城镇建设适宜性评价的贝叶斯网络机器学习方法
2022-09-24夏清清胡晓艳
赵 珂,夏清清,胡晓艳
(1.重庆大学建筑城规学院,重庆 400045;2.自然资源部国土空间规划监测评估预警重点实验室,重庆 401147)
1 引言
城镇建设适宜性评价作为《资源环境承载能力和国土空间开发适宜性评价技术指南》(以下简称“双评价指南”)的重要内容,是国土空间规划中城镇开发边界划定、城镇集约节约高效用地的基础。城镇建设适宜性评价的核心工作是建立评价指标体系及确定其权重,当前主流做法是:运用专家经验法、极值法和主成分分析法等方法,确定评价指标体系;运用专家打分法、层次分析法和熵权法等方法,赋值指标权重[1],或采取“木桶原理”,以短板指标“一票否决”。虽然这些方法便于操作和可实现结果量化,但在学理上,由于各单因素的适宜性内在机制不同[2-4],对适宜性的整体贡献并不是叠合加权汇总的线性关系,而是复杂的非线性关系,由此,在实践中必然出现适宜性评价结果最好的区域也是承载力评价结果压力最大区域的矛盾结果[5],城镇建设适宜性用地与农业生产适宜性用地、生态适宜性用地往往重叠。
“客观世界本身就是非线性的,线性只是一种近似”,“非线性认知能看到事物的普遍联系,线性认知易于理解,有助于探究事物的本质”,非线性认知的线性转化,是一种解决复杂非线性关系问题的有效路径[6],由此,具有认知复杂非线性关系能力的人工智能机器学习方法开始应用于城镇建设适宜性评价。机器学习评价方法,不依靠人的先验主观经验,而是秉持“存在就是合理的” “向传统学习”的原则,模仿人类有监督、无监督学习形式,将土地分为城镇建设和非城镇建设两种状态,通过寻找经历一定时间后转化为城镇建设用地的众多非城镇建设用地斑块内含因素之间的聚类关系,模拟城镇增长趋势,判别城镇建设适宜性用地。
但目前运用于城镇建设适宜性评价的机器学习方法主要是元胞自动机[7-10]和人工神经网络[11-13],它属于难以从算法中学习到有关影响要素组成及其权重的“黑箱学习”,局限在非线性认知,不易转化为能被人理解、便于操作的线性规则,不具备探究城镇建设适宜性本质的能力。所幸的是,在机器学习方法中,除大部分的“黑箱学习”方法外,还有小部分“白箱”方法,可将非线性认知转化为由影响因素主次性及其重要度组成的线性规则,其中,典型的是贝叶斯网络(Bayesian Network, BN)[14-16],它借助贝叶斯网络严密的数学逻辑表达能力和概率推理能力,海选尽可能多的数据,通过因果推断与概率推理[17]非线性认知各因子相互之间的依赖或独立关系等知识,应用于透明化影响因素主次关系、指标权重的评价或推理领域,如对生态红线、基本农田划定的支持[18-19],对机械、交通故障诊断的推理[20-21],洪灾、消防灾害预警推演[22-23]等。本文尝试运用BN机器学习方法,从其对城镇建设适宜性的非线性认知中转化出易于理解、便于落地实施的城镇建设适宜性线性评价规则。
2 城镇建设适宜性评价的BN机器学习原理
城镇建设适宜性评价的BN机器学习方法,是通过结构学习和参数学习两大模块,分别揭示城镇建设适宜性指标的影响主次性和重要度,进而转化出“主导因素优先、高重要度优先”的城镇建设适宜性线性评价的因素指标体系及其重要度规则。
2.1 指标影响主次性的BN结构学习
城镇建设适宜性的BN结构学习[24-25],是将存在于各指标之间的复杂非线性网络关系,展现为以有方向的边连接各指标节点形成的有向无圈网络(Directed Acyclic Graph, DAG),通过揭示各指标节点之间的依赖或独立关系,发现影响城镇建设适宜性的主导因素。其中,边代表指标节点间具有关系,边的方向代表指标节点间的依赖关系。
在DAG网络中,W代表影响因素,A代表相应W的表征指标,没有边指向的指标节点或独立或作用于其它指标,影响城镇建设适宜性,这些独立的指标节点所表征的因素,构成了城镇建设适宜性的主导因素。例如,图1中A1、A2、A3、A4是没有边指向的独立指标节点,其中A1是表征W1因素的指标,A2、A3是表征W2因素的指标,A4是表征W3因素的指标,W1、W2、W3共同构成该DAG网络中影响目标节点A8的主导因素。而A5、A6、A7是有边指向的依赖指标节点,其所表征的W4、W5是次要因素。
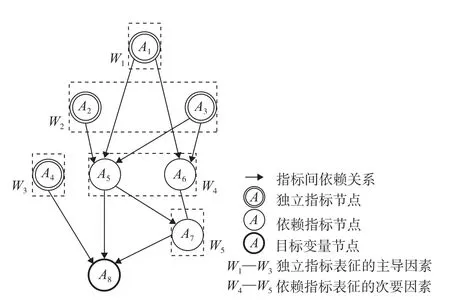
图1 BN结构学习出的依赖或独立关系Fig.1 Dependent or independent relationship in BN structure learning
2.2 指标影响重要度的BN参数学习
BN参数学习[26-28]的核心是计算各指标节点对评价目标的影响程度,即重要度,包括赋值在边上的发生概率重要度和赋值在指标节点上的关键性重要度两个方面。城镇建设适宜性DAG网络中两个指标节点在不同参数状态下相互依赖的条件概率(如果某一指标节点出现,则另一指标节点出现的概率),反映指标节点之间边上的依赖关系强度,是发生概率重要度,为指标节点的关键性重要度提供必要的中间特征向量。城镇建设适宜性指标节点关键性重要度,是指标节点对边发生概率重要度的敏感性,反映指标节点状态发生变化而引发评价结果发生变化的程度,通过对边发生概率重要度的概率变化敏感性度量,方差缩减为百分比的方式表示。在V表示指标节点、L表示边、S表示城镇建设适宜性目标变量的BN模型S=(V,L)中,发生概率重要度和关键性重要度分别按照式(1)和式(2)、式(3)计算确定[29-30]。

关键性重要度将反映在边上的依赖性强度转化为指标节点的重要度,促成城镇建设适宜性评价从关系(边)的非线性认知转化为指标节点重要度的线性叠合。但现实中受数据获取的制约,无法获得能完全反映事物本原的全部数据,即参与BN参数学习的指标节点少于真实本原的存在,通常关键性重要度加和值小于100%,一方面说明BN参数学习意识到现实中还有人类尚无法探明的微影响因素存在,一方面表明可不追求重要度归一化形成权重,而以关键性重要度替代权重的概念。图2描述了有A、B、C三个指标节点的城镇建设适宜性BN参数学习过程。在指标节点的条件概率表中,第一行是该指标的关键性重要度,第二、三行分别是该指标节点的不同参数状态下的条件概率,指标节点条件概率表之间有向连接边上的数值是发生概率重要度。例如,指标节点C依赖于指标节点A和B,发生概率重要度分别是0.24和0.47,对城镇建设适宜性的关键性重要度为42%。

图2 城镇建设适宜性的BN参数学习过程Fig.2 BN parameter learning of urban construction suitability
3 研究区域、学习流程与数据整备
3.1 研究区域
酉阳土家族苗族自治县地处东经108°18′25″~109°19′02″、北纬28°19′28″~29°24′18″,位于重庆市东南边陲,是武陵山区中乌江和沅江的分水岭,呈现“酉中中山、酉西低山、酉东丘陵”的山区立体多维地形特征,并形成“酉东热区、酉西温区、酉中凉区”三大明显的垂直性气候分区、“东优、西良、中薄”的土壤条件分区格局。
酉阳属于“三分丘陵七分山真正平地三厘三”的城市,城镇建设用地长期处于超负荷状态。第七次人口普查结果显示,近10年来城镇人口增长13.56万人,达到27.79万人,城镇化率42.19%。但城镇建设用地规模仅从2015年的15.04 km2增长到2020年的18.13 km2,人均建设用地65.23 m2,特别是老城5.5 km2城镇建设用地就容纳了近15万人,人均城镇建设用地仅36.7 m2,远远小于人均100 m2的标准。随着西部陆海通道的建设,酉阳将迎来城镇化发展的新机遇,亟需通过城镇建设适宜性评价,支持城镇集约节约高效用地满足城镇人口增长的需求。
3.2 学习流程
数据海选整备、模型学习、规则转化和结果验证4个部分构成了本文中城镇建设适宜性评价的贝叶斯网络机器学习流程框架(图3)。
(1)数据海选。秉持“存在就是合理的” “向传统学习”的机器学习原则,对比两个不同年份的用地变化,将在此期间由非城镇建设转化为城镇建设的用地,作为学习对象,并将海选能收集到的、与土地覆盖和土地利用相关的全部数据,涵盖高程、坡度等地形数据,到水系距离、地下水深度等水源数据,平均气温、降水量等微气候数据,成土母质、土壤质地、土壤类型、有效土层厚度、土壤肥力等土壤数据,与国家公益林距离等植被数据,与自然保护地距离等生物多样性数据,土壤侵蚀程度、土壤排水能力等地貌数据,地质灾害等灾害数据,与县级行政中心、乡镇级行政中心距离等城镇聚集条件数据,与主要道路、铁路站场、高速出入口距离等交通数据,集成到这些学习对象用地上。
(2)评价模型学习。通过BN结构学习和参数学习,得到完整的城镇建设适宜性评价指标贝叶斯网络结构及其重要度参数。
(3)评价规则转化。从BN结构学习出的复杂非线性贝叶斯网络结构,解译城镇建设适宜性的主导因素;从BN参数学习出的重要度,提取出高关键性重要指标,与主导因素指标一起,建立便于操作的线性评价规则。
(4)结果验证。针对以酉永高速、渝湘高铁等为代表的西部陆海通道建设对城镇带来的新发展情景,分别运用非线性BN评价、将非线性BN评价转化为由关键指标体系及其重要度组成的“转化线性规则评价”和遵循“双评价指南”集成多专业专家经验先验性选择指标、确定权重的专家经验线性评价三种方法,评价城镇建设适宜性,对评价结果进行对比,验证非线性BN评价的合理性、转化线性规则评价运用的可行性。
3.3 数据海选整备
3.3.1 数据海选
本文海选酉阳县与土地覆盖和土地利用相关的全部普查和勘测数据,包括:2015年全国土地利用变更调查数、第三次全国国土调查2021年年度变更调查,1∶10 000数字高程模型(DEM),水系分布,土壤检测数据、多年平均气温空间插值栅格、行政中心分布、交通GPS数据等(表1)。
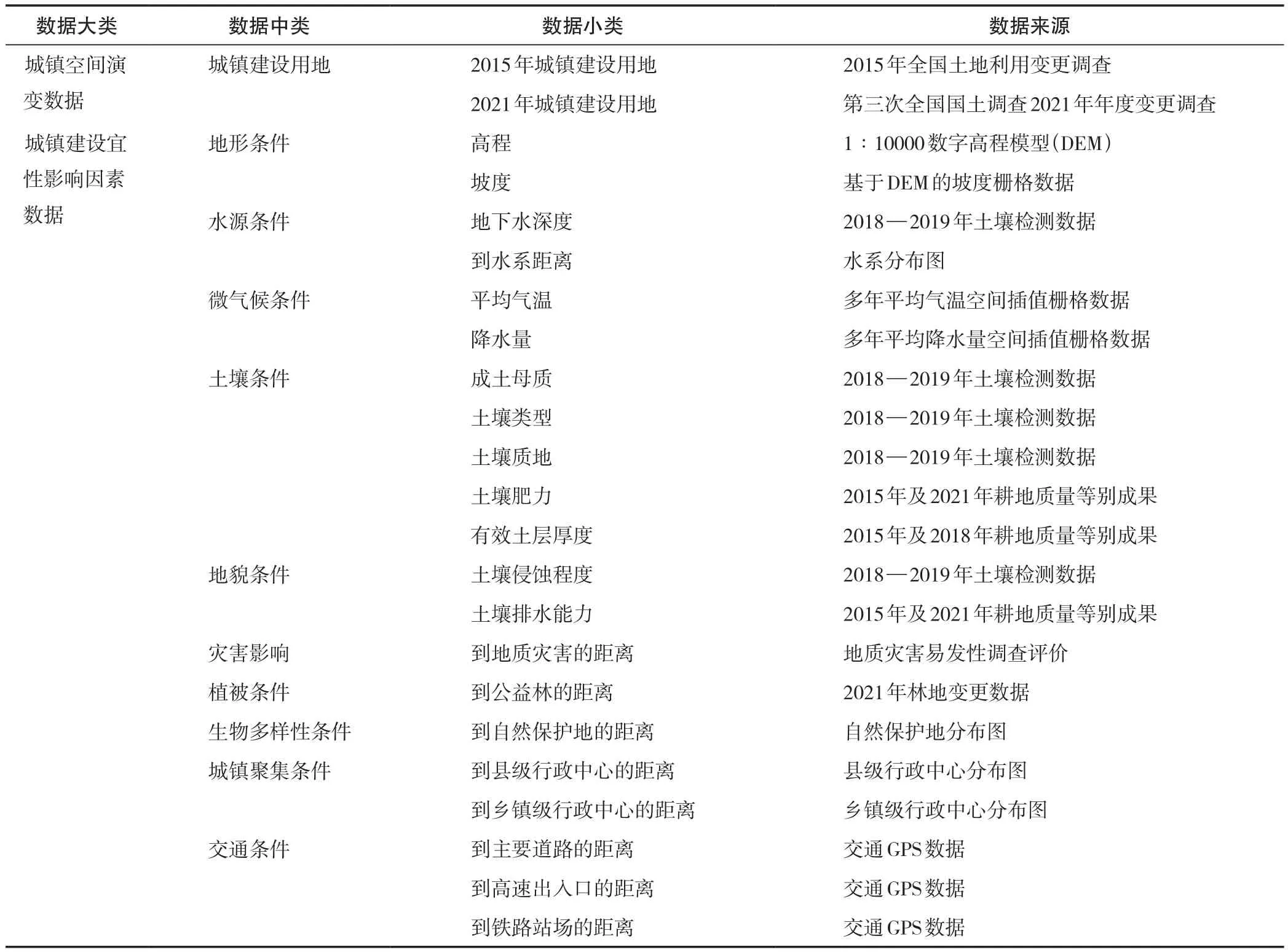
表1 研究数据组成及来源Tab.1 Data composition and sources
3.3.2 数据整备
研究数据整备包括城镇建设适宜性的数据标签赋值、数据离散分级和数据样本分类三个方面。
(1)数据标签赋值。旨在给出贝叶斯网络模型学习的榜样。基于“存在即合理”的机器学习理念,叠加对比分析2015年、2021年用地变化,将在此期间由非建设用地新转化为城镇建设用地的空间,标记为适宜城镇建设,打上“GOOD”标签。
(2)数据的离散分级。旨在提高贝叶斯网络模型的预测精度。基于上述被赋予“GOOD”标签的空间样本,观察其各项因子属性的数据分布状态,借助数据分布拐点及关键点合理划分因子分级区间,尽可能降低城镇建设适宜、不适宜两种空间样本落入同一数据区间的可能性。按1,2,3,…,n的次序对分级数据进行离散化赋值(表2)。

表2 连续数据的离散化分级标准Tab.2 Discretization classi fi cation criteria of continuous data
(3)数据样本分类。旨在提高贝叶斯网络模型模拟准确度。基于“向历史学习”的机器学习思路,本文将2015年城镇状态作为学习数据、2021年城镇状态作为预测数据,并进一步按照7∶3的比例将学习数据划分为用于模型构建的训练样本和用于模型准确度检验的测试样本。
4 学习结果
4.1 城镇建设适宜性指标影响的主次性
BN结构学习出的酉阳贝叶斯DAG中,有高程、坡度、主要道路、高速出入口、铁路站场、县级行政中心、乡镇级行政中心7个独立指标节点。
其中,表征交通条件因素的主要道路、高速出入口、铁路站场三个独立指标节点和表征城镇聚集条件因素的县级行政中心、乡镇级行政中心两个指标节点分别单独影响城镇建设适宜性。但表征地形条件因素的高程、坡度两个指标节点,一方面作用于植被条件因素进而影响生物多样性条件;一方面通过影响表征微气候条件因素的平均气温和降水量指标节点,作用于表征水源条件因素的水系和地下水深度指标节点以及表征土壤条件因素的成土母质、土壤质地、土壤类型、有效土层厚度、土壤肥力等指标节点,再作用于表征地貌条件因素的土壤排水能力、土壤侵蚀程度指标节点所影响的表征地质灾害条件因素的地质灾害指标节点,最终影响城镇建设适宜性(图4)。
7个独立指标节点所表征的地形条件、交通条件和城镇聚集条件三大因素共同构成了影响城镇建设适宜性的主导因素。
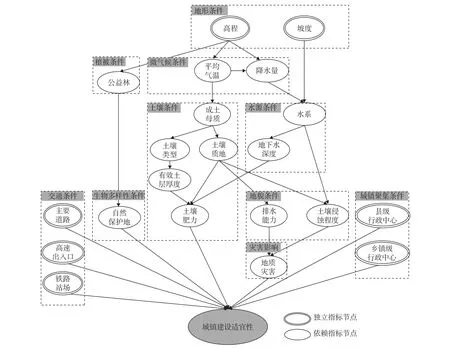
图4 BN结构学习出的城镇建设适宜性指标节点关系及影响因素主次性Fig.4 BN structure learning result: the relationship among the indicators and the primarysecondary of the factors about urban construction suitability
4.2 城镇建设适宜性指标影响的重要度
酉阳城镇建设适宜性BN参数学习结果显示:关键性重要度最高的指标节点,是城镇聚集条件因素中的乡镇级行政中心、县级行政中心两个指标,重要度分别为11.17%和7.46%,总和达到18.62%,排序分别位于第一和第八;交通条件因素中的主要道路、高速出入口两个指标,重要度分别为9.89%和7.83%,总和达到17.72%,排序分别居第三和第六;地形条件因素中高程、坡度两个指标,重要度分别为8.95%和8.04%,总和达到16.99%,排序中分别位于第四和第五。
关键性重要度显著的指标节点,是水源条件因素中的水系指标,微气候条件因素中的平均气温、降水量指标和生物多样性条件因素中的自然保护地指标,重要度分别为10.95%、7.73%、6.34%和6.15%,总和达到31.17%,排序依次为第二、第七、第九、第十位。
关键性重要度不明显的指标节点,包括土壤条件因素中的成土母质、土壤质地、土壤类型、有效土层厚度、土壤肥力5个指标,地貌条件因素中的土壤侵蚀程度、土壤排水能力两个指标,交通条件因素中的铁路站场指标,水源条件因素中的地下水深度指标,灾害条件因素中的地质灾害、洪涝灾害两个指标,植被条件因素中的公益林指标,其重要度均不足2%(图5)。
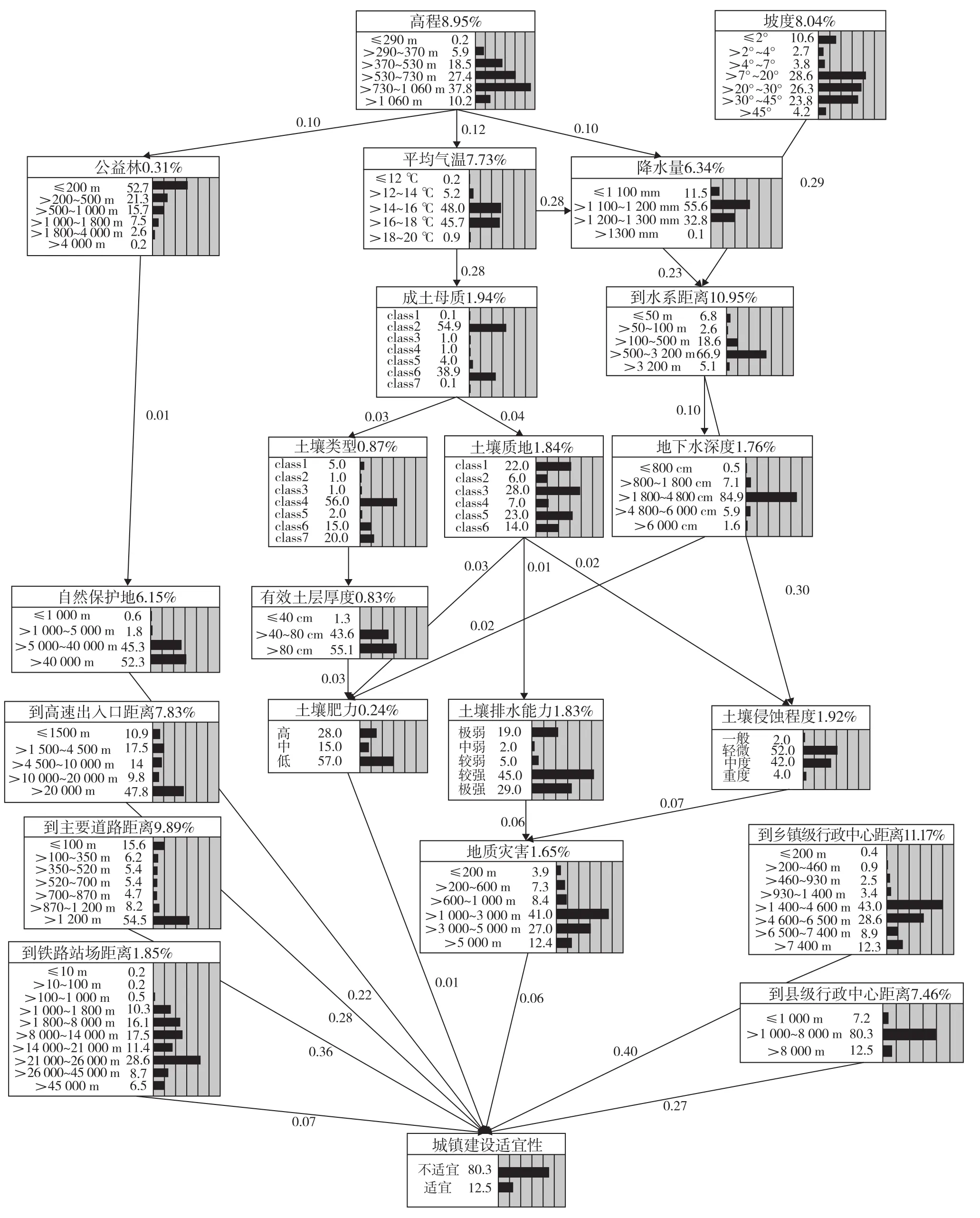
图5 BN参数学习出的城镇建设适宜性指标节点的重要度Fig.5 BN parameter learning result: the importance of indicators about urban construction suitability
4.3 线性评价规则转化
BN机器学习转化为线性规则的关键是将指标节点之间的依赖或独立关系强度转化为指标节点对事物形成或事件发生的整体贡献度,即以表征整体贡献度的关键性重要度选取指标,建立由指标体系及其关键性重要度所构成的线性规则。在实操层面,首先通过BN结构学习出的指标影响主次性提取具有主导性且关键性重要度高的指标,便于判断遴选BN参数学习出的关键性重要度高但非主导性的指标,从而构建关键性重要度高且影响主次性清晰的线性评价规则指标体系。
三大主导因素中的7个独立指标节点,除关键性重要度较低的铁路站场指标节点外,其余高程、坡度、主要道路、高速出入口、县级行政中心、乡镇级行政中心6个指标影响重要度较高,纳入评价指标体系。三大主导因素外,关键性重要度显著的水系、平均气温、降水量、自然保护地4个指标,纳入评价指标体系。形成由10个指标及其关键性重要度所构成的城镇建设适宜性线性评价规则(表3)。
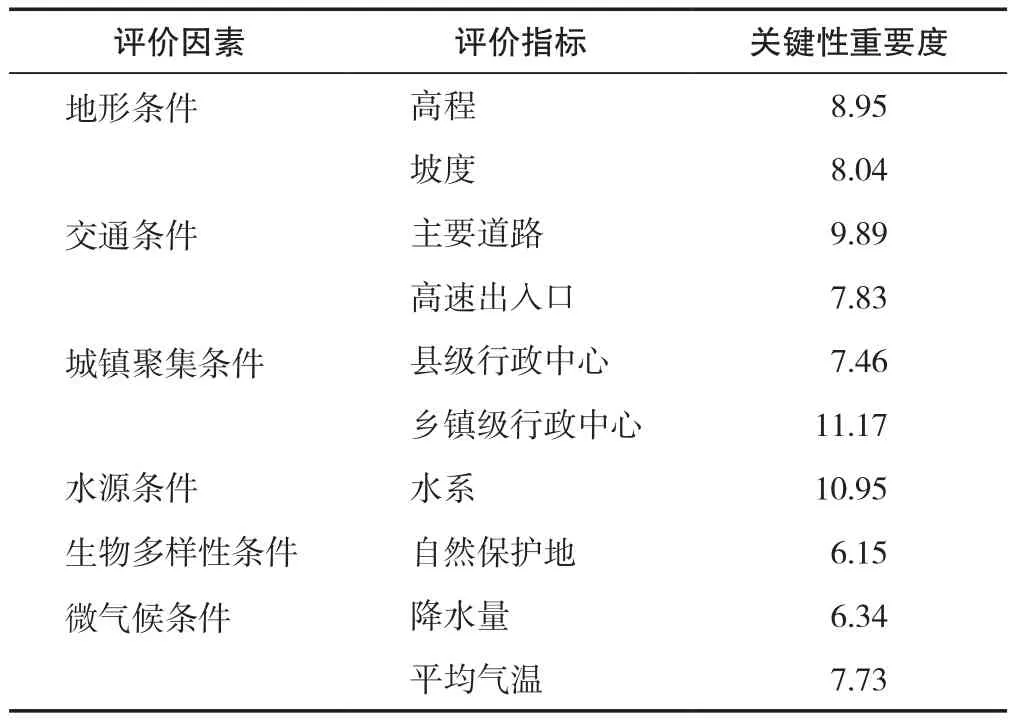
表3 城镇建设适宜性线性评价规则指标体系及其重要度Tab.3 Indicators of the linear evaluation and their importance about urban construction suitability (%)
5 评价结果对比验证
针对以酉永高速、渝湘高铁为代表的西部陆海通道建设带来的酉阳城镇新发展情景,分别运用“非线性BN评价”、“专家经验线性评价”、“转化线性规则评价”三种方法,评价城镇建设适宜性。然后,对比非线性BN评价与专家经验线性评价结果,验证非线性BN评价的准确性;对比转化线性规则评价与非线性BN评价结果,验证转化线性规则评价的可行性。
5.1 遵循 “双评价指南”的专家经验线性评价
重庆市下发酉阳县的城镇建设适宜性评价,是依据“双评价指南”,选取土地资源、水资源、气候、环境、灾害、区位6大因素12项指标,根据专家经验制定各项指标评价标准(表4),先进行单项评价,再按照专家经验的逻辑判断,进行集成评价:首先,以土地资源和水资源两类单项评价结果为基础,建立判别矩阵,确定城镇建设适宜性等级的初步结果。然后,以灾害、环境、气候和区位4类单项评价对初步结果依次进行修正,其中,地质灾害危险性评价结果为极高等级的,初步结果调整为低等级;为高等级的,初步结果下降两个级别;为较高等级的,初步结果下降一个级别。水环境容量为最低值的、气候舒适度等级为很不舒适的,均将初步结果下降一个级别。区位优势度为最低值的,将初步结果下降两个级别;为较差的,将初步结果下降一个级别;为好的,将初步结果为较低、一般和较高的分布上调一个级别。最后,以地块集中连片度进行修正集成为城镇建设适宜性评价结果。
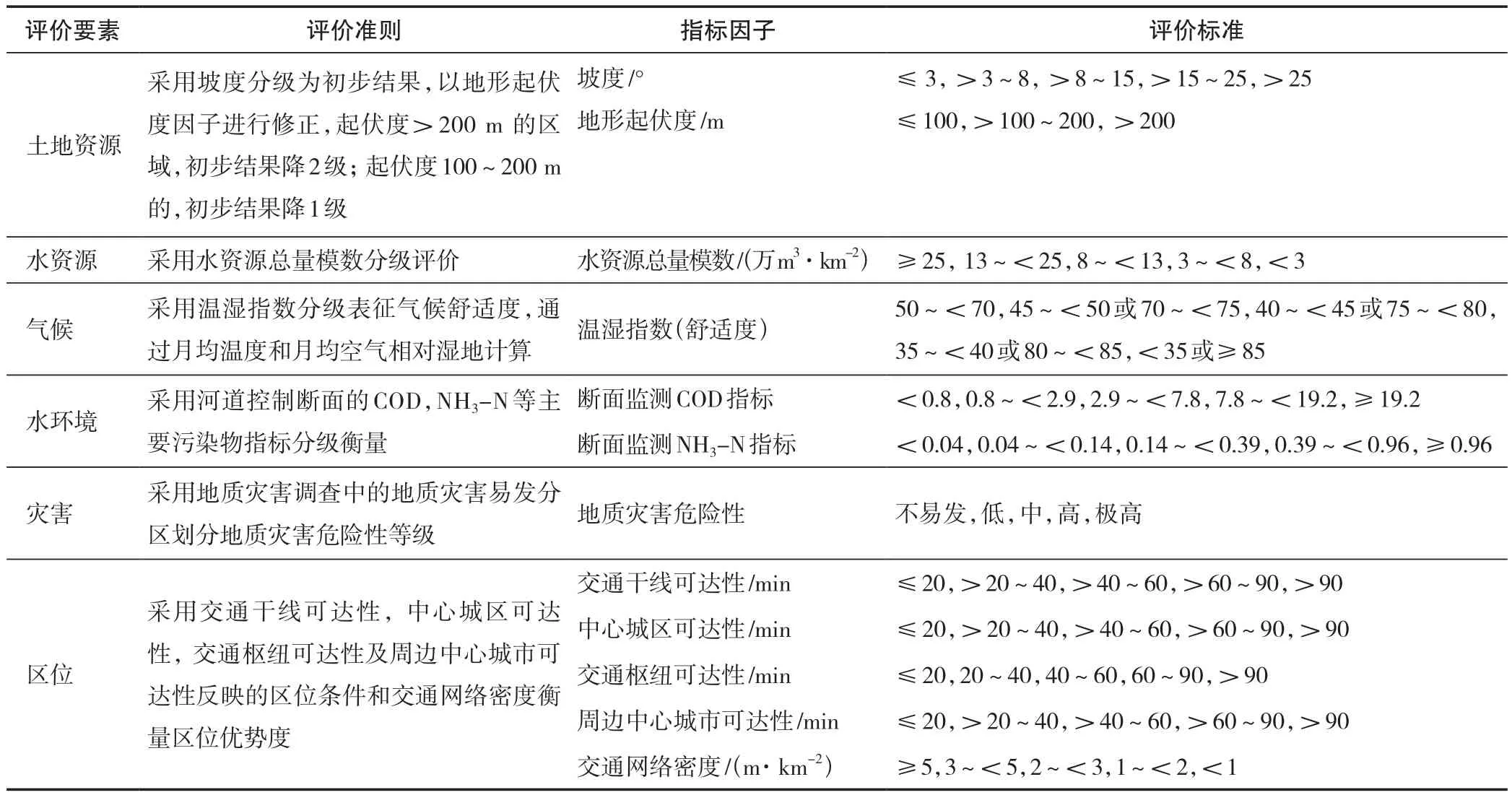
表4 遵循“双评价指南”的专家经验线性评价中的指标体系及单项评价标准Tab.4 Indicators of expert experience linear evaluation and their individual evaluation criteria complying with double evaluation guide
5.2 非线性BN评价合理性验证
判别城镇建设适宜性评价结果合理性最重要的标准是其与农业生产适宜性、生态保护重要性用地的重叠度。本文选取农业生产适宜性用地中最重要的高标准优质农田、生态保护性用地中最重要的公益林地与非线性BN评价和专家经验线性评价出的城镇建设适宜性用地之间的重叠度比较,验证非线性BN评价的合理性。
非线性BN评价与专家经验线性评价出的城镇建设适宜性用地分别为14 008.99 hm2和14029.43 hm2,比较结果发现:(1)在与高标准农田重叠方面,非线性BN评价结果没有出现集中占据高标准优质农田的区域,仅有少量零散用地占据高标准优质农田,面积129.79 hm2,占其评价结果总面积的0.93%,但专家经验线性评价结果有18处集中区域和大量零散用地占据高标准优质农田,面积达到2 680.05 hm2,占其评价结果总面积的比重达到了19.10%;(2)在与公益林地重叠方面,非线性BN评价结果没有占据公益林地,但专家经验线性评价结果中有12处集中区域占据公益林地,面积达到1 032.17 hm2,占其评价结果总面积的7.37%(图6)。由此可见,非线性BN评价结果的合理性大大高于专家经验线性评价结果。
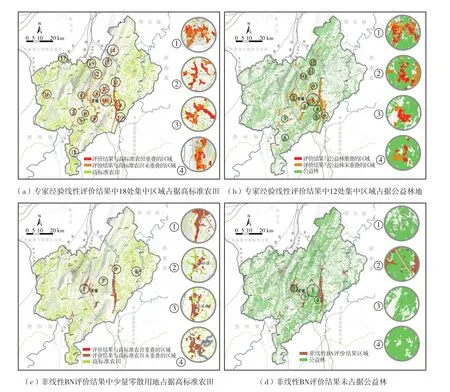
图6 非线性BN评价与专家经验线性评价结果对比Fig.6 Comparison between nonlinear Bayesian network evaluation and expert experience linear evaluation
5.3 转化线性规则评价可行性验证
从空间范围、与高标准优质农田和公益林地的重叠关系三个方面,对比转化线性规则评价结果与非线性BN评价结果,发现:(1)转化线性规则评价出的城镇建设适宜用地面积14 002.20 hm2,仅比非线性BN评价结果少6.79 hm2,且减少的主要是非线性BN评价中分散难以集中连片的用地;(2)转化线性规则评价出的城镇建设适宜用地占据315.97 hm2的高标准优质农田,比非线性BN评价结果多占据186.17 hm2,但占其评价结果总面积的比重也仅2.26%;(3)转化线性规则评价出的城镇建设适宜用地没有占据公益林地(图7)。对比结果显示,虽然转化线性规则评价合理性不如非线性BN评价,但误差在可接受范围内,评价出的城镇建设适宜用地更加集中连片,加之更好打开了非线性BN评价的“黑箱”,评价结果易于感知、理解,可行性更强。

图7 转化线性规则评价与非线性BN评价结果对比Fig.7 Comparison between transformed linear rule evaluation and nonlinear Bayesian network evaluation
6 结论与讨论
秉持“存在就是合理的” “向传统学习”的机器学习原则,引入具有将复杂非线性关系认知转化为各因子重要度线性知识的BN学习方法,通过“数据海选—非线性认知—线性规则转化”的方式,评价城镇建设用地适宜性,在数据选择、评价效果、评价过程可感知等方面的具有一定优势:(1)突破了数据选择的先验主观性。以数据为驱动,海选能收集到的、相关土地覆盖和土地利用的所有数据参与学习,而不是依靠先验知识选取数据,是BN机器学习不同于传统线性评价方法的一大区别,避免了因先验知识不足而导致的评价因子缺失。(2)非线性认知评价更逼近真实。“非线性是世界的真实存在”,在数据完备的前提下,具有非线性认知能力的BN学习,以山地、平原不同城镇形态或大城市、小城镇不同城镇规模的现实存在为学习榜样,会学习不同的延续城镇现实存在机制的评价结果。(3)具有易理解的线性剖析能力。“线性是非线性的抽象,更容易被人理解”,贝叶斯网络通过结构学习、参数学习,将指标节点之间的非线性关系转化为线性的指标节点关键性重要度,促成城镇建设适宜性评价机制透明、评价过程可感知。
当然本文的研究方法在数据制约、学习榜样等方面也存在一定的局限性。(1)以数据为驱动的BN学习评价方法,受制于数据的完备性,可能会因为数据的缺失,漏掉关键性因素或指标,导致评价结果的偏差。(2)以“存在就是合理”为参照的BN学习,容易陷入“坏榜样的陷阱”,如果现实存在是城镇建设较少侵占高标准优质农田和不占公益林的“好榜样”,城镇建设用地适宜性的BN学习评价结果就较少与高标准优质农田和不与公益林重叠;反之,现实存在是城镇建设大量肆意侵占高标准优质农田的“坏榜样”,BN学习出的城镇建设适宜性就会认为高标准优质农田可以大量侵占。(3)以现实存在为参照的BN学习分别运用于城镇建设适宜性评价和农业生产适宜性评价,难免会形成两类评价结果部分重叠的问题,需要进一步探索关于如何权衡取舍的方法。
虽然BN学习对城镇建设适宜性的评价还存在上述局限性,但逼近世界本原且容易被人理解的非线性认知和线性抽象相结合的方法,是人类探究世界本真的必然趋势,只有在不断尝试中了解其优缺点,才能不断修正完善。
