基于改进S-FCM和PSO算法的WSN分簇路由算法
2022-09-19孙爱晶朱开磊
孙爱晶,朱开磊
(西安邮电大学 通信与信息工程学院,陕西 西安 710121)
无线传感器网络(Wireless Sensor Network,WSN)由大量低功耗、能量有限的微型的传感器节点组成,多用于智能家居、智慧农业等场景[1-2]。传感器节点通过无线链路构建自组织网络,并将感知数据发送至簇首或者基站[3]。传感器节点能量有限且通常被随机布置在某些环境恶劣区域,对其进行充电是不现实的[4]。因此,延长网络生命周期成为当前的热门研究课题。
针对延长网络生命周期的问题,研究者们提出了许多基于簇结构的层次性网络路由协议[5-6]。文献[7]提出的经典的低功耗自适应集簇分层(Low Energy Adaptive Clustering Hierarchy,LEACH) 协议以循环的方式随机选择簇首,使各个节点都有机会成为簇首均衡网络负载。然而,LEACH协议中簇首的选举没有考虑节点剩余能量,当能量低的节点被选为簇首,会加速网络的死亡。针对LEACH协议存在簇首选举不合理的问题,文献[8]提出的LEACH-improve协议将剩余能量因子、间距因子和密度因子融入到传统LEACH阈值计算公式中,使选举的簇首更具合理性,网络生命周期得以提高,但仍会出现极小、极大簇,不利于簇内节点负载均衡。文献[9]提出了非均匀分簇协议 (Energy-Efficient Uneven Clustering,EEUC),候选簇首通过使用非均匀的竞争范围构造大小不等的簇,使靠近基站的簇的规模小于远离基站的簇,延长了网络生命周期。文献[10]将FCM算法(Fuzzy C-means,FCM)和模糊逻辑结合起来,先用FCM算法得到均匀分簇,然后结合能量、距离等因素利用模糊逻辑在簇内选举簇首,有效地均衡了节点负载,但该算法未对簇首规划路由,不利于均衡簇首负载。文献[11]使用遗传算法优化FCM的初始聚类中心以获取最优分簇,并结合节点能量及距离因子选举簇首。但在簇首轮换阶段,只说明网络系数取值过大过小都会加速网络能量消耗,并未给出最优网络系数的计算方式和实验数据。FCM算法虽然得到了均匀分簇,但在大规模节点部署环境下,由于其收敛速度缓慢,不适用于规模大且对网络实时性要求高的环境。文献[12]提出了一种基于凝聚嵌套(Agglomerative Nesting,AGENS)聚类的能量均衡WSN路由优化算法(An Energy-Balanced WSN Routing Optimization Algorithm based AGNES Clustering,EBRAA)。该算法首先使用AGENS分簇,然后结合簇内节点的剩余能量和节点与基站距离及两者权重因子,完成分布式簇首选举,最后采用改进后的Dijkstra算法产生簇首间最短路径的多跳路由。但是,并未给出最优权重的证明过程,也未考虑中继节点的负载因素,这会影响簇首选举的合理性及加速中继节点死亡。
为了改善FCM算法在网络分簇时收敛速度缓慢、簇首选举不合理和远端簇首能耗大的问题,在LEACH协议的分簇思想基础上拟提出基于改进抑制式模糊C-均值和粒子群算法的WSN分簇路由算法(WSN Clustering Routing Algorithm based on Improved S-FCM and PSO Algorithms,CRIS-FCMP)。分簇阶段,利用抑制式模糊C-均值算法的目标函数改进抑制率,使改进的抑制式模糊C-均值(Improved Suppressed Fuzzy C-means,IS-FCM) 算法既能提高收敛速度又能保持良好分簇特性;簇首选举阶段,依据簇内节点能量关系构建节点动态能量阈值选举簇首;数据传输阶段,依据中继节点具有高剩余能量、位置适中等特点设计路径选择适应度函数,并结合粒子群算法(Particle Swarm Optimization,PSO)为远端簇首搜寻最优路由路径。
1 系统模型
1.1 网络模型
为了均衡网络中节点的能耗,对网络中的节点进行分簇,之后在分簇中选举簇首,最后为簇首规划路由。涉及的传感器网络模型如图1所示。
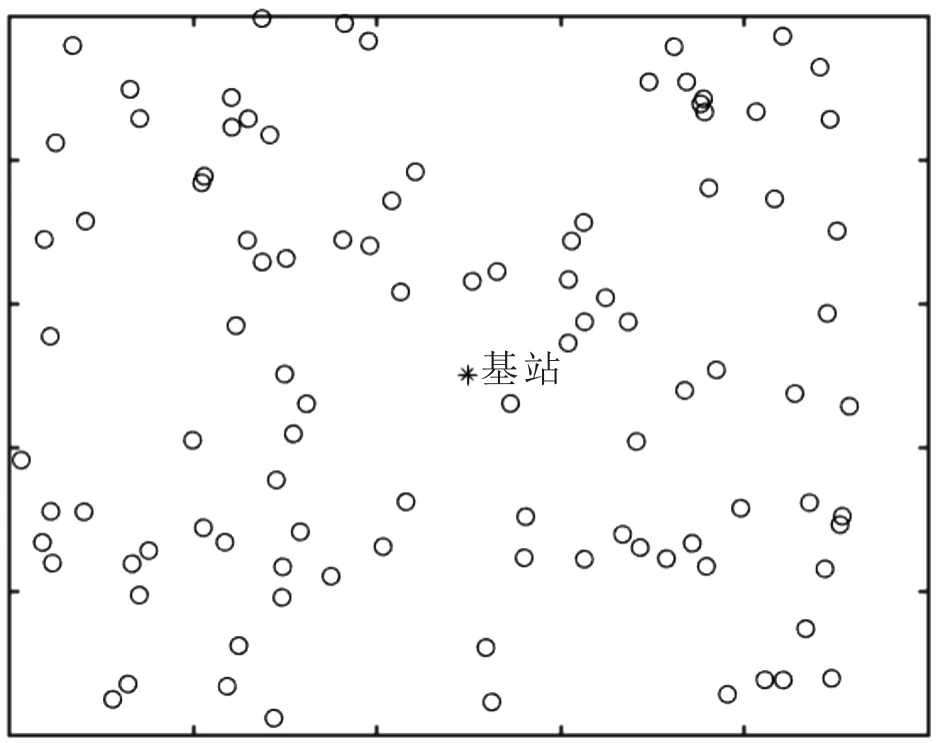
图1 传感器网络模型
图1中基站位于监测区域中心且假设具有无限大的处理能力和稳定能量供应。白圈代表传感器节点,这些节点随机布设在监测区域内,布设后将不再移动,每个节点由一个全局唯一的ID标识。此外,这些节点还拥有如下特点:所有节点初始能量相同且同构;节点能够根据接收信息的信号强度判断与发送者的近似距离,从而选取自身发射功率;节点可以感知自身位置和其他节点及基站位置,并可以周期性感知监测数据并发送至相应簇首;节点可以感知自己的剩余能量,且有存储、查询、计算和数据融合能力。
1.2 能耗模型
无线传感器网络的节点能耗主要来自于数据的收发,采用与文献[13]相同的网络能耗模型进行节点间的通信。节点信道模型的选择主要由其收发距离d决定。节点发送l位数据至距离为d的节点消耗的能量为
(1)

节点接收融合lbit数据消耗能量的表达式为
Erx=lEelec+lEda
(2)
式中,Eda表示融合1 bit数据消耗的能量。
结合网络模型及能耗模型的描述,改进路由算法将从均匀分簇选举合理簇首和为簇首规划合理路由的方向进行设计。具体路由算法的改进方案将在下文中进行详细阐述。
2 改进的抑制式模糊C-均值算法
抑制式模糊C-均值S-FCM(Suppressed Fuzzy C-means,S-FCM)算法[14]由范九伦于2003年提出,S-FCM算法是FCM算法[15]的拓展。考虑该算法具有快速收敛和良好分类的优点,将其应用到WSN分簇中。
FCM算法是通过计算每个节点对类中心的模糊隶属度、极小化FCM的目标函数得到最优分簇。FCM目标函数表示为
(3)

(4)
(5)
由于FCM算法迭代速度慢,在大规模节点集合环境下,聚类需要消耗大量时间。通过对隶属度进行合理的修正,可以保证合理分类的同时加快算法收敛速度。对每一个节点xj,节点j在所有类中的最大隶属度的表达式为
则最大隶属度和其他隶属度的修正表达式分别为
(6)
Uij=αuij(i≠p)
(7)
式中,0≤α≤1,表示抑制率。对FCM的隶属度进行抑制的算法称为S-FCM。当α=0时,S-FCM变为HCM,即K-means算法;当α=1时,S-FCM变为FCM算法。α作为HCM与FCM之间的折中因子,通常α取值为0.5。为了达到更快分类目的,采用不固定抑制率α的机制,第r轮的改进抑制率和改进抑制式模糊C-均值算法目标函数表达式分别为
(8)
(9)
式中:JIS-FCM(r-1)和JIS-FCM(1)分别为改进抑制式模糊C均值算法的第r-1轮与首轮目标函数;α(r)表示第r轮的抑制率。通过式(8)可以看出,抑制率α每轮随着上轮的目标函数变化而变化。当分类不合理时JIS-FCM值较大,通过式(6)与式(8)可知,每个节点最大隶属度的奖励降低,进而减慢了节点向自身所在类的收敛速度,算法性能向FCM靠近;当节点分类趋于合理时,JIS-FCM变小,α变小,此时增加了对每个节点最大隶属度的奖励程度,节点向自身所在类的收敛速度加快,算法性能向HCM靠近。通过以上分析,IS-FCM算法根据分类情况动态地调整抑制率,从而使节点根据分类情况对聚类中心的“吸引力”作实时动态变化,在保证合理分类的同时,加快算法收敛速度。
IS-FCM聚类算法步骤如下。

步骤2依据式(3)计算第r轮节点对各聚类的隶属度ur。
步骤3结合步骤2得到的隶属度ur,依据式(6)、式(7)和式(8)计算修正后的隶属度。


具体的IS-FCM聚类算法的流程如图2所示。

图2 IS-FCM聚类算法流程
3 CRIS-FCMP算法
为了加快网络分簇速度和降低簇首传输数据能耗,提出了基于改进抑制式模糊C-均值和粒子群算法的WSN分簇路由算法CRIS-FCMP。
3.1 簇的形成
网络初始化阶段,基站首先为监测区域的每一个节点分配唯一的通信ID,然后各个节点将自身的剩余能量、位置坐标发送给基站,基站获得节点信息后进行分簇,最终将分簇信息广播至各节点,广播信息中包含簇ID、节点与基站的距离。
合理的分簇数目能够进一步均衡无线传感器网络节点的负载,因此采用文献[11]计算最优分簇数目,最优簇首数目表达式为
(10)
式中:M表示监测区域的边长;dBS表示簇首到基站的平均距离。由式(10)得到最优分簇数后,将监测区域内的节点视为分类对象,采用改进抑制式模糊C-均值算法进行节点的分簇。此外,随着网络的运行,存活节点数目不断下降,网络特征发生了变化,当初的最优簇首数不再适合网络状态。因此,CRIS-FCMP算法在每轮结束时,基站会根据式(3)计算最优簇首数,当最优簇首数改变时,利用IS-FCM算法进行重新分簇,直至分簇数为1。动态分簇避免了因节点死亡造成的分簇不均匀,从而均衡了簇内负载,延长网络生命周期。
3.2 簇首选举
簇首担任簇内节点数据的接收、融合和转发任务,较簇内节点每轮消耗更多能量。为了均衡簇内节点的负载,选择一个剩余能量充沛,距离聚类中心较近的节点作为簇首,以均衡簇内节点负载,延长网络生命周期。
首先,为了保证选举的簇首能量充沛,设计了节点动态能量阈值,当节点剩余能量大于其动态能量阈值时,该节点当选为簇首。节点动态能量阈值主要由动态权重和簇内平均剩余能量组成,动态能量阈值和动态权重表达式分别为
θ(i)=F(i)Ecluster_avg
(11)
(12)
式中:Ecluster_avg表示簇内节点平均剩余能量;Emax表示节点i所在簇的最大节点剩余能量;Eres(i)表示节点i的剩余能量。Ecluster_avg作为阈值基数可避免选举簇首的能量太低,此外,为了降低簇首能量与簇内节点能量的差距,利用节点i的剩余能量Eres(i)和Emax构造F(i)作为动态权重。由式(11)与式(12)可以看出,当Eres(i)与Emax的值相差较小时,θ(i)变小,节点i当选为簇首的概率变高。
簇首拥有充沛合理的剩余能量很关键,但仍需要考虑簇首与聚类中心的距离以均衡簇内节点负载。因此,根据簇内节点与聚类中心的距离,按从小到大的顺序比较节点i的剩余能量Eres(i)与节点动态能量阈值θ(i)的大小,当Eres(i)≥θ(i)时,节点i选为簇首,否则进行下一节点的比较,直至选举出簇首,若簇内没有符合条件的节点,选择簇内拥有最大剩余能量的节点作为簇首。
3.3 数据传输
分簇阶段完成后,簇内节点采用时分多址(Time Division Multiple Access,TDMA)协议将数据发送至簇首,然后簇首再将接收的簇内数据融合并发送至基站。但是,随着节点间距离的增大,数据传输能耗按指数级增加[16]。为了减轻簇首因长距离传输数据消耗的能量,实现网络能耗均衡,对簇首进行路由规划。
针对数据传输阶段均衡簇首负载的问题,已有的算法[17-18]都是通过簇首到簇首的转发形式均衡簇首负载,虽然能够减轻远端簇首的负载,却加剧了靠近基站的簇首的负载。因此,利用PSO算法为簇首规划最优路由路径,以降低簇首被选为中继节点的概率。
PSO算法[19]是Eberhart和Kennedy于1995年提出的多目标优化算法。考虑其能有效解决大规模的非线性问题,将该算法应用到簇首路由路径规划中。算法中每一个粒子可以看作问题的一个可行解,根据适应度函数可以计算出每个粒子的适应度值,从而得到全局最优位置G和局部最优位置P,即规定粒子适应度值越小则对应的解越优。根据全局最优位置和局部最优位置,粒子的速度更新和位置更新的表达式分别为
Vi(t+1)=ωVi(t)+c1rand1[Pi(t)-Xi(t)]+
c2rand2[G(t)-Xi(t)]
(13)
Xi(t+1)=Xi(t)+Vi(t+1)
(14)
式中:c1,c2为学习因子,通常取2;Vi(t)表示第i个粒子第t代的速度,|Vi(t)|∈[vmin,vmax],ωmax和ωmin分别表示设置的最大、最小权重;Pi(t)表示第i个粒子在第t代自身搜索到的最好位置;G(t)表示第t代时所有粒子搜索到的最优位置;Xi(t)表示第i个粒子第t代的位置;rand1,rand2为0~1之间的随机数;ω为惯性权重系数。为了提高PSO算法的寻优能力,ω采用文献[20]的非线性自适应惯性权重系数,表达式为
ω=
(15)
式中:fmin,fmax,favg分别表示本轮粒子群的最小、最大和平均适应度值;f(i)表示第i个粒子的适应度值。
在利用PSO算法进行簇首路由寻优之前,需要确定路由跳数,为了能够进一步均衡簇首负载,根据最佳传输距离[21]dbest、簇首j到基站的距离dj-bs,计算簇首j经几跳将数据发送至基站,簇首j的路由跳数的表达式为
(16)
式中,round()表示四舍五入操作。
簇首路由跳数确定后,粒子的编码形式设为X={xCH,x1,x2,…,xh-1,xBS},其中:xCH,xBS分别表示簇首和基站的位置;x1,x2,…,xh-1表示簇首的随机初始中继节点位置。当PSO算法进行更新时,x1,x2,…,xh-1也进行更新,最终的最优粒子解就是簇首的最优路由路径。其他簇首按相同方法进行粒子编码。
PSO算法在为簇首规划路由时,需要一个标准评价路由的优劣,以得到最优簇首路由路径。因此,需要为PSO算法设计一个簇首路径选择适应度函数。由式(16)可知,簇首j需经hj跳将数据发送至基站,即经hj-1个中继节点。中继节点应具备以下几个特点:中继节点剩余能量应足够充沛,保证数据传输的稳定;中继节点与簇首和基站的距离要适中,以均衡簇首和中继节点的负载;簇首前向路由路径的长度要尽量的小;中继节点的选取不应局限于簇首之中,以降低簇首负载;中继节点不宜作为多个簇首的中继,以均衡中继节点负载。
根据上述几个特点,设计了路径选择适应度函数,表达式为
(17)
式中:Edelay-avg表示中继节点的平均剩余能量;Eavg表示所有存活节点平均剩余能量,中继节点充沛的剩余能量保证了数据传输的稳定;dmin和dmax分别表示簇首前向路由路径中相邻节点的最小、最大距离,两者之间差距越小,则中继节点位置越适中,中继节点负载越均衡;dCH-BS表示簇首到基站的直线距离;dtotal表示簇首前向路由路径的距离之和。节点被选为中继节点的次数定义为负载L,其值越小表示中继节点的负载越小,有利于均衡中继节点的负载。由于L的值在非零时通常大于前两项,且当其值越大时,节点多次作为中继节点的概率越小。因此,不在L因素前添加权重系数。通过分析,当froute值越小,结合PSO算法得到的簇首路由路径就越合理。
此外,随着网络的运行,中继节点的能量显得尤为重要,故定义权重系数a,b分别为
a=1-b
(18)
(19)
式中,Einit表示节点初始能量。网络初始阶段,Eavg较大,故b值也较大,路径选择适应度函数以距离因素为主;随着网络运行,Eavg变小,a值变大,路径选择适应度函数以能量因素为主。依据节点剩余能量设计的动态权重系数均衡了整个网络运行阶段的簇首路由能耗。
基于PSO的簇首路由算法步骤如下。
步骤1初始化粒子群初始位置、速度及其他参数。
步骤2依据式(17)计算粒子适应度值并依据适应度值判断全局最优解G和局部最优解P。
步骤3根据式(13)和式(14)更新粒子速度与位置。
步骤4重复步骤2和步骤3,直到最优适应度值收敛或达到最大迭代次数。
步骤5输出最优解。
输出的最优解即可解码为簇首最终路由。CRIS-FCMP算法的总体伪代码可参考附录A。
3.4 算法复杂度分析
初始化网络有k个簇首,N个无线传感器节点,从CRIS-FCMP算法的簇的形成、簇首选举和数据传输等3个阶段分析算法的复杂度。
簇的形成阶段,IS-FCM算法迭代次数为z,聚类维度为2k,因此,IS-FCM算法的复杂度为O(zk);簇首选举时遍历N个节点,复杂度为O(N);数据传输阶段,PSO算法迭代次数为z,种群规模为c,簇首数为k,那么簇首路由路径规划过程的复杂度为O(zck)。
因此,CRIS-FCMP算法每轮复杂度为O(zck),复杂度等同于算法执行所需要的基本运算次数。CRIS-FCMP算法由簇的形成、簇首选举和数据传输等3阶段组成。因此CRIS-FCMP算法每轮能在zck运算次数中得到结果,算法可行。
4 分析及其仿真
釆用计算机仿真软件对所提的CRIS-FCMP算法和LEACH-improve[8]、GAFCMCR[11]、EBRAA[12]进行仿真,并在相同的仿真环境下对算法进行对比分析,仿真参数如表1所示。

表1 仿真参数
4.1 分簇速度对比分析
为了验证IS-FCM算法的迭代速度较FCM[15]、Iα-SFCM[22]和S-FCM(α=0.5)[14]算法是否提升,在同一仿真环境和相同参数设置下,运用IS-FCM、Iα-SFCM、S-FCM(α=0.5)和FCM算法分别对100~500个节点(间隔为100)进行分簇运算。为了避免偶然性,对每次分簇的迭代次数和迭代时间分别取50次实验的平均值。IS-FCM、Iα-SFCM、S-FCM(α=0.5)和FCM算法的迭代次数、迭代时间分别如表2和表3所示。

表2 4种算法迭代次数对比

表3 4种算法迭代时间对比
从表2、表3中可以看出,在100~500个节点分簇仿真中,IS-FCM算法的迭代次数较FCM算法、Iα-SFCM和S-FCM(α=0.5)平均减少了83.6%、29.9%和-3.6%,迭代时间平均减少了81.8%、31.4%和9.3%。IS-FCM算法的收敛速度较FCM算法显著提高,这得益于IS-FCM算法采用了自身的目标函数构造抑制率,通过上轮的分簇效果反馈给抑制率,对最大节点隶属度进行了奖励,而抑制了其他隶属度,加快了节点向自身所在类的收敛速度。IS-FCM迭代次数高于S-FCM(α=0.5)算法,是因为S-FCM(α=0.5)算法一直处于奖励最大隶属度的状态(α=0.5),即一直处于加快收敛的状态,而IS-FCM根据分簇效果动态调整抑制系数,收敛速度忽快忽慢,但分簇效果要比S-FCM(α=0.5)的好。由于Iα-SFCM算法未对噪声及最大隶属度低于0.5的节点进行隶属度的修正,收敛速度要低于IS-FCM算法。
4.2 分簇效果对比分析
4.1节已经验证了IS-FCM较FCM、Iα-SFCM和S-FCM(α=0.5)算法收敛速度显著提高,但分簇的合理性同样重要,那么在同一条件下,对FCM算法、S-FCM(α=0.5)、Iα-SFCM和IS-FCM算法的分簇进行了仿真,分簇结果分别如图3(a)至图3(d)所示,图中实心点表示分簇中心,空心点表示分簇成员。

图3 4种算法分簇效果
比较图3(a)、图3(c)和图3(d),可以发现IS-FCM与FCM算法和Iα-SFCM算法的分簇效果几乎相同,从表4中可以看出其簇成员方差数区别不大,也未出现极小极大簇。虽然图3(a)、图3(c)的分簇效果相似,从以上分析中可以发现Iα-SFCM算法的收敛速度要比FCM算法快。因此,Iα-SFCM算法要优于FCM算法,然而IS-FCM算法收敛要快于Iα-SFCM算法,这说明IS-FCM算法比FCM与Iα-SFCM算法收敛速度快的同时保持了均匀分簇的良好特性。
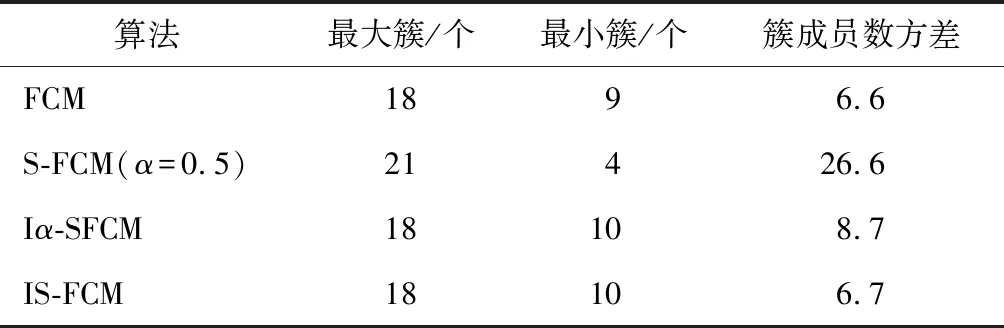
表4 簇成员数对比
对比图3(b)和图3(d),可以明显看出图3(b)中的左右两侧出现了极小、极大簇,说明S-FCM(α=0.5)算法的分簇没有IS-FCM算法的合理。这主要由于S-FCM(α=0.5)采用了固定的抑制率,不能根据分簇情况对抑制率做出实时调整,导致了S-FCM(α=0.5)算法盲目的奖励节点最大隶属度,虽然加快了算法收敛速度,但容易使算法陷入局部最优,而IS-FCM算法则利用分簇效果动态调整抑制系数,加速收敛的同时避免算法陷入局部最优。
综合仿真分析,IS-FCM相较于FCM、Iα-SFCM和S-FCM(α=0.5)算法收敛速度得到提升的同时,仍然保持了良好的分簇特性。IS-FCM的快速良好分簇特性使其可以应用于对实时性要求高的网络中,特别是大规模网络环境中。
4.3 网络生命周期
将CRIS-FCMP算法分别与LEACH-improve、GAFCMCR和EBRAA算法进行节点存活数量变化的仿真比较,相关参数如表1定义,网络生命周期对比结果如图4所示。经仿真得出,CRIS-FCMP算法首节点死亡时间出现在第1 025轮,而LEACH-improve、GAFCMCR和EBRAA算法首节点死亡时间分别出现在第472、第700和第715轮。因此,CRIS-FCMP算法较LEACH-improve、GAFCMCR和EBRAA算法分别提高117.2%、46.4%和43.3%。
图4给出了CRIS-FCMP算法与其他3个算法的网络生命周期的具体情况,从图4中可以看出,CRIS-FCMP算法的生命周期明显大于LEACH-improve、GAFCMCR和EBRAA。LEACH-improve、GAFCMCR和EBRAA算法分别大约在900轮、900轮和1 000轮,仅剩1/5存活节点,而CRIS-FCMP算法此时仍未出现节点死亡的情况,说明了CRIS-FCMP算法有效地延长了网络生命周期。此外,CRIS-FCMP算法第一个节点死亡后,节点死亡趋势陡直,说明了该算法有效地均衡了节点的能耗。

图4 网络生命周期对比
4.4 网络能耗
无线传感器网络生命周期的延长主要由节点能量消耗的快慢决定。图5为LEACH-improve、GAFCMCR、EBRAA和CRIS-FCMP算法的节点能量剩余对比结果。

图5 节点剩余能量对比
从图5中可以看出,在整个网络生命周期中,CRIS-FCMP算法的节点剩余能量始终高于LEACH-improve、GAFCMCR和BERAA算法,说明CRIS-FCMP算法降低了每轮节点的能量消耗,从而能够延长CRIS-FCMP算法的网络生命周期。这主要得益于均匀的网络分簇均衡了簇首的负载;其次簇首的选举考虑了与簇内其他成员的距离的均衡性,降低了簇内其他节点的能耗,簇首的选举还考虑了与平均剩余能量和最大剩余能量的关系,降低了低能量节点选为簇首的概率。最重要的是CRIS-FCMP算法为簇首规划了路由,且考虑了中继节点的合理性,进一步均衡了簇首的负载,而EBRAA算法虽然为簇首规划了路由,但中继节点仅在簇首中选取,且未考虑中继节点的负载因素,加剧了簇首能耗。
5 结语
为了提升FCM算法的收敛速度使其可应用于大规模且对实时性要求高的网络环境,并延长无线传感器网络生命周期,提出了CRIS-FCMP算法。簇的形成阶段,采用改进SFCM算法进行网络分簇,以进一步提升网络分簇时的收敛速度。簇首选举阶段结合簇内节点的剩余能量关系设计节点动态能量阈值,并参照距离顺序选举簇首。数据传输阶段,依据中继节点能量、距离及负载因素结合PSO算法搜寻簇首路由。仿真分析表明,网络分簇阶段所用的IS-FCM算法相对FCM、S-FCM-(α=0.5)算法能够有效提升合理分类的收敛速度。此外,CRIS-FCMP算法相对已有算法能够有效均衡节点负载,延长网络生命周期。
无线传感器网络生命周期还受到其他因素的影响,比如移动基站环境下的网络路由规划、三维网络的拓扑变化等,此类影响因素的问题有待进一步研究。
