基于自注意力深度哈希的海量指纹索引方法
2022-09-21吴元春
吴元春,赵 彤
1.中国科学院大学 计算机科学与技术学院,北京100049
2.中国科学院大学 数学科学学院,北京100049
3.中国科学院大数据挖掘和知识管理重点实验室,北京100190
在生物特征识别领域,指纹作为最具独特性与持久性的特征之一,被广泛应用于身份认证[1]。随着越来越多的用户注册到指纹识别系统,指纹库的规模也呈现出爆炸式增长。在这种基数巨大的指纹库中,较短的响应时间内完成检索任务成为一个极具挑战性的任务。
目前针对大规模指纹库中的指纹检索,主流做法分为两阶段:粗筛选阶段与精匹配阶段。第一阶段快速粗筛,缩小检索范围得到小候选集,第二阶段在候选集上选取某种精确度更高的方法进行精细匹配得到检索结果。完成第一步通常需要选择合适的预选技术。预选技术主要可以分为两类:独有分类(exclusive classification)和索引[2]。指纹的独有分类包括五大类[3-4]:左旋、右旋、斗、拱、支拱,但是根据统计93.4%的指纹属于左旋、右旋、斗这三类[5]。过少的类别以及类别上极度不均匀分布导致这类方法很难有效缩减检索范围,而基于指纹索引的方法能有效解决这个问题。基于索引的方法使用特征向量而非离散类别来代表一枚指纹。目前基于索引的方法包括:基于纹理、基于细节点、基于MCC、基于深度学习的方法。尽管这些方法利用到不同层次的指纹特征,但是它们的共同点是获取实数值的指纹特征向量,这也带来了如下问题:
(1)在大规模的指纹库中,实数值特征向量在存储与运算上都会耗费巨大资源。通过这种方式完成检索任务无法实时响应,需要漫长的等待。
(2)这些方法很容易受指纹质量的影响,例如噪声、失真、手指状况以及指纹采集设备等。当指纹质量较低的时候得到的特征向量不可靠,会严重影响检索系统的准确率。
目前基于深度哈希的方法能有效解决这些问题。深度哈希的主要思想是借助深度神经网络模型将数据从原始空间映射到汉明空间得到二进制表示,同时保留原始空间的语义相似性。得益于二进制编码按位存储与异或运算的特性,这类方法具有运算高效与存储低耗的巨大优势。以64 位编码为例,假设对指纹图像分别生成64 维二进制特征向量与64 维实数值特征向量,计算两张指纹图像的相似度时,64维二进制特征按位存储仅仅需要16 Byte的临时存储空间,并仅需1次异或运算得到汉明距离,而64维实数值特征则需要512 Byte的临时存储空间,并进行128次加法运算与64次乘法运算得到欧式距离。因此二进制编码在运算速度与存储效率上都远优于实数值编码,当执行大规模的检索任务时,能大幅度减少检索粗筛阶段所需时间,提高响应实时性。
但是指纹图像是一类特殊的图像,它具有高度的自相似性,即不同指纹之间差异细微,只能通过细节特征来区分,而现有的深度哈希相关研究大多基于自然图像,直接迁移应用到指纹检索领域效果往往不尽人意。为了能有效学习这种细微特征,本文借助了自注意力模型。自注意力模型最初被广泛应用于自然语言处理(NLP)领域,其中以Transformer[6]结构最为出名。Transformer 结构利用了自注意力机制,取代了传统的CNN与RNN网络结构并取得了SOTA结果。近几年来,计算机视觉相关领域研究逐渐开始把目光投向Transformer并将其改善应用于CV 领域[7-9],受文献[9]的启发,将Transformer 结构嫁接到深度哈希模型中取代传统卷积模块,得到一种自注意力深度哈希模型,并命名为FHANet。
FHANet主要由三个模块构成,自动对齐模块、预处理模块、自注意力哈希模块。
在指纹图像匹配过程中,对齐是至关重要的一个环节。传统的指纹匹配系统中大多是基于参考点(例如core 点)完成对齐,这类方法往往速度较慢且对指纹质量有着较高要求,而FHANet中的自动对齐模块借鉴了文献[10]中提出的空间变换网络结构,依靠卷积神经网络自动学习一个仿射变换矩阵来完成同类指纹的对准达到自动对齐的效果,较之传统方法,其优势在于能轻易利用GPU 进行加速,在实际工业生产应用中意义重大。此外,本文设计了一个STN-AE的网络结构来辅助训练自动对齐模块。现有的一些研究如文献[11]也利用到空间变换网络完成指纹对齐,但该研究中将对齐模块集成到端到端的卷积神经网络中,依赖下游学习任务更新空间变换网络,这样不仅引入了额外的超参数,增加了原有任务的训练难度,而且没有明确空间变换网络的学习目标,大大降低了对齐任务的可解释性。STN-AE的结构是由一个空间变换网络(STN)后接一个浅层卷积自编码器(AE)组成,由浅层自编码器作为空间变换网络的下游网络,然后对同类指纹的隐藏层特征向量余弦距离及自编码器的重构误差加以约束达到对齐效果。通常来说,卷积神经网络的层数越深,所抽象出来的特征越高级。深层卷积神经网络往往提取出全局的高层特征,而浅层的卷积神经网络更多地提取局部的低层特征,如图像纹理、姿态等相关特征。所以在本研究中,使用浅层卷积自编码器使得编码器所提取的隐向量包含更多姿态纹理信息,从而在训练过程中,约束同类指纹隐藏层特征向量余弦距离小间接地限制了同类指纹姿态相近,即使得空间变换网络具备了对齐指纹的能力。STN-AE网络整体参数少、轻量级、易于训练,优化目标与对齐任务关联更加紧密,使得空间变换网络学习目标的可解释性更强。
指纹预处理模块利用了现有的领域知识,将对齐后的指纹图像处理得到二值骨架图作为后续模块的输入,此过程中消除了背景噪声与按压力度等干扰因素的影响,大大降低了后续自注意力哈希模块的训练难度,提高了编码质量。
自注意力哈希模块则是利用Transformer 结构,对指纹二值骨架图进行特征提取,然后对特征向量进行哈希映射,得到二进制编码。传统的卷积结构具有平移不变性与局部敏感性,但缺少对于图像的宏观感知,它擅长提取局部特征而无法提取全局数据之间的长距离特征。通常为了使卷积神经网络提取跟踪长距离相关特征,模型需要加大卷积核尺寸同时加深网络层数来增大感受野。但是这样往往会让模型复杂度急剧上升,给模型的训练与使用带来诸多负面影响。本文使用Transformer结构,将原始图像进行均匀分块并进行展开和线性转换得到序列数据作为输入。Transformer 结构中将输入序列中的每个特征项都映射到三个空间:查询(query)空间、键(key)空间、值(value)空间。通过计算每一特征项的query向量与其他所有项的key向量之间的内积得到一个权重向量来度量特征项之间的关联度,然后将权重向量与所有value向量相乘并加和得到对应位置的新输出。在这个过程中,每个输入特征项的对应输出中既包含自身信息,也包含其他所有特征项的信息,即包含了全局信息。具体到本文中所用的指纹数据来说,每个输入的指纹图像子块通过Transformer 结构处理,既提取到了自身的局部信息(如细节点信息),又包含了一部分全局信息(如方向场信息),这样得到的信息更加全面,最终提取到的特征也更具区分力。
简而言之,本文的贡献可以总结为如下几点:
(1)首次将深度哈希模型应用到指纹检索领域,并引入自注意力机制中的Transformer结构替代传统的卷积结构,设计了更契合指纹图像的深度哈希网络,从而得到更高效的二进制编码,大大提升了海量指纹库中的检索效率。
(2)设计了STN-AE 网络,借助浅层自编码器来辅助训练得到指纹自动对齐网络,克服了端到端集成训练中空间变换网络难以调参优化的问题,同时也消除了对齐过程中对于参考点的依赖,在工业生产中更容易进行并行加速,更加贴近大规模指纹检索场景需求。
(3)首次提出使用指纹二值骨架图代替指纹原图用于神经网络特征提取,消除了指纹背景噪声及采集过程的不确定因素带来的干扰,大大降低了自注意力深度哈希网络的特征提取难度,加速了训练收敛过程。
1 自注意力深度哈希模型
首先简单地对FHANet 的结构与原理进行概述;然后介绍自动对齐模块的机理与实现细节;接着分析预处理模块的作用与可行性;最后详细介绍自注意力哈希模块的结构与优化目标。
1.1 模型概述
图1 描述了FHANet 的基本框架。在本研究中,使用了一个100 000 规模的指纹数据库来进行模型训练,其中采集自同一枚手指的重复按压指纹属于同一类,整个指纹库采集自20 000 枚手指,每枚手指5 枚重复按压。FHANet 的主要任务是学习指纹图像的二进制编码,确保同类指纹汉明距离足够小,异类指纹汉明距离足够大。

图1 FHANet流程图Fig.1 Flow diagram of FHANet
FHANet主要由三个模块组成:自动对齐模块、预处理模块、自注意力深度哈希模块。模型的输入为320×320的指纹灰度图像If。If首先被传入自动对齐模块,进行姿态上的调整。经过此模块以后,同类指纹被调整到相近的姿态达到对齐的效果。然后对齐后的指纹被传入预处理模块得到二值骨架图。最后二值骨架图传入自注意力哈希模块得到二进制编码用于索引。接下来将详细介绍各个模块。
1.2 自动对齐模块
指纹对齐在几乎所有现存的指纹识别系统中都是必不可少的,传统的方法往往基于参考点(如core点)完成对齐。尽管这类方法在实际应用中表现优异,但往往需要耗费大量算力,不适用于大规模检索场景。受到文献[11]的启发,采用自动对齐模块来解决这个问题。FHANet中的自动对齐模块本质上是一个预先训练好的STN(空间变换网络)。STN 由两部分组成:localization network 和gird sampler。图像输入到STN 中,由localization network 估计出一个仿射变换矩阵Aθ,然后由grid sampler完成逐点位置变换:

(1)STN 随下游任务(如分类任务)进行迭代更新,并没有自己独立的目标函数,其优化目标的可解释性与优化方向的可控性都大大降低。
(2)STN 集成到端到端的网络中,将引入额外超参数,大大增加训练难度。
因此,在本研究中,提出了一种全新的名为STN-AE的结构来训练STN。在此结构中,由浅层自编码器来辅助STN的训练。STN-AE中,浅层自编码器由一个三层的卷积神经网络构成,之所以选取浅层卷积自编码器是因为这样的结构能提取到对指纹像素位置及姿态更敏感的低层特征,从而得到富含指纹纹理及姿态信息的隐向量,同时这种简单结构也更加易于训练。STN-AE的结构如图2所示。

图2 STN-AE流程图Fig.2 Flow diagram of STN-AE

在该目标函数中,有两个约束:
(1)同类指纹隐向量的余弦距离要足够小。
(2)自编码器的重建误差要足够小。
其中,第一个约束得到满足则会间接约束自编码器输入指纹图像具有相近的姿态,即让STN具备对齐指纹的能力。第二个约束则是确保足够多的原始图像信息被编码到隐向量中,避免自编码器学习到平凡解。只有在这个前提得到满足的条件下,第一个约束才是有效的。
在训练阶段,参考了文献[11]的做法,将STN 估计的仿射变换矩阵平移和旋转参数的上界设为±100像素和±45°,这些限制是基于用户手指放置在指纹采集器上时旋转或平移的最大范围的实际领域知识。除此之外,还在这些约束条件下进行了随机旋转和平移来扩充训练数据。表1 显示了STN-AE 的具体结构组成,图3 显示了对齐模块之前和之后的图像。

图3 指纹对齐前后对比Fig.3 Comparison of unaligned fingerprint images with aligned ones

表1 STN-AE架构Table 1 STN-AE architecture
1.3 预处理模块
大部分现有的基于深度学习的模型多是使用端到端的网络架构,即纯粹利用神经网络完成特征提取。但是对指纹图像来说,领域知识在许多应用场景中都是至关重要的。
在本文中,提出依据现有领域知识来对指纹进行预处理后再送入网络中进行特征提取。整个预处理过程包括二值化与细化。图4 中展示了几个预处理效果的示例。通过完成这种转换,许多干扰因素,如背景噪声、指纹采集设备差异等都将被消除。尽管这样会导致部分的信息丢失,但大多传统的指纹识别算法[1]都是在二值骨架图的基础上进行细节点提取完成匹配,因此二值骨架图中保留的信息完全足够区分不同指纹。在本文的实验中,预处理模块降低了自注意力哈希模块的学习难度,实际训练过程中缺乏预处理模块甚至导致自注意力哈希模型无法收敛。

图4 指纹原图与骨架图对比Fig.4 Comparison of row fingerprint images with binary skeleton images
1.4 自注意力哈希模块
1.4.1 模型原理及优化目标
自注意力哈希模块是FHANet 的核心模块。具体结构组成如表2 所列出。假设I表示图像的原始特征空间,K表示二进制编码的长度,自注意力哈希模块本质是学习一个映射:F:I→{0,1}K,同时又要保留原始空间的相似性,即原始空间距离小的图像,映射到汉明空间后,汉明距离也要小,反之亦然。整个模块由特征提取与哈希映射两个子模块构成。其中特征提取模块的结构如图5所示。

表2 自注意力哈希模块架构Table 2 Self-attention hash module architecture

图5 特征提取子模块流程图Fig.5 Flow diagram of feature extraction submodule
标准Transformer的输入为1维序列数据,为了将输入图像转换为对应格式,自注意力哈希模块首先将输入的指纹骨架图S∈RH×W×1分割为固定大小的图像块并展开得到一维向量序列Sp∈,其中H与W为输入图像分辨率(本文H与W均为320),P为图像块分辨率(本文P为80),N为图像块个数(本文N为16)。然后将Sp进行线性映射并在头部连接一个可学习的“class”嵌入向量Xclass∈RD得到块嵌入向量序列Ex∈然后加上对应的位置嵌入向量Epos∈得到M层Transformer编码器的最底层输入Z0:
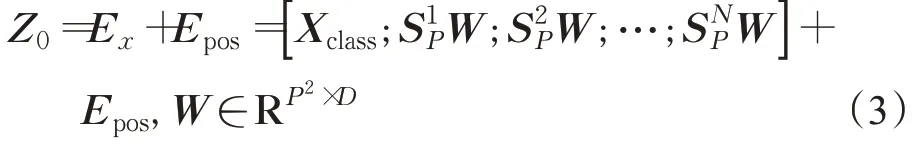
在多层Transformer编码器中,其第i层中的多头自注意力模块输出为:

第i层中多层感知机输出为:

其中,MSA表示多头自注意力(multi-head self-attention)模块,MLP 表示多层感知机(multi-layer perceptron)模块,LN表示Layernorm。
Xclass向量在Transformer编码器最后一层对应输出为,用于生成特征向量y:

哈希映射模块本质结构为一个两层的线性映射外接一个符号函数。特征向量y通过哈希模块得到二进制编码b∈{-1,1}K:

其中,H(⋅ )表示哈希映射模块中的多层线性映射,sgn(⋅)代表符号函数。为了方便数学运算,在训练阶段使用-1 代替编码中的0。

从上式中可知,二进制编码的汉明距离与内积成反比,因此可以用内积来量化二进制编码相似度。在本文中,参考了文献[12],成对相似性标签Sij的似然概率有如下定义:
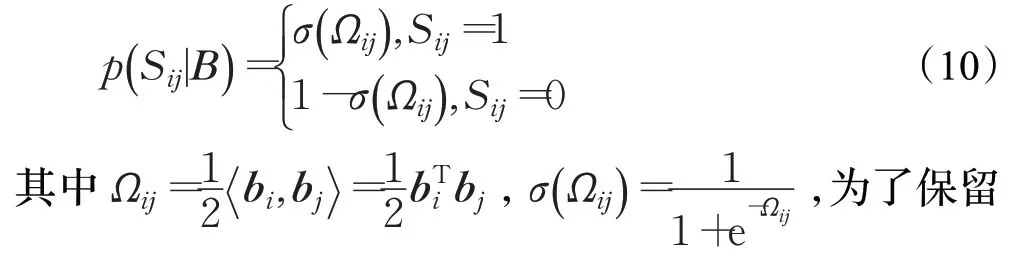

其中zi∈RK作为bi的连续松弛,1 ∈{ 1}K为全1 向量,Θij=之所以进行连续松弛是因为直接优化离散的二进制编码是一个NP-hard 问题[13],因此在训练阶段对编码进行连续松弛,在测试阶段使用符号函数得到二进制离散编码。在该优化目标中,L1项本质上是一个最大后验估计(MAP),具体推导过程可参考文献[14]。其主要目的是在得到编码B的条件下,最大化相似度信息S的概率从而使得编码成对相似性被最大化保留。这样得到的编码充分学习到类别监督信息,具有高度区分性。L2项表示量化误差,该项是为了约束二进制编码b与其连续松弛z之间距离尽可能小,使训练过程模型输出尽可能贴近真实二进制编码,增强模型泛化能力。
1.4.2 超参数设置
量化罚项超参数λ作为损失函数中最大后验估计误差与二值码量化误差之间的平衡因子,其选择至关重要。λ取值过小,则L1项处于主导地位,导致量化误差过大,实数编码二值化后泛化能力差;λ取值过大,则L2项处于主导地位,导致编码不能充分学习到类别相似度信息,编码缺乏区分力。本文中通过交叉验证加网格搜索的方式来进行量化罚项超参数的选择,整个搜索过程由粗粒度搜索与细粒度搜索两个阶段组成。首先在10-5到102之间进行粗粒度网格搜索,从10-5开始,逐次乘10,每次在训练数据上进行10-folds 交叉验证,在此轮搜索过程中得到一个λ的最优取值,本文得到结果为0.01。然后在首轮最优取值附近取一个区间,进行细粒度网格搜索,本文中取区间[]0.005,0.015,每次递增0.001 并进行10-folds 交叉验证,最终得到最优取值为0.01。因此经过两轮网格搜索与交叉验证,最终确定了量化罚项超参数λ取值为0.01。
1.4.3 复杂度分析
在自注意力深度哈希模块中,主要计算复杂度集中在Transformer中的多头自注意力子模块上。假设对指纹图像分块数为N,Transformer 编码器输出特征维度为d,Transformer 编码器的层数为L。每层中计算query空间与key空间的相似度得到权重矩阵,本质上即N×d的矩阵与d×N的矩阵相乘,得到N×N的矩阵W1,时间复杂度为O(N2d)。然后对W1每行做softmax,复杂度为O(N2),得到归一化权重矩阵W2。最后依据得到的权重矩阵W2在value空间计算加权和,本质上为N×N的矩阵与N×d的矩阵相乘,时间复杂度为O(N2d)。故综上所述每层Transformer的时间复杂度为O(N2d),对于L层Transformer,其时间复杂度为O(LN2d)。故自注意力深度哈希模块的计算复杂度为O(LN2d)。
2 实验
将通过实验来评估本文的模型性能,并与其他现有方法进行比较。下面详细介绍实验过程和结果。
2.1 数据集
在FVC2000[15]、FVC2002[16]、FVC2004[17]、NIST DB4[18]、NIST DB14[19]等公开数据集上进行了实验。数据集的详细信息如表3所示,其中包括尺寸、重复采集数、个体数等。此外,训练过程中使用一个10万规模的320×320的指纹数据库进行训练,该数据集采集自20 000枚不同手指。

表3 公开数据集详细信息Table 3 Detailed information of pubic datasets
2.2 评估尺度
在本文实验中,使用了穿透率(penetration rate,PR)与错误率(error rate,ER)两种指标来评估指纹索引算法的表现。假设N、X、T、ni分别代表识别过程中进行的查询次数、指纹库中图像的总数、正确识别的查询样本的数量,以及第i次查询。则以上两种指标有如下定义:

穿透率与错误率分别代表着指纹索引的效率与准确率。通常来说,一个优秀的指纹检索系统需要同时保证较低的穿透率与错误率,但通常这两个指标是此消彼长的关系。因此在本文中,采用“穿透率-错误率”(PR-ER)曲线来评估本文的模型。此外,为了比较FHANet与实际商用软件的速度差异,平均检索时间也被用来评估模型的效率。
2.3 指纹索引实验
在本节,评估了FHANet 在公开数据集上进行索引任务的表现,并与现有的基于二进制编码的索引方法进行了对比,包括MCC-LSH[20]、PMCC-MIH[21]、CBMCCMIH[22]。实验中分别实现了32 bit、64 bit 以及128 bit 版本的FHANet并与384 bit的MCC-LSH、64 bit CBMCCMIH、128 bit CBMCC-MIH 进行了对比。公共数据集上的图像将进行一些合适的裁剪与放缩来满足FHANet的输入尺寸要求。详细的实验结果如下文所示。
图6~9展示了在FVC2000、FVC2002、FVC2004、NIST DB4和NIST DB14上的PR-ER曲线。在FVC系列的数据集上,选择第一张指纹作为查询指纹,剩下七张指纹作为目标指纹。类似地,在NIST系列的数据集上,选取第一张指纹作为查询指纹,剩余的一张作为目标指纹。通过观察这些PR-ER 曲线可以发现,FHANet(128)的PR-ER曲线在所有对比实验中都处于最低位置,即效率与准确率都超过其他模型,相反FHANet(32)在所有 实验中都基本得到最差的表现。当编码长度从32位增加到64 位的时候,FHANet 的表现得到大幅度提升,当编码长度64 位增加到128 位的时候,FHANet 的性能依然提升,但提升幅度大大降低。根据这些结果可以得出结论:在选取合适的编码长度的前提下,FHANet有能力远超过现有的基于二进制编码的索引方法,这证明了自注意力深度哈希模型的有效性与可行性。另一方面,编码越长通常包含的信息也越多,但实验结果显示编码长度与索引表现并非线性相关的。推测当编码长度达到某个阈值,即编码能包含足够的指纹关键信息时,继续增加编码长度会导致编码中会包含大量冗余信息,对模型的性能提升十分微弱。这也指导在实际应用哈希模型中并非盲目选择长编码提高性能,选择合适编码长度才能发挥模型最优性能。
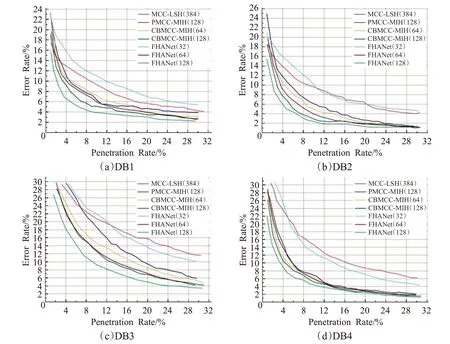
图6 FVC2000上各算法索引表现对比Fig.6 Indexing performance of different algorithms on FVC2000
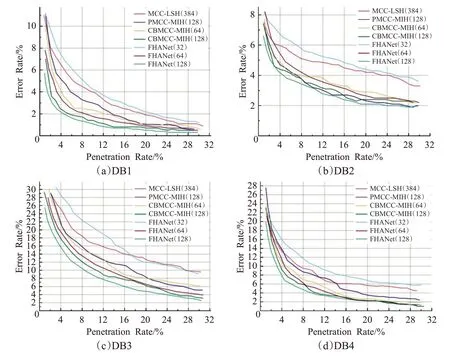
图7 FVC2002上各算法索引表现对比Fig.7 Indexing performance of different algorithms on FVC2002
为了说明Transformer 结构相对于传统卷积结构的优势,本文中设计了对比实验,分别使用本文中的6 层Transformer 编码器网络与Inception-v4[23]网络作为特征提取网络进行模型训练并对比索引性能。其中Inception-v4 网络曾在ImageNet 竞赛上取得了3.08%的top5错误率,其基础网络组件Inception模块基于多尺度卷积结构。因此用这种结构与本文Transformer编码器结构进行对比更能说明在指纹数据上Transformer结构相对于传统卷积结构的优势。本文在两个最大的公开指纹数据集NIST DB4 与NIST DB14 对两种模型分别进行了64 bit 与128 bit 编码进行了索引实验,实验结果如图10 所示。由结果可知,在同样编码长度的情况下,FHANet的PR-ER曲线总远低于Inception-v4,这说明了针对指纹数据,FHANet中的Transformer结构比传统卷积结构更胜一筹。
此外,为了展示FHANet 在时间与存储效率上的优势,在NIST DB14上进行了检索时间测试。NIST DB14是规模最大的公开指纹库。在这个实验中,实现了FHANet的128 bit版本并选取了东方金指公司提供的商用指纹软件作为对比,这套商用系统已经被广泛应用在公安部指纹系统中,因此其性能是成熟可靠且具备行业竞争力的。基于FHANet的检索实验中,在粗筛阶段使用了FHANet生成的二进制编码,然后在精匹配阶段使用了金指公司的指纹软件,对比实验中完全使用金指公司指纹软件,这样以有无FHANet参与作为唯一变量来探究FHANet对检索效率的影响。为了保证公平性,所有实验都在同一台配备了Intel Core i7-9700K CPU@ 3.60 GHz 的机器上进行且不加额外的优化策略(例如多线程、并行计算)。在测试中首先选取第一枚指纹作为查询,第二枚指纹作为目标,然后反过来重复此过程,计算平均检索时间与平均临时存储消耗。表4展示了实验结果,可以看出FHANet模型生成的二进制编码能大幅提升检索速度,其平均检索时间远低于东方金指公司所提供的商业软件,并消耗更少的存储空间,在大规模指纹检索应用中前景辽阔。

图8 FVC2004上各算法索引表现对比Fig.8 Indexing performance of different algorithms on FVC2004

图9 NIST上各算法索引表现对比Fig.9 Indexing performance of different algorithms on NIST

表4 FHANet与商用软件检索对比结果Table 4 Retrieval comparison results of FHANet and commercial software

图10 NIST上FHANet与Inception-v4索引表现对比Fig.10 Indexing performance of FHANet and Inception-v4 on NIST
3 结论
在本文中,提出了一种全新的指纹索引方法FHANet,它能够生成具备高度区分力的二进制指纹编码来进行索引。整个模型包括三个部分:自动对齐模块、预处理模块和自注意力哈希模块。首先,介绍了对齐模块的机理,并介绍了如何利用所提出的STN-AE网络对其进行训练。然后,分析了预处理模块的优点及其可行性。最后,介绍了自注意力哈希的结构以及其学习二进制编码的机理,并与之前的几种基于二进制编码的方法进行了对比实验。实验中以穿透率、错误率和平均搜索时间等指标来评价本文的方法,大量的实验表明本文所提出的方法在指纹索引方面具有良好的性能,在大规模指纹检索场景具备广阔的应用前景。
