语义及句法特征多注意力交互的医疗自动问答
2022-09-21张华丽康晓东李小军刘汉卿王笑天
张华丽,康晓东,李小军,2,刘汉卿,王笑天
1.天津医科大学 医学影像学院,天津300203
2.重庆市黔江中心医院,重庆409099
自动问答(question answering)是人工智能领域中重要的研究方向,其核心是利用计算机对用户提出的问题进行自动解析,并从答案候选集中检索出目标答案[1]。近年来,随着医疗信息化的飞快发展,越来越多的人通过互联网来寻找医疗帮助,导致在线医疗自动问答论坛十分活跃。现阶段,人们提出的健康咨询问题日益剧增,需要消耗大量的医疗资源。而医生的资源有限,很难及时回答所有问题。因此,如何通过分析现有的海量中文医疗问答数据构建快速、准确的自动问答系统是一个亟需解决的任务。构建完整的中文医疗自动问答系统不仅可以缓解医生资源有限的现状,也可以减少医生的工作量,避免重复工作。
目前,医疗自动问答领域的研究主要分为传统方法和深度学习方法两类。传统方法主要利用关键词匹配的机制,其包括人工规则方法[2]、信息检索[3]以及机器学习的传统模型[4]等。传统方法很大程度上依赖于大量的人工特征,需要耗费大量的人力且泛化能力弱,并在匹配正确答案的精度上也存在不足。随着深度学习不断融入到自然语言处理领域,研究者们尝试将深度学习算法应用到自动问答任务上,并取得优异效果。深度学习方法旨在通过文本表示、特征提取以及判断问答对之间的语义相似度等一系列操作,实现精准回答用户所提出的问题。Feng 等人[5]利用卷积神经网络(convolutional neural networks,CNN)提取问题和答案的局部特征,再通过计算余弦相似度判断问答对的匹配程度。由于长短时记忆网络具有捕捉长距离依赖的语义信息的能力,Tan等人[6]采用双向长短时记忆网络(bi-directional long short-term memory,BiLSTM),从句子整体上编码问题和答案的语义信息。Zhang 等人[7]在字向量的基础上,构建多尺度卷积神经网络(multi-scale convolutional neural networks,Multi-CNN),通过不同的卷积核从字、词和短语等不同尺度深度挖掘问答对的语义特征。考虑到句子的局部特征和全局特征对语义理解均有意义,Zhang 等人[8]提出BiGRU-CNN 联合网络模型,先利用BiGRU(bi-directional gated recurrent unit)获取句子的整体序列信息,再传入多尺度CNN 模型有效捕获句子的局部特征信息,利用两种不同的网络模型学习不同角度的语义信息。随后,有研究者把注意力机制和神经网络模型结合起来处理自动问答任务。邵曦等人[9]提出结合BiLSTM 和注意力模型的问答系统,具有良好的性能。Zhang 等人[10]在BiGRU-CNN 组合网络的基础上,添加注意力机制,将更多的注意力权重分配到问答对的关联信息上,并实现问答对的信息交互。Cui 等人[11]提出孪生BERT 网络,设计了Crossed BERT 模型,提取问答对深度的语义信息以及充分理解问答对之间的语义相关性,再融合Multi-CNN 或BiGRU 模型学习更丰富的语义信息,实验结果表明该方法在中文医疗自动问答领域上表现出最优性能。
中文医疗问答句表达方式灵活多样、句法语法复杂多变,文本中包含丰富的序列信息和句法语法信息,需要从不同维度和角度上全面分析句子复杂的内部语义信息。因此,在中文医疗领域的自动问答任务上,也面临着挑战。鉴于不同网络结构挖掘不同角度的语义信息,Tai 等人[12]将LSTM 模型拓展为Tree-LSTM 网络,在预测句子对的语义相关性和情感分类任务上,Tree-LSTM要优于LSTM。由此可见,树结构化LSTM 不仅具有良好的表示序列信息的能力,也拥有揭示句子语法结构的优势,实现从不同角度上捕获文本信息。Zhang等人[13-15]提出把图卷积神经网络(graph convolutional network,GCN)引入到中文实体关系联合抽取任务上,先通过双向长短时记忆网络编码句子的序列特征,再利用图卷积神经网络捕捉句子中蕴含的句法信息,兼顾了句子的序列信息和复杂的语法关系,提高模型实体关系抽取的准确率。比如,对“我没有感冒、发烧等不适症状,但是心慌、难受,我该怎么办?”文本序列进行语义表征,如果只依赖于BiLSTM模型,由于其对“没有”这种否定词的语义表征不敏感,文本理解上会有偏差,不利于下游任务。引入GCN模型提取句法信息,与GRU模型获取的特征信息表现出互补关系,因此,在一定程度上学习较完整的文本信息。
根据上述分析,本文提出融合语义及句法特征的多注意力交互的自动问答方法。也就是,本文在BERT模型的基础上,分别利用BiGRU 和GCN 进一步编码句子的语义特征和句法结构。通过引入GCN模型捕获单独从BiGRU 模型无法学习到的句法关系,与BiGRU 模型学习到的语义特征呈现互补关系,充分学习蕴含在问答句中的复杂信息;又添加多注意力池化模块,实现问答对的语义特征和句法特征两种不同语义空间上的特征交互,从而能够多角度捕捉问答对之间的语义相关性。在cMedQAv1.0 和cMedQAv2.0 两种公开数据集的基础上,相比于基准模型,本文方法的准确率均有所提高。实验证明通过引入GCN 模型捕捉句子的句法信息,优化了问答句的特征编码;利用多注意力池化模块,能进一步刻画不同角度的问答对特征向量,且充分学习问题和答案之间的语义关联度。
本研究的主要贡献包括以下四点:(1)采用不同网络模型捕捉问答对中不同角度和维度上的语义信息。利用双向门控循环单元学习句子的语义特征,引入图卷积神经网络捕捉句法结构的特征表示。(2)通过多注意力池化模型,在语义特征和句法特征不同语义空间上,实现问答对两种编码向量的多注意力交互表示,给特征向量分配不同的注意力权重,并学习问答对之间的语义关联。(3)所提出的方法在两种公开的中文医疗自动问答数据集上,cMedQAv1.0 开发集、测试集以及cMedQAv2.0开发集准确率均达到最优,分别为79.05%、78.45%和81.85%。(4)通过观察ACC@1评价指标,分析本文方法的各个模块对本实验的贡献。
1 本文方法
1.1 本文思路
首先,将问答句拼接起来以字嵌入方式输入到BERT 预训练语言模型,捕获和表示问答句的语义信息以及两者的语义关联性。其次,将BERT模型生成的特征向量分别作为BiGRU 和GCN 模型的输入,由此在BERT 模型挖掘的序列信息基础上,进一步得到句子的全局语义特征和句法特征,即通过BiGRU 优化文本的语义表示,获得全局化的语义向量;通过GCN能够捕捉句子的句法特征,并与BiGRU 获得的序列特征呈现互补关系。随后,利用多注意力交互模块,将问答对的语义特征和句法特征四个特征向量进行两两融合,一方面能够集成问答对的不同空间上的特征向量,使得特征向量包含更丰富的文本信息;另一方面可以多角度学习问答对的共现信息以及突出表达问答对的重要内容。其中,问答对的四个特征向量两两融合指的是问题的语义特征和答案的语法结构特征、问题的语义特征和答案的语义特征、问题的语法结构特征和答案的语义特征以及问题的语法结构特征和答案的语法结构特征四种交互方式,由此得到多个注意力池化矩阵。然后,将多个注意力池化矩阵传入到池化层分别做最大行和最大列的池化,进一步提取问答句的向量表示,并通过分别计算问答对特征向量的平均值,获得最终的编码向量;最后,通过计算问答对的相关性大小,衡量问答对的匹配程度,从而找到目标答案。
1.2 模型总体框架介绍
本文提出的自动问答模型主要分为了三个组成部分:编码层、多注意力池化模块和计算相似度层。总体框架如图1所示。
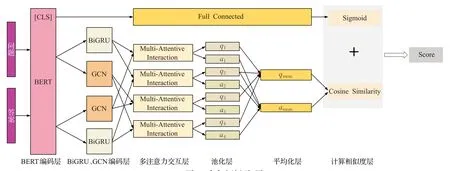
图1 本文方法框架图Fig.1 Framework diagram of proposed method
1.3 编码层
编码层中使用BERT 模型提取问答句的序列信息以及问答对的语义相关性;在BERT 模型的基础上,再利用BiGRU 进一步提取句子的全局语义信息,优化文本的序列特征,引入GCN 编码文本中基于依存分析图的局部依赖的句法关系,补充单独从BiGRU 无法捕捉的语法结构信息,与BiGRU 捕捉的序列信息表现为互补关系。
1.3.1 BERT编码
BERT模型是近几年Devlin等人[16]提出的一种优秀的语言表征模型,广泛应用于自然语言处理任务中。BERT模型是基于双向的Transformer编码器构成,其框架结构如图2 所示。如图1 所示,本文将问题和答案拼接起来并以[SEP]分隔,输入到BERT 模型,其中,BERT模型的输入向量由位置编码、段编码和词向量相加而成。然后经过双向Transformer得到问答对的编码向量[CLS],较完整地保存了问答对的语义信息,并利用自注意机制(self-attention)捕捉问答对的语义关联性。

图2 BERT框架图Fig.2 BERT frame diagram
1.3.2 BiGRU编码
由BERT模型生成的特征向量作为BiGRU的输入,利用BiGRU进一步编码问答对的全局语义信息。BiGRU是通过两层GRU对输入序列分别采用前向序列和反向序列的方式进行编码,由此生成上下文语境化的特征向量。GRU模型是在LSTM模型的基础上做改进,简化了模型结构,其只包括更新门和重置门两个门控结构[17]。GRU 模型降低了模型复杂度的同时,加快了运算速度。GRU网络模型的具体计算过程如式(1)~(4)所示:
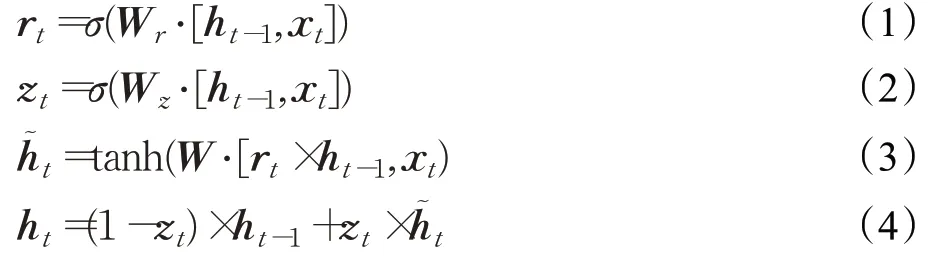
其中,rt表示重置门权重,其决定从历史信息中保留多少融入到xt。zt表示更新门权重,其决定从历史信息中有多少来更新ht。ht-1表示t-1 时刻的隐含状态的输出;xt表示t时刻的输入;ht表示t时刻的隐含状态的输出;Wr、Wz和W表示权重矩阵;σ为sigmoid激活函数;tanh为双曲正切激活函数。
因此,在t时刻,BiGRU 的前向输出为htf,反向输出为htb,将两种特征表示拼接获得最终的隐藏状态ht,计算公式如下所示:

1.3.3 GCN编码
本文在BERT编码的基础上,引入GCN编码得到问答对的句法信息,与BiGRU 编码的语义信息互补。GCN 是在卷积神经网络的基础上改进而来的,是一种直接提取依存分析图上结构特征的模型[18]。依存分析图由节点和边组成。对于一个句子s=c1,c2,…,cn,设定有n个节点的依存分析图。在本文中,依存分析图的每个节点代表一个字,边(i,j)代表第i个字和第j个字之间的依赖关系。并采用n×n的邻接矩阵Aij表示图结构,通常Aij=1 代表节点i到节点j之间存在边。本文利用BERT 模型生成的特征向量作为依存分析图的节点,将节点i与节点j的注意力权重用作衡量边权重的大小,以区别不同的依赖关系。对于图中每个节点,GCN通过该节点的附近其他节点的性质融合归纳得到该节点的特征表示向量,也就是,将每个节点邻域内的相关信息编码为一个新的表示向量。
在L层GCN中,表示输入向量,表示节点i在第L层的输出向量,具体的图卷积操作如下式所示:

其中,W(l)是线性转换,b(l)是偏置项,σ是非线性函数,Aij是邻接矩阵。
1.4 多注意力池化模块
问题和正确答案之间通常有相似的语义信息和语法结构,通过深度挖掘问答对之间的相似性,有助于找到最佳答案。本文的多注意力池化模块主要作用是从语义特征和句法特征两种不同语义空间上挖掘问答句中隐藏的相关性,其包括三个组成部分:多注意力交互层、池化层和平均化层。
1.4.1 多注意力交互层
本文先通过编码层构建问答句的特征向量Q和A,再将Q和A传入到多注意力交互层,进行语义特征和句法特征不同语义空间上的特征向量两两交互,由此构造注意力池化矩阵G,使问答对的向量表示包含丰富的语义特征和句法信息以及实现从多角度挖掘问答对的相关性。其计算公式如下:

其中,U是由神经网络训练得到的参数矩阵。
1.4.2 池化层
将多个注意力池化矩阵G传入到池化层,分别作基于行的最大池化和基于列的最大池化,并生成不同的向量q和a。池化层的作用是采用最大池化的方式进一步提取句子中的重要信息[19]。向量q的第m个元素表示问题中的第m个字附近的上下文对答案影响的重要性,同样地,向量a的第n个元素表示候选答案中的第n个字附近的上下文对问题影响的重要性。其计算公式分别如下所示:

其中,M表示问题的序列长度;L表示答案的序列长度。
接着,将向量q和a进行Softmax函数归一化处理,分别转化为注意力权重向量σq和σa。并将注意力权重向量σq和σa与神经网络模型提取的特征向量Q和A相乘,得到问题和答案表示向量rq和ra。由此着重突出问答句中相关信息。具体计算公式如下:

1.4.3 平均化层
通过将不同rq和ra取平均值,得到最终的特征向量qmean和amean。
1.5 计算相似度层
在问答对特征向量余弦相似度的基础上,为了减小预训练和Finetune的不一致性,增加由BERT的[CLS]预测得到问答对匹配概率值,作为最终匹配分数,从而判断问答对的语义匹配程度。
本文利用余弦值大小有效评估问题和答案之间的语义相关性大小。余弦值越大,两个句子的语义相关度越高。其计算公式如下:
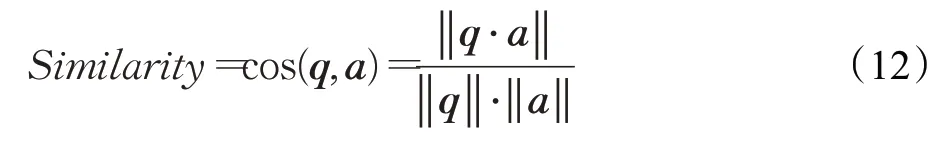
2 实验结果与分析
2.1 实验数据集
该实验依托于中文医疗自动问答任务中公开的数据集cMedQA[20]。cMedQA数据集包括v1.0和v2.0两个版本,表1是关于该数据集的概览。两种数据集均由训练集、开发集和测试集三个部分组成。训练集用于训练模型,开发集用于调整模型参数,测试集用于评估模型的性能。在cMedQAv2.0 训练集中,对于每一个问题qi,都有一个或几个正确答案和几十个不相关答案,由此共构成50 个问答对,所以,在训练过程中共有500 万个三元组输入到网络。对于开发集和测试集的每一个问题,目标是从由正确回答和不相关答案构成的100个候选答案中找出最佳答案,由此来评估模型性能的好坏。
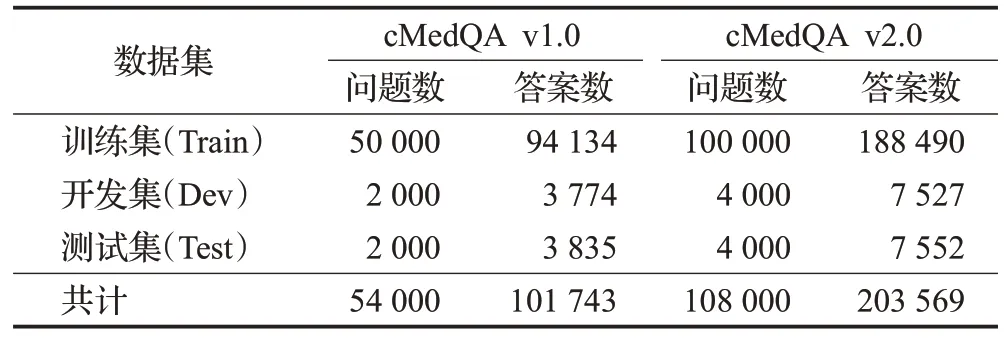
表1 cMedQA数据集的概览Table 1 Overview of cMedQA data set
2.2 实验环境、参数与评价指标
实验的硬件和软件的配置保证着实验的顺利进行,本文实验环境如表2所示。

表2 实验环境配置Table 2 Experimental environment configuration
本文的BERT 模型使用了12 头注意力机制的双向Transformer,隐藏层有768维,其他详细的超参数如表3所示。
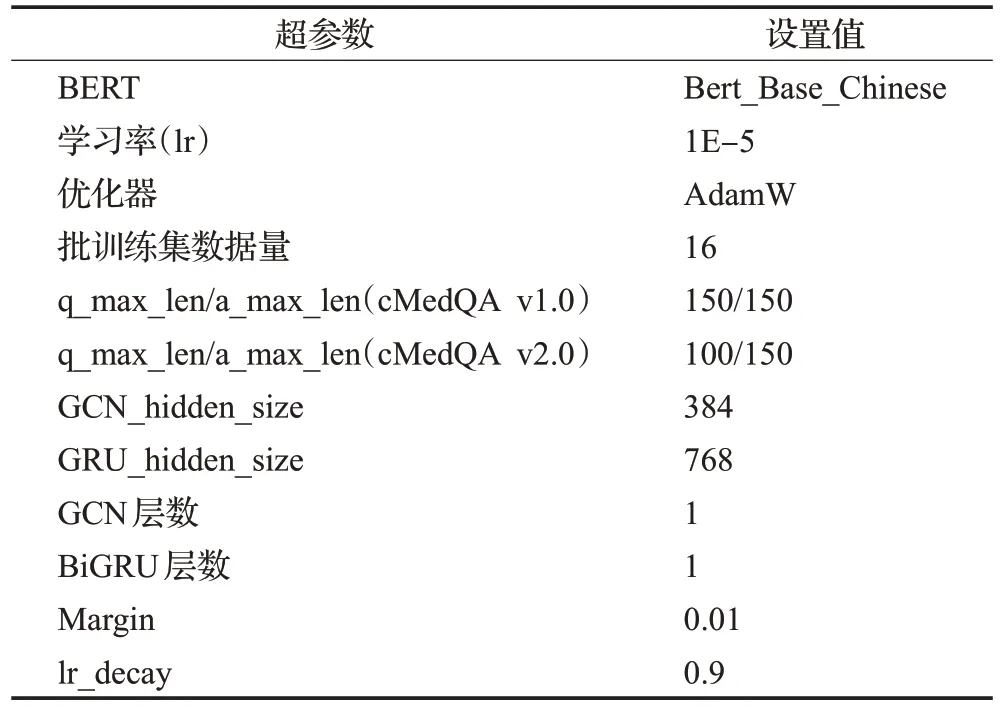
表3 超参数设置Table 3 Hyperparameter settings
为了评估本文方法的有效性,选用了top-1 精度(ACC@1)作为评价指标[21]。top-k精度ACC@k是信息检索中常用的一个评价标准,其计算公式如下所示:

其中,N表示开发集或测试集的样本数目;表示为问题qi的某一个正确答案;1[⋅]为示性函数,即当且仅当函数表达式成立时,其值为1,否则为0。
与传统信息检索任务不同的是,自动问答任务的主要目的是找出与问题最匹配的答案。因此,本实验采用ACC@1。即,ACC@1 值越大,表明模型回答问题的准确率越高,模型性能越好。
2.3 实验结果及分析
本文实验共包括4 个部分:实验1 通过与多种不同的基准模型进行对比研究,证明本文方法的优越性。实验2设置不同超参数值,分析其对模型性能的影响。实验3通过对本文方法中的各个模块进行移除,观察各个模块的重要性。实验4绘制问题和答案相关度热力图,进一步生动描述多注意力池化模块的表现。
实验1 模型对比。为了充分验证本文方法的可靠性和有效性,本文分别选取了cMedQA v1.0和cMedQA v2.0公开数据集进行实验,并将本文方法与当前主流的深度学习算法对比以验证所提出算法性能的优越性。实验结果如表4所示。
表4描述了在两种公开数据集下,不同神经网络的ACC@1 指标表现。宏观来看,各个神经网络模型在cMedQA v2.0 数据集的准确率与cMedQA v1.0 数据集的准确率相比均有提高。由此可见,训练集样本量的提高可以显著提高准确率。
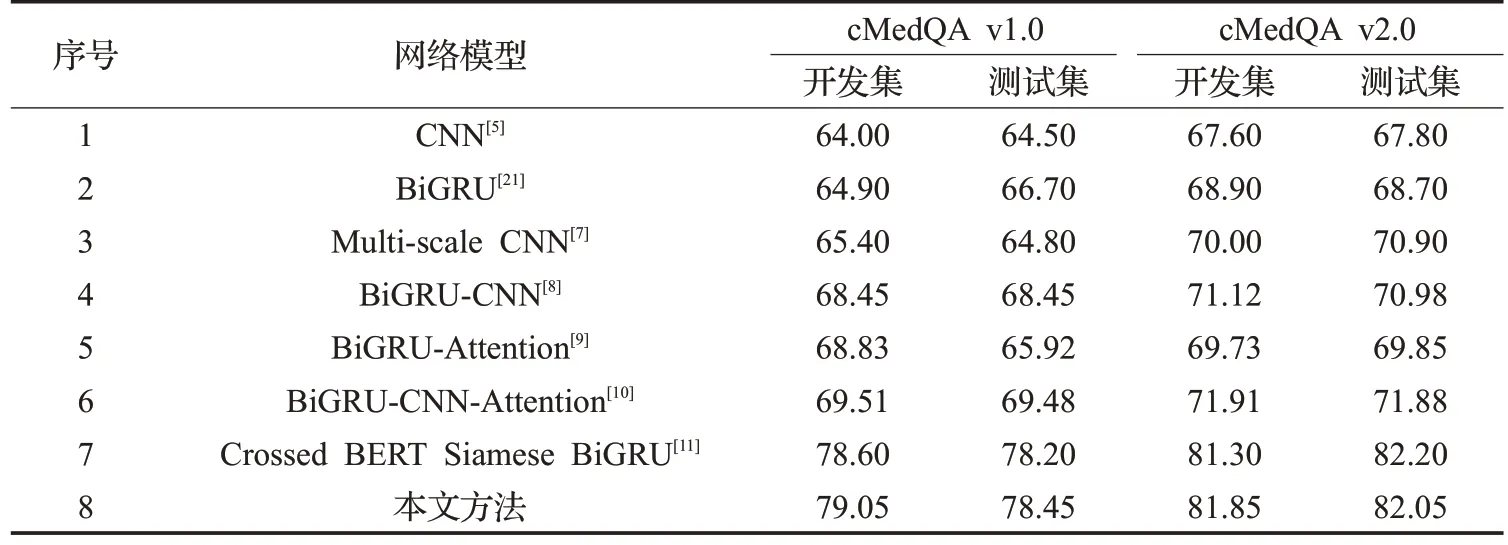
表4 多种网络在两种数据集下的实验结果(ACC@1)Table 4 Experimental results of various networks under two data sets(ACC@1)%
在下文的实验分析中,以cMedQA v1.0 的开发集和测试集为依据。表中前3 行是单个网络模型的实验结果,从实验结果可以看出,BiGRU模型要优于CNN模型,但Multi-scale CNN 的ACC@1 最高,说明多尺度卷积神经网络利用多个卷积核从字、词和短语等不同粒度多方面学习问答对的语义信息。表中第4 行是BiGRU和CNN 组合的多模型网络,无论与单个BiGRU 模型还是单个CNN 模型相比,多种模型组合的神经网络都比单个模型的准确率高,说明多种不同模型可以从不同角度和维度全面捕捉句子复杂的内在语义特征。表中第5、6行是添加注意力池化机制的多模型组合网络,从ACC@1 指标来看,引入多注意力池化机制的网络模型可以掌握问答对之间的信息关联,使得问答系统的性能有一定的提升。表中第7 行是目前中文医疗问答任务上效果最佳的方法,将本文所提方法与其相较,本文方法的开发集和测试集的ACC@1分别提高了0.45和0.25个百分点,主要因为本文方法集成多种不同功能的算法,不仅能提取问答句中的语义和语法结构信息,也能捕捉问答对之间的语义关系,具有一定的优越性。
同样地,从表4中可以看出,对于cMedQAv2.0开发集来说,ACC@1 均高于其他基准模型;对于测试集来说,稍稍低于Crossed BERT Siamese BiGRU 网络模型。由此可见,本文在没有利用大量的中文医疗文本对BERT模型进行预训练的前提下,也能取得较好的效果,这也证明了本文集成算法的优势。
实验2 参数设定。为了选择合适的超参数,本文采用准确率作为评价指标,对比了6种不同学习率对本文方法的影响。实验结果如图3 所示。图中横坐标表示不同的学习率,纵坐标表示cMedQA v1.0 测试集的准确率。从图3 可以看出,随着学习率的变化,准确率表现出较大幅度的波动。当学习率为1E-5 时,模型的收敛性较好,准确率达到最大,为79.05%。当学习率过小或过大时,准确率均有所减小。由此可见,学习率的大小对模型性能具有一定的影响。

图3 不同学习率对模型的影响Fig.3 Effect of different learning rate on model
接下来,固定其他超参数不变,调整不同BiGRU和GCN 的层数进行对照实验,并分析两者结构复杂度对模型性能的影响。本文在cMedQA v1.0 数据集上,进行了不同BiGRU 和GCN 层数的准确率变化的对比,具体结果如表5所示。

表5 不同BiGRU和GCN层数的实验结果Table 5 Experimental results of different BiGRU and GCN layers
本文分别选用1 个、2 个、3 个BiGRU 和GCN 作为特征提取器。通过对比实验,发现随着网络层数的加深,各个多层次复杂网络的准确率有所降低。设置BiGRU层数为1 时,准确率最佳,主要因为利用单层BiGRU 可以获取句子上下文的语义特征;层数设置为2和3时,准确率表现出下降,而且网络的结构复杂度增加、训练时间较长。同样地,设置GCN层数为1时,准确率也最佳,其原理是通过单层GCN 将问答对文本转化为节点构图,不仅学习节点的文本信息,还通过句法属性将文本关联起来,更好地利用节点之间的邻域信息。随着GCN层数的增加,加深的网络导致节点特征的平滑。因此,在考虑准确率的同时也考虑模型的复杂程度,本文选择了1 层的BiGRU和GCN作为本文模型的最终参数。
实验3 消融实验。上文中,通过不同模型的对比,证实了本文方法的有效性。为了进一步解析本文方法的BiGRU、GCN以及Multi-Attentive Interaction(多注意力交互)对实验结果的贡献,本实验在cMedQA v1.0 开发集和测试集的基础上,进行了消融实验。通过去除某个模块与本文方法进行横向对比,评估模块的重要性。
表6 具体展现了本文方法中各个模块的重要性。第1行是本文方法的实验结果,2~5行分别是去除BiGRU、GCN 以及Multi-Attentive Interaction 模块的实验结果。整体上来看,所有模块对本文的实验结果都起着积极作用。当移除BiGRU,与本文方法相比,开发集和测试集ACC@1分别降低了2.9个百分点和3.2个百分点。说明利用BiGRU抽取句子级别的语义信息有很大意义。当移除GCN,发现开发集和测试集ACC@1 分别减少了2.9 和2.05 个百分点。说明通过GCN 模型学习句子的句法属性,明显优化了文本的语义表征。综上所述,BiGRU模型和GCN模型能够从不同角度和维度抽取文本的语义和句法信息,也进一步刻画出BiGRU 模型和GCN模型所获取信息的表现出互补关系。当移除Multi-Attentive Interaction 模块,开发集和测试集CCA@1 也有所改变,分别减少了0.95 和0.4 个百分点。说明通过多注意力交互模块将BiGRU 和GCN 输出向量做进一步集成是有效的,能够描述问答对的依赖关系,有助于改善实验结果。

表6 消融实验结果Table 6 Ablation experiment results
实验4 实例分析。为了更直观地展示多注意力交互模块在中文医疗自动问答任务上的表现,本实验借助于一个实例进行阐述。具体内容如图4所示。图4是关于问题和其正确答案相关度的热力图,清晰地刻画了问题和答案相关性大小。图中横坐标代表的是正确答案,纵坐标代表的是问题。纵坐标的具体内容是“专业治疗中枢性截瘫的方法什么?病情描述(发病时间、主要症状等):男55 岁三十年前就有症状,肌张力高,勉强自理。双膝盖互相碰撞,脑核磁检查示脑萎缩趋势,走路不稳。医院检查确诊为中枢性截瘫,想问一下有没有朋友知道中枢性截瘫的特色治疗法?”,横坐标的具体内容是“指导意见:中枢性截瘫的症状多种多样,其中身体发硬,这是肌张力亢进的症状,在一个月时即可见到。如果持续4个月以上,可诊断为脑瘫。如果您出现这种症状就一定要及时就医,千万不要拖延。”。由图4 可知,问答句相对应的每个区域颜色深浅大有不同。颜色较浅区域表示问题和答案内容相关度较小,即通过多注意力交互模块,分配了较少的注意力权重;而颜色较深区域表示问题和答案内容相关度较大,即通过多注意力交互模块,分配了更多的注意力权重。具体的,患者提出的问题是中枢性截瘫的治疗方法是什么,问题中描述的症状如“肌张力高”“双膝盖互相碰撞”和“走路不稳”,也通常是由中枢性截瘫引起的。答句针对患者的疾病给出了指导意见,其中包括符合患者描述的症状以及给出恰当建议。问答句之间存在紧密的相关性。从图4 可以看出,问句出现的“中枢性截瘫”和答句出现的“中枢性截瘫”两个词汇对应区域颜色较深,并且问句中患者表现的症状与答句的症状描述相关性权重较大,这些区域颜色也较深。通过分析发现本文提出的多注意力交互模块可以进一步学习问题和答案的相关性,因此有助于找到与问题匹配的目标答案。

图4 问题和答案相关度热力图Fig.4 Question and answer correlation heat map
3 结束语
本文提出了融合语义及句法特征的多注意力交互的自动问答方法。首先,通过将问答句拼接输入到BERT模型,学习问答句的高阶语义信息和语义关联度;其次,利用双向门控循环单元编码句子的全局语义特征,同时采用图卷积神经网络编码句子的语法结构信息;然后,利用多注意力池化模块实现问题和答案不同特征向量之间的集成,以对其进一步分配不同的注意力权重,着重突出问答对的共现特征。通过与多组不同神经网络的实验结果对比,发现本文方法有效优化了自动问答的准确率。证明了本文方法通过多种深度神经网络的集成进一步改善了对中文医疗文本语义的表征和语义相关性的捕捉。
当然,本文也存在着不足,没有利用海量的中文医疗文本对BERT 语言模型进行预训练,让BERT 模型对医学领域文本有更好的语义表征能力。这也是下一步的工作,由此进一步增强特征向量对文本语义的表达和提高自动问答的准确率。
