深度学习背景下计算机视觉课程教学改革
2022-09-22陈章宝邓运生
陈章宝 邓运生 李 壮
(蚌埠学院电子与电气工程学院, 安徽 蚌埠 233030)
人工智能技术是新一轮科技创新和产业变革的重要驱动力量,深度学习是其中最有影响力的关键技术。近十年来,深度学习在技术创新和产业实践中均取得了巨大成就,使得基于深度学习的计算机视觉、自然语言处理、语音技术取得了突破性发展,并在相关领域中得到了广泛的应用。与机器学习的其他方法相比较,深度学习使用深层神经网络构建特征表示和分类的一体化模型,利用大量的样本数据对模型进行训练,让模型从大数据中学习以提高自身的性能。计算机视觉是深度学习技术发展最重要的领域,作为深度学习模型的LeNet是第一个卷积神经网络,并且在手写数字识别上取得了很好的效果,2012年AlexNet模型在ImageNet大赛上夺冠,将错误率从26%降低到了15%,从此深度卷积神经网络大幅度超越传统的特征提取+分类器的计算机视觉方法,在图像分类、目标检测、图像分割等领域均取得了长足发展。
目前本科专业的计算机视觉教学以图像的基础处理和传统的机器视觉算法为主,且图像处理的内容较多,如图像变换、图像滤波、形态学图像处理、图像编码与压缩等,机器视觉算法主要介绍边缘检测、区域分割、SIFT/SURF、ADABOOST等算法,没有将近年来以深度学习为基础的计算机视觉最新研究成果涵盖进来。本文根据我校自动化和机器人工程专业的图像处理和计算机视觉课程教学实践,在基础的图像处理和传统的计算机视觉算法介绍的基础上,加入了基于深度学习理论的计算机视觉部分,开展卷积神经网络相关知识的讲授,进行了图像分类、目标检测、图像分割等教学案例设计。
1 计算机视觉技术发展
人类感知周围环境80%的信息来源于视觉,计算机视觉就是要让机器像人一样具有视觉感知能力,如图像分类、目标检测、图像分割、三维视觉、目标跟踪等。计算机视觉对世界的认知还处于实现单一任务的初级视觉阶段,还远没有达到人类的视觉感知、信息处理和认识能力,不过在人类生物视觉的启发下,通过模仿生物视觉神经系统的感受野(receptive field)概念,提出的基于卷积神经网络的深度学习理论并持续发展,当今计算机视觉在复杂场景下的视觉理解,融合视觉、语音和文字等多源信息的视频理解方面均取得了重要的研究成果。
1.1 图像分类
图像分类是计算机视觉的最基本任务,也是深度学习技术研究最为充分的视觉任务场景。ILSVIC(ImageNet Large-Scale Visual Recognition Challenge)大赛是一个基于ImageNet数据集的图像分类任务挑战赛,该竞赛从2010年开始举办,到2017年是最后一届。2012年Alex Krizhevsky提出AlexNet网络并在ILSVRC大赛中夺冠,以15.3%的Top-5的错误率远超传统算法如SIFT、LBP、HOG等传统的图像分类方法,显示了深度学习强大的特征抽象和表示能力,并轻松实现端到端的训练,在大数据下表现出明显的优势。随后VGG、GoogleNet、ResNet[1]等网络被相继提出,图像分类错误率进一步减少,甚至超出了人类对图像的分类能力,目前细粒度图像分类(Fine-grained image categorization,FGIC)技术,实现同一类别的子类分类,也取得了长足的发展。图像分类模型的发展历程如图1上所示,这些模型是计算机视觉技术的基础网络,图像分类中的经典网络也成为目标检测、图像分割等其他视觉任务的骨干(Backbone)网络。
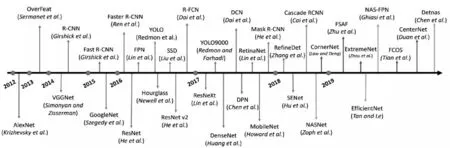
图1 计算机视觉模型发展历程
1.2 目标检测
目标检测是对图像中感兴趣的对象进行定位(Localization)并分类(Classification),输出对象的边界方框和标签。由于受到目标的复杂背景、光照变化、尺度变化、姿态多样、相互遮挡、非刚性形变等多种因素的影响,使得目标检测任务更加具有挑战性。基于深度学习的视觉目标检测网络主要有二阶段网络R-CNN系列和单阶段网络YOLO、SSD系列等。
2014年Girshick等提出基于选择性搜索(selective search)的R-CNN[2](region with convolutional neural network)两阶段目标检测网络,使得基于深度学习的目标检测的准确率超越了传统的目标检测方法30%,随后Fast R-CNN、Faster R-CNN网络被陆续提出,使得目标检测精度大幅度提高而且检测速度达到实时状态,基于深度学习的目标检测技术进入实用阶段。2016年以YOLO[3](You Only Look Once)为代表的单阶段目标检测系列模型相继提出,通过将目标检测设计成单一的回归任务,同时回归出目标的位置和类别,使得单阶段目标检测算法达到了满足实时检测要求(FPS > 30)的高精度算法,并实现在边缘端的部署, YOLO系列模型逐渐成为物体检测的主流模型。目标检测算法的发展历程如图1下所示。近年来基于 Transformer 的目标检测算法研究引发热潮,Transformer模型基于注意力机制,首先在自然语言处理(NLP)领域取得巨大成功,并成功迁移到计算机视觉领域。
1.3 图像分割
图像分割的任务是区分出图像中不同物体所在的区域,按照分割的精细程度,可以将图像分割归为三类:语义分割、实例分割和全景分割。语义分割是要求区分出图像中每个像素所属的类别,实现像素级别的分类;实例分割是在语义分割的基础上,实现同一类别的不同个体区域的划分;全景分割包含语义分割和实例分割两大任务,实现对图像中的所有物体,包括背景进行像素级别的分类。2017年随着全卷积网络[4](Fully convolutional network, FCN) 的提出,随后相继出现了DeepLab系列、U-Net、PSPNet等图像语义分割模型,DeepMask、Mask R-CNN、PANet、Mask SSD等实例分割模型;UPSNet、AUNet、TASCNet等全景分割模型。基于深度学习的图像分割算法超越了传统的基于边缘和阈值等算法。
近年来随着短视频在社交媒体的广泛流行,基于深度学习的视频分析和处理技术备受关注,在视频理解、行为识别、目标跟踪以及视频生成等领域,深度学习技术均取得了突破性的进展和应用落地,特别是结合视频、文字和语音的多源信息融合的视频分析和理解技术研究定会称为未来的发展趋势,必将成为今后一段时间最为热门的研究领域。
2 深度学习对计算机视觉教学的新要求
从深度学习理论在计算机视觉领域的发展和应用现状可以看出,深度学习是推动计算机视觉发展的关键技术,并引领计算机视觉技术继续发展。这也为本科阶段的图像处理和计算机视觉课程的教学内容更新和教学手段的改进提出了新要求,教学革新势在必行。
2.1 理论方法不同
计算机视觉技术可以分解为三个层次,既底层的图像处理、中层的特征提取和上层的图像分析。底层的图像处理技术实现图像的增强与复原,其输入和输出皆为图像,便于后续的图像特征提取和分析;中层处理是从图像中提取特征,形成“非图像”的表示和描述,典型的特征表示方法有直方图、LBP、SIFT、SURF、HOG等算法;高层的图像分析主要包括图像分类、分割、目标检测、视觉跟踪、视频理解等。现有的计算机视觉课程的教材和教学内容大多以“特征提取+分类”的模式。在深度学习的大背景下,计算机视觉技术表现为如下的特点。
(1) 深度学习的计算机视觉方法采用深度神经网络(deep neural network, DNN)作为视觉系统的基本网络,构成图像分类、目标检测、图像分割、目标跟踪和视频分析的骨干网络,通过海量数据训练出网络参数,端到端的实现特征提取与分类,避免了复杂的特征工程设计,最终的图像分类精度等指标大幅度超越了传统方法。
(2) 深度学习更加容易发挥大数据的优势,传统的机器学习方法如BP神经网络、支持向量机(support vector machine, SVM)、AdaBoost等机器视觉方法在数据量少时泛化能力弱,导致分类效果差,数据量多时效果提升变缓。深度学习具有与生俱来的适配大数据的能力,数据量越大效果越好。深度学习的标准数据集皆为大规模数据集,如ImageNet数据集就有1400万张标注图片,常用数据子集也有百万张图片,深度学习在工业界的应用中,也需要有大量的场景数据,海量的数据可以解决一切问题。
(3) 深度学习强大的特征表示能力,利用模型中的很多个隐藏层,通过特征组合的方式,逐层将原始的输入图像转化为浅层的空间特征,中层的语义特征和高层的目标特征,最终实现分类和预测任务。深度神经网络不仅可以实现图像特征的抽取,同样也可以实现语音、文字信号等特征的抽取和表示,具有很强的通用性,更易于实现融合视频、文字和语音的多任务学习和多模态学习任务,推动视频分析技术的发展。
(4) 实现端到端的训练,传统的计算机视觉技术需要进行“图像预处理+特征提取+分类预测”三个阶段,对于特定的任务,需要进行针对性的特征工程设计和分类器设计。深度学习不需要进行任务的阶段划分,而是完全交给深度神经网络模型直接学习从原始数据到期望输出的映射,直接实现从图像输入到任务输出。
2.2 实验平台不同
深度学习对实验平台的要求主要体现为大数据集、硬件训练和部署平台、软件框架三个方面。传统计算机视觉算法对数据集和训练平台的要求都不高,在个人电脑和ARM控制器上就可以实现训练和部署,而深度学习发展起来的几个关键因素,就是庞大的数据集、GPU的并行算力,以及深度学习框架。
在计算机视觉落地项目中,很难获取像标准数据集的规模,在工业品瑕疵视觉检测和异常场景分析中,数据采集比较困难,导致数据量较少,样本数据类别的不均衡等情况,解决此类问题的方法可以通过数据扩增的方法解决数据量不足的问题,通过损失函数的样本权重设计等来解决数据不均衡的问题,将通用数据集上的预训练模型迁移到场景数据集等来提高视觉模型效果。
通常深度学习的训练和部署对硬件平台的要求较高,需要用高配置的GPU电脑、服务器,或者云服务器等。对精度和实时性要求不高的场合,也可以进行模型的轻量化设计,利用模型蒸馏、神经网络搜索、剪枝和量化,进行模型压缩,获取小容量模型并部署到移动端或者嵌入式设备上。
深度学习的快速发展,以及模块化设计和计算特性给深度学习框架的开发提供了便利,目前具有代表性的框架有Google的TensorFlow、Meta的Pytorch,国内的深度学习框架包括百度于2016年推出的飞浆(PaddlePaddle)、旷视科技的MegEngine、华为的MindSpore和清华大学的Jitter。框架的推出为深度学习的研究和落地提供了极大的便利,加速了深度学习的研究进度,降低了模型设计和训练的难度,推动了相关项目的快速落地。
3 教学改革与创新
随着深度学习技术的发展,在计算机视觉课程教学中加入深度学习的入门知识和基础理论势在必行,由于课时的有限,需要弱化部分图像处理和传统计算机视觉的内容,同时进行教学资源和实验平台建设,并进行教学模式的创新,在进行传统计算机视觉教学的同时,紧跟新技术的发展步伐,引领学生进行基于深度学习理论的计算机视觉技术学习和研究。
3.1 教学内容优化
在深度学习主导计算机视觉技术的当今,为了将深度学习理论融入计算机视觉课程的教学中,需要对原有的计算机视觉课程的教学内容进行部分的优化,压缩传统视觉方法中的部分教学内容,特别是传统“特征提取+分类器”等被深度学习完美替代部分的教学内容,对压缩的部分只进行理论知识的介绍,不讲算法的实现过程。下面以张铮的教材《数字图像处理与机器视觉》[5]为例,涉及的部分教学内容如表1所示,需要增加深度学习理论的基础教学内容如表2所示。
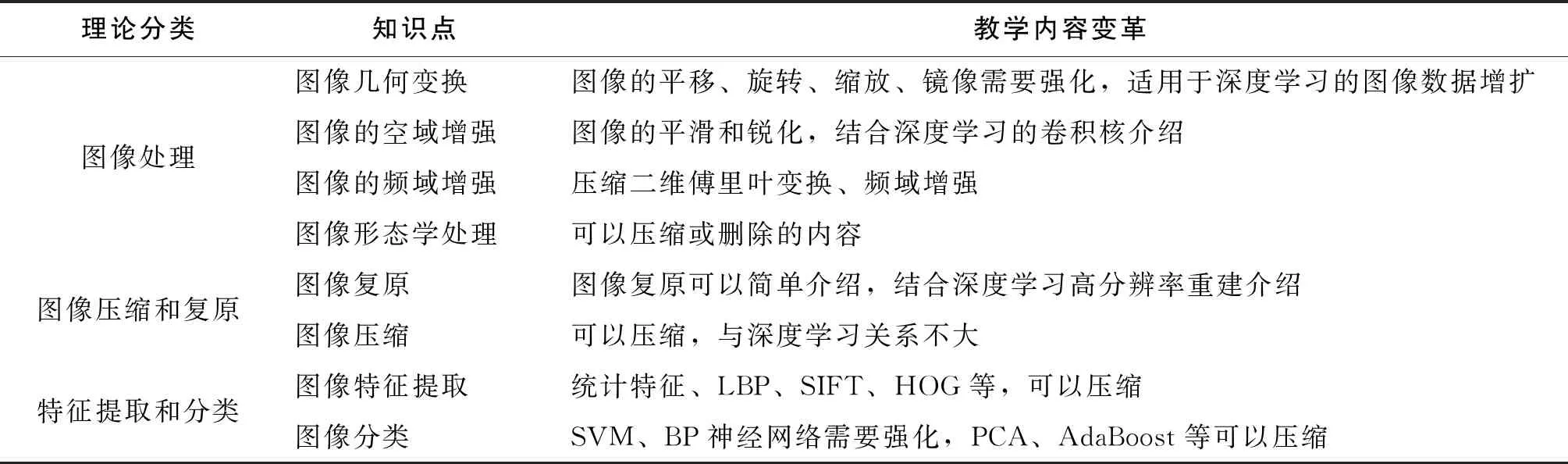
表1 部分压缩的教学内容
表1对计算机视觉课程的教学内容进行了优化设计,压缩了部分教学内容,如图像的频域增强,传统的图像特征提取和分类器等,压缩不等于不讲,而是简单讲,在教学设计中是需要了解的内容。强化了与深度学习理论相关的部分内容,这些内容在教学设计中是需要重点掌握,如图像几何变换常用于数据增扩,结合迁移学习,在深度学习的落地项目中广泛使用;SVM作为经典的分类模型,在小样本分类项目中表现优越,经典深度学习模型也有用SVM进行分类;BP神经网络模型是深度学习模型的基础,也是经典的分类器模型,是学习深度神经网络的入门知识。此外在图像的空域增强中,图像滤波算子结合卷积核进行介绍,滤波算子参数是确定的,而卷积核参数是学习出来的,更容易让学生了解图像卷积的概念。
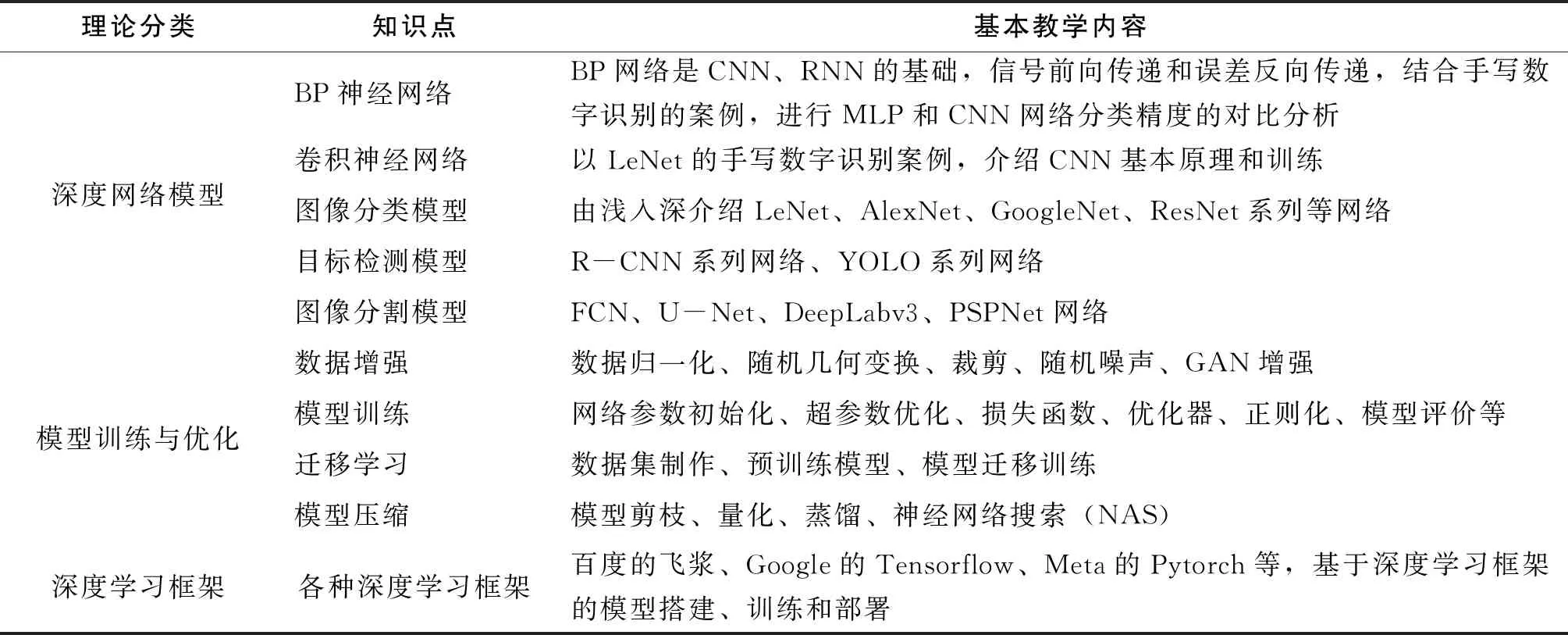
表2 深度学习教学内容
表2给出了本科专业教学中深度学习的基本教学内容,包括神经网络基础,基本的图像分类、目标检测、图像分割模型,模型训练和优化的基础教学内容,以及常用的深度学习框架。此表是在计算机视觉课程的教学实践中,总结出来的关于深度学习的教学类容设计,强调基础知识的掌握,基本平台的应用,引领学生入门深度学习技术。
3.2 教学平台和资源建设
深度学习是在大数据和大算力的推动下发展起来的技术,且其网络模块众多,基础理论复杂,这些因素都给学生入门深度学习造成了很大的难度。深度学习通过信号的前向传输和误差的反向传递,实现基于梯度下降的训练优化,编程特性和计算特性较为模式化,统一的编程框架会给学习和开发提供极大的便利,当今的深度学习框架也被称为人工智能时代的操作系统。教学中利用百度公司开源的飞浆(PaddlePaddle)深度学习框架[6],飞浆深度学习框架是国内开源最早的深度学习框架,其下接芯片,可以适配不同的底层硬件,上承应用,适应各种算法应用,对接云计算和大数据资源,集核心框架、工具组件和服务平台于一体,飞浆全景图如图2所示。
飞浆核心框架实现动态图和静态图两种编程方式的统一,集模型训练和预测于一体,开源了计算机视觉、自然语言处理、推荐系统和语音识别四大类官方模型,其中飞将视觉模型库(PaddleCV)提供了大量的图像分类、目标检测、图像分割、图像生成、视频分析等视觉算法的预训练模型。飞浆还集成了迁移学习、训练可视化等一系列工具组件,进行深度学习的开发训练和应用部署。飞浆还提供的AI Studio在线开发实训平台,集合了教程、案例、经典数据集、云端的运算资源、以及比赛平台和社区。利用百度飞浆深度学习框架和AI Studio平台,全面解决了深度学习教学中对大数据、大算力、框架和平台的要求。百度公司的平台保障和技术支持,为开展深度学习的教学、科研和工程开发提供了极大的便利。
教学资源建设是基于百度AI Studio平台开展教学活动,进行教学案例设计,开展集数据准备、模型设计、模型训练与评价于一体的教学活动,教学中进行了如表3所示的教学案例设计。在本科阶段计算机视觉教学中,深度学习理论的教学案例设计侧重于入门案例[7]和基础案例,前沿技术案例可以简要介绍,要进行进阶式的案例设计,并将深度学习的基础知识融入教学案例中。

表3 深度学习的教学案例设计

(续表3)
3.3 教学模式创新
“计算机视觉”是在传统图像处理和机器视觉课程的基础上,融入了深度学习技术的课程,实践性强。新工科背景下,课程教学坚持以“学生为中心,以产出为导向”的OBE教学理念,进行教学模式创新[8]。本科阶段的“计算机视觉”课程教学以基础理论讲解、案例教学、工程实践为主,通过规范教学与实验平台、改革课程教学模式和实践项目化教学等手段开展课程教学的改革和探索。
(1) 规范教学与实验平台。基于深度学习理论的计算机视觉教学需要大数据和计算平台的支撑,打造规范的教学和实验平台是开展教学活动的基础,采用百度PaddlePaddle深度学习框架,百度AI Studio教学平台开展教学活动和管理。
(2) 改革课程教学模式。首先,以案例推动教学,通过案例引申出具体的教学内容,实现由面及点、由点到面的知识体系教学,例如通过图像分类案例,可以讲解数据集预处理、模型设计、训练和预测等一系列知识点,所有知识点又构建了整个分类模型。其次,以作业提升教学,教学中以学生为中心,引导学生去分析问题和解决问题,通过优质的课程作业设计,让学生掌握数据处理与增扩、深度学习框架应用、模型结构优化、参数调节对提高分类精度的效果。最后,以应用拓展教学,通过深度学习视觉案例的应用部署,激发学生的学习兴趣,例如将训练好的预测模型如花卉识别、手势识别、交通标志检测、人体分割和抠图等,部署到云端、服务器和电脑端,嵌入式边缘设备端等。
(3) 实践教学。实践教学是课程教学的延伸,主要通过课程设计、毕业设计、大创项目、学科竞赛、学生参与教师的工程项目和科学研究等方式,让学生掌握工程需求分析与系统设计、数据分析与采集,模型设计与优化、模型部署的全过程,增强学生利用所学知识解决实际工程的能力,提高工程化应用型人才的培养成效。实践中,在实验室搭建了一个人脸识别项目,带领学生不断提升系统性能,从当初的人脸识别、口罩识别、到现在的融合视觉和语音的人机互动;指导学生参加全国智能汽车竞赛,讲授智能车的视觉导航和目标识别关键技术,让学生实践深度学习的技术在智能车、自动驾驶的应用;在工业机器人视觉引导抓取的项目中,实现了3D视觉的目标物体姿态检测,并引导机械臂以适当的姿态进行抓取,这些系统得到了大创项目、学校工程和科研项目的经费支撑,并转化为学生的毕业设计课题;学生参与老师的病鸡识别、玻璃品瑕疵检测项目,提高了学生的工程能力,培养了学生的科研意识。
4 结论
通过在计算机视觉课程中引入深度学习的教学内容,通过教学内容优化、教学资源建设和教学模式创新,开展案例化的教学,引导学生逐步进入学科前沿知识的学习和应用工程开发。通过多年的教学实践,学生对基于深度学习的视觉技术产生了浓厚的兴趣,我院学生在近三年的全国大学生智能车竞赛百度深度学习创意组比赛中屡获大奖;学生在百度AI studio平台的比赛中,轻松获取Top10名次。本着“以学生为中心,以产出为导向”的OBE教学理念,开展课程教学研究与改革,进行工程化应用型人才的培养,学生的学习热情持续增长,工程能力显著提升,科研素养逐渐养成。
