基于粒子群优化算法的数字档案馆个性化信息挖掘方法*
2022-09-29刘之阳
刘之阳,张 君
(1.中国南方电网有限责任公司,广东 广州 510000;2.南方电网数字电网研究院有限公司,广东 广州 510000)
1 引言
档案馆存储的信息越来越多,需要用更智能化、科学化的方式,为利用者提供数字化信息。数据库中包含的信息类型更加多样,在使用数字档案馆查询资料时,搜索内容与搜索关键词之间的匹配度逐渐下降,需要有对应的数据挖掘方法提高搜索内容的匹配度。早在20 世纪末期,国外相关研究就提出相关数据挖掘方法在图书馆中应用的文章,主要强调数据挖掘技术具备获取数据来源、处理数据的能力等[1-2]。而国内相关研究中,众多学者针对数字档案馆与数字图书馆之间的高度相似性,如文献[3]提出的基于双重模糊模拟的直觉模糊向量关联规则挖掘方法,文献[4]提出的考虑多粒度属性约简的关联规则挖掘方法,深入研究与发展不同的信息挖掘方法。
但是,以上数据挖掘算法应用过程中,存在支持度和置信度较低,影响关联规则挖掘精准度的问题,因此,此次研究结合粒子群优化算法创新数据挖掘方法,为数字档案馆的发展,提供更可靠的技术支持。
2 数字档案馆个性化信息挖掘方法
2.1 粒子群优化算法划分数字档案馆个性化信息
PSO在初始化种群过程中,假设每个简单个体为一个粒子,用来描述问题中的可行解,以随机初始化的形式开始处理数字档案馆个性化信息。这一过程将个性化信息划分作为问题,假设该问题的维度为W,初始化的总粒子数量为M,利用W维向量描述其中第i个粒子,则存在:

公式中:,为一个正整数;Zi表示集合、ziW表示向量。已知粒子更新自身位置的速度向量同样为W维,则将粒子信息代入目标函数,计算该值:

公式中:Si表示速度向量集合;siW对应单个粒子的速度向量。利用上述公式完成粒子评价后,第三步需要记录粒子自身经历的最佳位置,保证粒子更新过程中的位置最优,所有粒子根据自身经验选择下一步的目标位置,通过下列公式得到最优个体,为群体进化提供满足条件:

公式中:Pbest表示个体最优位置集合;piW表示个体最优向量。此过程中群体会共享个体之间的最优信息,从而整个群体也会形成一个种群最优信息,即:

公式中:xbest表示整个种群最优信息;xw表示对应的维度向量。PSO 根据上述所获结果,最后开始迭代寻优,粒子群通过重复上述过程找到最好的解,此过程中的PSO按照下列公式更新粒子信息:

公式中:t、t+1表示相邻的迭代次数;sij(t+1)、zij(t+1)分别表示t+1 时刻下,所有粒子的速度与位置;a1、a2表示控制粒子接受不同信息的约束参数;γ1、γ2表示提高PSO 随机性的参数。PSO 按照上述四组步骤获得最优解,根据最优解、次优解等计算结果,划分数字档案馆个性化信息。
2.2 挖掘数据整体关联规则
关联规则可以描述信息之间的隐含关系,从而进一步寻找不同类型数据之间的联系,根据数字档案馆个性化信息划分结果,计算支持度、置信度的值,然后通过设置关联规则支持度阈值,实现对数据整体关联规则的挖掘。关联规则的支持度,就是部分个性化信息与总体信息之间的关系,可利用一个概率描述。当某一类个性化信息初始支持度较低时,说明关联性较强,影响挖掘结果,所以PSO按照下列公式,获得支持度参数:

公式中:A、B表示PSO 划分后得到的不同个性化信息;G(A B)表示包含A、B的概率。而关联规则的置信度,描述需要A信息的同时又需要B信息的比例,是对关联性强弱的进一步说明,也就是证明挖掘的关联规则的可靠程度。根据现有研究可知,较低的置信度不具有意义,所以通过下列公式求解置信度的值:

公式中:G(A|B)表示需要A信息的同时,又需要B信息的比例;support(A B)表示包含A信息和B信息的支持度;sup-port(A)表示A信息的支持度。PSO设置关联规则支持度阈值为Y,根据上述过程获得所有频繁项集合,比较公式(7)与预设置信度阈值之间的差异性,当时,得到数据整体关联规则挖掘结果。图1是PSO的数据整体关联规则挖掘流程。
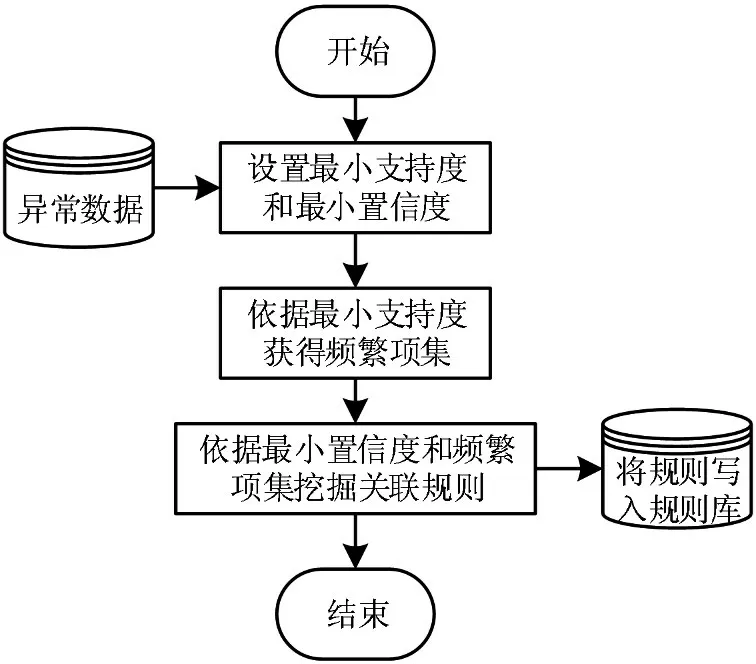
图1 粒子群优化算法数据关联规则挖掘流程
按照图1的关联规则挖掘流程,得到数字档案馆个性化信息之间的不同程度的关联,为实现数据匹配完成整体信息挖掘提供依据。
2.3 匹配数据完成个性化信息挖掘
基于粒子群优化算法的信息挖掘,需要融合信息划分流程和关联规则,通过匹配数据完成个性化信息挖掘。假设数字档案馆的数据库为U,根据PSO的划分可知,数据库中的个性化信息集合为{A,B,C,…},则随机一类个性化信息在U中的出现概率为:

公式中:I表示个性化信息集合中的随机项;、分别表示I在U中出现的总次数、U中已经记录的此类个性化信息的总数[5]。对随机项I进行加权操作,得到的权重值为:

公式中:ω表示权重;q表示个性化信息适用性的大小。加权处理档案馆信息查询记录,设置查询记录的权重为ωt(U),则存在:

公式中:f 表示经验值;n表示查询次数;|U|表示数据库中满足要求的信息集合总数。将上述内容与公式(6)和公式(7)融合,得到:

公式中:m表示数据库的反馈次数。通过上述融合过程,将个性化信息划分与关联规则融合,按照融合过程挖掘数字档案馆中存在的个性化信息,根据信息匹配概念,利用个性化信息特征和关联规则匹配信息,计算公式为:

公式中:σ是PSO根据公式(11)得到的两个特征相关性参数,当该值为1 时,证明两个个性化信息具有强相关性;R、F表示数据库信息、查询信息特征向量;O、K表示数据库信息、查询信息特征关系矩阵;α 和β 为R和F的二进制向量;φ和η为O和K的可能矩阵[6-7]。通过上述公式匹配按照关联规则获得的信息,至此,基于粒子群优化算法,实现数字档案馆个性化信息挖掘。
3 实验与分析
3.1 准备过程
目前的数字档案馆已大规模应用于各类型企业中,因此,选择一家具有数字化档案馆的大型工业企业,作为实验测试背景环境,测试此次提出的挖掘方法。所以实验准备过程中,以企业数字档案馆系统实际应用中,用户上一年度的搜索历史数据作为职工对数字档案馆的信息搜索情况,经分析发现,搜索TN类资料的职工同时还会搜索TP类资料,且这类职工的比重最大;其他搜索TH 类资料的职工也搜索TM 类资料,这类职工的比重占据第二;还有职工同时搜索TD 类和TF 类资料,这类职工比重占据第三,第四、第五等更多内容不再详细列出,以该调查数据为前提进行实验。为保证测试结果具有一定说服力度,引入文献[3]方法(测试b组)和文献[4]方法(测试c 组),通过比较三组方法的应用效果,得到具体实验结论。为了便于区分测试组,将三组方法分别作为测试a组、测试b组以及测试c组,选择该企业的一间信息加工室作为临时实验室,分别将三组方法安装到临时实验室的三台电脑中。已知电脑型号一致,均为510S,使用的系统为Windows 10,内存为DDR4,CPU为i5-10400,硬盘7200r/min,满足实验测试要求。实验开始前选择5 台设备进行开机测试,没有问题后分别在计算机上安装不同方法,剩余2 台设备作为备用,防止出现系统崩溃和硬件损坏带来的时间消耗,准备结束后开始实验。
3.2 关联规则挖掘情况
分别利用三组方法,挖掘该企业数字档案馆数据库中,上一年的职工搜索内容,并计算对应的支持度和置信度生成关联规则。表1为三组方法应用下,部分信息的关联规则挖掘结果。

表1 关联规则挖掘结果
根据上述三组方法的关联规则挖掘情况来看,测试a组的TN-TP 置信度最高、TH-TM 和TD-TF 的置信度位列2、3位。测试b组的TN-TP置信度位列第2位、TH-TM和TD-TF 的置信度为3 位、1 位;测试c 组的TN-TP、THTM、TD-TF 的置信度,分别位列第1 位、第5 位和第2 位。通过得到的关联规则挖掘结果可知,测试b 组和c 组的置信度排名,与实际调查结果不一致,可能影响最终的挖掘结果。
3.3 信息挖掘效果分析
继续测试,三组方法根据对应的关联规则挖掘结果,挖掘TN-TP、TH-TM、TD-TF 三组资源信息,图3 为挖掘覆盖度评价结果。
根据图3 显示的挖掘覆盖度曲线可知,测试a 组的挖掘覆盖度更高,测试b组次之,测试c组最差。
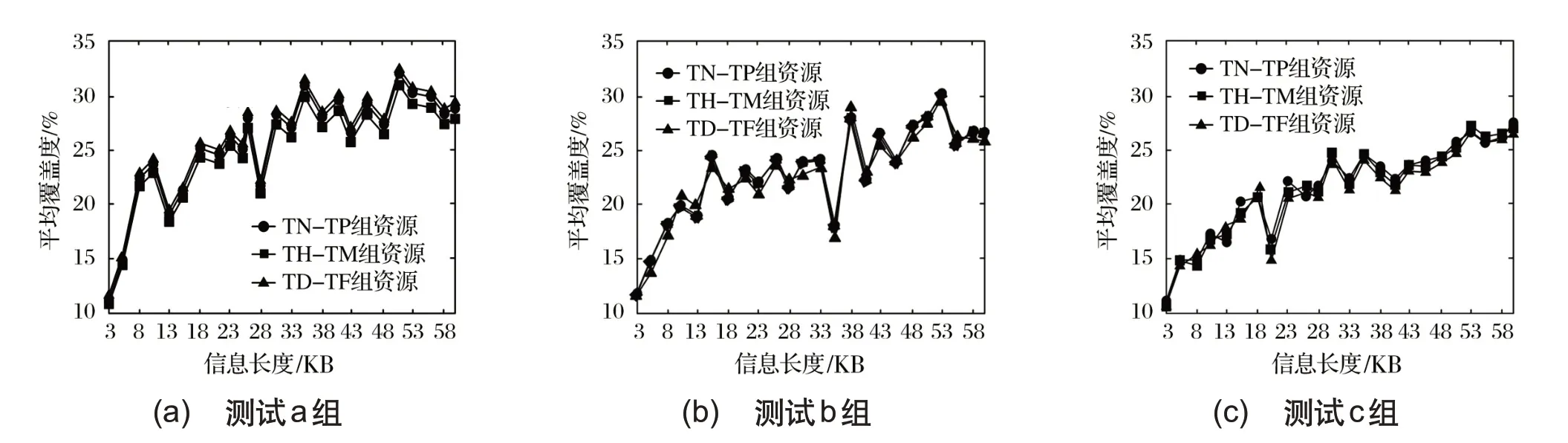
图3 挖掘覆盖度曲线
利用仿真软件和企业数字档案馆提供的MAYH 数据集,模拟不同长度的个性化信息,依靠评价平台生成挖掘平均难度散点图,如图4 所示,图中每一个节点都代表不同长度信息的挖掘难度评价结果。

图4 挖掘平均难度散点图
根据图4 显示的挖掘平均难度散点图可知,测试a 组的挖掘平均难度接近0.5,测试b 组和测试c 的挖掘平均难度更接近0.8。综合两组测试结果可知,基于粒子群优化算法的挖掘方法,获得的关联规则更准确,能够得到更完整的挖掘结果。
4 结束语
利用粒子群优化算法的多模态数据处理功能,重新设置的关联规则提取办法,为最终的个性化信息挖掘,提供更为精准的约束条件。但综合此次研究内容来看,没有对数据预测、数据清洗等内容深入说明,同时,在实验中选择的测试样本数据不够多,因此,今后在时间以及经验允许的前提下,需要补充此次没有详细描述的内容,扩大实验规模,用更多数据证明新方法的有效性。
