语义知识驱动的论文摘要关键词抽取方法
2022-09-16段建勇鲁朝阳王昊李欣何丽
段建勇 鲁朝阳 王昊 李欣 何丽
1. 北方工业大学信息学院 北京 100144;
2. 富媒体数字出版内容组织与知识服务重点实验室 北京 100038;
3. 北方工业大学CNONIX 国家标准应用与推广实验室 北京 100144
引言
当今社会信息高速发达,每天发表在社交平台上的内容不计其数,其中绝大部分都是短文本。对于时间有限的人们来说,想要快速检索自己感兴趣的内容就成了一个亟待解决的问题。关键词可以帮助读者快速了解一篇文档的主题内容,通过关键词抽取技术可以在海量的文本中将人们最关心的问题提取出来。关键词通常为一个或多个能够描述文档主题信息的词语或者词组[1]。早期文章的关键词主要靠的是人工标注,这导致关键词标注工作既费时又费力。随着计算机技术的发展,越来越多的机构和个人开始研究关键词抽取技术,已经有不少方法在关键词抽取领域取得了较好的效果。随着在自然语言处理领域对关键词抽取方法研究的逐步深入,在多项文本挖掘任务例如文本摘要、文本分类中都发挥了重要的作用。比如从最近一天所有用户发表的微博中提取出关键词,就可以知道当天人们最关心的问题。但是现有关键词抽取方法的性能依然较差,距离实际应用还有很长一段路要走。
传统的关键词抽取方法通常只关注单词出现的频率,迭代计算过程给与高频词较高的权重。但在短文本中,一些关键词低频较低,这导致了关键词的丢失。本文所采用的数据集为大量论文摘要,论文摘要符合一般短文本特征,并且对应作者所标注的关键词基本都能准确表达摘要以及文章的核心含义,因此本文以大量论文摘要作为数据集进行关键词抽取技术的研究。本文基于知网提供义原树结合词林知识构建知识图谱,并将知识融入到TextRank 方法所采用的词图模型中,使得构建的词图不仅包含词语之间的共现信息,还融入了语义知识。实验结果证明,本文所提出的方法相比传统TextRank、TD-IDF、Word2Vec 方法有一定提升。
1 相关工作
1.1 关键词抽取研究
早期的关键词抽取研究主要是基于统计的方法,对候选词的一些特征进行统计,然后根据统计的结果对候选词进行排序。包括以N-gram、TF-IDF 等指标来评价候选词在文档中的重要性。TextRank 是基于统计的图模型中最为典型的代表,首先通过词性标签筛选出文本中的候选词,其次为在同个窗口中出现的候选词之间建立边,最后赋予每个节点相同的初始值并运行PageRank 算法直至收敛[2]。SGRank使用单词的首次出现位置、词长等统计指标为候选词的边赋值[3]。
随着关键词抽取技术在文本挖掘等领域的深入应用,越来越多的学者开始从事研究相关工作。Zhang 等[4]利用“全局上下文信息”,提出基于支持向量机的任务执行方法从文档中提取关键词。Beliga 等[5]提出了一种新的基于选择性的关键字提取方法,该方法从源文本中提取以网络表示的关键字。通过加权网络计算节点选择值,将其作为权重分布在单个节点链路上的平均值,用于关键词候选排序和提取过程。Biswas 等[6]基于图模型,提出一种无监督关键词抽取方法,该方法通过综合各种影响参数来确定关键字的重要性。闫强等[7]将词语的语义信息引入到TextRank 算法中,改进了关键词抽取效果。还有学者对经典的TF-IDF 加权公式进行改进,构建一个综合考虑多种影响因素的候选关键词评分加权公式;对SharpICTCLAS分词进行改进,增加位置标注;选择评分较高的词作为候选关键词,利用词的位置标注进行关键词抽取优化操作,将“切碎”的候选关键词进行组配,形成正式抽取的关键词[8]。
回顾最近的工作,Zhang 等[9]提出了一个关键词提取框架。该框架有 2 个模块,分别是对话上下文编码器和关键词标记器。对话上下文编码器从他们的对话上下文中捕获指示性表示并将该表示输入关键词标记器,关键词标记器从目标帖子中提取显着词。这两个模块经过联合训练,以优化对话上下文编码和关键词提取过程。胡少虎等[10]通过对关键词提取方法,尤其是关键词生成方法进行总结,阐明了关键词提取方法的研究重心从特征转向数据的趋势与原因,并指出现有关键词提取评价体系所存在的缺陷。
1.2 知识图谱嵌入
近年来,知识图谱(Knowledge Graph,KG)作为一种新的知识表示方法,在问题回答、信息检索以及自然语言处理等领域有着重要的应用。知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系;其基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性键值对,实体间通过关系相互联结,构成网状的知识结构[11]。知识图谱嵌入(Knowledge Graph Embedding,KGE)是一种新的研究方向,其基本思想是将包含实体和关系的KG 组件嵌入到连续的向量空间中,从而在保持KG 固有结构的同时简化操作[12]。
Guo 等[13]首先提出了一个将由实体和关系构成的知识图谱嵌入到低纬稠密向量空间中的方法。后来他们又提出了一种新的知识图谱分布式表示学习方法——规则引导嵌入(Rule-Guided Embedding,RUGE),其借助软规则的迭代引导完成知识图谱表示学习[14]。TransE[15]是一种经典的知识表示学习方法,可以对知识图谱进行补全。其通过对头实体、尾实体及对应关系进行建模,将实体和关系都表示为同一空间中的向量,能够通过训练得到不错的低维嵌入向量。但是,它在处理一对多、多对多等关系方面存在缺陷。TransH[16]是对TransE 的改进,在一定程度上缓解了TransE 不能很好地处理一对多、多对一等关系属性的问题,在预测精度方面有了显著的改进。知识图谱嵌入已经可以有效处理各种下游任务,例如链路预测(Link Prediction, LP)[17]、关系抽取[18]和推荐系统[19]。
2 词汇知识库
2.1 义原简介
董振东花费数十年时间建立了一个汉语常识库——知网,一个可用于自然语言处理的知识系统,能解释词语概念和属性间关系的知识库。义原是知识库中不能再分割的最小的单位,在知网的知识库中每一个词语都可以使用若干个义原表示。
在知网中,并不是将每一个概念对应于一个树状概念层次体系中的一个结点,而是通过用一系列的义原,利用某种知识描述语言来描述一个概念。而这些义原通过上下位关系组织成一个树状义原层次体系。如图1 所示,知网中词语“联想”有两种意思,第一个“联想”是由电脑(computer)、样式值(PatternValue)、能(able)、携带(bring)、特定牌子(SpeBrand)组成;第二个“联想”表示精神(Mental)。知网定义了约2000 个义原,并且用这些义原表示了约10 万个中文和英文单词。

图1 联想在知网中的描述
2.2 词林简介
同义词词林是由梅家驹等编撰的汉语词库,里面归类了汉语词语的同义词和同类词。同义词词林经过哈尔滨工业大学信息检索研究室的扩展后,共有100093 个词语。如图2 所示,同义词词林的扩展板具有五层树状结构,上面四层的节点代表抽象的类别,最底层的叶子节点是具体的词条,词条的编码不唯一,可能在不同的类别中同时存在。词林根据汉语的特点和使用方式,将词语分为十二个大类。其中第一类至第三大类大多数是名词,数词和量词在第四大类中,第五类一般是形容词,第六类至第十类一般是动词,第十类多数是虚词,第十二类是其他类别词语。大类和中类的排序遵守从具体概念到抽象概念的原则。

图2 词林结构
关于词条的编码如表1 所示。前七位编码可以唯一确定一条编码,第八位编码只有三种情况:“=”代表同义;“#”代表同类;“@”代表独立,自我封闭,它在字典中既没有同义词,也没有同类词。本文所使用的词林为《哈工大信息检索研究同义词词林扩展版》1.0 版本。

表1 词林中词语的编码结构
3 融合知识的关键词抽取方法
3.1 词汇图谱的构建
受知识表示学习方法的启发,本文基于知网提供的义原树和词林知识,利用TransH模型[20]训练并建立了具有三种关系的知识图谱(HowNet and CilinE Knowledge Graph,HCKG)。三种关系分别是“同义”“同类”“是义原”。前两种关系是基于词林的表示词语和词语之间的关系,第三种关系是基于知网的表示词语和义原之间的关系。如图3 所示,“眼光(look)”和“目光(eye)”是同义关系,它们有着相同的义原。“急性(acute)”和“慢性(chronic)”是同类关系,它们有一部分相同的义原。

图3 知识图谱内的关系示例
HCKG 里面的所有关系为一个集合R={Rsym,Rsim,Rsem},Rsym和Rsim分别代表词语之间的“同义”和“同类”关系,Rsem代表词语和义原之间的“是义原”关系,例如在图3 中,“医(medical)”是词语“慢性(chronic)”的义原。图谱{Eword,Esem}里面的每个关系都由一个三元组(h,r,t)表示,h是属于Eword的一个头结点,t是属于Eword∪Esem的一个尾结点,r代表关系。损失函数定义如下:

λL是超参数,用来设置两个损失函数的权重。
3.2 融合知识的关键词抽取方法
本文基于HCKG 提供的知识表示来计算词语之间的语义信息。通过词语之间的语义信息构建语义词图,生成语义矩阵ωsim,结合词语之间的共现信息生成的共现矩阵ωco,分别赋予两者相应权重,得到新的概率转移矩阵P:

4 实验研究
4.1 实验环境和参数设置
4.1.1 实验环境
本次实验是在windows11操作系统上进行,处理器型号AMD Ryzen 7 5800H @3.20 GHz,内存16G,Python 版本3.7.11。
4.1.2 参数设置
在HCKG 中,词语、义原和关系的嵌入维度设置为800,采用Adam 作为优化器,学习率设置为0.05。由于存在未登录词的现象,如果实验中存在未登录词,将它与其他词语之间的相似度设为η。本次实验所取参数均在实验中取得了最好的效果。根据多次尝试得到的经验,公式(5)的参数α设置为0.85,η=0.4。
4.2 基准方法和数据预处理
4.2.1 基准方法
实验所采用的基准方法是TextRank,阻尼系数d 取0.85,当候选词权重迭代前后变化小于0.0001,停止迭代。
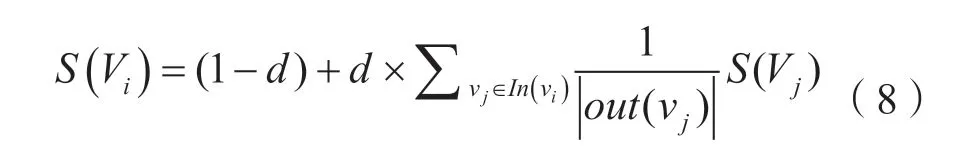
在上式中,In(Vi)代表指向节点i的节点集合,而Out(Vj)表示节点j指向的节点集合。d为阻尼系数,阻尼系数使得每个节点都有跳转至随机顶点的概率,从而避免节点无法跳出的情况,取值范围(0, 1)。
4.2.2 数据预处理
实验所使用的数据集为课题组搜集的33192篇期刊论文摘要,以及对应作者所标注的关键词,摘要一般在120 字数左右,关键词个数一般在4 个左右。相关论文所属领域主要为自然工程类,其中大部分属于工程科技类,少部分属于信息科技类和社会科学类。本文首先对期刊论文的标题和摘要进行拼接,组成一个新的短文本。拼接完成后,使用中文分词库jieba 对摘要进行分词。分词完成后剔除不需要的词,剩下的词语就是候选词。在研究了大量人工标注的关键词词性后,本次实验留下来的候选词类型有名词、动词、名动词、人名、地名、机构团体和其他专名。
4.3 对比实验
Word2Vec 方法是李跃鹏等[21]提出的一种基于深度学习工具Word2Vec 关键词提取算法,该算法首先使用Word2Vec 模型将所有词语映射到一个更抽象的词向量空间中,其次基于词向量计算词语之间的相似度,最后通过词语聚类得到文章关键词。TD-IDF 算法[22]采用TF 值和文本逆频率IDF 进行加权,根据候选词权值大小提取关键词。
4.4 评价标准
本文使用准确率P、召回率R 和F1 值作为指标来评价各种方法的效果。设w1为自动抽取的关键词集合,w2为人工标注的关键词集合,则评价指标如公式(9)、公式(10)和公式(11)所示。其中TP代表正类被判定为正类,FP代表负类被判定为正类,FN代表正类被判定为负类,Num代表个数。

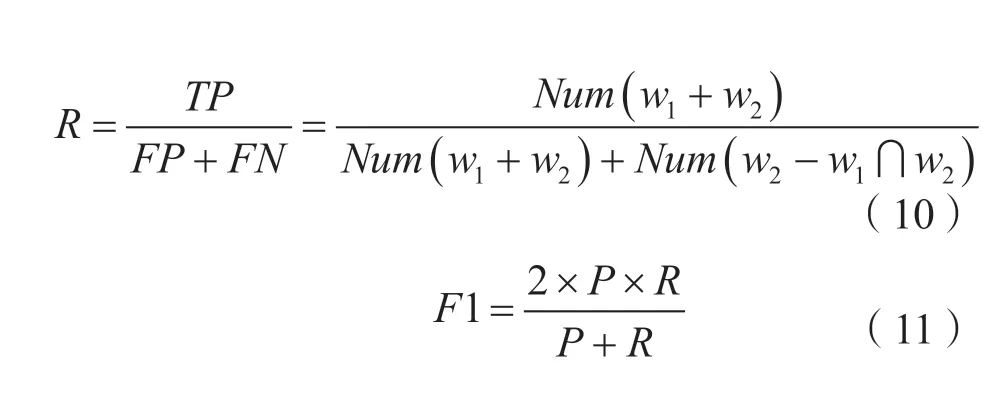
4.5 实验结果及分析
本节主要展示使用各种方法进行关键词抽取时得到的结果。如表2 所示,在抽取4 个关键词时,本文所提出的方法相比TextRank 方法F1 值提升5.9%,比TD-IDF 方法F1 值提升14.2%,比Word2Vec 方法F1 值提升65.2%。

表2 词林中词语的编码结构
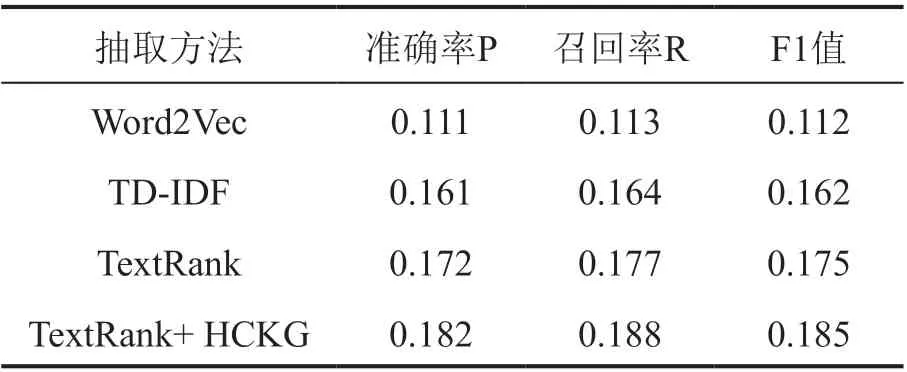
表2 抽取4 个关键词时实验结果
如表3 所示,在抽取5 个关键词时,本文所提出的方法相比TextRank 方法F1 值提升2.9%,比TF-IDF 方法F1 值提升11.4%,比Word2Vec 方法F1 值提升52.9%。

表3 抽取5 个关键词时实验结果
在抽取6 个关键词时,结果见表4,本文所提出的方法相比TextRank 方法F1 值提升2.2%,比TF-IDF 方法F1 值提升11.0%,比Word2Vec方法提升46.0%。
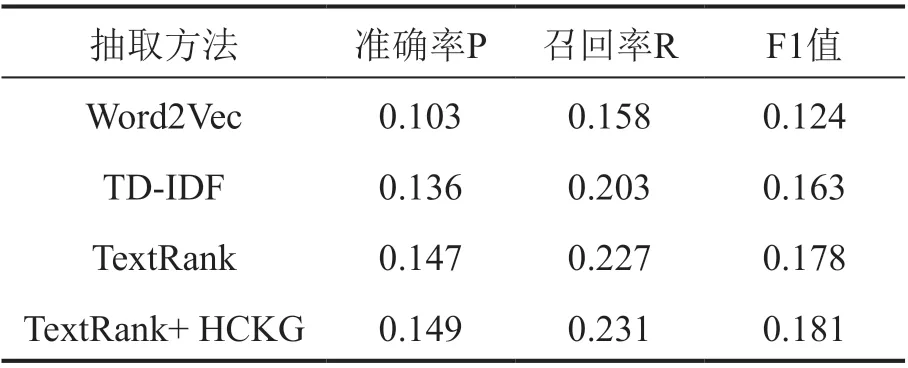
表4 抽取6 个关键词时实验结果
本文所提出的方法在抽取不同数量的关键词时效果均为最好。究其原因,论文摘要的关键词不一定为高频词汇,如果只考虑词语之间的共现信息,最终抽取结果会偏向高频词而忽略低频词。本文提出基于TextRank 算法的改进方法,在概率转移矩阵里面融入词语语义知识,赋予某些出现频率较低,重要程度较高的词语更高权重,实验证明该方法抽取效果更佳。Word2Vec 方法基于维基百科中文语料使用Word2Vec 模型训练生成词向量模型,再从中抽取候选关键词的词向量作为K-means 聚类模型的输入,选择聚类中心作为关键词。但是维基百科中文语料可能未包含某些专业或者生僻的词语,加上选择聚类中心作为文本的关键词聚类方法时,选择聚类中心作为文本的关键词本身就是不太准确的,因此使用这种方法得到的效果不佳。TF-IDF 结构比较简单,不能有效反映词语的重要程度,对于专业性稍微强一点的文本例如论文摘要抽取效果较差,所以TF-IDF方法的效果也不是很理想。
4.6 相关实例
为了更详细地展现出本文所提出方法的关键词抽取效果,表5 展示了一些示例在使用不同方法时的抽取结果示例。在例一中,本文所提出的TextRank+ HCKG 方法提取出了“试验台”和“喷油泵”关键词,其他方法只提取出了“试验台”关键词。例二同样只有TextRank+HCKG 方法提取出了“柴油机”和“增压”关键词,其他方法只提取出了“柴油机”关键词。这也证明本文所提出的方法相比其他方法,可以取得更好的论文摘要关键词抽取效果。

表5 不同关键词抽取方法效果对比
5 总结
本文基于义原树和词林知识,利用TransH模型训练并构造了知识图谱HCKG。利用知识图谱提供的知识表示计算词语的语义信息,构建语义词图,结合词语之间共现词图,生成新的概率转移矩阵进行迭代计算得到各候选词权重,最终根据权重大小提取关键词。实验证明,本文所提出的方法比传统TextRank、TD-IDF 和Word2Vec 方法有一定提升。
观察实验结果,有些常用词也出现在了其中。例如基于摘要“柴油机喷油泵试验台…在LabVIEW 环境下的实现”抽取出的关键词中,词语“采集”和“数据”被当成关键词抽取了出来。这也是课题组下一步要做的工作,根据研究目标特点建立特定词库,提高分词效率和关键词抽取效果。
