基于改进YOLOv3网络的卡尔曼社交距离检测与追踪
2022-09-29焦帅吴迎年张晶孙乐音
焦帅, 吴迎年,3*, 张晶, 孙乐音
(1.北京信息科技大学自动化学院, 北京 100192; 2.智能物联与协同控制研究所, 北京 100192; 3.高端装备智能感知与控制北京市国际科技合作基地, 北京 100192)
2020年初,新冠肺炎(COVID-19)的出现改变了人们的日常生活。据统计,截至2021年年底,全球因新冠肺炎导致的死亡人数已经超过了400万人,并且这一数字还在不断上涨。为了预防新冠肺炎的传播,在佩戴口罩的同时,保持一定的社交安全距离是必要的。社交距离的检测与追踪,对于提高人们在常态化疫情下的安全保障具有重要意义。
对社交距离的检测方法有2种:一种是目标检测方法[1];另一种是目标追踪方法[2]。检测是跟踪的基础,跟踪是检测的应用。第一种方法在不同方面有着不同的应用:如在对对象进行检测时用到的特征[3];用一些人工智能的方法进行进一步的挖掘[4]。前者将对象的一部分固定特征当作检测区域,并努力将图像或视频帧与模板进行匹配[5]。但是时代在发展,许多新技术掩盖了过去的光辉,以至于后者的优点被不断放大。现在,利用更加智能的人工智能的方法不仅在精确度上大大地提高,并且还可以像录像一样连续跟踪。
目标跟踪这一类方法其实有着多种类型:其中一种类型就是对单目标这种物体进行跟踪[6]。而另一种类型顾名思义,就是对多目标也就是不同的物体或者是数量上多的物体进行跟踪[7]。对单目标跟踪实际上开始的时候将单个目标框在原始图像上,然后对它下一位置进行一些合理的预估。多目标跟踪与但目标跟踪最大也是最多的不同之处恰恰就是前者所要面临的问题更多。例如,一些出现的物体它们是不是新的东西;这些物体经常出现在图像的各个角度方位,并且更甚的是它们不确定有多少也就是数量无法预测;另外,这些物体在运动方面也有着不能确定的模式,无法做到视频图像的这一帧与下一帧之间的具体联系。因此,中外学者充分发挥了他们自己的优势,研究了不同种类型的相关工作。近几年发现的多重假设跟踪[8]或数据关联过滤器[9]很好地处理了多目标跟踪问题,虽然效果非常不错,但做出决策的速度上实在太慢,并且与跟踪物体的配对方面的准确性方面会很大程度上减少,因此很少使用。Rezatofighi等[9]在联合概率数据关联公式的基础上,将算法目标整体进行了更为细致的改良,完成了更为复杂性的问题。Wojke等[10]使用人工智能的方法将边缘上的方形形状整理出来,并以此为延伸,对物体的表现和它的动作进行标记;Xiang等[11]将待检测物体的实际表现进行更深层次的记号刻画,并使用一些优化算法将它们进一步的关联在一起。Sun等[12]对不同画面在连续的视频中的表现进行记录,并使用各种优化算法进行合理的比对,解决了对追踪的物体的预测优化结果。
事实上,检测是追踪的基础,因此目标检测算法的好坏对目标追踪所产生的结果有着十分重要的影响,甚至可以说是起着决定性作用。为此Redmon等[13]提出了YOLOv3(You Only Look Once version 3)算法,该算法不仅在构成方面十分简易,并且对物体检测的快慢与正确与否都非常出色。但是,就算是传统的YOLOv3算法也会在进行社交距离检测中无法同时保证实时性与准确性,存在特征提取不足和特征利用率不高的问题,导致漏检率与误报率较高。
因此,为了解决现有的目标检测算法在社交距离检测中无法同时满足检测的实时性、准确性以及在复杂场景中存在遮挡、小尺度目标等问题,现主要对YOLOv3算法的改进展开研究,提出基于YOLOv3网络的改进算法DPPY(dilated pyramid-pooling with YOLOv3),并结合卡尔曼滤波[19]与修改过后的匈牙利算法[20]以期对行人进行更有效的社交距离检测与追踪,在预防新冠肺炎病毒的传播方面具有重要意义。
1 距离检测模型设计
将摄像头调整好必要的角度焦点对齐路面上的行人,以此用来更好地模仿公共场所中的摄像头监控装置。对实验所处的环境进行的仿真构建如图1所示。
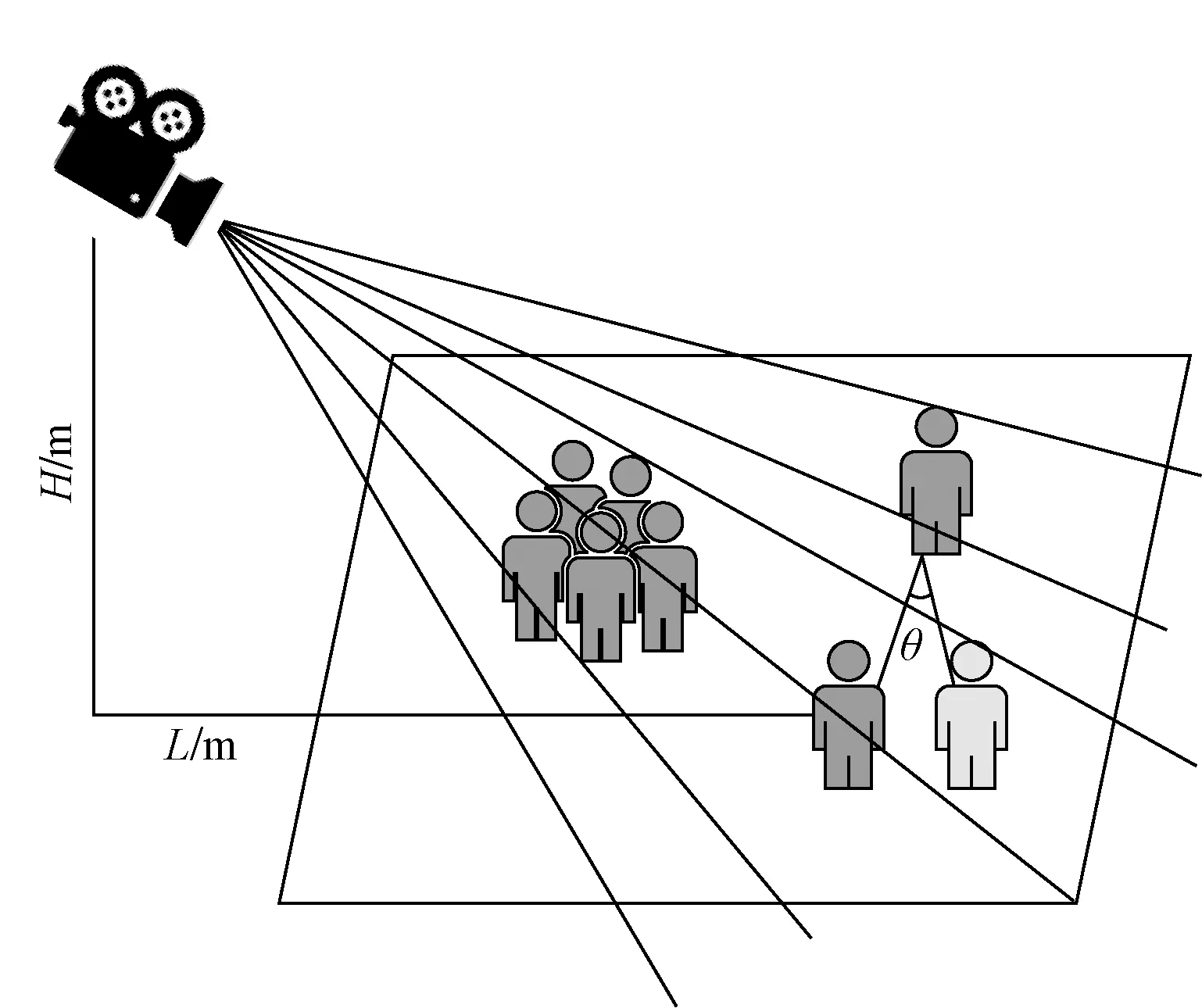
H为悬挂的摄像机与地面的垂直高度;L为悬挂的摄像机与行人的 水平距离;θ为路面行人彼此对于水平位置旋转角图1 距离测量模型Fig.1 Distance measurement model
构造该实验模型模仿对城市中行人中心点的位置使用距离运算得到彼此之间的距离,并严格使用1 m这个长度作为安全社交距离。判断被检测人员之间的社交距离与1 m之间的接近程度,上报传输给计算机。行人彼此距离计算公式[14]为
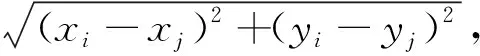
i,j=0,1,…,n
(1)
式(1)中:xi、xj为边界框中心归一化水平坐标;yi、yj为边界框中心归一化垂直坐标。
2 目标检测算法
2.1 YOLOv3算法原理
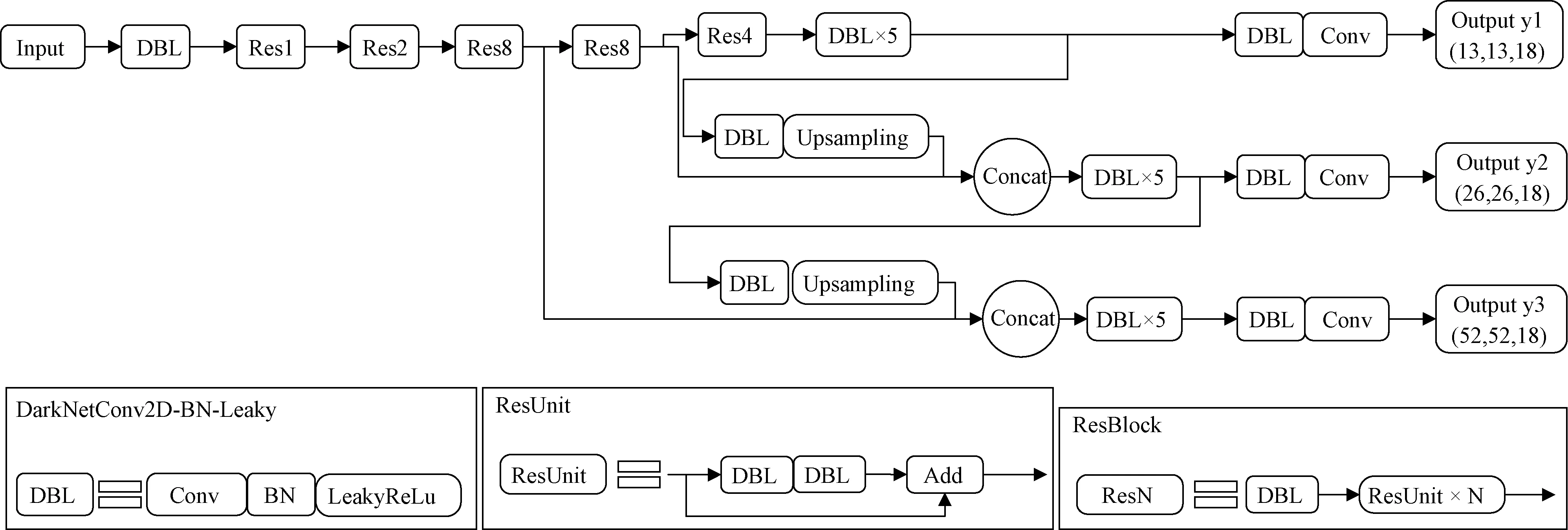
Input为输入;ResUnit为残差单元;ResN为残差块;Upsampling为上采样;Concat为连接融合;Conv为卷积;Output为输出图2 YOLOv3网络结构示意图Fig.2 Network structure diagram of YOLOv3
YOLOv3网络的结构如图2所示,从图2中可以发现,该网络将一种名叫DarkNet-53网络用于它的核心,在它的核心网络中,有多达52个卷积被用来使用,再加上全连接层后,便达到了一种拥有53层卷积的深层结构。因此,该网络通过组合卷积-批归一化-线性修正单元(DarkNetConv2D-BN-LeakyReLu, DBL)将进入其中的原始数据进行整理,紧接着对图像数据中蕴含的深层的结构状态进行归纳,并以特征图的形式进行处理,将这种形式的图进行不同规模、不同大小的采样处理,进而搭建出一种名叫特征金字塔的模型结构,使不同形状不同特征的输入图像特征数据得以更加方便地融合,这样更能充分地考虑到整体效果。最后,将经过特征金字塔网络(feature pyramid networks,FPN)后的三个加强特征利用YOLO Head获得预测结果,预测结果特征层的形状分别为(13, 13,18)、(26,26,18)、(52,52,18)。
2.2 空洞卷积
空洞卷积[15](dilated conv)起源于语义分割,由于对更大感受野的包容性比较强,并且还能处理不同大小的特征图数据,对细小数据与数据的密集型生成上有着较为显著的作用,因此,在YOLOv3的核心网络中试着添上这一卷积结构,这样做的好处有许多:一是可以在进行图像数据处理时不至于导致过大的计算量;二是对于图像数据的分辨率优化方面有着更为明显的作用,并且这一优化建立在更大的感受野上。因此,可以利用这些好处获取更为精致的细节信息。下面给出针对这一空洞卷积核计算公式[16]:
fd=fo+(fo-1)*(Ecoe-1)
(2)
(3)
式中:fo为原始卷积核大小;fd为空洞卷积核大小;Ecoe为膨胀系数;ln为第n层感受野的大小;ln-1为n-1层感受野大小;si为第i层的步幅大小。该模块如图3所示。图3中Dilated Conv2D表示空洞卷积层,Conv2D表示卷积层,膨胀系数Ecoe为2,感受野对于这样的处理将得到更好的扩展,扩展到7。并且特征图的大小根本不会变化,好处是有利于图像数据特征之间的链接,对细小物体的处理能力得到了加强。

图3 空洞卷积模块Fig.3 Dilated convolution module
2.3 密集型网络连接单元
密集型网络连接单元,也叫作DenseNet[17]。这种网络是从残差网络(residual neural network, ResNet)演化而来。ResNet网络的核心是后面的单元与这之前的单元之间的相互连接,层层递进,有效解决梯度消失等问题,获得更为深度的延伸结构。不同的是,密集型连接单元DenseNet在ResNet的基础上对层与层之间的交互方式做了改变,真正做到了更为系统、更为全面地不漏掉任何一层的网络结构。密集型连接单元的基本公式为
xl=Hl([x0,x1,…,xl-1])
(4)
式(4)中:xl为网络在第l层的输出;Hl(·)为非线性转化函数[16]。
在DarkNet-53核心网络中尝试着放入密集型连接单元,该结构如图4所示。
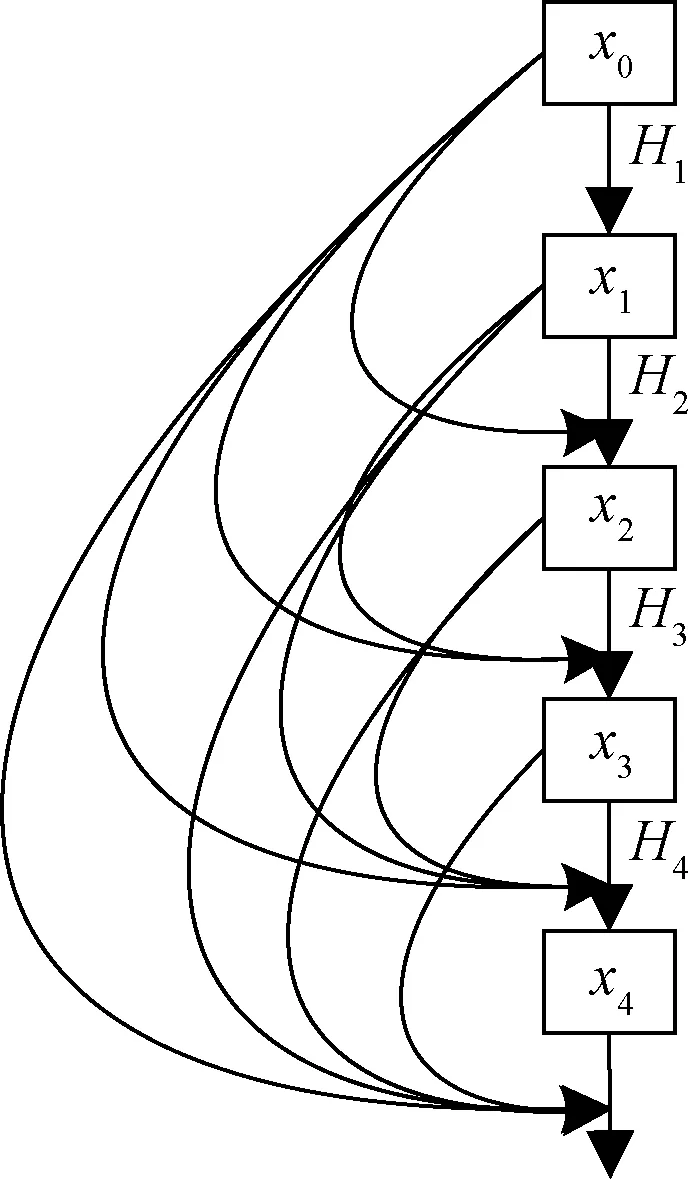
图4 DenseNet结构Fig.4 DenseNet structure
由图4可知,原本不相关的图片数据生成的特征图也能互相连接。这样做的好处有:首先是对提取到的特征反复利用从而更快、更高效地起到关键作用;二是网络结构中存在的庞大的参数得以减少,提高速度。
2.4 空间金字塔池化
空间金字塔池化结构(spatial pyramid pooling,SPP)在做输入图片的提取等关键操作上,常常存在着不成比例的尺寸问题,如拉伸等扭曲现象。为了解决这一困扰多年的问题,He等[18]通过改变池化操作中的尺度,并对这些变换后的图像数据特征和它下面紧接着的全连接层互相连接。受到上述启示,本文考虑在最后一个用于提取图像特征的卷积层中运用金字塔池化算法进行重构,重构后的SPP网络结构如图5所示。
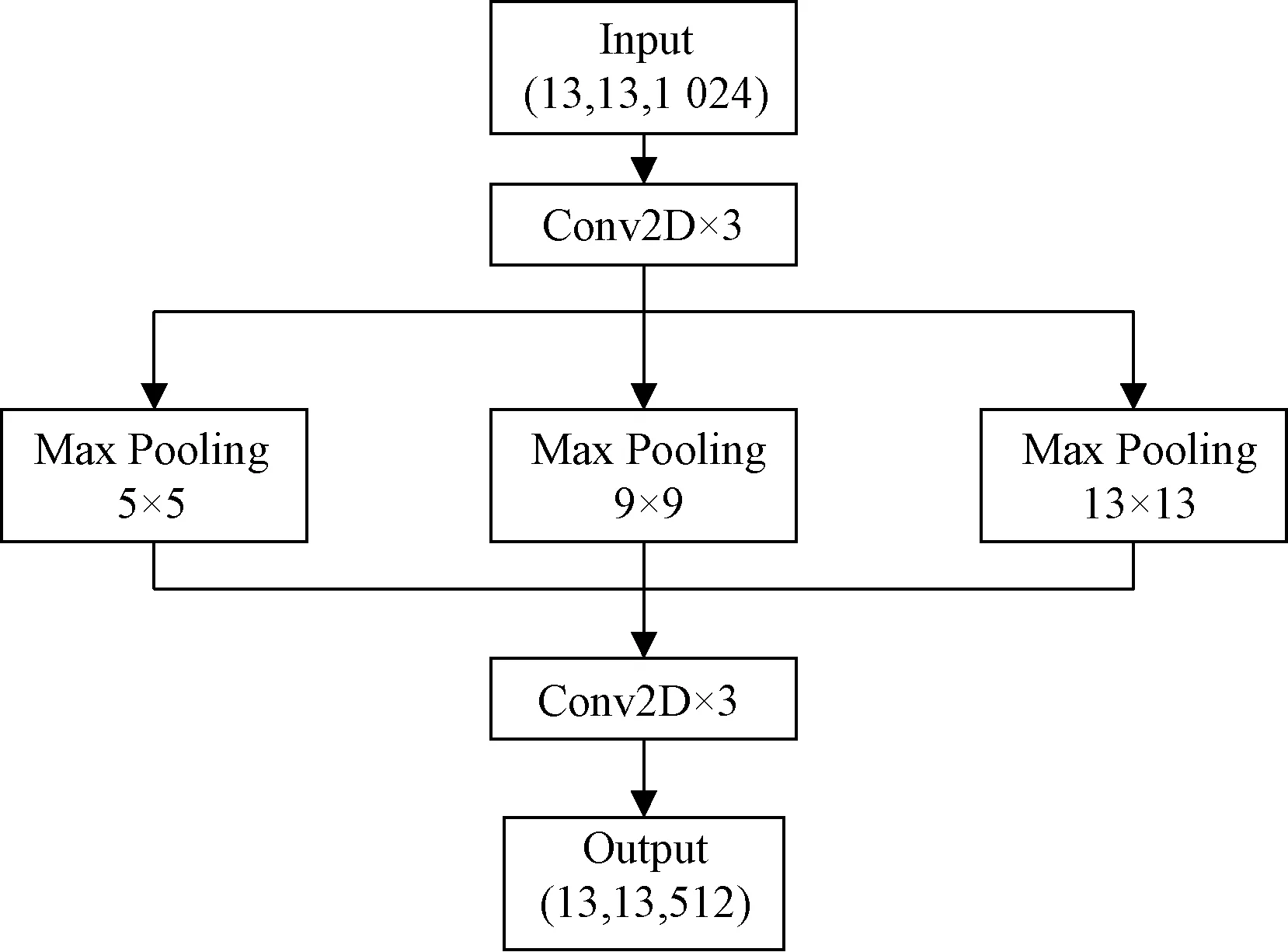
Max Pooling为最大池化图5 空间金字塔池化模型Fig.5 Spatial pyramid pooling model
从图5可以看出,该模型首先使用DarkNet核心网络最后一个图像数据特征提取层的特征图作为该结构的输入,然后进行3次卷积操作;接着利用3个不同大小的池化层进行最大池化(Max Pooling)操作,再经过3次卷积操作得到最后的输出。这样做的优势在于对图像数据特征的采集更为有效与多元,并优化感受野的感受范围。
2.5 DPPY算法
将空洞卷积、密集型网络连接单元、空间金字塔池化结构加入YOLOv3的DarkNet-53核心网络中,将改进后的算法命名为DPPY。改进后的网络如图6所示,在改进的网络中,空洞卷积模块所选用的膨胀系数Ecoe为2,从而扩大特征图的感受野;其中的DBL模块表示批归一化(BN)、卷积(Conv)、修正线性单元(Leaky-ReLu)的组合;ResUnit模块表示残差结构;在DarkNet-53主干特征提取网络中用于提取52×52、26×26、13×13的残差块间进行密集型连接单元连接,用DenseResN表示,其中N表示DenseNet中密集链接的残差结构的个数。在DarkNet核心网络的最后一个图像数据特征处理层DRes4后尝试转变结构特征,引入空间金字塔模型,将其与全局特征信息进行融合得到更丰富的特征表示,进而提升预测精度。
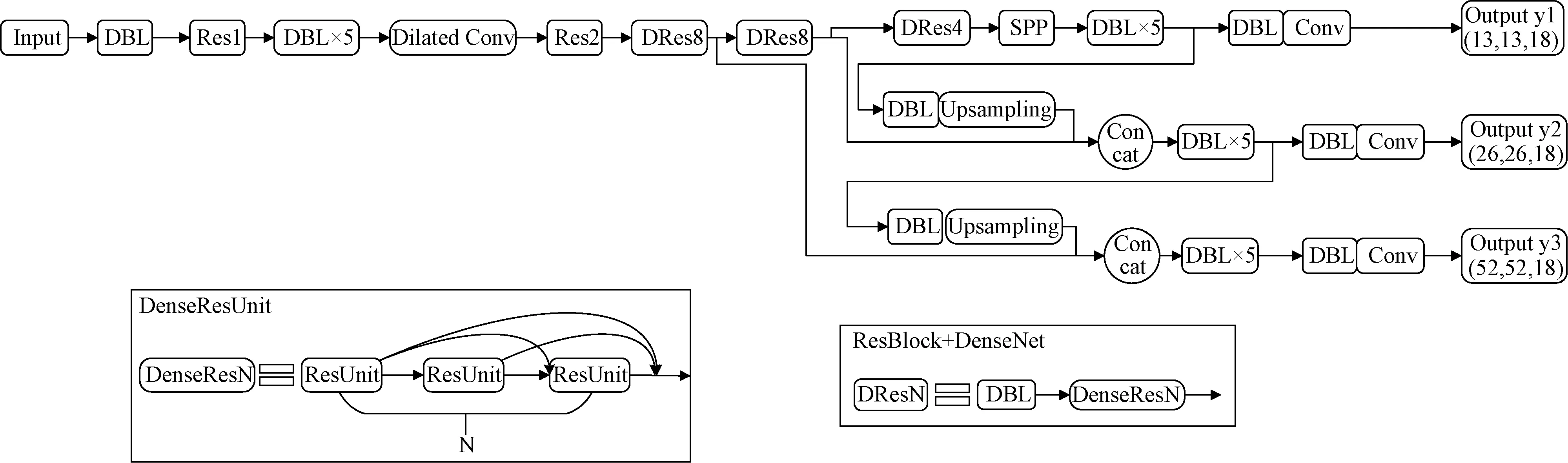
图6 DPPY 网络结构示意图Fig.6 Network structure diagram of DPPY
3 目标追踪算法
3.1 卡尔曼滤波器
卡尔曼滤波[19]通俗意义上来说是一种预测系统下一状态的优化算法。它具有简单易懂的原理,在拥有非确定含义的系统结构中发挥着更新与预测作用。
该滤波器的模型如图7所示。完整的计算方程如下。
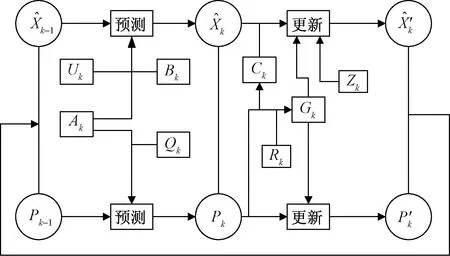
图7 卡尔曼滤波示意图Fig.7 Kalman filter schematic
(1)预测过程。
(5)
(6)
(2)更新过程。
(7)
(8)
P′k=(Ik-GkCk)Pk
(9)

3.2 改进的匈牙利算法
匈牙利算法[21]可以用来求解二分图的匹配问题。通俗来说,对于图论中的一些经典匹配问题比如说二分图匹配就会涉及一些求它们的增广路径的问题。因为非匹配点存在于增广路径的头尾,匹配点则是剩余的部分,边的匹配和点的匹配在进行变换的过程中也不会因为这样的改变而受到牵连,匹配的结果不会被打坏;该方法步骤如下。
(1)任意取一个匹配M(可以是空集或者只有一条边)。
(2)令S是非饱和点(尚未匹配的点)的集合。
(3)如果S是空集,则M已经是最大匹配。
(4)寻找为进行交错路P而指定的起点,标记为u0。
(5)如果P是一个增广路,则令M=(M-P)∪(P-M)。
(6)如果增广路与P不相等,那么就要在S中舍去u0,转到步骤(3)。
循环迭代以上步骤,最终得到二分图中的最大匹配。这便是匈牙利算法的核心思想。为了匹配目标追踪中前一帧与当前帧也可以借鉴这个想法,因此,要是想让一个以上的物体方便地进行彼此之间的连接,就要考虑这些物体什么时候出现,什么时候又离开,也就是消失,并且他们的检测框身份标签(id)不能发生变化,也就是同一个物体id要一样。利用本文提出的DPPY算法,首先对多个目标物体进行检测操作,记录并标记出与之相关的信息,然后辅以卡尔曼滤波进行更为细致的预测操作,如果只将面积交并比作为唯一评估因素会引发意想不到的问题,很可能会因为待追踪的物体彼此之间靠得十分近导致产生可怕的结果。综合分析了以上可能出现的问题,现运用新的颜色直方图的形式进行相应操作,并与上述面积交并比进行深度融合,更好地对靠得过近的物体进行识别,计算公式为
Mi,j=αMCom(i,j)+βMCoe(i,j)
(10)
式(10)中:i为检测结果;j为预测结果;MCom(i,j)为二者面积的交并比;MCoe(i,j)为外观关联系数,可通过巴氏距离得到;α、β为权重系数。将改进后的匈牙利方法应用在最终结果的匹配上,并进行必要的关联操作,以此更好地服务于物体变多产生的轨迹跟着变多的追踪问题处理上。
4 整体算法流程
如图8所示,先用DPPY算法对视频中的当前图像帧的物体进行检测,计算每两个物体间的距离,判断是否超过1 m,然后选取卡尔曼滤波器与匈牙利算法完成对这些物体的检测与追踪任务。主要步骤如下。
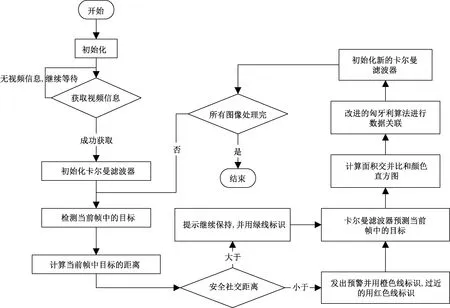
图8 实验流程图Fig.8 Experimental flow chart
(1)输入所截取的第一幅图像数据,经过DPPY方法处理,输出相应检测结果。
(2)将数据传给卡尔曼滤波器,这样做的好处是这张图像中的物体会被实时计算。实时反馈给计算机,判断人员社交距离是否为安全距离并给出相应状态,用橙色连接线表示距离小于安全距离,红色连接线表示小于安全距离的1/2,也就是0.5 m左右,绿色连接线表示大于安全距离。
(3)为了防止线条密集度过大,采用设定安全距离阈值上限2 m,大于这一距离的将不会被用连接线标出。
(4)将下一幅图像数据进行输入,经过卡尔曼滤波器和修改后的匈牙利算法处理后,完成相应的任务目标操作。
(5)判断是否已将所有图像数据处理完,若有,则重新返回步骤(2);若没有,则表示图像数据已全部处理完成,关闭程序。
5 实验结果与分析
VS-Code中通过Anaconda平台搭建Python虚拟环境。选择Python3.8版本作为编程语言,并配合Pytorch1.8版本深度学习框架来搭建网络模型。使用NVIDIA GeForce RTX 2070用来加速训练。
5.1 数据集
选取CityPersons数据集[22]进行训练和验证。该数据集包含了丰富的环境变换下的人物图像数据。经过查阅官网(www.cityscapes-dataset.com)数据,并进行综合比对,决定训练数据的数量规定在2 975张,500张图片用于验证,训练集包含19 654个人物,验证集包含3 938个人物。这些人物的细粒度标签占比如图9所示,由图9可知步行的人占了绝大多数,并且密度较高,平均一张图片上大约有7个人物。
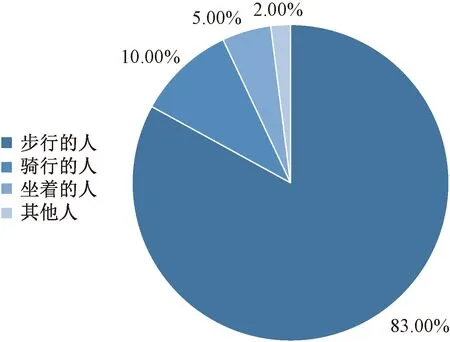
图9 CityPersons上的细粒度人物类别Fig.9 Fine-grained person categories on CityPersons
5.2 评价指标
将以下评价指标运用在评估这个提出的算法性能上。
(1)查准率(Precision)和召回率(Recall)。
(11)
(12)
式中:Pprecision为查准率;Rrecall为召回率;若所要研究的物体类别与实际的物体类别相同,则用TP表示这样的个数;若正好相反,则将相反的个数用FP显现出来;还有一种情况,那就是如果物体的确在里面但是由于一些原因没有被分析出来那么就用FN来标记。
(2)平均准确率(average precision,AP)指标以及平均准确率均值(mean average precision,mAP)指标。

(13)
(14)
式中:N为所有类别的数目。用一种名叫P-R曲线的方式来进行有效的评估,这个曲线下方的面积大小即为某类目标的AP值。
5.3 本文算法与YOLOv3算法比较
分别使用YOLOv3算法和本文所提出的DPPY算法进行对比试验,如图10所示。从图10中可以看出,YOLOv3算法在一定情况下会发生无法捕捉到小物体的问题,并且容易发生漏检。而本文所提出的DPPY算法则很好地弥补了上述问题的发生,提高了算法的鲁棒性。

图10 本文DPPY算法与YOLOv3算法在 数据集上的表现Fig.10 Performance of DPPY and YOLOv3 on dataset
图11展示了两种算法各自生成的P-R曲线,并以可视化的方法直观地展现出来。从图11可以看出,相比于传统的YOLOv3算法,本文算法在对行人的目标检测中取得了较好的性能。YOLOv3算法只取得了82.1%的AP,而本文的算法DPPY的AP则高达91.2%,相比YOLOv3算法提高了9.1%的AP。
从图12可以看出,在进行小尺度行人目标(tiny)、中尺度行人目标(medium)、大尺度行人目标(large)检测时,YOLOv3算法的mAP分别为0.754、0.809、0.858,而本文算法DPPY的mAP则达到了0.843、0.891、0.936。与YOLOv3相比,本文算法DPPY的mAP分别提高了8.9%、8.2%、7.8%。

图11 DPPY算法与YOLOv3算法的P-R曲线对比Fig.11 Comparison of P-R curve between DPPY algorithm and YOLOv3 algorithm
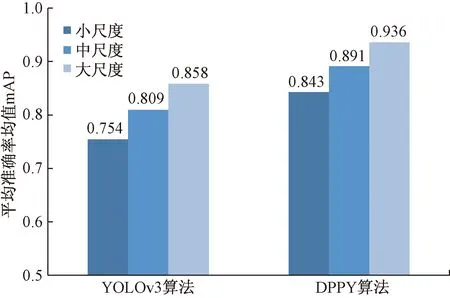
图12 本文算法与YOLOv3算法在各尺度下结果对比Fig.12 Comparing the results of this algorithm with those of YOLOv3 algorithm at different scales
5.4 实验过程
为了验证社交距离检测与跟踪的准确性与实时性,将安全社交距离设定为1 m,摄像机高度距地面1.8 m,实验设计与结果如下。

图13 社交距离检测与追踪实验Fig.13 Detection and tracking experiments
如图13(a) 所示,当真实场景中的第一个人与第二个人距离为0.98 m时,摄像头将检测到的图像传给计算机,并实时显示出检测的社交距离0.974 m,并用橙色连接线标识,表示第一个人和第二个人之间的距离小于安全社交距离,处于警戒状态。与此同时,第二个人与第三个人真实距离为1.1 m,计算机显示出的检测的社交距离为1.092 m,并用绿色连接线标识,表示此时第二个人和第三个人的距离处于安全社交距离范围内。如图13(b)所示经过5 s,当真实场景中的第一个人移动到距第二个人距离0.49 m时,第二个人与第三个人距离为1.7 m时,摄像头将检测到的图像传给计算机,并实时显示出检测的社交距离为0.498 m,并用红色连接线标识,表示第一个人和第二个人的距离小于安全社交距离的1/2,处于危险状态。与此同时,显示第二个人与第三个人距离为1.683 m,计算机显示绿色连接线,表示第二个人与第三个人的距离处于安全社交距离范围内。
由于行人移动的不确定性,导致所测量的数据具有一定的误差率,因此进行了多组实验, 如表1所示,其中R表示行人间的真实距离,ri表示第i帧摄像头所检测到的行人间的距离。
由表可知,使用YOLOv3算法的误差范围在0.068~0.096 m,帧率范围在21~23帧/s;而使用DPPY算法的误差范围为0.011~0.042 m,帧率范围在32~34帧/s。这表明本文所提出的算法在社交距离检测与追踪中的实时性与准确性都有所提高。

表1 真实距离与目标检测距离Table 1 Real distance and target detection distance
6 总结与展望
为了在疫情期间实时且准确地对行人间的社交距离进行检测与追踪,针对现有目标检测算法YOLOv3进行了改进,提出了DPPY算法。
(1)受到空洞卷积的启发尝试进行该模块的引入,并通过计算确定了所需的膨胀系数大小。
(2)为了更好地对互不相关的图像数据特征进行更为深入的链接,引入了密集型连接单元,承担了大部分的层与层之间的深度融合作用。
(3)为了更好地解决图像数据特征在不同尺度下的扭曲变形问题创造性地尝试引入空间金字塔池化模型用来处理输入问题。
(4)最后通过连续图像中物体的行动方式形成的前后位置间的不同进行相应的预测,工具选用卡尔曼滤波器的方式来进行,而为了防止距离过近引发的问题在匈牙利算法的基础上进行了改进操作,融合颜色直方图与交并比,并根据行人间的社交距离的变化给出相应的预警信息。
(5)根据检测到的行人间的社交距离的不同给出不同的提示信息,并用红、橙、绿三种连接线表示极度危险,危险和安全三种信息。
实验结果表明,不仅在AP值上DPPY算法非常良好,有着91.2%的不错数值,而且还能胜任基本的人类肉眼感到舒适的34帧/s的检测帧数(30帧/s为人类肉眼不觉得卡顿的舒适范围尺度)。相比于YOLOv3算法,该算法在实时性与准确性上有着很大的提高。接下来的工作将对算法进行探索与改进,使算法能在弱光环境下对行人目标的检测与追踪取得更好的效果。
