一种基于合作博弈的分布式蜜罐部署策略
2022-09-22郭昊月
郭昊月,沈 勇
(江苏科技大学计算机学院,江苏镇江 212100)
0 引言
在互联网时代,网络安全问题愈发受到重视[1]。随着黑客的攻击技术越来越高明,网络安全已经被上升至国家安全的重要战略高度。蜜罐技术是一种网络诱骗陷阱,其作用是拖延攻击者进程并收集其信息。分布式蜜罐则是将众多蜜罐组合成一个系统,从而力求获取更大收益[2-3]。随着网络安全问题复杂程度的不断提高,单一的蜜罐技术已不足以应对[4]。网络攻防是一种偏向于不完全多阶段演化博弈的过程,因此很多学者尝试将蜜罐技术与不同的博弈论思想相结合。例如,Kiekintveld 等[5]提出若干种博弈模型用于配置蜜罐;石乐义等[6]基于非合作不完全信息动态博弈理论推理分析了拟态式蜜罐诱骗博弈中存在的贝叶斯纳什均衡策略;李阳等[7]在演化博弈的基础上对蜜罐技术的有效性进行了研究,分析了如何使博弈的收益最大化;赵柳榕等[8]通过比较不同场景下攻防博弈的纳什均衡混合策略,得出了蜜罐与入侵检测系统技术组合的最优配置;李娟利等[9]将蜜罐系统与不完全信息动态博弈融为一体,进行了模糊矩阵博弈的网络安全威胁评估。
尽管分布式蜜罐技术已被广泛应用,但关于其部署策略方面的研究仍较少,现有研究多关注单一蜜罐的大量部署,该情况下蜜罐取得的收益往往不及预期。为此,本文提出一种基于合作博弈的分布式蜜罐部署策略,创新性地将合作博弈思想与蜜罐技术相结合,在分布式蜜罐系统场景下对Shapley 值法进行优化,并在此基础上建立收益分配模型,从而使蜜罐获得计划内的更大收益,同时在分布式节点中加入聚类分流技术以提高多项系统的性能。
1 相关理论
1.1 蜜罐技术
根据部署目的,蜜罐常分为生产和研究两种类型[10-11]。生产蜜罐通常被放置在生产网络中与生产服务器协同工作,对整体安全状态进行优化;研究蜜罐则用于收集在不同环境下的攻击方式和攻击策略等信息。在交互深度方面,蜜罐可以分为低交互和高交互两种,详见表1。
相较于单一蜜罐系统来说,分布式蜜罐扩展了蜜罐系统所能收集信息的广度,不仅保留了单一蜜罐的优点,克服了其收集数据量少的缺陷,还可以保障系统安全性。分布式蜜罐系统分为总服务器、节点服务器和蜜罐层3 层,见图1。其中,总服务器集成了用户管理、节点管理等各种功能,负责整个系统的管理和数据分析;各节点服务器负责对网段内的蜜罐进行配置和管理;蜜罐层由当前节点指定需求功能的蜜罐组成。
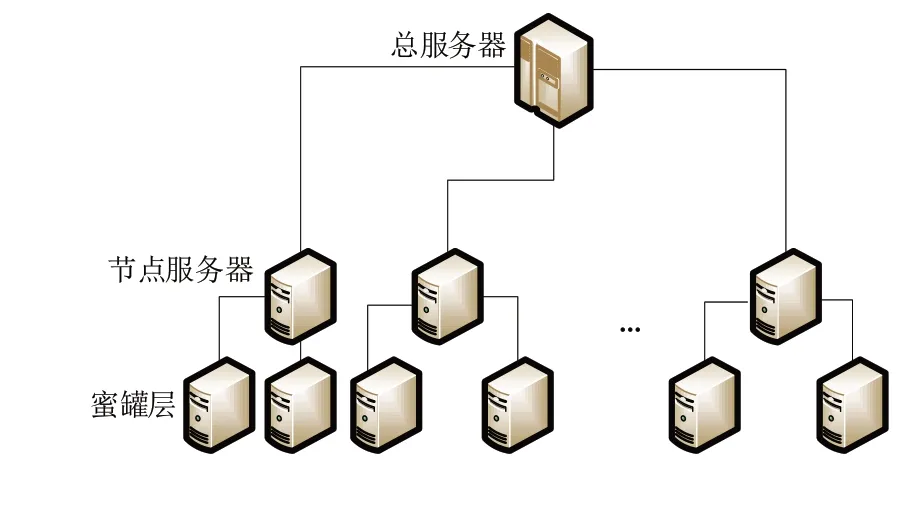
Fig.1 Structure of distributed honeypot system图1 分布式蜜罐系统结构
1.2 合作博弈
合作博弈是指众多参与者以合作的方式所进行的博弈,其常用于研究收益分配问题。本文探讨的一个重要问题即为什么样的部署策略可以实现各蜜罐的收益最理想化,因此采用合作博弈法讨论。
基于合作博弈的Shapley 值法于1953 年提出[12],该法是解决n人合作对策问题的数学方法[13],常用于收益分配问题的分析。当联盟有n个参与者时,该联盟中若干参与者的不同组合均可得到一定的收益,且随着参与者的增加,收益也在增加,因此n人合作时的总体收益即为最大收益[14]。假设n个蜜罐组成联盟M,其成员的集合为N={1,2,3…,n},N的任一子集S 均对应一个收益函数V(S)且满足[15]:
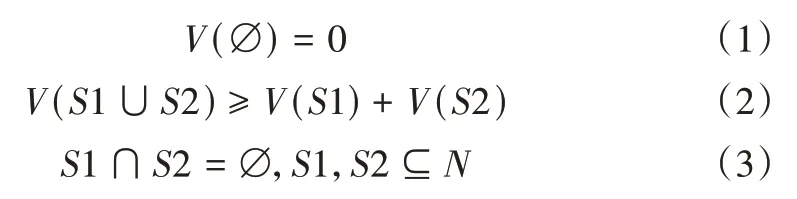
记(N,V)为n人合作博弈,V为合作博弈的特征函数。式(1)-(3)表示联盟M存在的必要性,即联盟收益值必须大于部分收益值之和。当n个蜜罐均参与联盟时,联盟将获得最大收益,将其记为V(N),表示为:
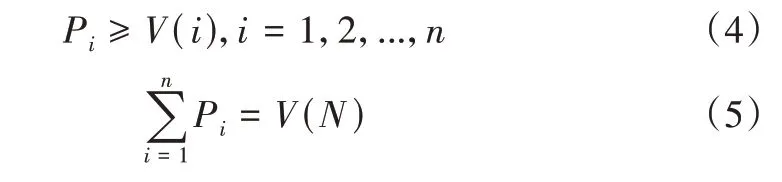
式(4)、(5)中,Pi表示联盟M中蜜罐i从V(N)中应得的收益,V(i)表示蜜罐i不加入联盟时的收益。
ϕi(v)表示第i个成员在联盟中应得的收益,则各联盟成员所得利益分配的Shapley值表示为:
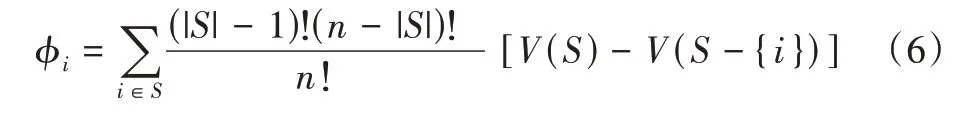
式中,|S|为表示联盟中蜜罐的个数,V(S)表示子集S的收益,V(S)-V(S-{i})为子集S中除去i后可取得的收益值。
1.3 聚类分流技术
聚类分流是一种数据处理技术,是基于聚类算法的拓展[16],其中聚类是将抽象对象的集合分成由相似对象组成的多个类的方法[17];分流是指对聚类后的数据进行不同处理,根据已聚类数据的分组判断其类型,并采取相应措施。通过聚类分流技术可以对未知类型数据进行保留分析或等待数据后续收集,将已知类型数据从疑似数据或近似数据中提取出来。在实际应用中,聚类和分流两种技术的结合可有效提高数据分析的效率和准确率。
2 基于合作博弈的分布式蜜罐部署策略
本文提出一种基于合作博弈的分布式蜜罐部署策略,旨在解决现有分布式蜜罐系统收益不合预期、资源浪费和数据处理效率低下的问题。首先对传统的合作博弈Shapely 值法进行优化,使分布式蜜罐在满足系统需求的情况下取得更大收益;其次将聚类分流技术与该模型相结合,对正确数据先聚类再处理,将错误数据抛出或传入蜜罐进行二次收集。
2.1 模型优化
根据Shapely 值法的基本原理,联盟中的利益分配是基于各参与者对联盟整体的边际收益贡献所定,影响因素比较单一。分布式蜜罐系统需要考虑系统资源的占用量、蜜罐的功能性、风险水平等因素,因此本文将根据这些因素对Shapely值法进行优化。
2.1.1 系统资源占用系数Ai1
联盟中各蜜罐占用的资源比例不同,以Q表示,Qi为蜜罐i占用的资源,n为成员个数,资源占用系数Ai1表示为:

2.1.2 蜜罐功能性系数Ai2
蜜罐的功能性系数也可以看作其有效性,常采用SPN(Secret Private Network)模型进行评估,该模型可使用PIPE模拟实现[18],通常根据模拟得出的标记概率密度函数、平均标记量等指标获取。设其功能性带来的收益为G,Gi为蜜罐i带来的收益,i为成员个数,则蜜罐的功能系数Ai2表示为:

2.1.3 系统风险水平系数Ai3
由高低交互蜜罐的风险大小来看,其与蜜罐功能性系数成正比,因此可以设不同功能蜜罐存在1 个影响因子hi,因此风险系数Ai3表示为:

2.1.4 优化后的Shapely值法模型
利益分配的修正因素用集合j=1,2,…,m表示,因此第i个蜜罐关于第j个修正因素的测度值为Aij,其中i=1,2,…,n。表2即为Shapely值法模型的相关修正因素。
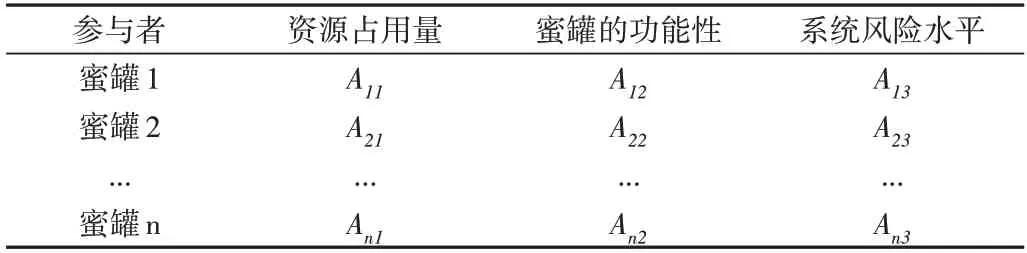
Table 2 Relevant correction factors表2 相关修正因素
修正矩阵为B,表示为:
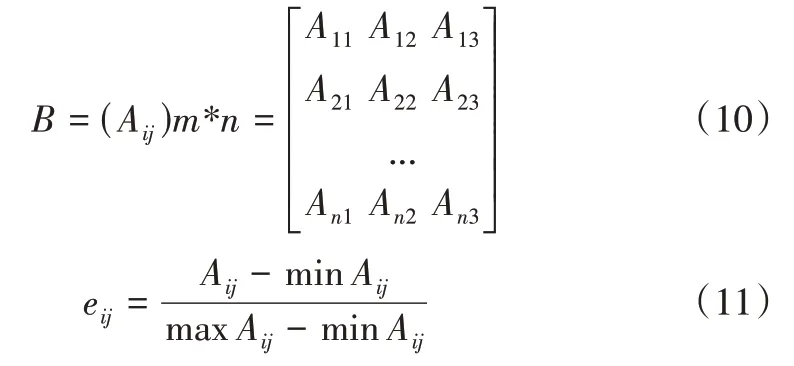
通过0-1 标准化方法对数据进行归一化处理,可以得到新矩阵E,表示为:

由于不同因素对收益的影响不同,在层次分析法的基础上分配其权重,即ω=[ω1,ω2,ω3]T且ω1+ω2+ω3=1。设不同因素的影响因数为Fi,可得到[F1,F2,F3]T=ω*F。
设蜜罐i的收益分配为ϕi′(v),其修正的收益为Δϕ(i),ΔFi表示蜜罐i 的影响因子,V(N)为联盟的最大收益值,则蜜罐i的收益为:
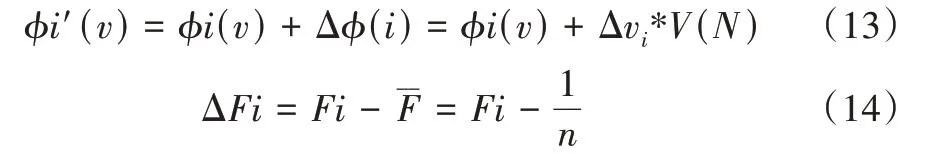
2.2 方案设计
2.2.1 模型框架
本文模型框架如图2 所示,蜜罐层主机负责搭载系统所需蜜罐,统一将数据上传至节点服务器。节点服务器首先将数据传输至聚类分流器进行归类处理,随后将合理数据交付给数据分析系统进行分析处理。
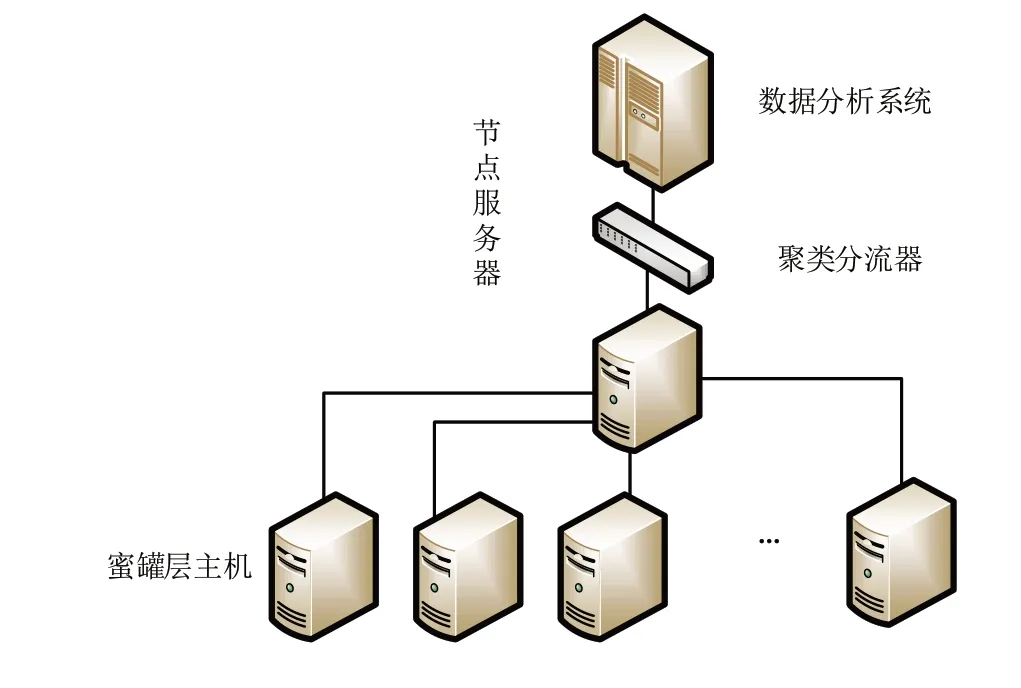
Fig.2 Model framework图2 模型框架
2.2.2 聚类分流设计
聚类分流首先实现初始中心类的划分和拓展,随后在其基础上进行数据聚类分流,详细步骤为:
(1)初始类中心选择。首先定义CDT=(U,A,V,f)为1 个分类数据表,U为对象的非空有限集合,A为属性的非空子集,V为Va的集合,Va为a的值域,a∈A;f(x,a)∈Va,为x和y关于A的相异度,当f(x,a)=f(y,a)时,Ea(x,y)=0,其他情况下Ea(x,y)=1。则x关于a在U的密度表示为:
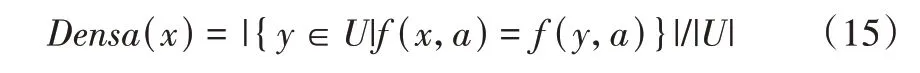
设Dens(x)为其平均密度,则Dens(x)=|。由此可见,x聚集的数据越多,成为类中心的概率越大,初始类应选择密度最大的对象。
(2)数据聚类。在初始类确定后,利用k-modes 算法将1 个n=|U|个对象聚集成k类以找到B和C,其中B=[bli],为1 个k×n的矩阵;C=[c1,c2,…,ck],cl为第l 个类中心,目的是使目标函数F(B,C)最小,其中F(B,C)表示为:
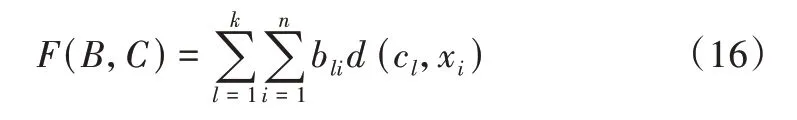
聚类步骤为:①设置变量t,令t=1,计算C(t+1),使得F(B(t),C(t+1))最小,若F(B(t),C(t+1))=F(B(t),C(t)),聚类停止,反之进行下一步;②求解B(t+1),使得F(B(t+1),C(t+1))最小。如果F(B(t+1),C(t+1))=F(B(t),C(t+1)),聚类停止,否则令t=t+1 并回到上一步;③若上述步骤执行两次后仍需令t=t+1 并回到步骤①,即两次工作均无法满足F(B(t),C(t+1))=F(B(t),C(t))时,则停止此次聚类,标记此数据无法聚类并重新送回蜜罐,随后继续对后续数据进行聚类。
(3)数据分流。分流是对常见攻击手段进行分类,有利于从已有数据中分析出攻击者的攻击手段、方法和目的,对于提高系统收益有重要作用。在本文部署策略中,聚类分流通过在各节点部署聚类分流器实现,可有效提升整个系统的数据准确率和处理速度。蜜罐聚类分流器的工作流程如图3所示。
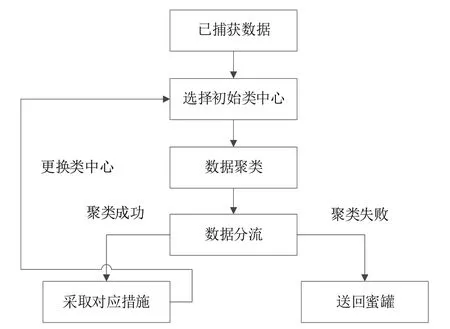
Fig.3 Cluster diverter workflow图3 聚类分流器工作流程
2.2.3 部署策略分析
对当前系统的需求确定权重系数后即可开始分析,通过系统需求对蜜罐进行收益分配,可以得到基于3 个因素Ai1、Ai2和Ai3的部署策略。各蜜罐的资源占用量分别为a1、a2...an,且(a1+a2+...+an)=A,暂将a1/A、a2/A...an/A设为t1、t2...tn。参考文献[18],基于SPN 模型对蜜罐功能性系数与系统风险水平进行评估分析,蜜罐功能性可获得的收益设为(G1,G2...G3)T,因此在Ai1主导的情况下,各蜜罐的收益向量为ϕ(v)=(L1,L2,L3...Ln),其中L均可由式(6)求得,即可求出Ai1主导的蜜罐收益值。结合归一化处理和不同蜜罐的风险水准与其功能性系数成正比的事实,暂设其风险权重为(G1h1,G2h2...Gnhn)T,且G1h1+G2h2+Gnhn=1,可得修正矩阵为:

只需将所需参数代入即可求解,随后按照系统需求确定各蜜罐收益。
本文提出的部署策略即在分布式蜜罐系统部署前通过式(18)对不同蜜罐预期收益进行计算,结合不同系统的实际需求对收益进行分配,因此可最大程度地满足实际需求。目前,分布式蜜罐常用于检测DDOS 攻击[19],亦有通过端口诱骗结合重定向技术实现的分布式蜜罐系统[20],其存在数据处理较慢且准确率不高等问题。因此,本文在分布式节点处加入聚类分流器,可在保证收益提升的前提下提高数据收集准确率和处理速度。
3 实验结果与分析
3.1 实验测试环境
3.1.1 环境设置
实验测试环境包括12 台服务器,其中9 台作为蜜罐服务器,均搭载Ubuntu18.04 系统,并配备2GB 内存和500G硬盘,安装实验所需各类型蜜罐,当蜜罐使用时开启,禁用时杀死进程;其余3 台作为节点服务器部署ELK 分析系统和聚类分流器,收集分析蜜罐获取的数据,在系统部署环境中采用各种攻击手段等频率等量级进行攻击。本次实验使用honeyd、MySQL-honeypotd 和Cowrie 3 种蜜罐,蜜罐服务器搭载以上3种蜜罐,组合方式可变。
3.1.2 参数设置
结合系统对不同因素重要性的评判,基于层次分析法确定本实验中系统资源占用量、蜜罐功能性和风险水平的权重系数分别为0.6、0.3 和0.1,因此ω=[0.6,0.3,0.1]T。设定各蜜罐收益比例为4∶3∶4,结合式(18)和蜜罐性能分析可得各蜜罐分配资源量为45%、35%和20%,系统资源量为分配给蜜罐的内存大小,将其作为实验组参数。对照组1 部署策略参照文献[14],为结合端口重定向的单一蜜罐部署法,该组采用honeyd 蜜罐,设置对照组1 用于比较不同部署策略下蜜罐的平均收益。对照组2 条件相同但未采用本文部署策略的方式,各蜜罐资源量配额为常规随机生成数,并进行5 次实验对收集到的数据取均值,设置对照组2 用于比较相同条件下本文部署策略的提升程度。具体参数设置如表3。
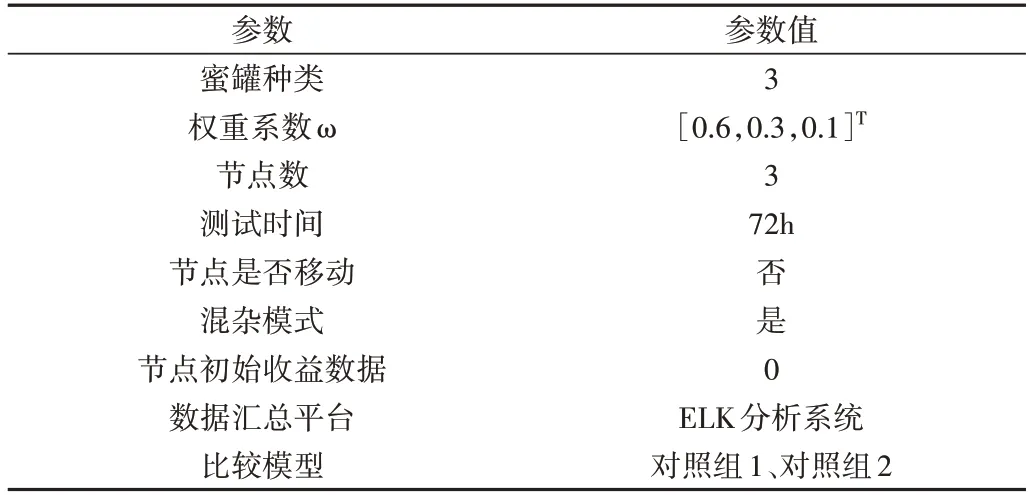
Table 3 Parameter setting表3 参数设置
3.2 实验结果与分析
各组实验差错率结果见表4。实验组差错率低于两个对照组,这是由于本文策略通过聚类分流技术对系统中的不同类型数据进行归类,并将模糊且不合规数据剔除或导回蜜罐进行二次收集,因此可以很大程度地减少分析系统的错误信息量,进而降低差错率。

Table 4 Error rate of experimental results of each group表4 各组实验差错率
数据平均处理时间t表示为式(19),其中T为检测总时间,N为信息量,在大批量数据处理后获得单一数据平均处理时间,用于检验部署策略数据处理效率。

各组数据平均处理时间见表5。聚类分流技术采用初始类中心优化,并基于不同类型信息延伸出多个中心,从而实现数据的快速归类。对归类后的信息进行分析,以分组为单位进行数据分析效率更高。与不采取聚类分流技术的两个对照组直接对大量数据进行分析处理的方式相比,实验组的数据平均处理时间最大缩短了59.22%。

Table 5 Average data processing time of each group表5 各组数据平均处理时间
系统的资源损耗率可用式(20)表示,结果如表6 所示。对照组2 资源损耗率远超对照组1,显然随机部署会大大损耗系统资源。虽然系统资源损耗不可避免,但本文部署策略可通过各蜜罐拟定收益推导出合理的蜜罐占用资源量,进而有效减小该损耗。


Table 6 Resource loss rate of each system表6 各系统资源损耗率
通过ELK 系统可得到实验组各蜜罐最终收益,结果见表7。3 种蜜罐收益比例近似为4∶3∶4,符合“3.1.2”项下所述的系统需求收益比例,因此本文部署策略实现了收益可控,即可在不同系统需求下对收益进行合理分配。
实验组与对照组的蜜罐收益曲线如图4 所示,可以看出对照组1由于蜜罐种类单一,honeyd 收益较高,但与其他组比较,对照组1 总收益仍较低;对照组2 只有Cowrie 的收益比较突出,其余两个蜜罐收益并没有实质性提高,并没有在满足系统需求的前提下将各蜜罐收益最大化;而采用本文部署策略的实验组基于合作博弈模型将资源分配完备后,在尽可能减小资源浪费的情况下将各蜜罐收益合理化、最大化。

Table 7 Each honeypot benefits表7 各蜜罐收益
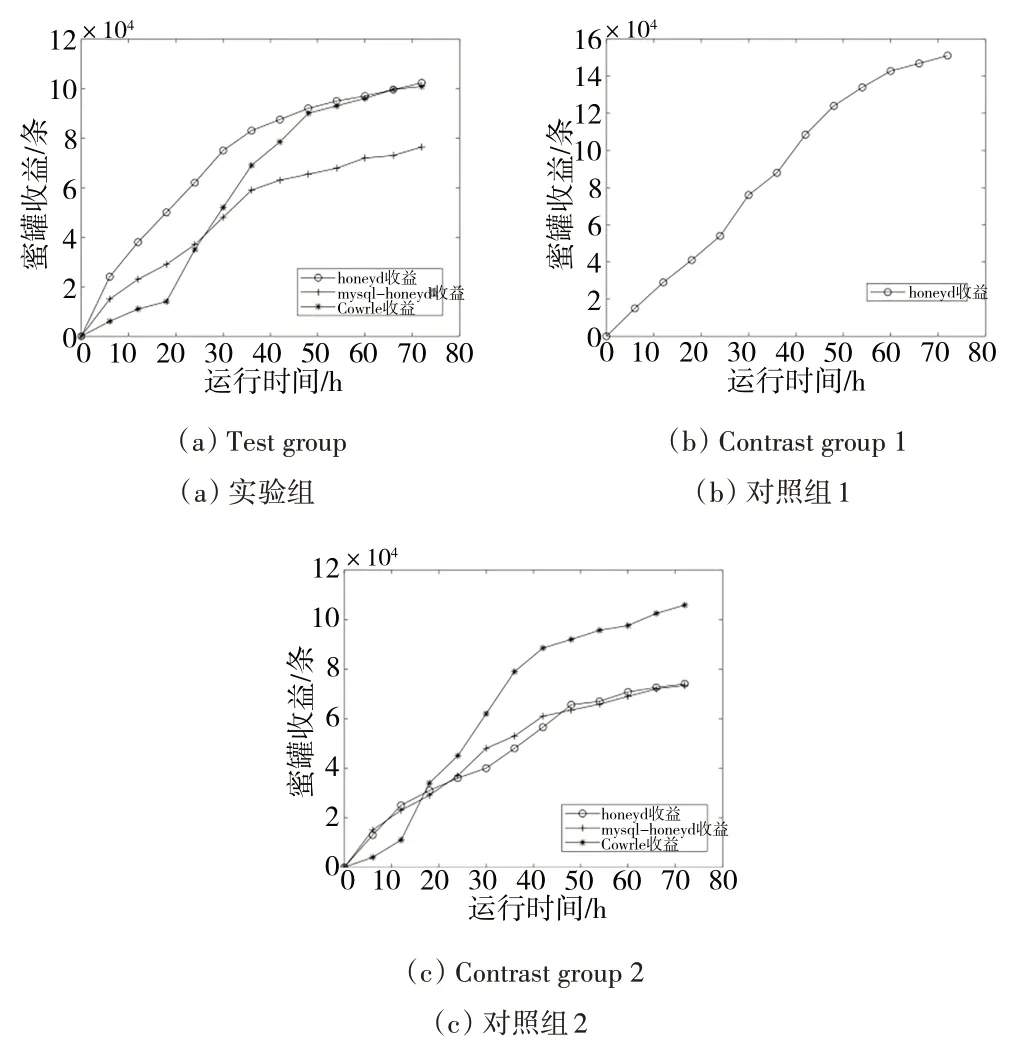
Fig.4 Honeypot income curve of each group图4 各组蜜罐收益曲线
各组蜜罐总平均收益如图5 所示,均符合蜜罐收益分布,即随时间变化蜜罐收益曲线会逐步减缓,可以证明为有效测试。由变化曲线可见,实验组蜜罐平均收益大于两个对照组,且测试时间充足,证明了合作博弈模型的有效性。综上所述,本文部署策略可结合实际需求使分布式蜜罐获得更大收益。
4 结语
本文建立了优化Shapley 值法的博弈模型,在此基础上提出一种基于合作博弈的分布式蜜罐部署策略,在分布式节点加入聚类分流技术,并通过实验验证了该策略可有效提升各蜜罐收益,且在数据差错率、系统资源损耗率和数据处理时间等方面较常用分布式蜜罐部署策略有显著提升。该部署策略可能会因蜜罐种类增加、收集多种不同类型数据而引起聚类分流效率低下的问题,未来研究方向应侧重于考察更多影响系统收益的因素以及对聚类分流技术进行改进,以提高系统的精确性和运行速度。
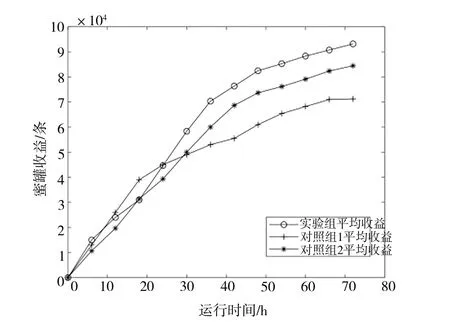
Fig.5 Average income curve of honeypot in each group图5 各组蜜罐平均收益曲线
