,因此四声的单字音用时最长。F1学习汉语时间为一年半,学习水平在三人中处于中等,因此四声的单字音用时也大致居中。
四、数学建模——声调变化三维图
数学建模的优点在于可以通过数理方法对语言现象进一步开展定性、定量研究(聂娜,2007)。在姚云(2012)研究的基础上,我们结合上述实验数据,建立了一个可从斜率差、函数差及残差和三方面生动体现实验对象声调习得状况的三维数学建模。需要说明的是,一方面,我们仅将数学建模作为一种方法手段,以此探讨数学建模对于留学生语音习得情况立体可视化的可行性,并非要得出统一的标准模型数据;另一方面,该模型建设还处于初步探索阶段,本实验仅借此小做尝试。
实验语音学的发展使得语言习得研究愈加趋于图像化、可视化,而传统的声调实验研究只能从平面的二维反映留学生调型和调值的习得情况。通过数学建模,我们能将二维升级至三维,更加立体直观地呈现留学生语音习得情况,进一步解决二维图难以体现的实验对象发音自然度问题,促进语音实验的可视化发展。
发音自然度是指语言习得者发音时喉头肌肉控制声带的紧张程度,是相对于母语者而言的。可以理解为听感上与标准普通话的相似程度,相似度越高越自然,反之则越不自然,即我们常说的“洋腔洋调”。不同人的具体发音状况各不相同,数学建模建立的三维图像能为学习者提供个性化、可视化的习得状况分析。
本研究将普通话调值、调型、发音自然度合为一个整体的标准。声调基频函数差越小,说明乌兹别克斯坦留学生声调调值与标准普通话差异越小;声调基频斜率差越小,说明他们的声调调型越接近标准普通话的声调调型。
如何体现发音自然度呢?如果声调的数值距离模型函数很近,均匀地分布在曲线两侧,说明声调比较平稳;如果声调数据距离模型函数很远,分布也不均匀,说明声调不自然,不流畅。所以使用声调原始数据点与模型函数的距离之和作为参照,这个“和”就是点到直线的差的累计值,即“残差和”。声调基频残差和越小,说明实验对象声带控制越自然,发音越“地道”。
首先,我们利用T值及声调空间时长等数据拟合出了乌兹别克斯坦留学生单声调曲线的数学函数模型,表4为乌兹别克斯坦留学生普通话习得声调模型参数。

表4 乌兹别克斯坦留学生普通话习得声调模型参数
从表4可以看到,阴平为y=3.769的常数函数,阳平为y=6.1894★x^2-7.4708★x+4.3210的一元二次函数,呈抛物线状。而标准普通话的阳平曲线更趋近于一元一次函数的直线状,这说明实验对象的阳平声调与标准普通话阳平声调差距较大。上声为y=8.4318★x^2-5.6168★x+1.2070的一元二次函数,a=8.4318,大于0,曲线开口向上,符合标准普通话上声的“降升调”走向。去声为y=-4.3473★x+5.5160一元一次函数。
通过与标准普通话进行对比,我们分别得出这四个声调模型的函数差、斜率差及残差和。乌兹别克斯坦留学生单字声调表现在以下几个方面。第一,阴平函数差数值较小,斜率差为0,残差和小于0.11。这说明留学生的阴平调值与标准普通话虽然有差距,但相对较小,调型标准。发音时声带肌肉较为稳定,比较接近汉语母语者的普通话发音。第二,阳平函数差较大,斜率差大,残差和小。表明留学生的阳平调值与标准普通话调值差距较大,调型偏误尤为明显,不过发音时声带控制自然。第三,上声函数差偏大,斜率差数值较大,残差和较小。说明留学生的上声调值和调型与标准普通话的调值和调型差距较大,发音时声带较为自然。第四,去声函数差小,斜率差小,但残差和较大。表明留学生去声的调型与调值较为接近标准普通话,不过发音时声带肌肉不够放松自然,稳定性不强。这也是上文提到的乌兹别克斯坦留学生去声声调格局曲线有明显不自然弯折、普通话发音不地道的原因之一。
五、声调数学建模的现实意义
通过前面的实验研究,我们发现建立的数学模型能客观、立体地反映乌兹别克斯坦留学生的普通话声调习得情况。除了能促进普通话语音实验研究的可视化发展外,本实验还能为汉语教师、汉语学习者及汉语学习软件的开发提供帮助和借鉴。
对于汉语教师来说,了解学生的语言习得情况,是及时调整教学方式和帮助学生更好地学习汉语的重要条件。一般来说,汉语教师主要通过语感听辨和书面测试来了解留学生的普通话声调习得情况,缺乏客观标准和量化方式。本文通过实验,对留学生普通话声调拟合函数的斜率差、函数差及残差和的数值进行比较,将调值、调域和发音自然度三方面合为一个整体,能生动、立体地反映学生普通话声调习得的情况。通过这种方式,教师定期组织一定的语音测试,就能科学地量化学生普通话声调习得情况,获得更好的教学反馈,及时做出教学调整,帮助学生纠正发音。在本实验中,教师可通过听音辨音、图画演示和动作法等方式强化学生的调域感知,让学生理解55调和44调的区别。另外,为学生多营造自然轻松的口语操练氛围,鼓励他们敢说、多说。指导他们放慢发音速度,放松声带肌肉,把每一个拼音声调都发得饱满完整。
对于汉语作为第二语言的学习者来说,他们主要是通过教师的正音、书面练习和听音模仿等途径来获得学习反馈,纠正自己的声调发音。我们初步建立的数学模型,可以帮助留学生从数理的角度理解普通话声调,更好地了解自己的发音情况,从而做出相应调整。对于乌兹别克斯坦留学生来说,他们以前可能只是知道自己汉语发音不地道,却不知道具体该在哪个方面有所提高和改进。声调数学模型可以使留学生懂得应该从调值、调域和自然度哪个方面来调整,多加练习,在平时发音过程中注意保持喉头放松。
另外,我们的声调建模还能为语言学习软件的开发提供借鉴参考。目前,市场上针对留学生的汉语语音学习App主要有“Chinese Pinyin Game”“声调分听”“魔力小孩拼音”“Pinyin Table”和“拼音一点通”等。它们主要通过故事线闯关、游戏测试、听音选词、选音填空等方式来强化留学生汉语语音,特别是强化声调的辨识和运用能力。但它们在测试环节和成果反馈环节都有所欠缺,即缺乏科学、可量化的方式来衡量留学生的语音习得情况并为学习者提供相应改进建议。随着声调建模研究的进一步完善,如果能在软件设计的过程中加入声调数学建模的相关内容,再完善后期用户互动页面,就能为语言学习者提供更加全面、系统与科学的学习反馈和建议。
总之,将数学建模运用到汉语作为第二语言习得研究中的尝试,既可以促进学科的建设与完善,也能为汉语学习,特别是为声调学习提供参考。
六、结语
本文通过声学实验的方式建立数学模型,以实验手段获取乌兹别克斯坦留学生普通话单字声调发音数据。通过上述分析我们得出以下结论。
乌兹别克斯坦留学生普通话声调发音整体偏低,阴平和去声发音表现得尤为明显。现实生活中,乌兹别克斯坦留学生的阴平虽为平调,却不到位,原因是调域偏低。他们并未完全理解和掌握上声的发音规律,将上声与其他三个声调混淆,发音不饱满、不完整,将目的语普通话的声调泛化。另外,实验对象的声调发音受母语语调影响明显,其声调的起点或终点总是习惯性地偏高或偏低。
通过初步尝试,我们发现,数学建模对于汉语作为第二语言的实验研究的三维可视化发展具有实用价值,对教师教学、学生学习和相关学习软件开发都有较大的参考意义。
希望本次声学实验研究能为面向乌兹别克斯坦留学生的汉语教学提供参考,减少声调习得过程中的偏误,丰富汉语教学理论研究,尤其是为面向中亚地区的汉语教学提供理论指导。
