车险定价中风险保费类别的构造
——基于广义线性模型与数据驱动的分箱方法
2022-09-20张连增江璐嘉
张连增 江璐嘉
一、引言
车险定价一直是非寿险精算定价中的一个研究热点,已有文献较多(Denuit 等,2007[1];Klein 等,2014[2];孟生旺等,2017[3])。保险公司经营的核心目标是盈利,科学的风险管理技术可以为保险公司的持续运营提供保障。精算定价人员构造风险保费类别(insurance tariff classes),将风险状况相似的保户归入同一类别,收取相同的保费,使保费与类别的风险相匹配。风险状况由不同的变量(variables)组合来定义,根据变量的数值特性,可以分为分类型变量(如性别、地区)和连续型变量(如驾驶员年龄、车龄)。
Denuit和Lang(2004)[4]指出,变量的不同类型会影响风险保费类别的构造:分类型变量构建风险保费类别直接明了,每一定价类别都代表了分类变量的特定组合;连续型变量由于其数值连续性,在一定程度上可以被理解为具有很多不同水平的分类型变量。Ohlsson和Johansson(2010)[5]指出,如果考虑将连续变量中的每一个数值都定义为一个水平(level),会导致同一个变量有很多水平,且每一个水平下的样本数量都不多,但这样并不利于定价模型的拟合。一种更好的方法是连续变量离散化,把连续型变量的某个区间合并为一个水平,从而转化为包括少数水平的分类变量。
将连续变量离散化的方法被称为分箱法(binning),该术语是由Kuhn和Johnson (2013)[6]提出的。本文将介绍一种由数据驱动(data driven)的分箱方法,将连续型变量转化为包括几个水平的分类变量,由此构造风险保费类别。本文使用回归树(regression tree)作为分箱方法,因为回归树模型会产生直观的连续分割,符合我们对连续变量连续值分箱的要求。在回归树模型中,我们选择采用进化树模型(evolutionary tree),因为进化算法可以达到全局最优的分箱效果。Grubinger 等(2014)[7]设计的R软件包evtree可以实现相关功能。
在车险定价中,通过大量历史索赔数据,可以估计出不同风险保费类别的保险成本,进而计算相应的纯保费(pure premium)。Frees 等(2014)[8]提出纯保费的计算从两个方面分别进行:索赔频数(claim frequency)和索赔强度(claim severity)。通常应用广义线性模型(GLMs)进行车险索赔频数和索赔强度的拟合与预测。在索赔频数和索赔强度相互独立的假设下,保单的纯保费可以用索赔频数的估计值乘以索赔强度的估计值得到。在纯保费的基础上,再考虑附加费用,就构成了保险产品的价格。
在GLMs中,当存在连续型变量时,GLMs不能捕捉连续型变量的非线性效应。此时,通常考虑应用更加灵活的广义可加模型(GAMs)(James等,2013[9])。广义可加模型本质上是一种特殊的广义线性模型,对连续型变量,对应的样条函数可表示为一些基本样条函数的线性组合。在GAMs中,可通过对连续型变量引入样条函数,使模型的拟合效果更加平滑,反映非线性效应。
在模型拟合中,一直存在着“拟合效果”(fitting effect)与“可解释性”(interpretability)之间的权衡。显而易见,广义线性模型的可解释性要优于广义可加模型,而广义可加模型的拟合效果更优。为在两者中找到一个平衡,在本文中,我们先运用GAMs构造一组索赔频数和索赔强度预测模型;然后运用进化树分箱方法,将连续型变量离散化为分类变量,最终运用GLMs构造另一组索赔频数和索赔强度预测模型;将GAMs和GLMs的预测结果进行比较,找到最优的定价预测模型。
本文后面的结构如下:第二节是数据描述和数据预处理;第三节是GLMs和GAMs的基本介绍;第四节是GAMs在车险定价中的应用;第五节是数据驱动分箱构建风险保费类别;第六节构建GLMs,并与GAMs进行模型整体性能的比较;第七节是总结。
二、数据描述和预处理
(一)数据描述和预处理
本文运用的数据集是法国汽车第三者责任险(简称“三责险”)理赔数据freMTPL2freq和freMTPL2sev(1)freMTPL2freq里面包含了很多特征(变量),但不包含索赔金额ClaimAmount变量;freMTPL2sev里面只有保单信息IDpol和索赔金额ClaimAmount这两个变量。共有的变量IDpol将freMTPL2freq和freMTPL2sev两个数据集的保单信息连接起来。,这两个数据集都可以在R软件包CASdatasets里找到。freMTPL2freq里包含了678 013条法国三责险的索赔次数数据,freMTPL2sev里包含了26 639条法国汽车三责险的索赔强度数据。

为了拟合索赔强度模型,我们选取FF数据集中索赔强度大于0且小于20 000(2)FF数据集中包含一些损失特别大的极端数据,会对模型拟合产生影响。区间(0,20 000)包含了92.80%的索赔强度数据量,为此我们挑选这部分数据来进行模型拟合。的保单信息,组合成了一个新的数据集FF.sev,新的FF.sev数据(24 743行、16列)共有24 743个保单数据信息。
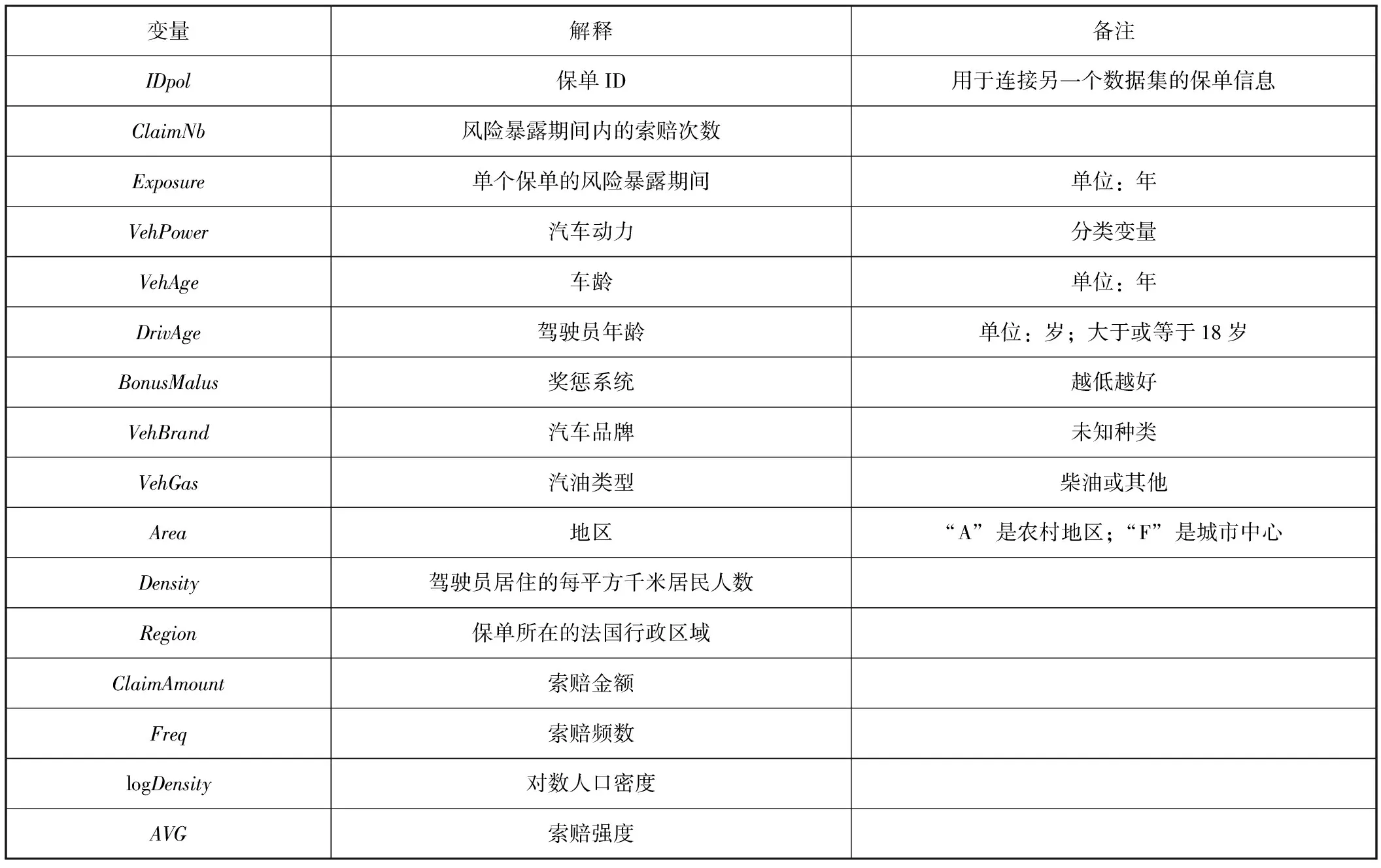
表1 FF数据集变量描述
(二)进一步的分析
根据以上描述我们知道,FF.sev是FF数据集的一个子集。下面我们描述FF数据集的基本数据特征,图1是FF数据集中的一些特征(变量)展示。
在FF数据集中,对索赔次数(ClaimNb),有94.98%的保单没有提出索赔(即ClaimNb=0),有4.75%的保单提出了一次索赔,剩下的0.27%的保单提出多次索赔。对风险暴露(Exposure),24.18%的保单保障期间是1年,剩下的75.82%保单的风险暴露分布于0~1之间。在索赔金额(ClaimAmount)方面,有88.93%的索赔金额位于0~5 000区间中,剩下的11.07%索赔金额高于5 000。
图1展现了FF数据集中的两个分类型变量:汽油类型(VehGas)和汽车品牌(VehBrand)。在汽油类型方面,48.99%的汽车使用柴油(Diesel),剩下的51.01%汽车使用其他类型。在汽车品牌方面,B12(24.49%)、B1(24.00%)和B2(23.58%)是占比最多的三种车型,剩下的27.93%是其他类型的汽车。
FF数据中的四个连续型变量:车龄(VehAge)、驾驶员年龄(DrivAge)、奖惩系统(BonusMalus)和对数人口密度(logDensity)也在图1中呈现。在车龄方面,72.60%的保单车龄集中于0~10年,剩下的27.40%保单车龄超过10年。在驾驶员年龄方面,15.41%的驾驶员年龄在18~30岁之间,76.99%的驾驶员年龄在30~65岁之间,7.60%的驾驶员年龄高于65岁。在法国,奖惩系统的基准是100,低于100是奖励(bonus),高于100是惩罚(malus)。在FF数据中,有98.85%的保单是奖励状态,只有1.15%的保单是惩罚状态。在对数人口密度中,79.19%聚集于2.5~8区间之内,剩下的20.81%分布在其他区间。

图1 FF数据部分特征展示
三、车险定价与GLMs(GAMs)
(一)车险定价基本思路
在车险定价中,精算师根据已有的历史索赔数据,预测出潜在损失,由此计算出保单纯保费πi。保单纯保费可以由索赔频数和索赔强度分别计算得到,即πi=E(Fi)×E(Si),其中E(Fi)是索赔频数预测的均值,E(Si)是索赔强度预测的均值。索赔频数是单位风险暴露(risk exposure)下保单的索赔次数;索赔强度是指在索赔发生条件下的平均单次索赔额度。
在本文中,我们假设索赔频数和索赔强度相互独立。使用数据集FF中所有保单的索赔次数历史,为Fi构建模型;使用数据集FF.sev中提出索赔的保单持有人的索赔历史,为Si构建模型。对每份保单的纯保费πi再加总求和,可以得到整体纯保费。
在本文中,我们考虑运用GAMs和GLMs来构建两组回归预测模型。
(二)GLMs和GAMs模型基本介绍
传统的线性回归模型形式如下:
(1)
其中Yi是响应变量,xij是自变量,p为自变量的个数。
一般的广义线性模型形式如下:
(2)
其中,μi=E(Yi)是响应变量的均值,g(·) 是连接函数(link function),xij是自变量,p为自变量的个数。
GAM本质上是一种特殊的GLM,通过允许自变量存在非线性的平滑效应(smooth effect),同时保持可加性来扩展线性模型。在GAM中,单个自变量的非线性平滑效应可用样条函数fj(xij)表示,它可表示为基本样条函数的线性组合,代替GLM中的βjxij;两个自变量之间也可能存在非线性交互效应,用样条函数fj(xij,zij)来表示自变量之间的非线性交互效应。GAM的形式为:

(3)

四、GAMs在车险定价中的应用
在本节,我们运用GAM对索赔频数和索赔强度分别构建回归预测模型,R里的软件包mgcv可以用来实现GLM和GAM。在最优模型选择方面,我们考虑使用AIC(Akaike Information Criterion)和BIC(Bayesian Information Criterion)两个指标。这两个指标都同时考虑了模型的拟合优度(goodness of fit)和复杂度(complexity),它们的定义如下:
AIC=-2(log-likelihood)+2·r
BIC=-2(log-likelihood)+log(n)·r
(4)
其中,log-likelihood是模型的对数似然值(拟合优度的度量),r是模型的参数个数(复杂度的度量),n是数据集的样本个数。AIC和BIC的值越低表示模型越好。与AIC相比,BIC对模型复杂度的惩罚效果更大,为此在GAMs的模型拟合中,我们选用BIC作为最优模型选择指标。
(一)索赔频数模型


+β1VehGasRegular
+f2(DrivAge)+f3(BonusMalus)
+f4(logDensity)
(5)
上述模型中包含了两个分类变量:汽油类型(VehGas)和汽车类型(VehBrand),以及四个连续型变量:车龄(VehAge)、驾驶员年龄(DrivAge)、奖惩系统(BonusMalus)和对数人口密度(logDensity)。

由此得到索赔频数的最终预测模型形式为:
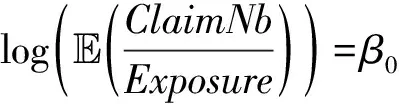
+f1(VehAge)+f2(DrivAge)
+f3(BonusMalus)+f4(logDensity)
+f5(VehAge,BonusMalus)
(6)
索赔频数模型的具体拟合情况见表2。

表2 索赔频数模型(GAM)的参数估计
根据图2,在车龄(VehAge)方面:当汽车处于 [0,2]的年龄区间时,刚买新车的平滑效应最大,随着车龄增大,平滑效应在不断下降。当车龄位于 [2,5]区间时,随着车龄增大,平滑效应增加。当车龄处于 [5,20]区间时,平滑效应再次呈现下降趋势,并在20年时达到了最低谷,说明驾驶员车龄越大,驾驶技术越熟练,预估索赔频数降低。
在驾驶员年龄(DrivAge)方面:当驾驶员年龄处于 [18,30]区间时,随着年龄增大,平滑效应在不断下降,在30岁达到最低谷。当驾驶员年龄处于 [30,40]区间时,随着年龄增大,平滑效应不断增加,但整体数值小于0。在 [40,50]区间内,随着年龄增大,平滑效应在不断增加,并且大于0。[50,60]区间内平滑效应有一个小幅下降。60岁以后,再次呈现增加趋势。
奖惩系统(BonusMalus)的平滑效应随着奖惩水平的提高呈现增长趋势,这与我们的直觉相一致:BonusMalus越低表明驾驶员的索赔历史记录越好,越高表明索赔越多。

图2 索赔频数模型(GAM)的平滑效应展示
对数人口密度(logDensity)的平滑效应随着人口密度的增加呈现稳定的增长趋势,这也十分直观:人口密度越大,该地区发生交通事故的可能性也越大,索赔次数也就越多。
车龄-奖惩系统(VehAge-BonusMalus)的效应区域图中浅灰色表示负相关性,深灰色表示正相关性。高车龄-低奖惩系统、低车龄-低奖惩系统和低车龄-高奖惩系统组合的风险更低一些,而高车龄-高奖惩系统的风险更高。
(二)索赔强度模型
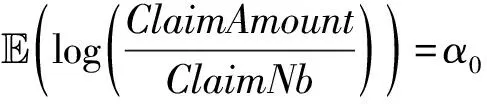
+g2(BonusMalus)
+g3(DrivAge,BonusMalus)
(7)
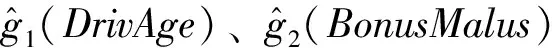
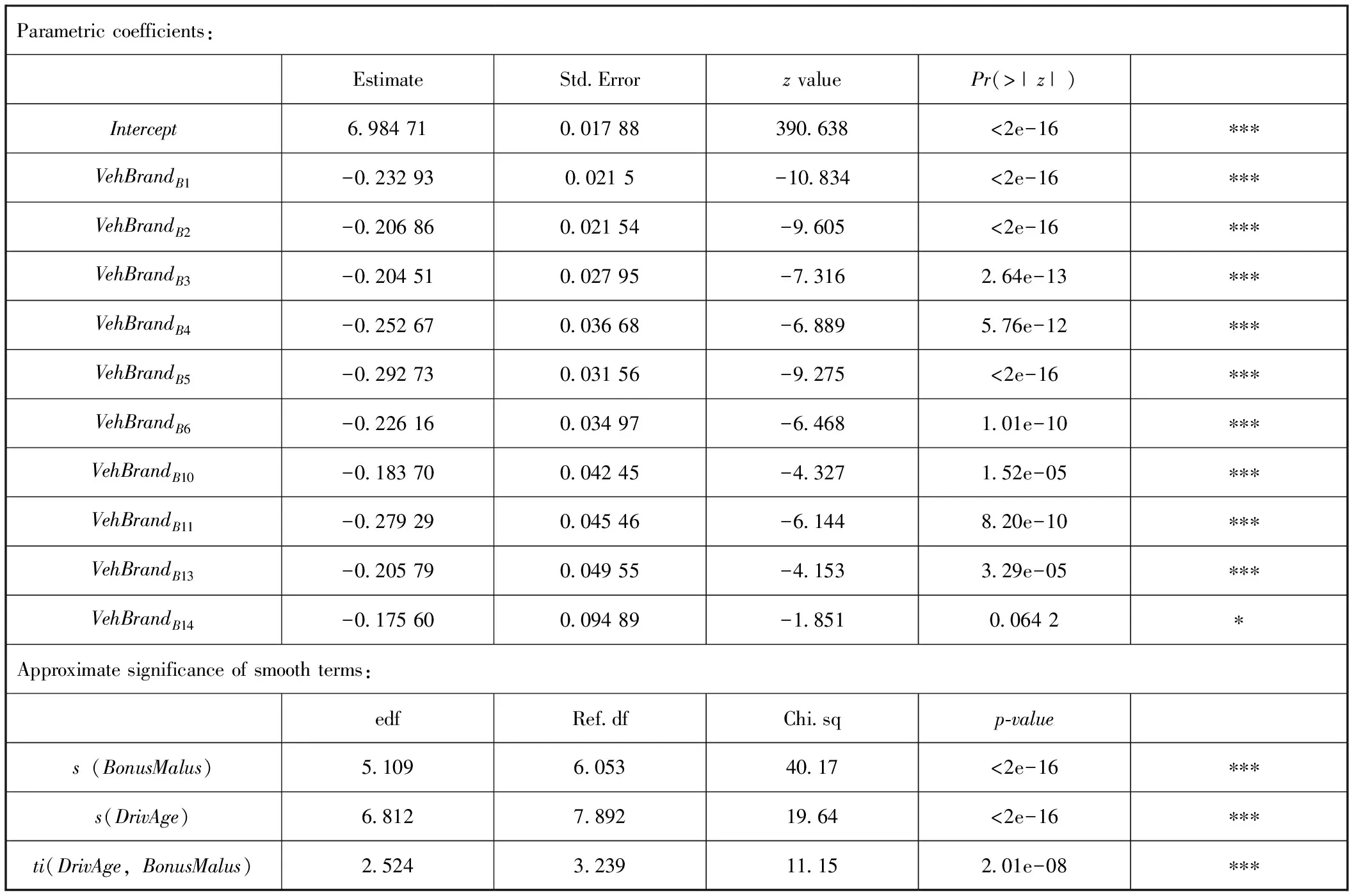
表3 索赔强度模型(GAM)的参数估计
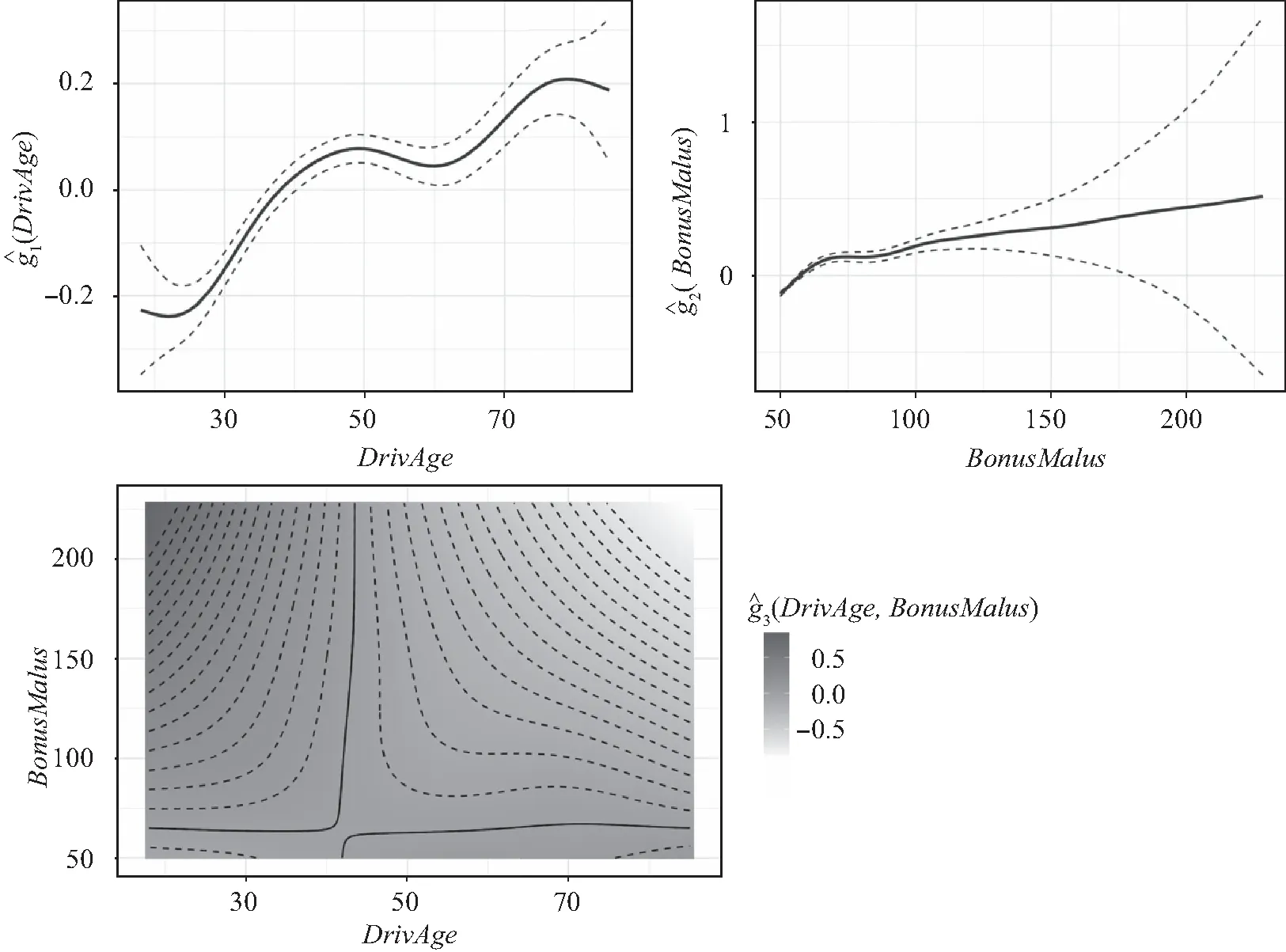
图3 索赔强度GAM平滑效应展示
从驾驶员年龄(DrivAge)角度:在 [18,50]的年龄区间,随着驾驶员年龄增加,索赔强度平滑效应整体呈现增加趋势。年龄处于 [18,40]区间时,平滑效应小于0。[40,50]区间内,效应大于0。在 [50,60]区间,平滑效应有一个下降趋势。60岁以后,随着驾驶员年龄增加,平滑效应再次呈现上升趋势。
奖惩系统(BonusMalus)的平滑效应随着奖惩水平的提高呈现增长趋势,这与我们的直觉相一致:BonusMalus越低表明驾驶员的索赔历史记录越好,越高表明索赔越多。
由图3可知,在驾驶员年龄-奖惩系统(DrivAge-BonusMalus)方面:低驾驶员年龄-低奖惩系统和高驾驶员年龄-高奖惩系统组合的平滑效应要低于低驾驶员年龄-高奖惩系统和高驾驶员年龄-低奖惩系统组合的平滑效应,其中低驾驶员年龄-高奖惩系统组合的平滑效应最高。
五、数据驱动分箱方法构建风险保费类别
在模型拟合中,一直存在着“拟合效果——可解释性”之间的权衡。上一节GAMs的构建中包含一些针对连续型变量的平滑函数,可以捕捉到一些连续型变量的非线性效应,使得拟合效果更好,预测更加精确,但也让模型变得更加复杂和难以解释。相比于GAMs,GLMs只包含线性形式,直观简单,易于理解,但模型的拟合效果在一定程度上会有不足。在实务定价中,定价人员更加倾向于使用分类变量进行定价。在本节中,我们基于前面GAMs得到的回归预测模型,运用数据驱动的分箱方法,将连续型变量离散化,将其转化为包含少数水平的分类变量,从而构造风险保费类别。
(一)数据驱动分箱方法——进化树
1.回归树的基本介绍。

本文使用决策树进行分箱,将连续变量离散化。决策树模型是一种常用的分类与回归方法,分类树输出的结果是分类型变量,回归树输出的结果是连续型变量。本文使用回归树模型,一方面因为索赔频数和强度都是连续型变量,另一方面回归树模型对连续型变量会产生直观的连续分割,符合我们对连续变量连续值分箱的要求。
常用的回归二叉树(binary tree)方法,如CART(Classification And Regression Tree)算法等,都是以逐步向前搜索的方式建立模型的递归分割。这种方法由来已久,但CART算法的结果只是局部最优的,因为节点的选择(从而产生叶子)是在上一步的基础上,最大化下一步的结果。每个内部节点的分割规则是为了最大化其子节点的同质性,而不考虑回归树上更下一层的节点,由此只产生局部最优的树。另一种在树的参数空间上搜索的方法是使用全局最优方法,如进化算法,对应的回归树被称为进化树。
2.进化树。
进化算法的思路来自达尔文的自然进化思想:物竞天择,适者生存。进化算法是以种群(population)为基础,是个体(individual)的集合,在每一代进化过程中,个体之间彼此竞争,以评估函数(evaluation function)为指标,保留高质量的个体,淘汰低质量的个体,如此循环往复,种群的质量随着时间的推移而不断增加,得以进化。
在进化递归的每一次进程中,首先,整合上一次进化过程得到的所有个体,这些个体在该次进化过程中被称为父母个体(parent individuals)。随后,变异算子(variation operator)作用于种群中的父母个体,改变个体的结构,被改变后的个体被称为新的解决方案(solutions),也被称为子代个体(offspring individuals)。最后,生存者选择过程依据评估函数指标来衡量这些个体的质量,保留优质个体,淘汰劣质个体,得以进化。在我们的模型中,在每一代,初始的父母个体要与经过变异算子作用后产生的子代个体同时竞争,优胜劣汰,保证每一代种群的个体总数不改变。在这个进化过程中,种群的整体质量不断优化,进化算法的具体思路如表4所示。

表4 进化算法
当进化算法与决策树模型相结合时,一棵树即是个体,多棵树组成的整体是种群。进化树中共有五种变异算子:四种突变算子(mutation operators,针对单一个体)和一种交叉算子(crossover operator,针对多个不同个体)。在进化过程中,变异算子随机作用于个体,修改树的结构,产生新的后代。根据Grubinger 等(2014)[7]的做法,五种变异算子如下:
(1)分叉(split)。
随机选择一个叶子节点T,并为其分配一个有效的、随机生成的分叉规则,分叉规则由相应的分割变量x(r)和分割数值s(r)来定义。由此,被选中的叶子节点成为内部节点r,并生成两个新的叶子节点T1和T2。
(2)修剪(prune)。
随机选择一个内部节点r,它有两个叶子节点作为子节点,剪去这两个叶子节点,将内部节点r修剪成叶子节点Tr。
(3)大分割规则突变(major split rule mutation)。
随机选择一个内部节点r并改变其分叉规则,其中以50%的概率,内部节点r的分割变量x(r)由原特征空间X={x1,x2,…,xn}中的其他特征变量替代;如分割变量保持不变,则其分割数值s(r)发生变化。
(4)小分割规则突变(minor split rule mutation)。
与大分割规则突变运算类似,但它并不改变分割变量x(r),而只是将分割数值s(r)改变一个小的幅度。
(5)交叉(crossover)。
树在被变异算子作用后,需要对其质量进行衡量,我们使用的评估函数的表达式如下:
n·log(MSE)+4·α·(m+1)·log(n)
(8)

(二)由进化树构造风险保费类别
本节,我们将考虑使用前面介绍的进化树方法,对八个平滑效应进行分箱处理,得到包含少数水平的分类型变量,构造风险保费类别。
关于索赔频数和索赔强度的平滑效应分箱,我们需要分别进行估计。对于索赔频数来说,观测值的数量nfreq=678 013;对于索赔强度来说,观测值nsev=24 743。调试变量α是模型预测精度和复杂度之间的调和值,针对不同的模型,调试参数取值不同。在α选择方面,我们也是对索赔频数αfreq和索赔强度αsev模型分别计算。参考Henckaerts(2018)[11]的做法,我们对αfreq和αsev分别取不等距集合{1,1.5,2,…,9.5,10,20,30,…,90,100,150,200,…,1 200}中的值,再分别代入模型中,以BIC为指标,找到使得模型BIC最低的αfreq= 1 100,αsev=200。


图4 索赔频数模型平滑效应分箱


图5 索赔强度模型平滑效应分箱
六、保费结构分析
(一)从GAMs到GLMs
上一节我们运用了R软件包中的evtree对几个连续平滑效应进行了分箱处理,根据以上索赔频数和索赔强度的分箱结果,我们得到了连续变量分箱后的分类变量。应用这些分类变量构造GLMs,由此得到了两个模型的参数估计,见表5和表6(3)受篇幅限制,文中无法列出表5和表6的全部内容,仅列出部分参数估计,感兴趣的读者可联系作者索取。。
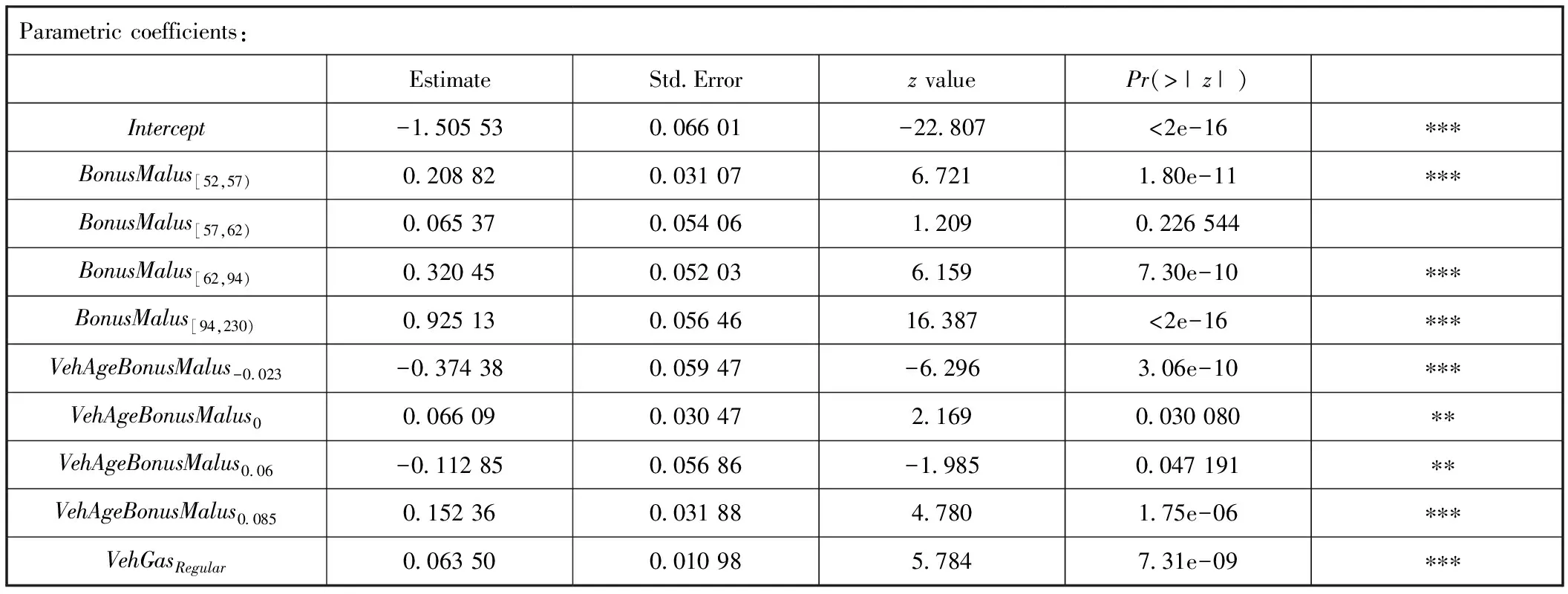
表5 索赔频数模型(GLM)的参数估计
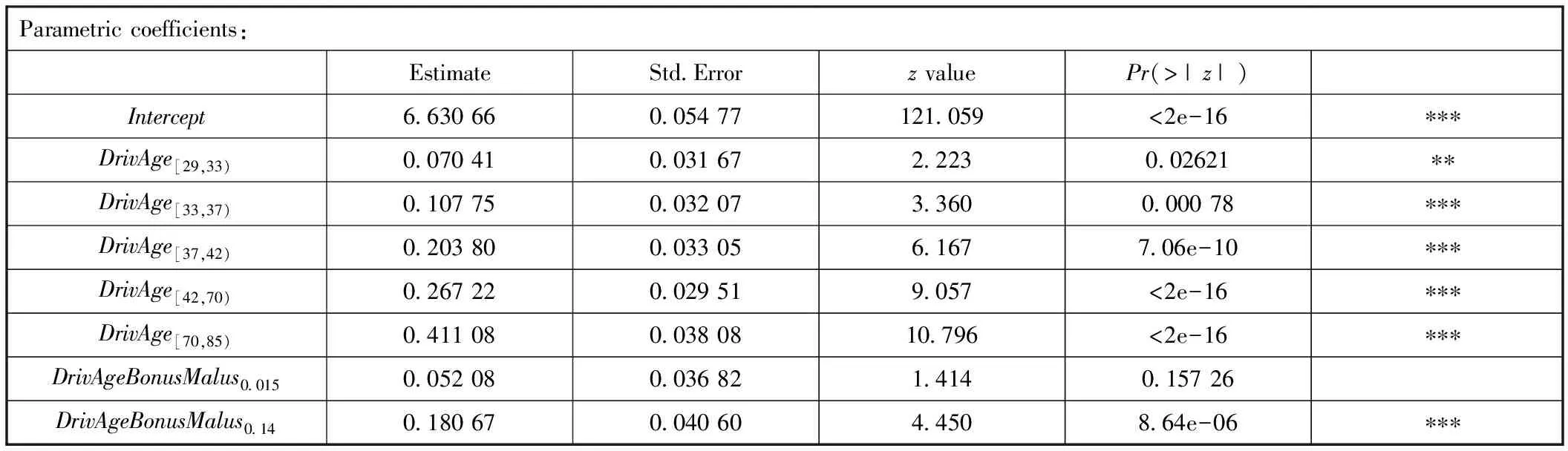
表6 索赔强度模型(GLM)的参数估计
在最优模型选择方面,以同时衡量模型拟合效果和复杂度的AIC和BIC为指标。表7列举了GAMs和GLMs下的索赔频数和索赔强度模型对应的AIC和BIC的值,从表7可知:不管是索赔频数模型,还是索赔强度模型,对应的AIC和BIC很相近。

表7 GAMs和GLMs的AIC和BIC比较
(二)纯保费分析
为每一份保单i计算纯保费πi,纯保费πi的公式如下:
πi=E(Fi)×E(Si)
(9)
其中E(Fi)是保单i索赔频数的期望值,E(Si)是保单i索赔强度的期望值。
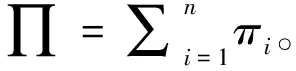
在保费预测时,我们再次对数据进行了处理,删去了那些损失特别大的极端数据,以免对模型预测产生极端影响。最终我们新生成了预测数据集FF.pred,里面包含了677 499个保单持有人的损失数据(原数据FF中包含了678 013个数据(4)为避免极端值对模型预测产生影响,我们从FF数据集中删去那些损失额大于10 000的数据,总共删去了514个数据量,新生成的FF.pred包含677 499个数据量,用于纯保费的估计。)。此时,对预测数据集FF.pred,根据以上模型,最终求得的GAM纯保费为33 942 460,GLM的纯保费为33 864 103,GLM预测的纯保费比GAM低了78 357,占比0.231%,这两个估计都略高于实际的总损失33 742 058。
就纯保费预测精度而言,GAMs和GLMs两者表现相当。就模型解释性而言,GLMs有直观的风险保费类别,更易于理解和解释;而GAMs有非线性的平滑效应,在解释方面较为复杂。
根据以上整体分析,分箱后的GLMs在拟合效果上近似于GAMs,解释性优于GAMs,以进化树分箱来构造车险风险保费类别的方法可以从多角度来优化GAMs。
七、总结
在车险定价中,广义线性模型(GLM)已经成为标准方法。对连续型自变量,很多情况下,直接应用广义线性模型,会忽略自变量的非线性效应。作为传统的广义线性模型的推广,通过引入变量的样条函数,广义可加模型(GAM)能很好地考虑到非线性效应。广义可加模型的预测精度更好,但不足之处是在实务应用中,模型的可解释性变差。在实务中传统的做法是:对连续型自变量,直接划分为分类变量,再应用广义线性模型。但这样做的不足之处在于,主观性较强,理论依据显得不足。
本文运用了数据驱动的分箱方法,对连续型变量进行分箱处理,目的是更好地建立车险定价中的风险保费类别。我们对索赔频数和索赔强度这两个响应变量,在分箱处理前后,分别建立了广义可加模型(GAM)和广义线性模型(GLM),结合这两个模型的预测值,预测了纯保费,结果发现分箱后的GLM可以用来优化GAM。
本文的思路是先对法国三责险数据freMTPL2freq和freMTPL2sev进行处理,得到索赔频数和索赔强度模型拟合的数据集FF和FF.sev。再以GAM框架为起点,构建了一组索赔频数-索赔强度模型。随后,运用决策树中的进化树算法,对连续型变量进行分箱处理,将连续型变量转化为分类变量,再构造新的GLM,得到了一组新的索赔频数-索赔强度模型,由此构造了车险风险保费类别。
模型拟合一直存在着拟合精度和可解释性之间的权衡,不断优化模型的目的之一,是用更简单的模型达到更好的拟合精度,分箱后的广义线性模型比广义可加模型更简单、更直观、易解释。经过模型预测,我们得出由广义线性模型计算出的保费,与由广义可加模型得到的结论非常接近。由此,本文研究得到了一个更简单直接的模型,可作为实务中更复杂车险定价模型的较好替代。
本文的研究结果中,模型里的定价类别并没有加入地区(Area)等空间因素自变量,但是在Fahrmeir 等(2007)[12]、Tufvesson 等(2019)[13]中考虑了地理空间因素在车险风险保费类别构造中的影响。此外,模型最终拟合中没有加入汽车动力(VehPower)自变量,而在Wüthrich(2020)[14]车险定价模型中包含了这个自变量。
本文使用的进化树算法是一种近几年才出现的机器学习算法,作者查阅了国内相关文献,未发现将进化树算法应用于车险定价的论文,本文重点介绍了进化树算法的原理及其精算应用。
近年来,大数据和机器学习技术快速发展,本文的数据驱动进化树算法不仅可应用于车险定价领域,今后也必会应用于其他领域来处理预测建模问题。数据科学对保险业的冲击和促进是必然趋势,相信在不远的未来,会有越来越多的机器学习方法被应用于精算领域。
