基于LSTM和动态策略的定向灰盒模糊测试技术
2022-09-21李兆基王田原周自强陈永乐
李兆基,王田原,周自强,王 尧,陈永乐
1.太原理工大学 信息与计算机学院,山西 晋中030600
2.国网山西省电力公司电力科学研究院 电网技术中心,太原030001
模糊测试是一种自动化的程序测试技术,它通过向目标系统或待测程序提供大量输入,然后监测程序运行过程中的异常状况来发现程序错误或漏洞。随着模糊测试技术的研究与发展,对于许多仅有部分代码区域需要测试的实际场景来说,定向模糊测试成为了一种最为行之有效的解决方案。例如补丁测试、bug重现和特殊bug搜索等场景[1]。
传统的定向模糊测试是基于符号执行的[2-6],它使用程序分析和约束求解来生成执行不同程序路径的输入。这种定向模糊化器将可达性问题转化为迭代约束满足问题。但其将运行时的大部分时间都花在重量级程序分析和约束求解上,可能会导致路径爆炸问题,因此效率是低下的。2017年,Bohme等人[7]提出了一种定向灰盒模糊测试工具AFLGo,它通过计算每个基本块和插装阶段的目标位置之间的距离来测量种子到目标位置的距离,并使用基于模拟退火的调度策略通过输入距离评估来分配测试能量,以此来获得更高的定向性能和效率。然而实验发现,在某些程序运行中,AFLGo的定向性能并不像预期的那样优于AFL。这是因为整个定向模糊化过程分为探索阶段和开发阶段[7],AFLGo使用探索和开发阶段的固定划分,一旦探索阶段转向开发阶段,即使由于没有足够的路径而导致方向性能差,也没有回头路可走,不充分的探索结果通常会导致较差的开发结果。针对此问题,RDFuzz[8]使用一个交织的时间表来交替进行探索和开发,但即使是这样,也显得不够灵活,无法做到对于真实世界的不同应用程序自适应地权衡探索阶段与开发阶段。研究人员将深度学习应用于定向模糊,为解决以往研究中的难题提供了新的见解。V-Fuzz[9]和Suzzer[10]基于深度学习模型预测函数的易受攻击概率,计算每个输入执行路径上所有基本块的静态得分之和,对得分较高的输入进行优先级排序。FuzzGuard[11]使用一种基于深度学习的方法,在执行之前过滤掉无法到达的输入,节省了在实际执行上花费的时间。但无法忽略的是,他们都采用随机突变策略来生成输入用例,由于随机突变无法精确地改变输入文件,这样导致的后果就是,在对生成的输入进行筛选和优先级排序之前,需要花费大量的时间和资源去生成海量输入,然后通常会出现数百万个新生成的输入被丢弃,只有其中的少数输入(执行新的代码路径)被保留下来,这势必会使得它们在探索阶段和开发阶段都耗费大量不必要的资源去生成许多无效输入,从而使模糊器变得低效。
在本文中,提出一种基于神经网络的动态策略定向模糊测试方法,以缓解以上问题。该方法通过建立一个深度学习模型来优化定向模糊测试中种子突变策略,学习先前输入文件中不同位置的应用突变模式,进而精确引导当前输入生成过程,以最大限度地减少花费在生成不期望输入上的时间,从而增加模糊器覆盖新代码路径的机会。将模糊测试阶段的分裂投射到种子的划分上来动态协调探索阶段和开发阶段的划分,即将种子分成两组:用于探索的覆盖种子和用于开发的定向种子,基于本文设计的动态算法,可以自适应地在两个状态之间切换。在这些技术的基础上,开发了一个原型,名为DYNFuzz。并且在libxml2[12]、mupdf[13]、readelf[14]这三个应用程序上对DYNFuzz 进行了测试。实验结果表明,DYNFuzz具有比一般定向模糊器更优越的性能。
本文做出的主要贡献如下:
(1)提出一种新的神经网络解决方法来优化种子突变,模型通过学习过去模糊探索输入文件中的模式,预测当前输入文件中执行变异的最佳位置,模糊器基于此信息生成高质量的输入。
(2)提出一种全新的定向模糊测试动态协调方法,能够自适应地调整定向模糊测试阶段的划分,提高模糊器的性能和效率。
(3)在AFL的基础上实现了原型DYNFuzz,实验结果表明,DYNFuzz具有比其他模糊器更好的性能表现。
1 方法
1.1 方法概述
定向灰盒模糊测试(directed greybox fuzzing,DGF)的目标是到达程序代码中的一组预先确定的位置,即潜在的容易引发错误的位置。为此,整个DGF 过程需要经过探索和开发两个阶段。两个阶段的界限与权衡是影响DGF性能的一个重要因素。采用一种动态策略来协调二者之间的划分,并且能够做到自适应地在两个阶段之间来回切换。具体来讲,将模糊测试中的种子分成两组:用于探索路径的覆盖种子和用于开发的定向种子。在本文的方法中,每组中种子的数量来表示花在相应阶段的能量,通过控制每组种子的数量来实现对两个阶段的动态协调。另外,为了大幅提高模糊器生成输入的效率,利用现代神经网络模型的强大学习能力去探索输入文件中的模式,通过学习一个函数来预测输入文件不同位置的突变增益,根据结果进行相应的模糊突变,从而达到指导未来的模糊搜索的能力。DYNFuzz的整体框架如图1所示。

图1 DYNFuzz整体框架图Fig.1 Framework of DYN fuzzz
1.2 神经网络模型
模糊测试需要大量的计算。即使是很小的输入增益,也需要成千上万的随机突变来发现。然而,并不是所有的突变都是一样的。文件格式及其解析器是异构的,对于一个复杂的输入格式,如果没有大量的领域专业知识,手动识别那些有可能产生输入增益的关键位置是很困难的。为此,通过一个神经网络模型来自动识别输入文件中使用代码覆盖反馈有用的位置。
给定一个字节格式的输入文件,该模型注释了一个热映射函数,强调了在输入文件中改变每个位置的相对有效性。由于种子文件的长度可变,将模型定义为一个函数族。这类函数可以表示为公式(1)中的f,它可以接受任意数量的输入位置作为输入。

通过这个函数将输入文件中的每个位置与产生输入增益的突变概率关联起来。在种子变异之前,模糊器为每个种子文件查询该模型,并将突变集中在高亮显示的位置,然后使用生成的热图引导突变到有用的位置。另外,针对少数有用位置的潜在输入在模糊执行期间被否决,这样可以避免执行不太可能产生输入增益的输入,从而节省时间。可以通过公式(2)来决定一个突变的输入是否被否决。
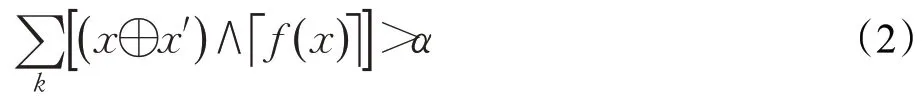
其中,x表示模糊测试输入的文件,x′表示变异后的输入,f(x)对应输入文件的位置突变增益概率,α为用户自定义阈值。x⊕x′可以表示变异输入与原始种子文件之间的差异,通过α来控制一个合法的突变输入需要多少有用的字节必须被突变。
直观上来讲,认为对于一个经过变异的输入来说,代码覆盖的缺乏表明该输入应用了无用位置的突变。为了训练一个模型来学习预测函数,可以通过输入文件和相应的代码覆盖率位图的组合来表征和确定有用的位置。具体来讲,模型的数据训练集对由以下公式来生成:

对于某一实值γ的截止值。给定训练数据集,目标是学习一个模型,该模型可以将输入文件x映射到差异热图x⊕x′,这反过来又可以用来识别潜在有用的位置,以集中注意力于突变。s(b,b′) 用于表示导致输入增益的突变。可以用一个激励函数来表示:

其中,bi表示位图b的第i位,|b|表示位图的长度。具体的取值参考如表1所示。

表1 激励函数真值表Table 1 Truth table for activation function
由于输入文件都是序列数据,而且长度是可变的,选择长短时记忆(LSTM)神经网络[15]来进行训练,以输出一个模型,可用于预测预期的代码覆盖。众所周知,LSTM克服了RNN在较长的序列上存在的问题,能够学习长依赖关系。LSTM 神经元包括一个用来保存长期记忆的细胞状态和输入门、输出门及遗忘门,结构如图2所示。
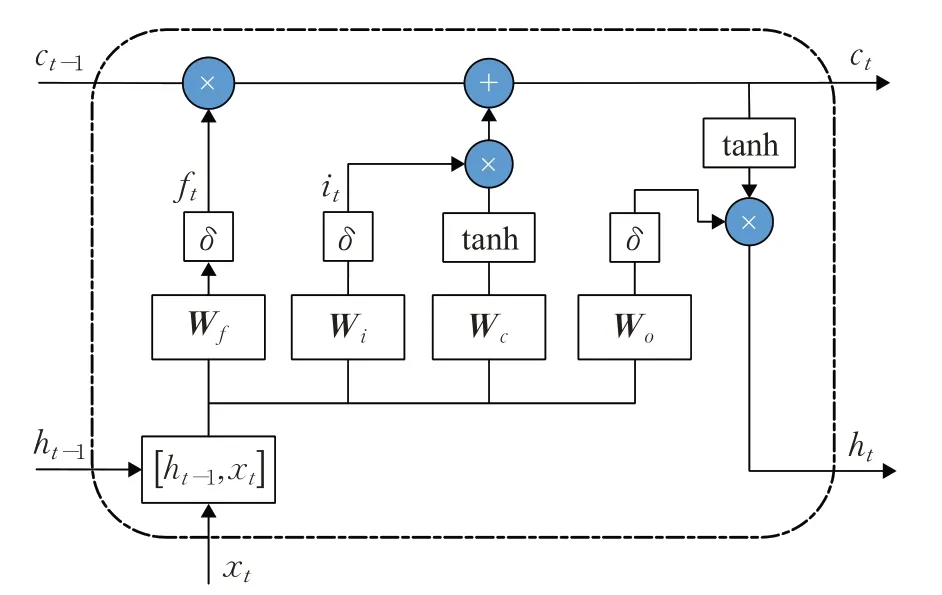
图2 LSTM神经元结构图Fig.2 Structure of LSTM neuron
遗忘门ft决定上一时刻的细胞状态Ct-1有多少保留至当前时刻,输入门it决定当前网络的输入xt有多少保存到细胞状态,然后将当前记忆和长期记忆组合在一起,形成新的细胞状态,具体如式(5)~(7)所示:

其中,W*表示模型的学习权重向量,σ为Sigmoid激活函数,b*代表模型的学习偏差向量。最后通过输出门ot控制单元状态Ct有多少输出到LSTM的当前输出值ht,即:

训练模型中,使用平均绝对误差(MAE)作为损失函数,优化器是Adam。
1.3 高效定向模糊测试
现有的定向模糊器效率不高的很大一部分原因在于无法去灵活确定探索阶段与开发阶段的界限,一旦由探索阶段转向了开发阶段,即使由于没有足够的路径导致方向性能差,也没有回头路可走。为此,设计了一种动态算法,能够使模糊器在运行过程中根据情况去选择调用执行合适的阶段。详情如算法1 所示。使用一个变量dr来表示种子池中定向种子所占的比重,相应地它也表示花在开发阶段的能量。在每个模糊化周期中,给覆盖种子与定向种子加上标签,由dr进行调整。定向模糊过程首先会进入探索阶段(dr=0),不断地去发现更多的程序路径,然后通过逐步增加dr的值来进入开发阶段。另外一种情况是,当模糊器长时间得不到的新的程序路径覆盖时,需要迅速增加dr的值转入开发阶段。在开发阶段,会优先选择距离目标位置更近的种子进行变异,同样有时也需要从开发阶段回到探索阶段,那就是当模糊器由于不充分的路径探索信息陷入局部困境时。具体表现为如dr非常大,但经过多个模糊化周期后仍不能靠近目标,这时应当大幅降低dr值返回探索阶段继续探索新的路径,发现更多潜在的定向种子。另外,算法中的阈值是根据神经网络模型的准确度设置的。通过这一动态策略,能够自适应地权衡探索阶段和开发阶段,提高模糊器的性能。
算法1 Directed Greybox Fuzzing with dynamic strategy


众所周知,模糊器的突变策略是影响模糊器性能的一个重要因素。一些模糊器优化突变策略以辅助定向模糊,Chen 等[16]利用了一种自适应突变策略,它将突变器分为粗粒度和细粒度。粗粒度的突变器用于在突变期间更改大量字节,而细粒度的突变器则只涉及几个字节级的修改、插入或删除。但突变器的调度是由经验值控制的,带有一定的主观性。本文通过采用机器学习的方法将变异具体到种子的字节粒度来改善这一过程。DYNFuzz在每次种子突变之前查询训练好的神经网络模型,通过模型反馈的预测结果来优化探索阶段和定向阶段的种子变异。探索阶段的目的在于代码覆盖,因此在探索阶段,模糊器在种子突变前查询神经网络模型,模型返回对应的完整输入文件的覆盖热图,对应文件各位置突变导致新代码覆盖的概率可能性。使用覆盖热图中的概率值对突变位置进行排序,优先选择产生突变增益可能性高的位置进行突变。此外,通过模型查询获得到的bytemask是按位的,结合突变输入与原始种子之间的差异可以获得如公式(10)所示的K值,其中input⊕Seed表示突变差异。当K值小于给定阈值α,此次突变无法导致代码覆盖率的增加或者其增幅不够明显,则在执行之前拒绝此次突变以节省资源消耗。而到了开发阶段,由于选取的都是距离目标位置比较近的定向种子,而且经过模型查询,可以否决那些无用部分的突变,这样一来,大量的突变极有可能导致种子偏离目标位置,因此DYNFuzz在开发阶段对于模型反馈的有效突变位置以50%的概率选择对其进行轻微的突变,即单一方式的突变。

在探索阶段,为了能够让模糊器尽可能探索到更多的程序路径,在测试执行跟踪中关注那些触发新的路径覆盖的种子,这样配合神经网络模型的反馈信息进行精准变异,可以大大提升模糊器的探索效率,获取到丰富的路径信息。到了开发阶段,借鉴了AFLGo 的种子优先级排序方法,基于LLVM方法[17]计算基本块距离目标点的距离,赋予每个定向模糊种子一个distance值,由此对其进行优先级排序。
2 实验和评估
2.1 实验环境
在搭载了Intel Core CPU i7-6500U、16 GB RAM、Nvidia GeForce GTX 1080 Ti(11 GB)和 以Ubuntu 16.04(64位)为操作系统的计算机上执行了所有实验和测试。在实验中,选择了libxml2[12]、mupdf[13]、readelf[14]这3个基准来测试和验证提出的技术。
2.2 模型与实现
神经网络模型是基于高级深度学习库Keras[18]开发的,并选用Tensorflow[19]作为底层后端。为了收集训练模型所需要的数据,针对每个基准随机选取了7 800 个种子文件,将种子平均分为训练集和测试集,在AFL上运行了24 h。给定一个包含输入、变异输入以及其对应的代码覆盖的集合(x,x′,b,b′),通过公式对数据进行过滤,构造一个训练集XY。模型训练了12 h 以确保收敛,损失函数使用平均绝对误差(MAE),同时还使用Adam 优化器来帮助学习函数快速稳定地收敛到最优解。当学习函数的损失值变得稳定时,训练过程结束。
基于所提出的方法,开发了一个原型,由DYNFuzz命名,它建立在AFL[20]、基于LLVM[17]的分析和python脚本之上。AFL提供了一个基本的测试框架;此外,在afl-fuzz.c模块中添加了一些额外的代码,实现了提出的方法,包括动态策略、QueryModel()函数。基于LLVM的分析和python脚本用于输入距离计算。
2.3 评估
为了评估本文提出方法的有效性,在不同的测试基准上进行了多次实验,从神经网络模型的有效性、DYNFuzz的定向性能两个方面进行了评估。
2.3.1 模型有效性
模型的有效性对DYNFuzz 至关重要,因为种子变异是基于模型的预测结果进行的。如图3所示,经过5个时期的训练,本文的模型准确率达到了91.3%,训练损失下降到了23%,结果如图3所示。

图3 模型的训练精度和损失值Fig.3 Training accuracy and loss of proposed model
另一方面,使用机器学习中广泛使用的假正例率(FPR)、假阴率(FNR)、真正例率(TPR)、准确率(P)以及F值(F-score)作为度量来评估本文的模型。其中FPR=FP/(FP+TN)是假阳性输入增益占全部无法产生输入增益总体的比例,FNR=FN/(TP+FN)为假阴性输入增益与输入增益总体的比例。TPR=TP/(TP+FN)表示正确预测输入增益样本与输入增益总体的比例。P=TP/(TP+FP)用于度量预测输入增益,增加代码覆盖的正确性。F-score=2×P×TPR/(P+TPR)综合考虑了准确率和TPR。结果如表2 所示,可以看到本文的模型在三个基准测试集上都表现出了良好的预测结果和精准度,但可以看出在mupdf解析器上的表现要明显低于其他两个基准,这可能是由于典型的PDF文件的大小相当大(超过100 kb),针对这种冗长格式文件,模型没有训练充分,学习过程中丢失了部分信息所导致的,针对此问题,可以尝试通过增加训练集的大小来改善。

表2 DYNFuzz在测试基准上的表现Table 2 Performance of DYNFuzz on test benchmarks
2.3.2 定向性能评估
使用机器学习模型的目的在于提高模糊器在探索期间的覆盖能力,丰富的路径信息可以使得模糊器在进入开发阶段后精确导向目标位置,动态策略的引入也使得模糊器更加灵活,能够在陷入困境时在两个阶段之间自由切换。为了直观地表现DYNFuzz 的定向性能,采用探索阶段的输入增益和开发阶段生成输入的最小输入距离作为评价指标来定量表示。输入增益是在目标程序中发现的表现出从未见过的行为路径的数量。这种行为表征为执行一个新的代码块,或者增加先前执行的代码块的执行频率。最小输入距离最早是在AFLGo中提出使用的,这是一种反映直接测试结果的方法。使用AFLGo 和RDFuzz 两个定向模糊器作为比较,在CVE-2017-5969、CVE-2018-6544、CVE-2019-14444这三个基准上进行了对比实验,它们分别对应了结果如图4所示,x轴代表了持续的时间,探索阶段y轴表示找到的代码路径的唯一枚举,开发阶段轴表示所有生成的输入中的最小输入距离。
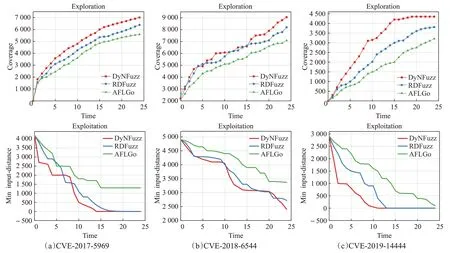
图4 DYNFuzz在三个测试基准上的表现Fig.4 Performance of DYNFuzz on three benchmarks
基于图示结果可以看出,在3个测试基准中,DYNFuzz都表现出了良好的探索和开发结果,特别是在第一个和第三个测试基准上,可以明显看出DYNFuzz 无论是在探索阶段的路径覆盖上还是开发阶段的目标位置定向上,都要好于RDFuzz 和AFLGo。而在第二个基准(CVE-2018-6544)上,DYNFuzz 与RDFuzz 的结果非常接近,甚至在某些时刻点上,RDFuzz 的结果要好于DYNFuzz,推测出现这一结果的原因是模型查询的时间过长从而导致对DYNFuzz的性能产生负面影响。由于典型的PDF 文件大小相当大,DYNFuzz 在模糊化每个种子文件之前,必须为这个种子文件查询模型,以产生显著改善的输入增益,但对于这样大的种子文件,整个查询过程可能需要几秒钟甚至更多的时间,在模型查询上经常会阻塞执行,以致于影响了整个fuzzer 的性能。而RDFuzz 由于采用了分支级别的统计数据,因此在面对mupdf这样比较大的程序也限制了其一定的性能,所以二者在CVE-2018-6544 上的整体表现并没有相差很多。而AFLGo 受限于探索与开发阶段的权衡问题,有时会在CVE-2017-5969 上表现的那样,被困在开发阶段,无法更进一步地接近目标位置,而在DYNFuzz上没有出现这种情况,这得益于动态协调策略的引入,在长时间无法趋近目标代码区域时,模糊器会调用探索阶段来丰富程序路径信息。
3 总结和展望
在本文中,提出了一种基于神经网络模型的动态策略定向模糊测试方法,用于改善当前定向模糊器的效率,在三种处理常见文件格式的程序上进行了实验测试,分析了模型的准确性和DYNFuzz 的定向性能。结果表明,所提出的方法能够更快、更高效地实现程序路径覆盖并接近和覆盖目标位置,这说明本文的技术方法具有更高效的定向性能,从而有着更大的概率去发现漏洞。另外,动态策略方法的应用也避免了模糊器陷入局部困境的情况。
另一方面,DYNFuzz 仍存在一些值得进一步研究的问题与局限性。首先,在实验中发现本文的模型在应对大型文件处理程序时表现不佳,需要进一步完善模型的设计,或者还应该考虑应用其他更好的神经网络模型来学习文件变异模式。其次,动态协调算法中的阈值是根据本文模型的准确度进行设置的,但这在一定程度上也给DYNFuzz 带来了一定的局限性,更为合理的方式应该是基于启发式算法生成的,因此寻找和应用合适的启发式算法也是接下来需要研究的方向。最后,DYNFuzz 的局限还表现在无法发现隐藏在复杂的健全性检查背后的漏洞,例如魔法字节。可以将当前的一些高级方法集成到本文的工具中,以增强漏洞检测能力。例如可以结合污点分析[21]或者动态符号执行[22]技术,设计更加高效的种子遗传变异策略,提升DGF的能力。
