数字人文视域下典籍动物命名实体识别研究
——以SikuBERT预训练模型为例*
2022-09-23林立涛王东波刘江峰冯敏萱
林立涛,王东波,刘江峰,李 斌,冯敏萱
0 引言
动物是地球生命共同体不可或缺的组成成员,与人类文明发展紧密相连[1]。我国海量古籍文献有大量动物记载,蕴含丰富的动物知识有待挖掘。长期以来,对古籍中动物的探究主要采用文献引证等定性研究方法,探究内容包括动物形象[2]、动物寓言或寓意等[3-7]。古籍数字化文本的积累和自然语言处理技术的发展,特别是命名实体识别技术的进步,为深入推进古籍特定领域数字人文研究提供了有力的技术支撑。
命名实体识别是实现知识结构化组织的前提,也是数字人文研究的基础工作之一,典籍数字人文研究不断深入,已经使得人名、地名、机构名、时间词等通用命名实体的识别难以满足需要。开展典籍领域化命名实体识别研究,对于深化典籍数字人文研究,挖掘古籍时代价值,深入推进中华优秀传统文化创造性转化、创新性发展,促进新时代中国特色社会主义文化建设具有重要意义。
本研究立足典籍动物这一领域,利用SikuBERT等多种模型构建动物命名实体自动识别模型,并进行性能测试对比,使用最优模型对《史记》动物命名实体进行识别。本研究不仅为深度挖掘和组织典籍中动物知识提供有效方法,同时对构建面向其他领域命名实体识别模型具有借鉴意义。
1 相关研究
数字人文是信息技术与人文科学交叉、融合的研究领域[8],主要采用文本挖掘、社会网络分析、统计计量、数据可视化等方法解决人文科学问题。公认的数字人文实践肇始于1949年罗伯托·布萨用计算机辅助编制《托马斯著作索引》。国内公认最早数字人文实践属陈炳藻使用词频统计方法解决《红楼梦》前80回与后40回作者之谜。数字人文正成为人文社会科学创新的重要方向。
命名实体识别是数字人文研究的技术支撑[9],目的是从文本中识别出有特定含义的词语及类型。识别方法可以分为三大类,分别是基于规则的方法、基于统计机器学习的方法和基于深度学习的方法。基于规则的方法是指由人工构建有限的规则,辅以计算机对规则进行完善,再从文本中匹配符合规则的字符串,达到识别的目的。该类方法对构建的规则有严格要求,且具有较强的语料导向性,导致规则迁移性较差,逐渐被其他两类方法取代。基于统计机器学习的方法是选择合适的机器学习模型,同时对已标注语料开展相应的特征工程[10],然后使用一部分语料对模型进行训练,再使用训练得到的模型对目标语料进行命名实体识别。常用的机器学习模型有隐马尔可夫模型(HMM)[11-12]、最大熵模型(ME)[13]、支持向量机模型(SVM)[14]和条件随机场模型(CRF)[15]。基于深度学习的方法是指使用以神经网络为架构的深度学习模型,利用已标注语料对模型进行训练并更新神经网络的参数,然后应用于目标语料命名实体识别。循环神经网络模型(RNN)、门控循环单元(GRU)、长短时神经记忆网络模型(LSTM)和预训练语言模型BERT是当前较为主流的深度学习模型。此外,还有由不同类型模型结合形成的联合模型,如Bi-GRU、Bi-LSTM、Bi-LSTM-CRF,其相较于单一模型,识别性能又有提升。
近年来,预训练语言模型BERT(Bidirectional Encoder Representation from Transformers)[16]成为自然语言处理的主流模型,还出现了多种基于BERT 发展而来的预训练语言模型,面向汉语的主要有BERT-base-Chinese[16]、Chinese-RoBERTa-wwm-ext[17]、 Guwen-BERT-base①、SikuBERT和SikuRoBERTa[18]等5种。BERT-base-Chinese是谷歌利用中文维基百科数据训练而成,面对中文自然语言处理任务具有较好的通用性。guwenBERT-base、SikuBERT和SikuRoBERTa等3种预训练模型专门针对古代汉语自然语言处理任务。Guwen-BERT-base是北京理工大学基于Chinese-Ro-BERTa-wwm-ext用简体汉字版《殆知阁》语料继续训练得到。SikuBERT和SikuRoBERTa是南京农业大学分别基于BERT-base-Chinese和Chinese-RoBERTa-wwm-ext 利用文渊阁繁体字版《四库全书》语料继续训练而成。已有研究表明,SikuBERT、SikuRoBERTa相较于另外3种模型在古文自动分词、断句标点、词性标注和命名实体识别上具有更好性能[18]。
古籍命名实体识别模型研究不断深入,在通用命名实体识别方面,黄水清等[19]利用先秦古汉语语料,对比分析了条件随机场模型和最大熵模型在地名识别任务上的效果,发现条件随机场模型优于最大熵模型,并构建了调和平均值为90.94%的条件随机场模型,将其应用于《国语》中地名的识别。杜悦等[20]基于7种深度学习模型,使用先秦典籍中的人名、地名以及时间词进行识别模型构建研究,结果表明基于Bi-LSTMCRF模型经训练得到的识别模型效能最优,调和平均值达到86.59%。在动植物命名实体识别方面,崔竞烽等[21]基于Bi-LSTM、Bi-LSTM-CRF等深度学习模型和BERT模型分别对中国古典诗词中的菊花命名实体进行了识别模型构建研究,发现基于BERT模型的命名实体识别最优,调和平均值达到91.60%,高于其他模型。李娜[22]基于CRF 模型构建多元特征模板,对《方志物产》中的多种类型命名实体进了识别研究,对别名、地名、引用书的识别取得了较好的效果,但是对人名和用途名的识别表现不佳。徐晨飞等[23]基于Bi-RNN、Bi-LSTM、Bi-LSTM-CRF、BERT模型对《方志物产》中的产物别名、人物、产地、引书四种命名实体进行了识别研究,发现Bi-LSTM-CRF对引书命名实体的识别效果最优,而BERT对人物命名实体的识别效果最优。
2 模型选择和研究框架
CRF 模型、Bi-LSTM-CRF 模型、基于BERT发展而来的预训练模型在命名实体识别上具有优势,而SikuBERT、SikuRoBERTa相较于BERT-base-Chinese、 GuwenBERT-base、Chinese-RoBERTa-wwm-ext等3种预训练语言模型更适用于古文领域的命名实体识别任务。本研究基于5 种BERT 发展而来预训练模型及CRF、Bi-LSTM-CRF 模型,利用 25 部经动物命名实体人工标注的先秦典籍语料进行训练,构建古籍动物命名实体识别模型,并对识别性能进行测试对比,选用最优模型对《史记》动物命名实体进行识别,研究框架见图1。
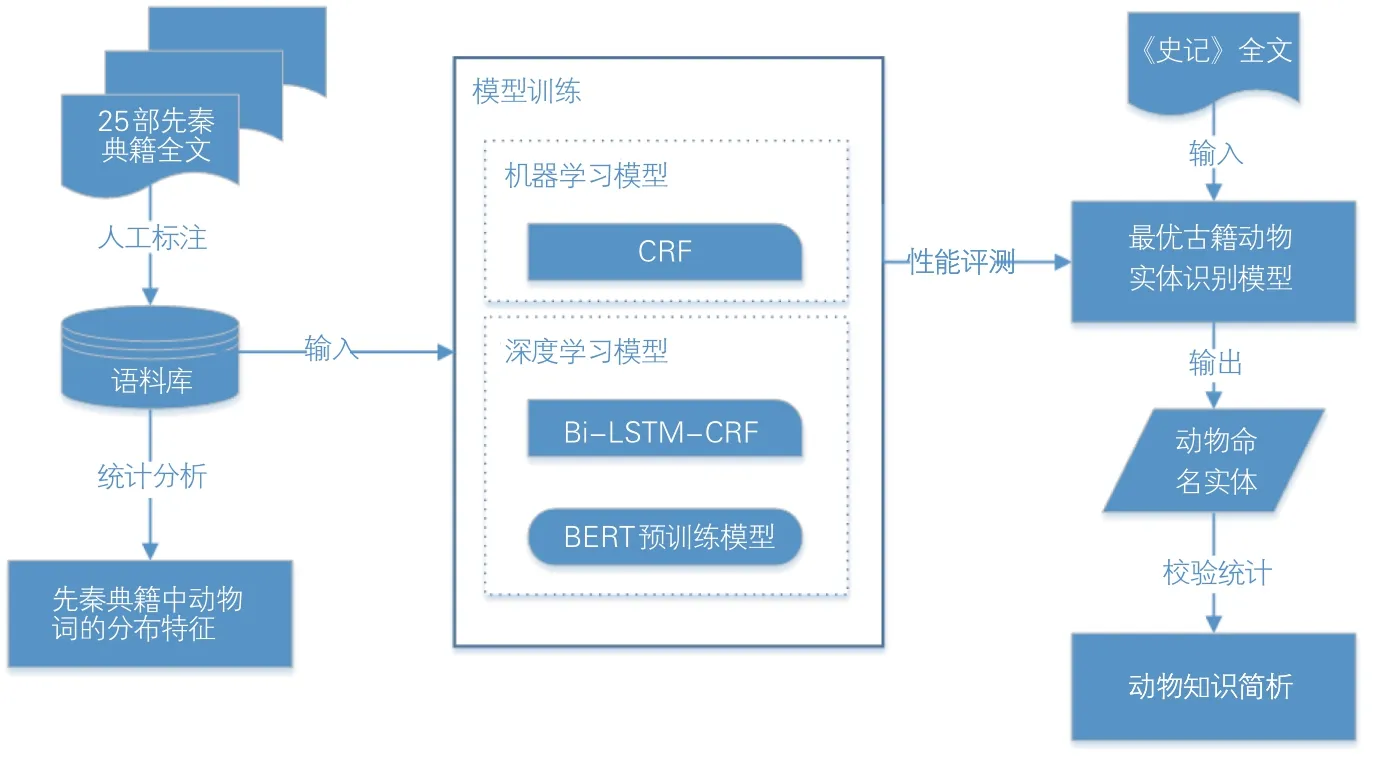
图1 研究框架
3 语料库数据标注与统计
3.1 语料库命名实体的标注
本研究使用的语料是由南京师范大学语言科技研究所经人工标注和机器辅助校对构建的先秦典籍语料库,包含《仪礼》《公羊传》《吕氏春秋》《吴子》《周易》《周礼》《商君书》《国语》《墨子》《孙子兵法》《孝经》《孟子》《尚书》《左传》《庄子》《晏子春秋》《楚辞》《礼记》《管子》《老子》《荀子》《论语》《诗经》《谷梁传》《韩非子》等25部繁体中文古籍,所有句子已完成了分词和词性标注,去除标点符号后,总词数为1,551,944个,共含116,348个句子,平均每个句子含13.34个词。基于上述语料数据,组织5名信息管理与信息系统专业具有标注经验的本科生,对其中的动物命名实体进行标注,标注工作采用二人二组校对、一人终审讨论的模式。采用“【】”为标注符号,标注后语料句子样式如:“之/r子/n于归/v,/w言/i秣/v其/r【驹】/n。/w”。
3.2 语料库动物命名实体计量分析
(1)动物命名实体分布。25部先秦典籍中动物命名实体(以下简称“动物词”)总计7,912个,占全部语料总词数的0.51%,平均每部古籍含动物词316.48个。全部语料中不重复动物词535个,平均每个动物词出现14.79次。表1为各部古籍中动物词的数量情况。
(2)各频次段不重复动物词数量。25部先秦典籍中出现次数10及以下的不重复动物词达446个(占比83.36%),其中出现次数为1-2次的不重复动物词达295种(占比55.14%)。出现次数超过100的不重复动物词17个(占比3.18%)。总体来看,动物词分布整体呈现少量不重复动物词高频出现,大量不重复动物词低频出现的特征(见表2)。
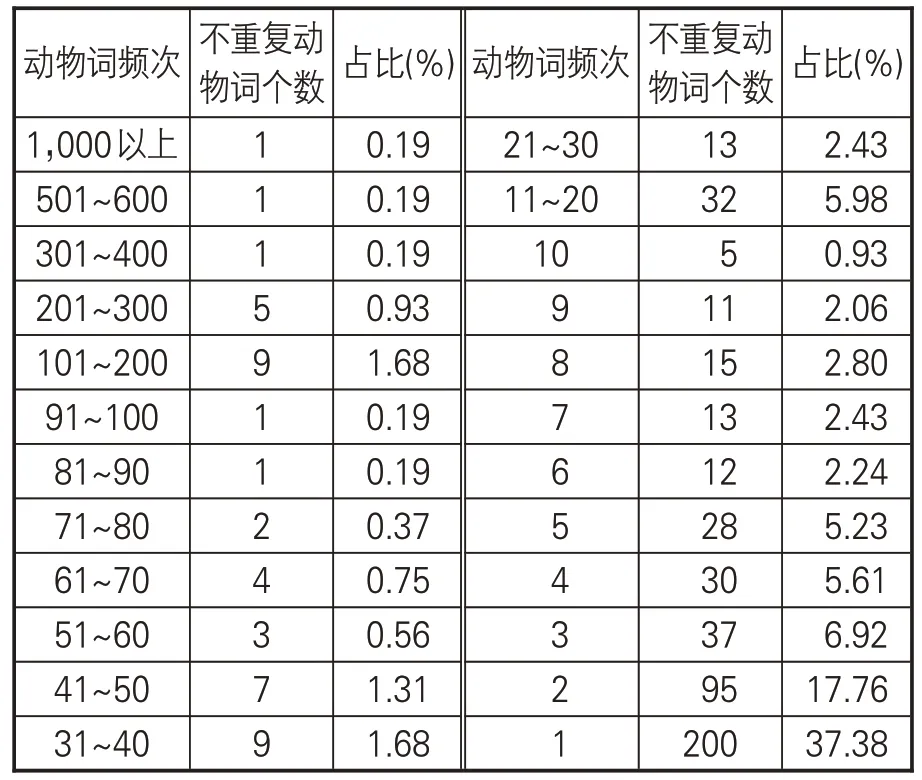
表2 按出现频次段统计的不重复动物词个数及占比
(3)不同字数的动物词频次。将某个动物词所包含的字数定义为动物词的长度,动物词长度均为1 或2。长度为1 的称单字动物词,共257 种,总词频为7,165,频次在100 次及以上的17个不重复动物词均为单字动物词。长度为2 的称双字动物词,共计278 种,最高频次为37,总词频为747。单字动物词频次明显高于双字动物词,这与先秦典籍文言文用词习惯有关。频次排名前10的单字动物词和双字动物词详见表3。

表3 频次前10的单字动物词和双字动物词
4 模型训练与测试
本研究依据动物词标注符“【】”,采用4词位标记集对语料进行机器标记。标记集可表示为R={B-A,E-A,S-A,O},其中“B-A”表示动物词的开始字符,“E-A”表示动物词的结尾字符,“S-A”表示单字动物词,“O”表示所有非构成动物词的字符。完成标记后,删除所有分词符、词性标记和动物词标注符“【】”。最终输入模型训练用的语料格式如:“蛰B-A虫E-A咸O动O苏O,O开O户O始O出O。O”。
训练与测试使用的环境为操作系统:CentOS 3.10;CPU:4颗Intel(R)Xeon(R)CPU E5-2650 v4@2.20GHz;内存:256G;GPU:6块Tesla P40;显存:24G。训练和测试CRF模型采用的软件为CRF++0.58。深度学习模型Bi-LSTM-CRF 和 5 种 BERT 模型均基于 Pytoch 框架搭建。
上文分析表明,动物词的长度均为1 或2,因而本研究构建的CRF模型的特征模板窗口大小为3,即对每个字的考察范围固定为当前字的前后各一个字。由于BERT-base-Chinese、Chinese-RoBERTa-wwm-ext、 SikuBERT、SikuRoBERTa 和 GuwenBERT-base 的代码均采用相同架构,因此使用相同的超参数,最终模型的主要超参数设置见表4。

表4 深度学习模型的主要超参数设置
本研究采用准确率(Precision,P)、召回率(Recall,R)以及调和平均值(F1)来衡量各个模型的命名实体识别效果。计算公式如下:

训练测试采用十折交叉策略,即将语料随机分成大致相当的10份,依次取其中的1份留作测试语料,合并其余9份作为训练语料。为便于对各模型测试性能的比较评析,所有不同模型进行训练测试用的10份语料相同。每种模型将进行10次训练和10次测试,得到10组测试结果。表1数据表明,25部古籍中动物词分布并不均衡,为保证每一份语料中动物词大致均衡,本研究对4词位标记后的所有语料以句子为单位进行随机重组。经对各模型的10 组测试结果计算均值,结果见表5。

表5 十折交叉训练测试结果
测试结果表明,基于SikuBERT、SikuRo-BERTa、BERT-base-Chinese 预训练模型和CRF构建的识别模型,识别效果相对较好,调和平均值(F1)均达到80%以上。其中又以Siku-BERT为最优,其10次测试调和平均值(F1)的平均值为85.46%,其中最高一次为86.29%,具体数据见表6。

表6 SikuBERT模型的动物词识别测试结果
将识别结果与人工标注结果进行对比,各模型表现出不同的识别性能。总体而言,模型识别性能受到语料特征、各模型算法原理和预训练语言模型的领域特征强度影响。在语料特征方面,两个原因可能影响所有模型的测试识别效果。一是动物词人工标注质量。标注人员的文言文阅读理解能力水平参差,可能导致动物词漏标或误标。二是古汉语文法的特殊性。语料中存在较多通假字和同义字(词),还存在一词多义现象,都会增加深度学习模型正确理解文本内容的难度。例如,“驺虞”一词具有3种含义,表示义兽、古代管理鸟兽的官或古乐曲名;“凤凰”有时又写作“凤皇”;“燕”古又同“饮宴”的“宴”。在模型的算法原理方面,并非结构复杂、算力资源消耗更大的模型势必具有更好的效果。面向特定语料时,结构简单、算力资源消耗小的模型同样具有良好的表现,命名实体识别模型应针对具体领域任务做相应选择。在预训练语言模型的领域特征强度方面,具有较强古文领域特色且面向繁体汉语的SikuBERT模型具有明显优势。
(1)CRF模型。条件随机场(CRF)模型[24]是一种无向图模型,其结合最大熵模型和隐马尔可夫模型的特点,具有表达长距离依赖性和交叠性特征的能力,能较好地解决标注(分类)偏置等问题的优点,对特征进行全局归一化能求得最优解。在应用于分词、词性标注和命名实体识别等序列标注任务时具有很好的效果。在测试实验中,CRF模型呈现出相对较高的准确率,但召回率较低,综合表现尚可。从具体的识别结果来看,CRF将非动物词字符、双字动物词的起始字符,错误识别为单字动物词的频率是7种模型中最低的。但也过多的将双字动物词错误识别为单字动物词,导致召回率偏低。例如输出测试识别结果“征O鸟S-A厉O疾O。O”,把“征鸟”这个双字动物词识别成了单字动物词。分析原因主要是在训练语料中既有“鸟”这样的单字动物词也有“征鸟”“海鸟”“鸷鸟”这样的双字动物词,而“鸟”这样的单字动物词频率远高于“海鸟”“黄鸟”“鸷鸟”这些双字动物词。可见,CRF模型对这些差别进行准确区分的能力还有些欠缺。
(2)Bi-LSTM-CRF模型。双向长短时记忆条件随机场(Bi-LSTM-CRF)模型是由长短时记忆网络模型(LSTM,Long Short-Term Memory)[25]和条件随机场模型(CRF)结合发展而来。单向LSTM利用上文的信息对当前位置的输出随机变量进行预测,双向LSTM(Bi-LSTM)[26]在LSTM的基础上增加了从右向左进行预测的并行层,使得模型在进行预测时可以同时考虑当前位置上文和下文的信息,有效提高模型的效果。Bi-LSTM-CRF 在Bi-LSTM 的基础上将输出层的softmax函数替换为CRF,利用CRF对全局范围统计归一化的条件态转移概率的计算,提取出实体标签之间的依赖关系[27],使得最终预测出的标签序列满足一定的约束规则。
在测试实验中,Bi-LSTM-CRF模型综合表现不如CRF,导致这一现象的可能原因是所使用的先秦典籍语料的每个句子平均词数较少,因而Bi-LSTM-CRF模型无法发挥其捕获较长文本的长距离依赖优势。同时,古文行文精炼,骈偶句多,存在许多具有固定结构的短语和词组,这使得基于概率统计的CRF 模型反而比结合了Bi-LSTM的模型更加适用。Bi-LISTM-CRF常见错误类似CRF模型,即将双字动物词的后一个字识别为单字动物词,例如输出测试识别结果“天O龟E-A曰O灵O属O,O地O龟E-A曰O绎O属O,O”,把“天龟”和“地龟”这两个双字动物词识别成了单字动物词。相较于其他6 种模型,Bi-LSTM-CRF的这种错误频率最高。
(3)BERT系列模型。BERT-base-Chinese在由Google构建过程中,采用了掩码语言模型任务(MLM)和下一句预测任务(NSP),前者使得模型能够更好地根据语境对词汇进行预测,后者旨在让模型更充分地学习到上下文的关系。SikuBERT在由BERT-base-Chinese 继续训练过程中仅保留了掩码语言模型任务,移除了对性能提升不明显的下一句预测任务。
在测试实验中,SikuBERT和SikuRoBERTa分别相较于它们的基础模型BERT-base-Chinese 和 Chinese-RoBERTa-wwm-ext 的性能,都有大幅度提升,这表明利用《四库全书》语料进行继续训练取得了明显的成效。其中SikuBERT 表现最优,且体现出较好的泛化能力,其可以结合上下文对动物词进行正确的预测,如一次测试中输出动物词识别结果有:“游O环O胁O驱O,O阴O靷O鋈O续O,O文O茵O畅O毂O,O驾O我O骐B-A馵E-A。O”和“玄B-A蝯E-A失O于O潜O林O兮O,O独 O 偏 O 弃 O 而 O 远 O 放 O。O”,而“骐馵”“玄蝯”这两个词并未曾在本次训练语料中出现。SikuRoBERTa 表现略微逊色于SikuBERT,可能是因为其基础模型使用了全词遮罩技术,在预训练阶段注重对词的编码,而SikuBERT的基础模型则注重对字的编码。由于汉语单字成词的现象普遍,以字为承载语义基本单位的频率较高,因而SikuBERT 训练后具有较好的识别效果。而GuwenBERT-base是基于简体中文语料训练而来,其在繁体中文语料上的表现不佳。
5 《史记》动物词识别
本研究将基于SikuBERT构建的古籍动物词识别模型应用于汉字繁体版数字化《史记》文本的动物词识别,以验证模型实用性,也为基于《史记》的动物知识挖掘提供研究材料。以《史记·司马相如列传》的一段话为例,动物词识别结果输出为:“其O兽S-A则O㺎O旄O貘B-A嫠E-A,O沈B-A牛E-A麈B-A麋S-A,O赤O首O圜O题O,O穷O奇O象S-A犀O”。可见模型可以正确识别出其中常见的动物词“兽”和“象”,并且还正确识别出了“貘嫠”“沈牛”等未曾在25部先秦典籍中出现的词,再一次体现出SikuBERT较好的泛化能力,可以结合上下文对动物词进行正确的预测。对识别结果对照原文进行核对和统计计量,共识别出词数1,864个,其中正确动物词1,707个,识别准确率达到91.6%,共有不重复动物词335个,动物词长度为1-3,其中不重复单字动物词140个,不重复双字动物词189个,不重复三字动物词6个。表7列举了频次最高的前10个单字动物词和双字动物词。从表7中可见,单字动物词频次显著高于双字动物词频次,最高频次单字动物词为“马”,最高频次双字动物词为“凤皇(凤凰)”。

表7 《史记》记载频次前10的动物词
经对比《史记》和25 部先秦典籍动物词,存在两方面相似特征。一是单双字动物词频次特征相似。即单字动物词频次显著高于双字动物词。二是高频次动物词的种类构成相似。10个最高频次单字动物词有7个相同:“马”“牛”“兽”“羊”“龙”“鱼”“鸟”。
本研究未对《史记》进行动物词标注计量。因此,不能计算模型识别结果的召回率和调和平均值。但是《史记》与先秦典籍所使用的文字和语言表达方式十分接近,且《史记》记载的大量内容在历史时期上都属先秦时期。所以,上述两方面的相似特征可以从侧面印证针对《史记》中动物词的识别任务,该模型是有效的,其比较高的识别准确率可能与训练用语料规模比《史记》语料规模大得多有关。同时也可以从侧面印证该模型对《史记》中动物词识别得到的结果是合理的,该结果可以作为进一步深入挖掘《史记》记载动物的种类、功用等知识的材料。
从人文角度看,《史记》动物词频次高低反映了动物词所指代的动物与西汉以前人们生产生活联系的密切度,本研究获得的结果与历代对《史记》研究积累的认识总体一致。如“马”,最晚在商代已经有马[28],在战国时期开始有骑兵[29]。“马”在古代社会中具有极其重要的影响力和地位,如《史记》中“马”所在的句子“优孟曰:马者王之所爱也,以楚国堂堂之大,何求不得,而以大夫礼葬之,薄,请以人君礼葬之”,背后的故事体现出古人对马的珍视程度。还有“是年,晋公子重耳过宋,襄公以伤于楚,欲得晋援,厚礼重耳以马二十乘”“范睢归取大车驷马,为须贾御之,入秦相府”“今匈奴负戎马之足,怀禽兽之心,迁徙鸟举,难得而制也”,分别表明马还作为外交礼品以及乘骑工具用于交通、战争,因此还出现“千里马”“乘马”“战马”“戎马”等词。“马”在古代还被剥削阶级上层作为祭祀殉葬物品。与“马”类似,“牛”也是与古人生产、生活关系密切的动物。春秋时期已经有人用牛耕作,到战国时期,开始使用铁犁等农具,牛耕效率明显提升。《史记》中“牛”所在的句子有“祭日以牛,祭月以羊彘特”“牛者,耕植种万物也”“……自天子不能具钧驷,而将相或乘牛车,齐民无藏盖”,分别反映牛作为祭祀用品、耕作动力、用来拉车等多种用途。
6 结语
本研究利用先秦典籍动物命名实体语料库,使用多种模型构建了多个典籍动物命名实体自动识别模型,通过对比分析,验证了预训练语言模型SikuBERT针对典籍中动物这一细分知识领域开展自然语言处理任务的优势,为典籍文献中动物命名实体自动识别提供了有效方法。但相比数字人文研究追求准确、详尽识别命名实体的目标还有距离。进一步提升SikuBERT模型性能的措施可以从以下方面展开:一是检查25部古籍动物词的标注准确性,提高标注质量,特别是要详尽、准确标注;二是适当扩大语料库规模,使模型能够在训练过程中充分学习到更多动物词及其上下文的特征。此外,还可尝试构建融合CRF的SikuBERT模型,使得模型对命名实体识别结果的标签转移具有约束能力,或尝试构建融入领域词典的深度学习模型,以期取得更好的识别效果。
注释
①访问地址:https://github.com/Ethan-yt/guwenbert.
