融合时间序列和协同过滤的学生成绩预测方法
2022-09-16单春宇张怡文吉宇洁董云春
单春宇,张怡文,张 婷,吉宇洁,褚 俊,董云春①
(1.安徽建筑大学 电子与信息工程学院,安徽 合肥 230601;2.安徽新华学院 信息工程学院,安徽 合肥 230088;3.安徽建筑大学 数理学院,安徽 合肥 230601)
0 引言
教育数据挖掘[1]是目前教育领域[2]的研究热点,教育数据挖掘能够将大量零散的教育数据转变成对教学过程更有意义的信息,通过教育类的数据挖掘技术[3-5]老师可以了解班级同学现阶段的学习情况及时地调整教学计划,分析学生的学习行为和学习动机,因材施教.学生学业成绩预测[6]是目前教育数据挖掘的一个热点话题.
由于高校学生人数的不断增加,老师不能及时了解学生的最新学习情况,可能导致学生学业质量得不到保证,达不到毕业要求.学生成绩是衡量学业质量的重要指标之一,因此,对学生的成绩进行预测是目前教育领域的重要研究方向.
目前已有相关研究者对学生学业成绩预警进行研究,如2018年河北师范大学暴延敏[7]使用支持向量机将学生的个人信息、学习成绩数据、生活作息规律以及行动轨迹构成学生成绩预测模型,预测学生的学业成绩,对挂科的学生做出及时的预警.2019年西安理工大学吴蓓[8]使用改进的C4.5决策树算法来构建期末成绩预测模型,结果表明,预测成绩是否及格的准确率达到92.49%.2021年山东大学宗鉴[9]使用深度卷积、行式卷积、列式卷积和注意力机制对学生的校园卡数据记录构建模型,来对学生成绩预测,结果表明,该方法对学生特征表示有较强的学习能力,能够准确地识别出学业落后的学生.
在本文中,使用协同过滤的方法结合时间序列对学生的课程成绩进行预测,即把学生学业成绩预测问题类比成推荐系统[10-11]的用户评价问题,把学生类比成用户,学生成绩类比成商品的评分,再按照时间序列对学生每学期的成绩进行预测.实验结果表明,通过融合时间序列和协同过滤的方法对学生成绩进行预测的RMSE(Root Mean Squared Error)、MAE(Mean Absolute Error)误差有所降低.
1 相关研究
1.1 协同过滤方法
协同过滤[12]方法可以帮助用户从海量的数据中挖掘出有用的信息,为用户进行个性化推荐[13-14],目前被广泛地应用在电商、电影、音乐、社交网络[15]等领域.算法采用用户历史评分数据,计算用户之间的相似度,根据相似度找到与目标用户Q最相似的N个用户,通过最相似的N个用户来评估目标用户Q没有评分项目的数据值,从而判断是否为用户进行推荐.
类似的,建立协同过滤成绩预测方法,以预测学生stu1的“C++程序设计”课程成绩为例.首先,用所有学生的历史成绩记录来计算学生之间的相似度;其次,通过学生相似度找到和学生stu1最相似的前N个学生;最后,通过相似的N个学生的“C++程序设计”课程成绩来预测学生stu1的“C++程序设计”课程成绩,具体过程如图1所示.
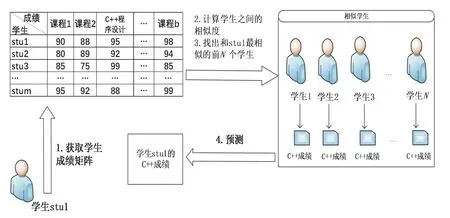
图1 协同过滤方法成绩预测
其中,学生之间的相似度是使用余弦,皮尔森等方法来计算.
1.2 基于时间序列的协同过滤成绩预测方法
由于课程之间具有较强的时间序列特征,学生对课程的兴趣也会随着时间的推移产生动态变化.传统的协同过滤方法无法解决时间序列的问题,从而导致预测成绩准确率降低.因此,本文提出一种融合时间序列的协同过滤方法进行学生成绩预测,即使用学生的第1学期课程成绩结合协同过滤方法来预测第2学期的课程成绩;再使用第1、2学期的成绩来预测第3学期的成绩;以此类推,再用第1、2、3、4、5、6学期成绩来预测第7学期的成绩,最终得到学生受时间因素变化的课程成绩.融合时间序列的协同过滤方法对学生成绩预测的流程如图2所示.
图2中,d表示第几学期,H表示学期总数目,Zd表示第d学期的成绩.
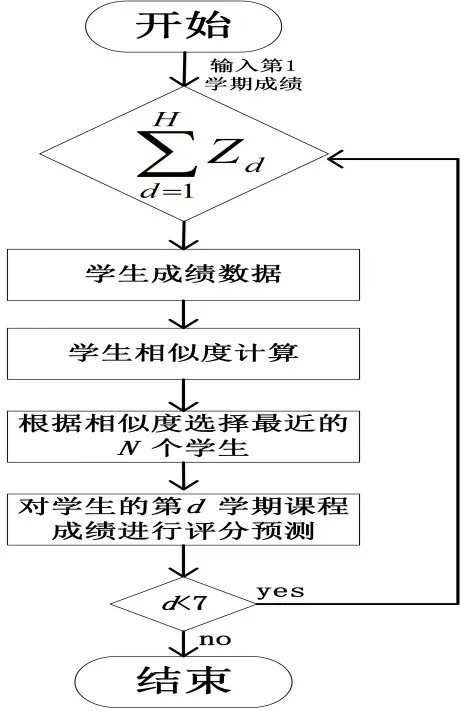
图2 融合时间序列的协同过滤方法流程图
1.2.1 学生之间的相似度计算
学生之间的相似度计算是预测学生成绩不可少的一个环节,本文采用基于用户的相似度方法.假设给定的数据集由m个用户n个项目组成,则用户的评分矩阵如式(1)所示.式(1)中,C={C1,C2,…,Cm}表示用户的集合,T={T1,T2,…,Tn}表示项目的集合,Rc1,1表示用户C1对项目T1的评分,该评分反应用户对当前项目的喜爱程度.在推荐系统中计算2个用户之间的相似度,通常使用余弦相似度和皮尔相似度来计算.

其中,皮尔相似度的取值范围为[-1,1],它反映2个评分向量之间的相关度,当取值为-1的时候,表示2个用户评分向量负相关;当取值为0的时候,表示2个用户不相关;当取值为1的时候表示2个向量正相关,计算方法如式(2)所示:

式中:P(Ci,Cj)代表用户Ci和用户Cj的共同评分皮尔相似度,表示用户Ci的平均评分,表示用户Cj的平均评分,k∈Ti,j表示用户Ci和用户Cj共同的项目.最终得到的用户相似度矩阵如式(3)所示:

其中YC1,C2表示用户C1和用户C2的相似度,1表示用户与自己本身的相似度值.
1.2.2 成绩预测
根据余弦、皮尔森等方法来计算所有学生的相似度值[16],再把得到的相似度值从大到小进行排序,选取和当前学生最相似的前N个学生作为和当前学生最相似的学生集合,最后计算当前学生的目标课程的成绩.如式(4)所示:

RCi,k表示预测学生Ci课程k的成绩,表示学生Ci的平均成绩,UN表示选取和学生Ci最相似的前N个学生的集合表示N个学生相似度值的和.
2 实验方法
本次实验设计方案分为两个部分,第一部分为传统的协同过滤成绩预测(Collaborative Filtering Grade Prediction,记为CF-G-P),第二部分为融合时间序列的协同过滤成绩预测(Based On Time Of Collaborative Filtering Grade Prediction,记为Based-T-CF-G-P).具体如下:
Step1学生成绩数据划分训练集和测试集.
Step2计算基于学生的相似度矩阵.使用余弦和皮尔相似度计算基于学生的相似度.
Step3成绩预测.找出和当前学生最相似的前N个学生,然后使用式(4)预测当前学生的下一学期的所有课程成绩,然后依次预测所有学生的下一学期课程成绩.
Step4重复步骤Step1、2、3,直到2~7学期课程成绩都被预测完成.
Step5确定最相似的N个学生的取值.N范围从1~40进行迭代,重复步骤Step1、2、3、4的过程,然后选取最优的N的值.
Step6然后将融合时间序列的协同过滤和基于协同过滤的实验进行对比.
3 实验结果和分析
3.1 数据集
本文使用的数据来自安徽新华学院信息工程学院15、16、17级软件工程专业的学生成绩,这3个年级的学生培养方案相同.该数据包含学生大学四年的基础课、专业课和选修课成绩记录,第8学期为实习和论文答辩成绩,只选取1到7学期的学生成绩进行实验.学生成绩记录经过处理后一共有382个学生,50门课程,19 100条成绩记录.数据的预处理主要包含以下几个步骤.
Step1去除学生的体育课和选修课程.因为每个班的学生可能只有几个人上过该门课程,所以构成的数据比较稀疏,直接去除掉.
Step2缺失值或者多值处理.某门课程没有分数,使用平均成绩来填充该缺失值.一个学生同一门课程有2个成绩记录,以第1次考试成绩为准.
Step3等级划分.由于学生的成绩数据包含具体的成绩分值和成绩评分等级制度,因此需要进行统一的量化,才能方便后期的计算.本文主要采用5分制度,90≤S<100之间为5分,80≤S<90之间为4分,70≤S<80之间为3分,60≤S<70之间为2分,0≤S<60之间为1分;优秀为5分,良好为4分,中等为3分,及格为2分,不及格为1分.
Step4数据的合并.将每个学生的7学期的成绩进行合并为一条记录,然后将15、16、17级的所有学生成绩记录合并成一张大表.
3.2 评估指标
本次实验的评价指标用RMSE、MAE进行衡量的,它们的取值范围为[0,+∞],当误差值和真实值相吻合取值为0,反之误差越大RMSE、MAE取值就越大.RMSE的值简称为R,如式(5)所示:

式中:R表示预测成绩的均方根误差,Sg表示当前课程g的真实成绩,表示当前课程g的预测成绩,f表示预测学生stu1的f门课程数目.
MAE的值简称为M,具体如式(6)所示:

3.3 实验结果分析
本文实验共分为2组进行的,第1组:将余弦和皮尔森算法进行对比,选取最优的算法来计算学生的相似度值;第2组:根据第1组最优的值,使用基于协同过滤和基于时间序列的协同过滤方法来预测每学期的成绩进行对比.具体实验结果如下.
(1)融合时间序列和协同过滤的学生成绩预测方法,当N取不同的值时候,计算得到的RMSE、MAE效果如图3、4所示:
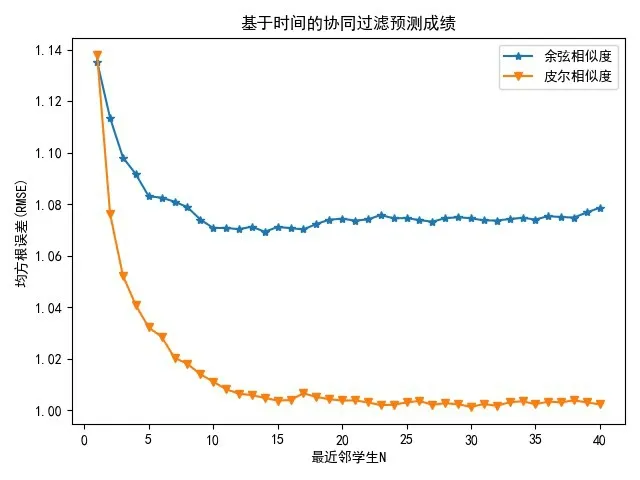
图3 CF-RMSE
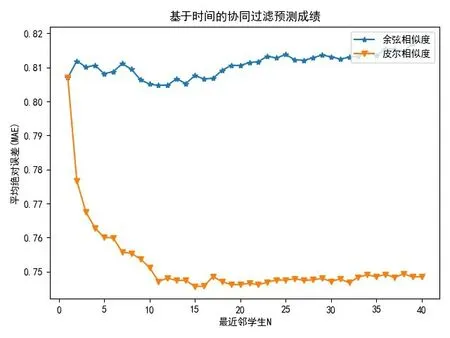
图4 CF-MAE
由图3、4可以看出,皮尔相似的计算结果比余弦相似度的计算效果要好,当最相似的学生N的取值范围为23、24、30的误差较小.
(2)当N的取值为30的时候,基于协同过滤和基于时间序列的协同过滤方法来预测的每学期整体课程的RMSE、MAE如图5、6所示:
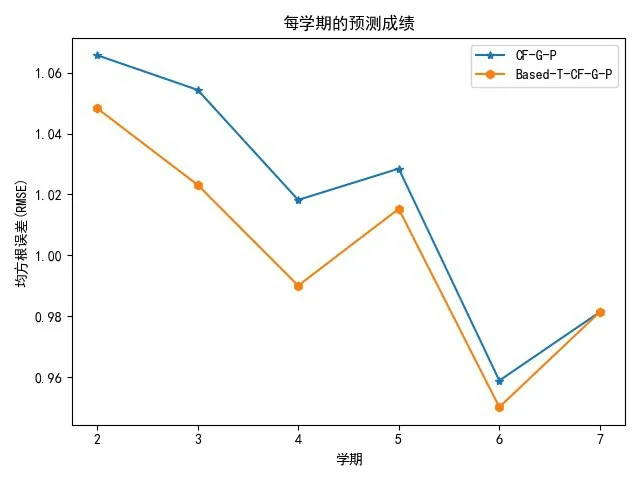
图5 按学期预测成绩的均方根误差RMSE
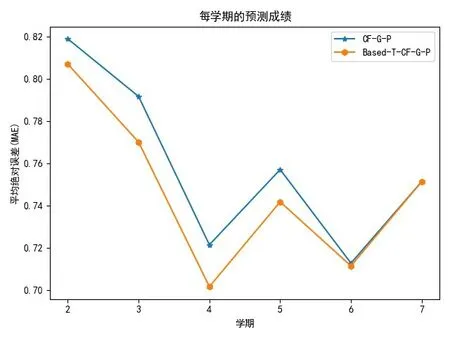
图6 按学期预测成绩的均方根误差MAE
从图5~6可以看出,在第2~6学期基于时间序列的协同过滤预测的均方根误差比基于协同过滤均方根误差低,只有在第7学期的时候重合.可能是因为随着课程数目的增加它们两个之间的误差变小.总体来看基于时间序列的协同过滤要比基于协同过滤来预测学生的课程成绩效果好.
4 总结
本文使用融合时间序列的协同过滤方法,来对安徽新华学院信息工程学院的15、16、17级软件工程专业的学生成绩进行预测.通过计算发现最近邻学生N的取值为23,24,30效果较好,当N为30的时候,可以发现融合时间序列的协同过滤计算的误差要比随机抽取的协同过滤方法来预测学生成绩效果好.但是由于本文使用的实验数据较小做出的实验还是不太理想,下一步通过增加学生的成绩数据,使用基于课程的相似度和基于知识图谱的方法来预测学生成绩.
