基于SSD 算法的口罩佩戴检测模型*
2022-09-17卢云聪
卢云聪
(铁道警察学院智慧警务研究中心,河南 郑州 450000)
新冠病毒主要是通过呼吸道飞沫进行传播,当新冠患者说话、咳嗽、打喷嚏时,飞沫会进入空气,对其他人的健康造成安全隐患。佩戴口罩可以有效减少飞沫传播的途径,同时可以降低自身的飞沫量和飞沫喷射速度,进而降低新型冠状病毒的传播和感染风险。目前,为有效应对新形势下的疫情防控工作,各省市新冠疫情防控指挥部均要求乘客乘坐公共交通及列车必须佩戴口罩。
在地铁、车站这种人流量巨大的公共场所,如何快速对每位旅客的口罩佩戴情况进行检测是防疫工作的一大重点,目前该工作通常由众多驻站民警及工作人员人工筛查完成。但随着铁路以及公共交通客流量的恢复和增加,单纯依靠人力很难实现对全部乘客的口罩佩戴情况进行监督,同时大量人力的投入也会造成资源的浪费,影响防疫工作的整体效率[1]。而采用口罩佩戴检测模型能够有效帮助工作人员在极短的时间里对所有入站旅客的口罩佩戴情况进行检测[2]。
目前,目标检测主流的算法主要是two-stage 方法和one-stage 方法[3]。其中two-stage 方法的主要思路是通过CNN 在图像上生成候选框并对所有候选框进行回归与分类,其优点是准确率高,缺点是速度慢,例如R-CNN 算法;one-stage 方法的主要思路是以不同的长宽比均匀密集地在图像进行抽样,然后利用CNN 提取特征后直接进行分类与回归,其优点是识别速度快,缺点是训练困难、准确率较低,例如YOLO 和SSD。
根据口罩佩戴检测任务即时性的要求,本文采用识别速度较快的SSD 算法来搭建口罩佩戴检测模型,为解决SSD 算法低级卷积层数少导致的特征提取不充分以及正负样本不均衡导致的准确度低问题,本文在SSD 算法的基础上加入one-hot,以此来在保证识别速度的同时提高识别的准确度。
1 SSD 目标检测模型
单发多边框检测器,简称SSD,属于端到端目标检测方法的一种,与R-CNN 等two-stage 目标检测方法相比,其最大的不同是它可以省略一阶段的候选区域生成步骤,也就是说,SSD 算法可以直接对输入的图像进行特征提取,以此来对图像中的所有物体进行种类和位置上的预测,也正是因为这一特点,SSD 模型的训练成本得到了降低,检测速度得到了提高[4]。
SSD 算法是在VGG16 算法的基础上做了以下修改所得:①移除全部Dropout 层以及全连接层FC8;②分别将全连接层FC6 和FC7 转换成3×3 卷积层Conv6 和1×1 卷积层Conv7;③将池化层pool5 由原来的2×2 变成3×3 ,同时步长由stride=2 变为stride=1;④增加了Atrous 算法;⑤在网络末端新增了4 层卷积层,以便于获取更多的特征图以用于检测目标。
SSD 的网络结构如图1所示。
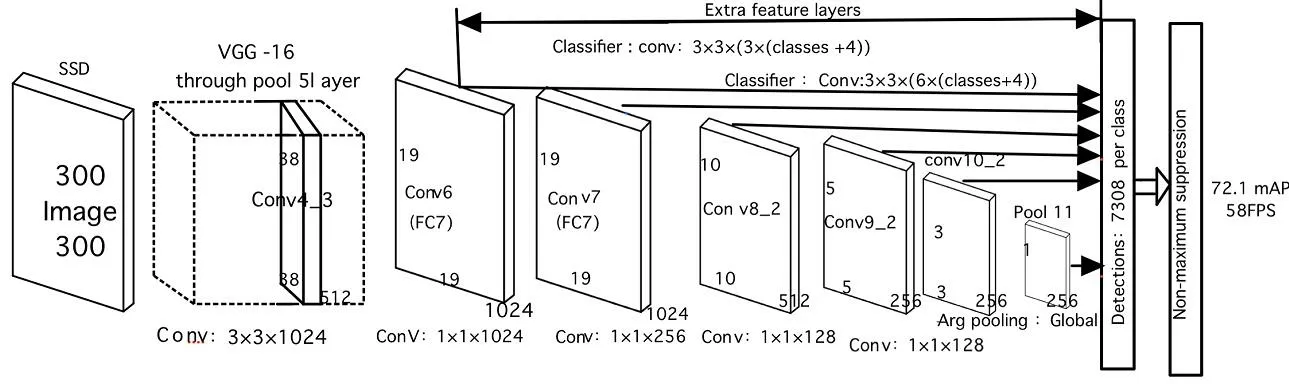
图1 SSD 网络结构图
SSD 算法的损失函数原理与Faster RCNN 相同[5],都是由2 部分组成,分别是分类损失函数和回归损失函数,具体公式如下:
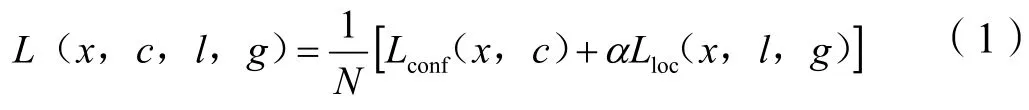
式(1)中:Lconf为置信函数,也就是分类误差;Lloc为边框定位误差。
SSD 算法通过对自身网络参数的不断训练迭代,使得分类误差和边框定位误差不断变小,最终模型对目标的定位和分类也会变得越来越准确。
与YOLO 算法相比,SSD 算法具有以下几点不同之处:①采用多尺度特征图进行检测。所谓多尺度特征图,就是大小和形状不等的特征图,其中大尺度特征图(网络中靠前的特征图)可以用来检测图像中体面积较小的目标,小尺度特征图(网络中靠后的特征图)可以用来检测图像中面积较大的目标,这就使得SSD 算法能够胜任任何尺寸目标的检测。②借助卷积层对目标进行检测。与YOLO 算法在全连接层后对目标进行检测不同,SSD 直接采用CNN 来对目标进行检测。③先验框。YOLO 算法虽然能够对每个单元生成多个正方形边界框来进行预测,但实际中真实目标的形状都是不规则的,这就要求YOLO 算法在训练中对目标的形状进行自适应调整。而SSD 算法借鉴了Faster R-CNN 中anchor 的理念,对每个单元设置大小不同的先验框,如图2所示,最终根据生成的所有先验框来产生目标的预测边界框,以此来减少模型训练的成本。
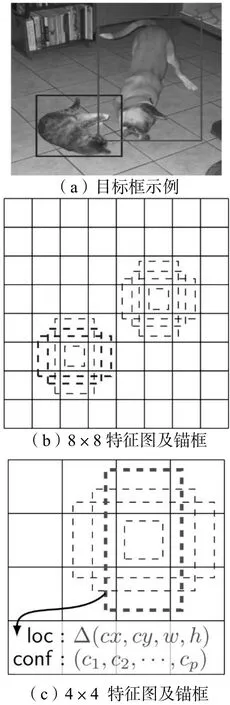
图2 SSD 先验框
2 基于SSD 算法的口罩佩戴检测模型
本文将基于SSD 框架搭建用于人脸口罩佩戴情况检测的识别模型,同时加入了one-hot 编码,并最终分别与YOLOv3 模型及未加入one-hot 编码的SSD 模型进行了检测效果对比。
2.1 数据集获取
本文对WIDER Face 数据集和MAFA 数据集进行筛选,按照佩戴口罩和未佩戴口罩图像1∶1 的比例,共选出4 568 份人脸数据。具体如表1所示。
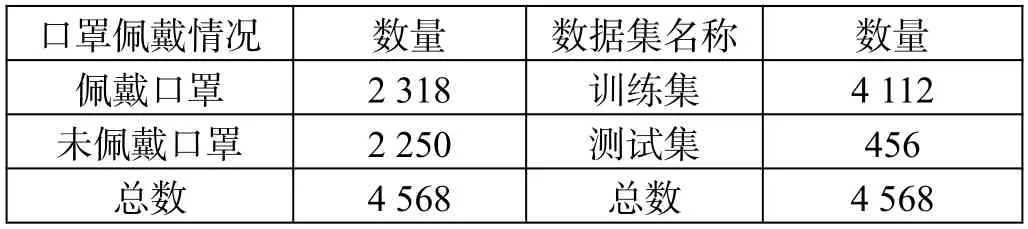
表1 实验数据集比例
其中佩戴口罩的数据共2 318 份,占数据集总数的50.74%,未佩戴口罩的数据共2 250 份,占比为49.26%。本文取总数据集的90.01%为训练集,取9.99%作为测试集。
实验数据集示例如图3所示。
图3 数据集示例
2.2 one-hot 编码
本文在传统SSD 模型的基础上加入了one-hot编码。
one-hot 编码(One-Hot Encoding)也称作“独热编码”,是数据预处理的方式之一。它采用N个状态寄存器来保存编码过程中的N个状态,每个状态都有其独立的寄存器位。
one-hot 可以使神经网络中非偏序关系的变量取值不具有偏序性,简化神经网络建模的复杂度,同时扩充了离散特征,让特征之间的距离计算更加的合理。
相比单独采用单发多边框检测器的口罩佩戴检测模型,结合one-hot 编码能够提高模型速度,使模型运算效率大幅提升,增强了单发多边框检测器自身的鲁棒性。
2.3 SSD 目标检测
本文构建的基于SSD 算法的口罩佩戴检测模型对输入图像的识别处理过程如下:①为了便于模型进行识别,在输入模型前对图片进行预处理操作,将所有图片尺寸转化成300×300;②输入图片经过SSD 模型中多个卷积层的前向传播和反向传播后,依次获得第一至第六个特征图;③将网络中提取的特征图进行综合,搭建特征金字塔,并以此来对特征图中的信息进行融合;④通过模型中的损失函数来对所有特征图中的目标进行定位和分类,并获取特征图中的检测框;⑤使用非极大值抑制法,在筛选出最佳目标检测框的同时消除其他得分较低的检测框,进而获得最终的口罩佩戴检测结果。
2.4 模型训练与测试
本文构建的基于SSD 算法的口罩佩戴检测模型具体训练步骤如下:①收集开源数据集,并按照佩戴口罩人像与未佩戴口罩人像1∶1 的比例进行筛选,分别生成训练集和测试集;②对数据集进行预处理,将所有图像的尺寸统一成300×300;③基于Visual Studio 2019 编译器和Opencv-Python4.5 中的深度学习模块设计SSD 网络,并加入one-hot 编码扩大数据的离散特征;④将训练集输入网络进行多轮迭代训练,最终生成目标检测模型;⑤将测试集输入已训练好的模型当中,测试本文所构建模型的最终识别性能。
同时,本文还在使用相同数据集的情况下,分别训练了未使用one-hot 的SSD 目标检测模型和YOLOv3 目标检测模型作为参照实验。具体实验结果如表2所示。
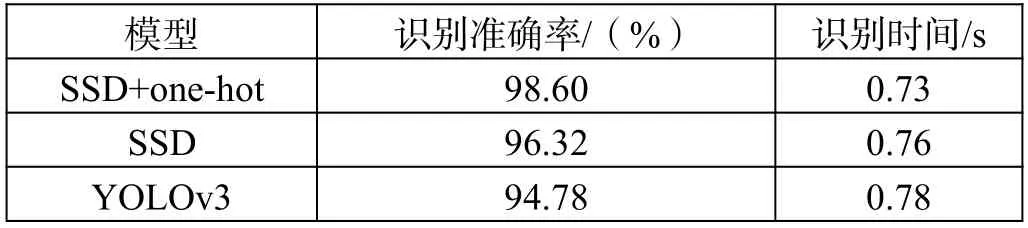
表2 实验结果
各个模型的识别准确率函数图如图4所示。
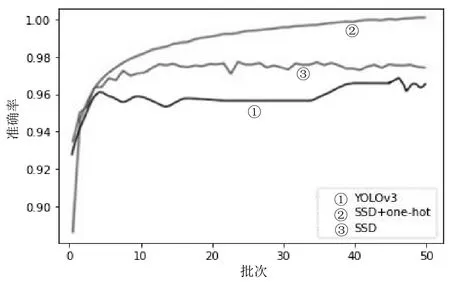
图4 各个模型的识别准确率函数图
实验结果显示:在相同实验条件下,本文构建的口罩佩戴检测模型与未加入one-hot 编码的SSD 模型相比,在识别准确率(ACC)上有着2.28%的绝对提升和2.37%的相对提升,在单张图片的识别时间(TIME)上有着3.94%的相对降低;与YOLO 模型相比,在识别准确率(ACC)上有着3.82%的绝对提升和4.03%的相对提升,在单张图片的识别时间(TIME)上有着2.56%的相对降低。
最终可以得出,本文构建的基于SSD 的口罩佩戴检测模型在识别性能方面要优于其他2 种常用模型,在准确度和速度方面能够满足检测工作的需求。
3 结语
车站是疫情防控的重要防线,确保入站乘客正确佩戴口罩,有助于深入贯彻落实国家防疫大计,保护人民群众生命健康安全。
本文使用目前在目标检测领域表现优异的SSD 算法结合one-hot 编码,搭建了口罩佩戴检测模型。经过与其他模型对比可以得出,本文构建的基于SSD 算法的口罩佩戴检测模型能够以高准确率和高速度完成对图像中人脸口罩佩戴情况的识别。将该模型投入实际应用不仅可以大大提升疫情防控形势下车站管理的智能化水准,保障车站安全,同时还可以有效缓解驻站乘警工作压力,提高工作效率。
