基于对抗学习的深度迁移问句分类方法
2022-09-26亢文倩
亢文倩 苏 磊
(昆明理工大学信息工程与自动化学院)
问答系统作为数据检索的一种方法,能够通过检索使用者提供的自然语言问句,给使用者返回比较简洁和精确的回答。 当前,问答系统已经成为自然语言处理(Natural Language Processing,NLP)技术研究领域的热点。问答系统中的重要研究——问句分类,能够根据答案的类别对答案加以约束, 从而精确定位答案并检验正确答案,所以问句的分类精度会直接影响问答系统的品质与性能。
传统分类方法的主要问题是文本表示是高纬度、高稀疏的,特征表达能力较弱,需要人工进行特征工程,导致其成本较高。 而深度学习利用CNN[1,2]、RNN及LSTM[3~5]等网络结构自动获取特征,去掉繁杂的人工特征工程,实现了端到端的解决方案。 但由于深度学习对人工标记数据的依赖性强,导致其存在训练数据不足、模型可解释性差等问题。且深度学习模型在处理NLP任务时,都建立在训练数据和测试数据拥有共同特征空间和相同数据分布的情况下,无法满足不同领域的问句分类要求。
迁移学习是将已经掌握的其他场景的相关任务和知识转移到新的场景来适应新任务、学习新知识,针对标注数据稀缺性问题行之有效。 近年来,迁移学习在问答系统,例如问句分类、语义分析及问答匹配等方面取得了很好的效果。 针对问句分类任务, 只考虑领域不同但任务相同的领域自适应[6]。 迁移成分分析(Transfer Component Analysis,TCA)[7]试图将源域和目标域的数据映射在核希尔伯特空间中,再利用最大平均差异最小化两个域的距离,在文本分类实验中平均正确率为0.686 5。联合分布适配[8]同时适配源域、目标域的边缘分布和条件分布, 分类效果优于TCA。YOSINSKI J等对深度神经网络是否可以迁移进行了研究,提出一种衡量深度学习网络不同层的通用性和特殊性的方法, 即判断该层的特征从一个任务迁移到另一个任务的程度[9]。 HOWARD J和RUDER S提出一种适用于NLP中任何任务的有效迁移学习方法——ULMFIT,ULMFIT虽然可以学习上下文之间的关系,但是无法并行化,给模型的训练和推理带来了困难[10]。VASWANI A等使用self-attention的方式对上下文进行建模,提高了训练和 推 理 的 速 度[11]。 DEVLIN J 等 提 出 一 种 基 于Transformer Encoder的预训练模型Bert,可以直接学习文本的上下文信息,在11个自然语言处理任务上,相对RNN更加高效、能捕捉更长距离的依赖关系[12]。LAN Z Z等在此基础上提出ALBERT模型,降低了内存消耗、提高了训练速度[13]。
然而,庞杂的新领域数据总是含有各种干扰信息和噪声,深度迁移模型遭遇对抗攻击时所表现出的脆弱性, 给实际应用带来了极大的风险。GANIN Y等最先将对抗学习引入迁移学习领域,重点关注领域之间可以进行迁移的特征,使判别器区分特征是来自源域还是目标域从而进行对抗学习[14]。 但是这种方法的模型分类精度较低,无法满足问句分类的需求。 故笔者提出一种基于对抗学习的深度迁移问句分类方法(A-ALBERTFiT),由于自然语言处理领域的对抗训练往往是在词嵌入层上进行的,从本质上来说是一种提高模型泛化能力的正则化手段, 故而在模型训练时,向词嵌入添加扰动生成对抗样本,并对模型进行对抗训练。
1 模型结构
1.1 词嵌入优化
作为短文,问句包含的关键词较少,提取的特征有限,不利于NLP下游任务。 传统的NLP数据增强技术包括同义词替换、反向翻译、文本表面转换、噪声添加和交叉扩展方法,这些方法致力于允许机器自动生成文本数据和获得更多的训练数据。 在数据特征提取阶段,在不改变问题含义的情况下, 扩展数据集中每个问题的单词量,使模型能够获取到更多的问句语义特征,从而提高分类精度。
如图1所示, 对原问句进行同义词扩展。 例如, 输入问句 “what makes friendship click does spark keep going”,从中抽取出核心词(core word)“friendship”, 然后在关系知识库中查询“friendship”的同义词或近义词,并将搜索得到的结果随机插入原问句中,即得到问句“what makes friendship click make does spark perish friendly keep going relationship”。
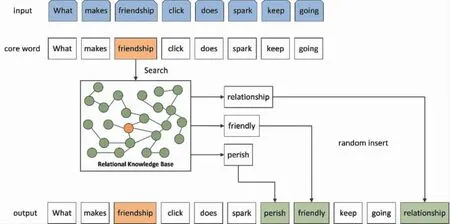
图1 同义词扩充过程
实验选取WordNet[15]作为关系知识库,用于检索核心词的同义词。WordNet是一个依据词义组织词汇信息的结构化知识库, 通过节点结构的词集合体现单词的语义关系, 构成较完善的基于语义信息的单词网络系统。WordNet中含有属性不同的集合, 如同义词词集 (Synset)、 类别词集(Class word)和含义解释词集(Sense explanation)。
依据这3个词集,选取候选的同义词,对每个候选同义词提取特征:
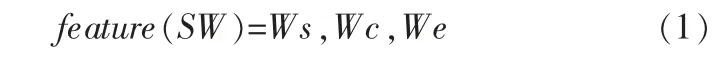
其中,Ws代表从含义解释词集中抽取的同义词,Wc代表同义词所属的类别,We代表候选同义词含义中的所有实词,SW代表单词的含义(同一个单词有多个不同含义),feature(SW)代表某个含义SW的特征向量。 通过计算3个不同含义在特征空间的距离,来获取两个含义的相似度(距离越小则相似度越大)[16]:
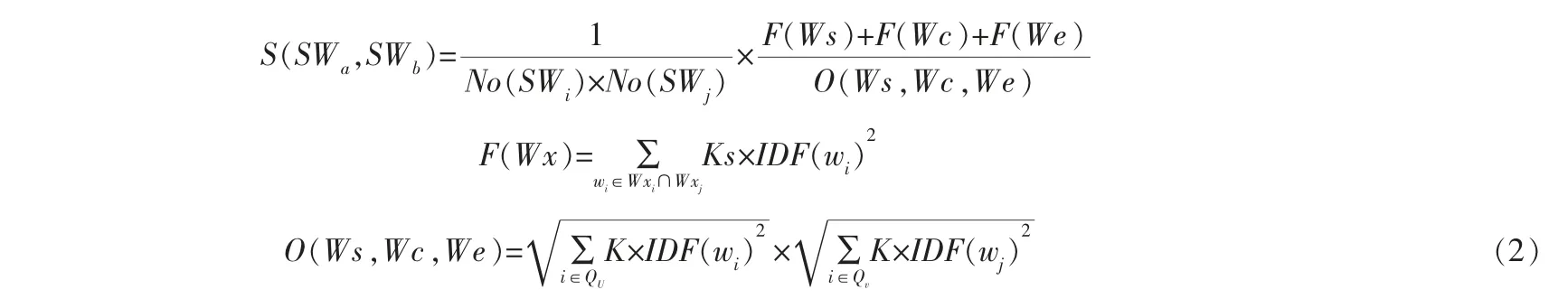
其中K∈{Ks,Kc,Ke},Ks代表同义词特征的权重,Kc代表类别特征的权重,Ke代表含义解释的权重;Wx∈{Ws,Wc,We},No(SW)代表候选词的顺序;wi代表含义SWa中出现的实词,wj代表含义SWb中出现的实词,IDF (wi) 代表单词wi的IDF值,QU代表出现单词wi的指标集,Qv代表出现单词wj的指标集。 由此可以计算出两个单词的相似度[16]:
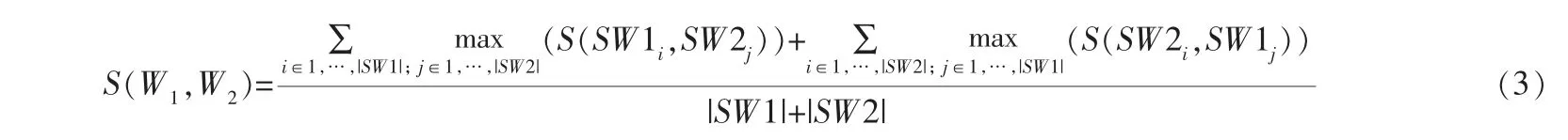
其中,W1代表单词1 (核心词),W2代表单词2(候选同义词),|SW1|代表W1的含义的个数,|SW2|代表W2的含义的个数。最后对候选同义词进行排序,取前k个作为扩充单词。
为了保证扩充效果, 往往会提取多个核心词。
1.2 对抗训练
依据MIYATO T等提出的Fast Gradient Sign Method(FGSM)来计算扰动,添加到连续的Word Embedding上产生radv,再一次喂给L-ALBERT-FiT,得到Adversarial Loss,通过和原来的Classification Loss(Cross-Entropy)进行求和即可得到新的损失函数[16]。 由于FGSM是通过模型的迭代来优化损失函数, 故在NLP领域中取得了一个较好的分类表现。
NLP任务中的对抗训练与在图像上添加扰动不同,NLP的文本表示通常为one-hot向量,理论上两个Embedding之间的欧式距离是固定的, 不存在微小的扰动。 故而NLP领域的对抗训练往往是在Embedding层上进行的, 通过对抗训练来进行数据增强从本质上来说就是一种通过正则化方法来增强模型泛化能力的手段。
为了提高问句文本表示的质量 (即Word Embedding质量) 和A-ALBERT-FiT模型的泛化能力,在ALBERT的词嵌入层中加入对抗扰动,并将生成的对抗样本用于A-ALBERT-FiT模型训练,通过最大化对抗损失、最小化模型损失的方式进行对抗训练,对ALBERT参数进行正则化。
ALBERT将问句中的每个单词转化为词嵌入vk,假设输入的每个问句x含有k个单词,模型将问句中的每个单词转化为词嵌入vk, 其相应的类别为y;由于将要对词嵌入添加扰动,且扰动是一个有界范数,在对模型进行对抗训练时,模型为了自身的分类正确率会降低扰动,学习具有相对较大的范数的词嵌入,故而要将初始词嵌入进行标准化:
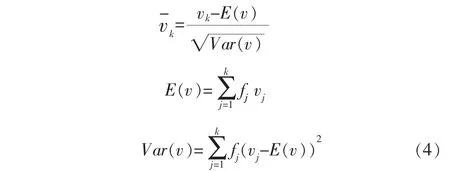
然后向标准化后的词嵌入添加扰动, 得到对抗样本,并用对抗样本和原始样本对ALBERT进行对抗训练,此时ALBERT的损失函数将发生变化:
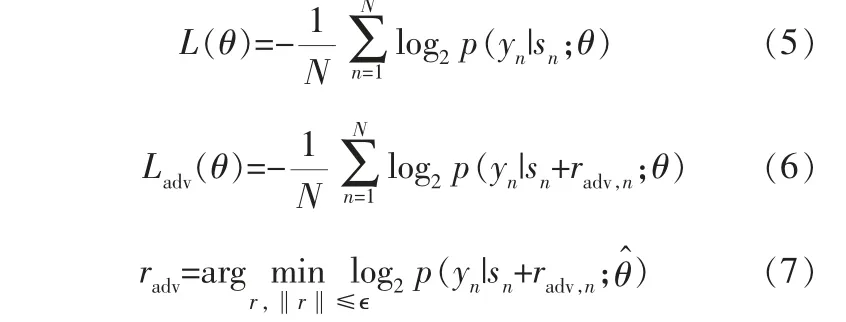
其 中,L(θ)是A LBERT 的 原 始 损 失 函 数,Ladv(θ)是加入对抗扰动后的ALBERT的损失函数,sn=[---是标准化后的词嵌入向量序列,radv是向量序列sn的扰动,n是带有标签样本的问句数量,n∈{1,2,…,N},sn+radv,n为对抗样本,根据全概率公式,“一个问句的预测类别即为其真实类别”的概率为p(yn|sn;θ),θ是模型参数。
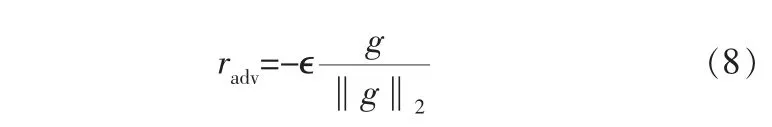
其中,g=▽slog2p(y|s;θ^)为此时ALBERT的损失梯度,‖g‖2为g的欧几里得范数的平方,▽s梯度,即对sn求偏导,为了进行梯度下降radv取负值。这样就得到了对抗扰动,生成了对抗样本。 通过最大化对抗损失、最小化模型损失的方式对模型进行对抗训练,并更新ALBERT参数;将被修改的对抗样本和原始样本一起输入到预训练过的ALBERT中, 让ALBERT对这两种样本进行分类,并在过程中更新参数θ;这样就得到了对抗扰动,然后对模型进行对抗训练,并取目标域测试集来验证模型的分类精度。
对抗训练算法中,Input: 输入源域训练问句集x,训练模型参数θ,训练分类模型损失L(θ),目标域验证集、测试集。Output:测试样本分类精度。Return:经过对抗训练的L-ALBERT-FiT。 具体步骤如下:
a. 将ALBERT在源域训练问句集进行预训练;
b. 将ALBERT生成的初始Word Embedding进行标准化得到新的词嵌入;
c. 构建对抗样本,在词嵌入上加入扰动x+radv,固定模型初始参数常量θ^, 确保参数θ在生成对抗样本时不会更新;
d. 在每个iteration中计算最大扰动, 并对radv进行更新,进而最大化对抗损失函数Ladv(θ);
e. 在更新过程中对模型进行对抗训练,最小化模型损失L(θ);
f. 取目标域验证集微调模型, 更新模型参数θ;
g. 取目标域测试集验证最终模型分类精度,对模型进行评估。
2 实验设置
2.1 数据集
数据集采用的是Yahoo answer问答数据集[17]。该数据集的字段包括问题标题、问题内容和最佳答案。 标题共有10个类别,每个类别包含14万个训练样本和5 000个测试样本, 数据集本身含4百多万个问答对。 按照不同的类别标签,将数据集划分为5个不同的领域, 每个领域含有两种类别的问句(表1)。

表1 Yahoo answer问答数据集问题标题类别
人为设定源域和目标域。 源域用于训练模型,目标域用于测试和评估。 将不同的模型在不同领域上进行实验,例如取领域A作为源域,取领域B作为目标域,进行跨领域问句分类。 每个模型各进行5组分类实验。 随机选取5 000条源域数据作为训练集,取50条目标域数据作为开发集,取2 000条目标域数据作为测试集。
对问句进行降噪后, 考虑到短文本的特点,增加数据项的数量并不符合训练目标,所以需要扩展每个数据的片段。 随机选择问题中除停止词外的50%的单词作为核心词,然后从WordNet中随机选择与核心词对应的同义词。 在原问句中随机插入同义词前后的对比情况见表2。

表2 问句同义词扩充前后对比
2.2 评估指标
在目标域问句数据集中使用模型,测试其对目标域问句的分类能力。 使用精度(Accuracy)来评价模型的分类能力:

该方法的有效性是通过计算以上指标来衡量的:精度(Accuracy)是问句分类中最常见的测量指标,#Correctly classified questions代表被正确分类的问句数量,#Total number of questions代表问句的总数量。
2.3 实验结果
问句的核心词和问句类别是高度相关的,但同一词的重要性对于不同类别的问题是不同的。模型通过同义词扩充引入新词,将模型推广到不在训练集中的单词,因此,问句的同义词扩展可以训练增加模型的泛化能力。
由表3可以看到,有4组实验明显地改善了目标域的分类效果,表明插入同义词的问句可有效扩展文本的长度、提取更多的语义特性,从而实现更好的问句分类效果、更高的分类精度。 除此之外,该方法还引入了一定数量的噪声来防止过拟合,并将同义词扩展到源域,该模型可以很好地扩展到目标域。 而在源域为B、目标域为E的实验(B->E)中,精度并没有提高,这可能是因为模型在实验中已经获得了较高的精度,如果问句文本被进一步扩展,可能会引入一定的干扰。
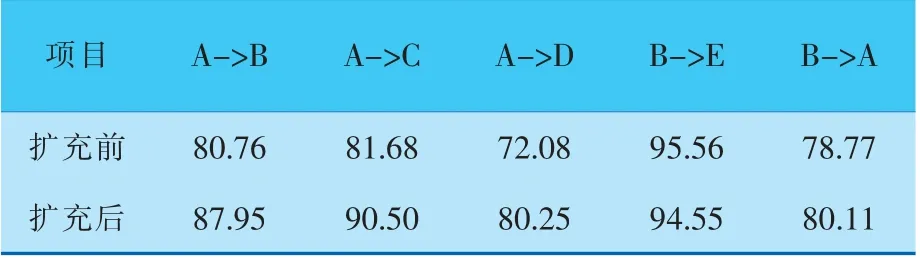
表3 同义词扩充前后模型跨域问句分类精度%
对ALBERT-FiT模型的Embedding 层添加扰动,扰动范围ϵ=0.25,嵌入维度128,隐藏维度768,注意头为12个, 参数11M。 隐藏层的激活函数是Relu,epoch的最大数量为15个, 每批执行110次迭代。 对于优化,使用Adam,初始学习率为0.000 5。每组实验进行5次,取其平均值。
同义词扩充前后模型跨域问句分类精度见表4。可以看出,A-ALBERT-FiT模型分类性能进一步提升, 其精度比没进行对抗训练的模型在5组实验中平均提升了0.8%,且模型看起来是“健壮的”。 即使对于ALBERT来说, 对抗训练有助于ALBERT的可迁移性研究。 依旧是源域为B、目标域为E的实验中,精度提升极其微弱。 由此可以得到: 原始精度较高的模型一般较难受到攻击,原因是精度较高的模型抗干扰能力较强,故而对抗训练对其精度提升是微乎其微的。
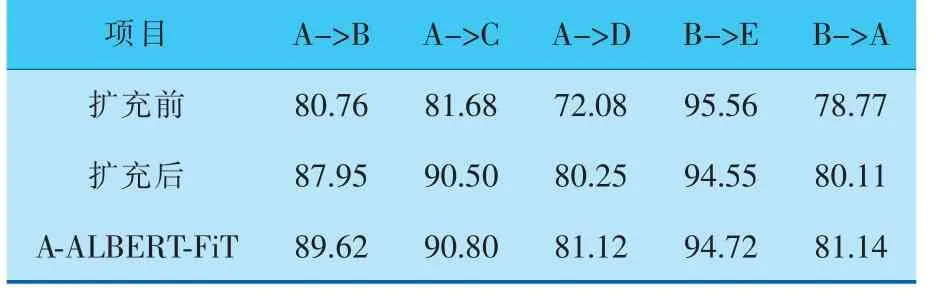
表4 同义词扩充前后ALBERT-FiT和A-ALBERT-FiT跨域问句分类精度 %
为了可视化对抗训练对词嵌入的影响,对比不进行对抗训练与进行对抗训练得到的词嵌入。用余弦距离作为度量衡量不同词嵌入向量p、q之间的相似性,其值越小表示对抗样本越接近真实样本,表达式如下:
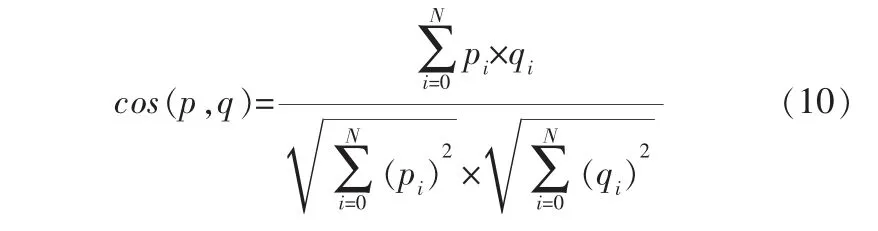
表5为对抗训练后10个与“good”和“bad”最近邻的词嵌入,它们都有经过训练的嵌入。 由表5可以看出,“good” 的最近邻词嵌入都含有积极的含义,“bad”的最近邻词嵌入都含有消极的含义,这是由于对抗训练确保了问句的含义不会因为加入小的扰动而发生改变,故而这些单词不会发生含义的交叉,例如“bad”出现在“good”的前10名最近邻词嵌入,或者“good”出现在“bad”的前10名最近邻词嵌入的情况。
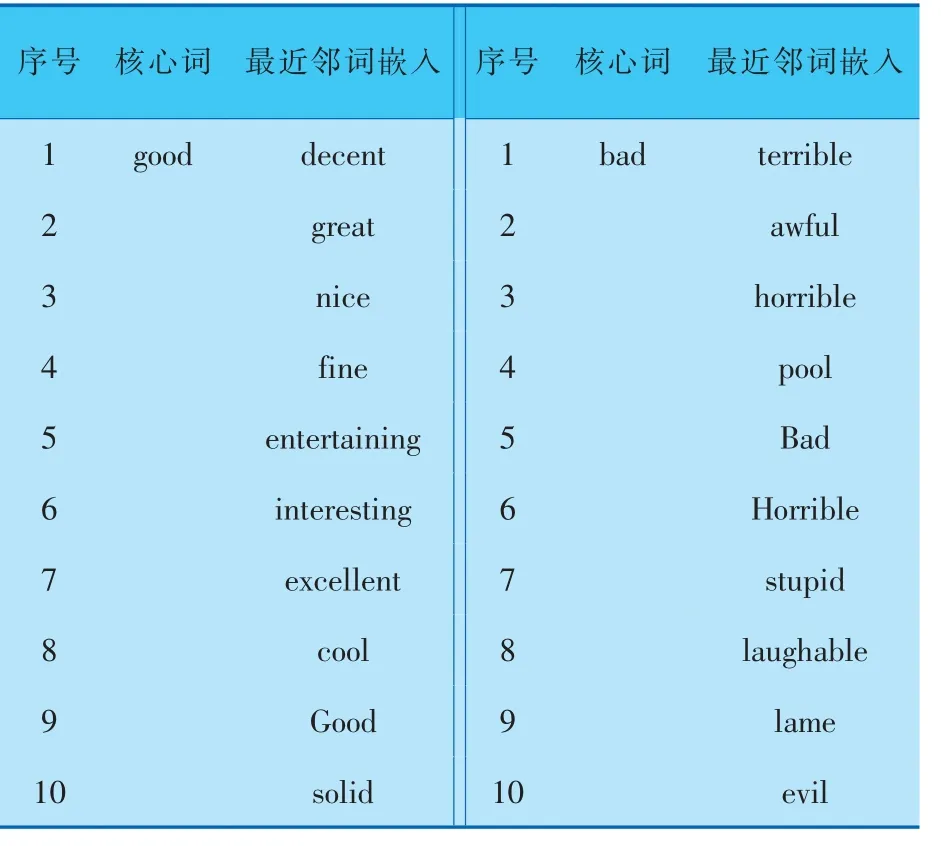
表5 对抗训练后10个与“good”和“bad”最近邻的词嵌入
3 结束语
笔者首先对问句文本进行同义词扩充,并在跨领域问句分类上获得了较为显著的提升。 该方法引入了一定数量的噪声来防止过拟合,并将同义词扩展到源域问句,可以很好地将ALBERT-FiT模型扩展到新领域。 向Embedding层添加扰动,生成对抗样本,并对ALBERT模型进行对抗训练。结果表明,A-ALBERT-FiT相较于ALBERT-FiT有了进一步的提升。 同时,对抗性训练不仅提高了分类性能,而且提高了单词嵌入的质量。
