多模态情感识别综述
2022-09-22程大雷张代玮陈雅茜
程大雷,张代玮,陈雅茜
(西南民族大学计算机科学与工程学院计算机系统国家民委重点实验室,四川 成都 610041)
近年来,情感识别作为人工智能的关键技术之一,在远程医疗、智能家居等多种场景中得到了广泛的应用.人们每天都会产生大量具有丰富情感的多模态数据,如面部表情、语音等.基于多模态数据对情感进行识别具有重要的研究价值和应用意义.如图1所示,多模态情感识别一般分为数据预处理、多模态特征提取和多模态情感融合等几个步骤.为了提取高质量的特征,会对原始数据降噪、去重等预处理操作.多模态表示学习是利用多模态的互补性和冗余性的方式来表示多模态数据[1].多模态情感融合就是通过模态间的相互作用将来自不同模态的信息联合在一起.由于融合信息可以提供更多的情感线索,因此能够提高整体结果或决策的准确性[2].
本文分别从数据集、多模态特征提取以及多模态情感融合等方面对多模态情感识别进行系统探索.特别针对多模态情感融合这一重点问题,对特征级融合、决策级融合、模型级融合这三个主流融合策略分别进行了探讨.最后从引入新模态和多模态融合等方面对改善和提升情感识别性能进行了展望.
1 多模态情感识别数据集
在机器学习与人工智能这个大的领域,情感识别作为一门成熟的学科,有一系列不同的数据集来满足日益增长的数据需求.用于多模态情感识别的模型必须具备很强的泛化能力,既能推断出有用的社会信息,又能有效地落地于工业应用.该任务的数据集必须具备一些期望的属性,如不同的说话人、性别、讨论主题、口语、使用的词汇、情感强度以及数据量的多样性等.表1列出了常用的多模态情感数据集.
(1)IEMOCAP数据集
IEMOCAP(Interactive Emotional Dyadic Motion Capture)[3]是应用最广泛的数据集,在实验室环境中以叙述的方式收集的.包含12个小时的英语对话,男女均有,拥有即兴表演和脚本语言两种方式,并按照愤怒、悲伤等九种情绪分类.此外,它还包含高质量的视觉特征,因为面部、头部和手势的标记被用于捕捉面部表情和手势动作.IEMOCAP也是使用最早的、有良好注释和维护的数据集之一,因此绝大多数多模态情感识别模型都使用该数据集进行评估.
(2)MELD数据集
MELD(Multimodal EmotionLines Dataset)数据集[4]是一个大型的多模态多方情感对话数据集,包含13 000个来自《老友记》电视剧的话语,由1 433个对话组成,每个对话包含两个以上的说话人.每个话语都带有情感和情绪标签,该数据集分为训练集、验证集和测试集,分别对应有9 593、1 061和2 504个话语.有愤怒、厌恶等七种情绪类别.
(3)CMU-MOSEI数据集
CMU-MOSEI(CMU Multimodal Opinion Sentiment and Emotion Intensity)数据集[5]是最大的话语级情感分析和情感识别数据集,包含超过65小时的注释视频1 000名发言者和250个主题,这些视频来自于YouTube.由于许多工业产品使用类似的数据,这使得它成为最有用的数据集之一.每个视频话语有来自3个不同人的注释,以减少偏差.该数据集通过给每个例子分配一个情绪评分(-3到3之间)来进行注释,其中-3代表极端消极的情绪,+3代表极端积极情绪.
(4)CMU-MOSI数据集
CMU-MOSI(Multimodal Opinion-level Sentiment Intensity)数据集[7]由93个来自YouTube的电影评论视频组成.这些视频涵盖了2 199个话语.每个话语的标签由5个不同的工作者标注,在-3到+3的连续范围内,表示消极情绪(低于0分)或积极情绪(高于0分)的相对强度.
(5)CH-SIMS数据集
CH-SIMS(Chinese Single-and Multimodal Sentiment)是中文多模态情感分析数据集,它包含2 281个精细化的视频片段,多模态和独立的单模态注释[7].它允许研究者研究模态之间的相互作用或使用独立的单模态注释进行单模态情感识别.
2 多模态情感特征提取
特征提取是指从原始数据中提取一组特征并降低特征空间的维数这一过程.在特征提取过程中,会删除不相关和冗余的特征,从而提高算法的准确性,缩短训练时间.因此,特征提取是多模态情感识别的首要步骤,本节主要介绍文本、语音和面部表情特征的提取技术.
2.1 文本情感特征提取
文本特征提取即对文本信息进行提取,是表示文本信息的一种方法,它是对大量文本进行处理的基础.过滤法、融合法、映射法和聚类法是常用的文本特征提取方法[8].与传统的特征提取方法相比,深度学习可以从训练数据中快速获得新的有效的特征.一些研究[9-10]利用卷积神经网络(CNN)提取多模态情感识别的文本特征.循环神经网络(RNN)[11-12]用于处理顺序数据.对于涉及顺序输入的任务,例如语音和自然语言,通常使用RNNs更好.另外有各种各样的无监督架构被设计用来学习单词的向量空间表示,GloVe[31]是第一个产生健壮的词嵌入的模型之一,其次是BERT[13]模型.BERT是一种开源的预训练模型,它是在一个大型的未标记文本语料库上预先训练的,该语料库包括整个维基百科(约25亿单词)和一个图书语料库(8亿单词).之前的研究[14]使用BERT提取文本特征作为多模态情感识别中的文本模态.这些模型设计高效,经过大量数据的预训练,具有很强的特征表示学习能力,能够捕捉词义和上下文.在这一点上,为了方便与基线模型进行比较,大多数多模态情感识别模型都采用了GloVe嵌入.
2.2 语音情感特征提取
将语音信号分割为20~30 ms的帧,然后从这些帧中提取特征,这些帧统称为低级描述特征(LLDs).文献[15]提取17维的LLDs声学特征进行情感识别.话语的长度因数据库而异,由于话语长度的不同,数据库中每个话语的帧数也不同.话语长度的确定是通过在话语的所有帧中提取每个LLDs特征的统计描述符来实现的.高级统计描述特征(HSDs)是在LLDs的基础上做一些统计(如均值、最大值)而得到的.文献[16]分别提取这两个层次的声学特征,进行有效的互补融合达到了较好的结果.使用Librosa[17]音频处理库和openSMILE[18]开源软件可以进行简单的语音特征提取.深度学习算法在语音情感识别中也得到了广泛关注和应用,例如卷积神经网络(CNN)[19]被广泛应用于图像相关特征学习.因此当给定一种将音频信号映射到二维表示(图像)的方法,CNN就可以学习深度音频特征.循环神经网络(RNN)[20]以及它的改进长短期记忆网络(LSTM)[21]同样也取得了显著的改善.最近,为了从初始波形中学习音频表示,人们提出了各种表示学习技术和结构.SincNet[32]网络使用有监督的方式以CNN处理原始语音波形.另一方面,从音频中学习语音表示的无监督方法正在迅速发展,并产生了高效的架构,如wav2vec[33],wav2vec 2.0[34]是目前先进的表示学习模型.
2.3 面部表情特征提取
虽然从理论上讲,肢体语言在表达人的情绪方面起着重要的作用,但多模态情感识别的相关数据集大多是捕捉人脸面部表情.面部表情特征提取会产生更小、更丰富的属性集,这些属性集包含脸部边缘、对角线等特征,以及嘴唇和眼睛之间的距离、两只眼睛之间的距离等信息.特征提取的方法包括基于几何的特征提取和基于外观的特征提取.前者基于几何的特征提取方法诸如边缘特征和角点特征等,Neha等人[22]分析了特征提取技术Gabor滤波器的性能,他们还测试了平均Gabor滤波器,并比较了两种滤波技术以提高识别率;后者利用突出的点特征来处理脸部不同点的状态,比如眼睛的位置,嘴巴和眉毛等重要点的形状.传统的特征提取方法大多采用局部二值模式(LBP)作为特征提取技术,LBP是一种基于通用的框架,用于从静态图像中提取特征.此外,随着深度学习的发展,其特征提取方法要比传统方法要好.近年来研究人员提出了一系列深度卷积神经网络(CNNs)方法用于视频序列中面部表情识别任务的高级特征学习.其中,具有代表性的深度模型有AlexNet[23]、VGG[24]、GoogleNet[25]、ResNet[26]等等.特别是Li等人[27]利用预先训练的VGG网络学习了专门的面部表情识别模型.Zhang等人[28]采用3D-CNN网络来学习视频序列中与面部情绪表达相关的情感视频特征.
3 多模态情感识别
在多模态情感识别中,特征表示和多模态情感融合是两个重要的研究方向[29-30].一个好的特征表示应该捕捉丰富的情感线索,这些线索可以概括不同的说话者、背景和语义内容等.一个良好的融合机制应该能够有效地整合各个模态数据.
3.1 多模态情感识别特征表示
为了帮助理解多模态情感特征表示的任务,本文列出了两种常用的多模态表示学习策略:联合表示和协同表示.联合表示将单模态信号整合到同一个表示空间中称为联合嵌入空间,而协同表示分别处理单模态信号,但会对它们施加某些相似性约束.
联合表示法将单模态表示投影到多模态联合表示中.联合表示的最简单的例子是单个模态特征的拼接(也称为早期融合[35]).在本文中我们主要讨论使用神经网络创建联合表示的方法如表2,神经网络已经成为一种非常流行的单模态特征表示方法,它们被用来表示文本、视觉和听觉数据,并越来越多地用于多模态情感识别领域.为了使用神经网络构建多模态表示,每个模态都从几个单独的神经层开始,然后使用一个隐藏层将多种模态投影到联合空间中.Mai等人[36]提出了一种新的对抗性编码器-解码器-分类器框架来学习模态不变性的联合嵌入空间.由于各种模态的分布性质不同,为了减少模态差距,利用对抗性训练,通过各自的编码器将源模态的分布转化为目标模态的分布.此外,通过引入重构损失和分类损失对嵌入空间施加额外的约束.在多模态情感识别中我们经常需要表示长度不等的序列,如句子和音频.循环神经网络(RNN)及其变体,如长短期记忆(LSTM)网络,因其成功地对各种任务进行序列建模受到了广泛关注.RNN表示的使用并不局限于单模态,使用RNN构造多模态情感识别表示的早期用法来自于Chen等人[43].基于神经网络的联合表示的主要优势在于,当标记数据不足以用于监督学习时,它们能够对无标记数据进行预训练.Zhao等人[44]提出了一个用于多模态情绪识别的预训练模型MEmoBERT,该模型通过自监督学习从大量的未标记视频数据中学习多模态联合表示.

表2 多模态情感识别表示技术综述Table 2 Asummary of multimodal emotion recognition representation techniques
协同表示不是把模态一起投影到联合空间,而是学习每个模态的单独表示,但通过一个约束来协调.协同表示主要分为相似性和结构化协调空间模型.相似性模型最小化了协同空间中模态之间的距离.Weston等人[46]的研究是此类表示学习的最早例子之一.最近,由于神经网络具有学习特征表示的能力,它已经成为一种构造协同表示的流行方式.它们的优势在于可以通过端到端方式共同学习协同表示.Fu等人[47]使用增强稀疏局部判别典型相关分析方法来学习多模态共享特征表示,利用En-SLDCCA方法得到视频和音频的相关系数,然后利用相关系数形成融合视频和音频特征的共享特征表示.结构化的协同表示模型在模态表示之间加强了额外的约束.例如,典型相关分析(CCA)[48]方法计算线性投影,最大化两个随机变量之间的相关性,并加强新空间的正交关系.Zhang等人[49]将深度典型相关分析(DCCA)引入到多模态情绪识别中.DCCA的基本思想是将每个模态分别变换,并通过指定的典型相关分析约束将不同模态协调到一个多维空间.
3.2 多模态情感识别特征融合
对来自多种模态的信息进行融合是多模态任务的一个重要步骤.然而,多模态数据在本质上是高度异构的,所以融合是一项具有挑战性的任务.多模态情感融合主要有特征级融合、决策级融合、模型级融合[37]三种策略.如图2所示,特征级融合最为直观,通过串接等方式对不同模态的特征进行融合.由于融合特征包含更多的情感信息,可以明显提高情感识别性能.Zadeh等人[38]提出了一种张量融合网络(TFN)利用多模态特征的乘积来融合多模态信息.但这样会极大增加特征的维度,使模型过大难以训练.与张量网络不同的是Liu等人[39]采用了低秩多模态融合方法,利用低秩张量提高了融合效率,该方法不仅减少了参数,而且提高了情感识别性能.Zeng等人[40]提出了一种新颖的、数据驱动的乘法融合技术来融合多模态,在训练过程中它会对模态进行检测,过滤掉无效的情感特征,这样就学习了更可靠的情感线索.
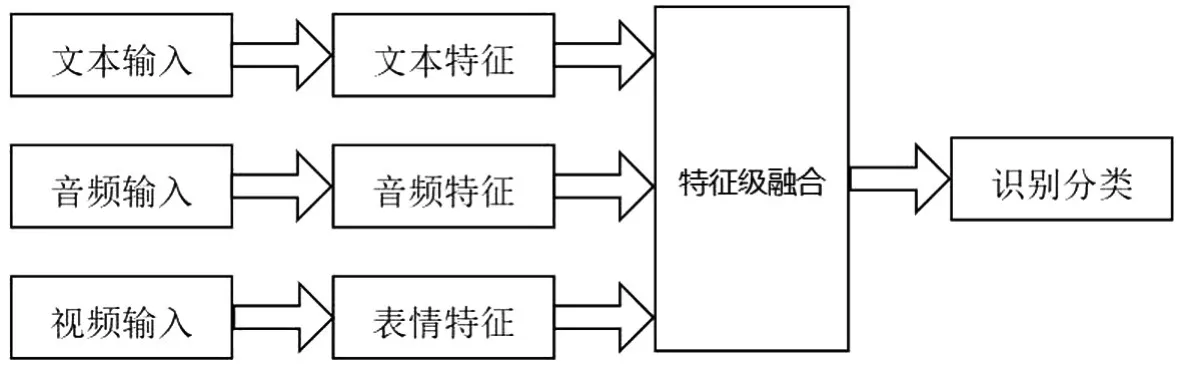
图2 特征级融合Fig.2 Feature level fusion
决策级融合将各模态的特征进行独立的提取和分类,得到局部决策结果之后,再融合各个决策结果为决策向量以获得最终决策,如图3所示.相比特征级融合,决策级融合更简单自由,因为每种模态的决策结果通常是具有相同意义的数据.此外,每种模态可以自由选择合适的特征提取器和分类器,产生更优的局部决策结果.Zadeh[5]等人提出了一种动态融合图(DFG)技术来融合多模态.DFG可以学习n-模态之间的相互作用和有效参数数目(不同于TFN具有大量参数).它还可以根据n-模态动力学的重要性动态改变其结构和选择融合图.DFG具有高度可解释性,与目前的技术水平相比,具有较强竞争力.
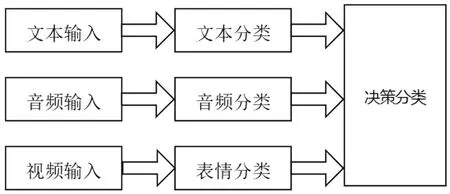
图3 决策级融合Fig.3 Decision level fusion
与特征级融合和决策级融合相比,如图4所示,模型级融合可以更好学习模型内部的多模态交互,更好地发挥了深度神经网络的优势.随着注意力机制(Attention)的普及,它在多模态融合中发挥着重要的作用.Chen等人[41]提出了条件注意力融合模型,采用长短期记忆循环神经网络(LSTM-RNN)作为基本的单模态模型来捕获长时间依赖.分配给不同模态的权重是由当前输入特征和最近的历史信息自动决定的,通过在每个时间步上动态地关注不同的模态,对传统的融合策略进行了改进.最近提出了一种更有效的Transformer模型.它以较长的时间跨度来模拟长期的时间依赖,更适合于模拟情感的时间过程.Huang等人[42]利用Transformer模型学习语音和视频两个模态之间的语义关联,实现模型级融合,进行连续的情感识别.
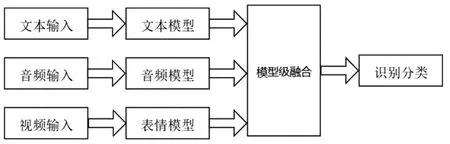
图4 模型级融合Fig.4 Model level fusion
4 展望
多模态情感识别目前还有很多问题有待研究,如怎么融合新模态的信息来提高情感识别的准确率、多模态特征对齐,如何结合多个模型的优点来提高情感识别率等.其中,我们认为新模态的引入和多模态融合是未来的重点发展方向.
4.1 新模态的引入
除了文本、语音和视频等常用模态外,可以考虑引入姿态和生理信号等新模态.在很多大的场景中(如商场、火车站等公共场所),用户的面部表情、语音等属于微观情感,这些信息通过近距离才能采集到.而动作姿态也是用户表达情感的重要方式,目前尚未得到充分的利用.而且,对于听障人士、面部表情障碍人群等,相较于语音和面部表情,他们表达感情的方式更依赖于动作姿态.用户的动作姿态空间尺度大、数据容易采集、不同情感之间数据变化明显.因此,通过姿态所表达的情感也是抑郁症和自杀行为检测以及暴力倾检测的重要指标.
另外当人处于某一情感状态时,身体会发生一系列的生理反应,脑电、心电、肌电等信号是我们常用的生理信号.在某些情况下人们刻意掩盖自己的情绪,或者患有面神经炎的人无法表达表情,就无法准确预测他们的情感.随着脑机接口等领域的研究发展,许多研究者提出了基于生理信号的情感识别方法.在未来生理信号和面部表情、语音、姿态等特征相结合的多模态情感识别技术会成为新的发展趋势.
4.2 多模态情感融合问题
多模态情感融合一直是一个被广泛研究的课题,研究者们提出了大量的方法来解决它,每种方法都有自己的优缺点.近年来,神经网络已成为处理多模态融合的一种非常流行的方法.然而多模态融合仍然面临以下挑战:(i)各个模态数据可能不是时间对齐的;(ii)难以建立利用互补信息提高情感识别性能;(iii)每个模态在不同的时间点可能表现出不同类型和不同程度的噪声.在未来多模态情感融合方法还需要大量创新来提高情感识别准确率.
4.3 如何提高模型的泛化能力
虽然在多模态情感识别领域提出了很多优越的模型,但它们通常是在特定的数据集上训练的,模型训练依赖于不现实的数据,如强制对齐的多模态序列,无错误的文本转录,人工的对话语境等,缺乏泛化能力,很难适应工业应用.因此,在实践中,需要设计更稳健的模型.未来的工作应该包含以下几个方面:(i)采用跨数据集的评估方式进行训练,同时利用无监督或有监督领域适应方法的能力,以便更好地评估其泛化能力;(ii)能够对非对齐的多模态数据进行推断;(iii)在有噪声或缺失模态的情况下能够进行推断.
4.4 预训练表示学习
在多模态情感识别的文献中还缺少一个概念,即无监督地表示学习.在其他机器学习应用领域中,也有很多功能强大的无监督表示学习方法,如针对文本的BERT[13],针对音频的wav2vec[33],以及针对视觉的MoCo[50],这些方法都是独立于应用的.已经为多模态情感识别任务创建了几个定义良好的数据集,结合它们以生成通用的多模态情感特征表示的研究可能有助于提高情感识别的准确率.
