基于EMD-LSTM的冷轧煤气消耗量预测模型仿真
2022-09-16翟慧熊伟李福进杨杰
翟慧,熊伟,李福进,杨杰
(1.华北理工大学电气工程学院,河北唐山 063210;2.唐山钢铁集团高强汽车板有限公司,河北唐山 063026)
0 前言
在我国,钢铁行业作为一个重要且依赖能源的行业,如何合理利用和配置资源一直是制约它发展的重要因素。煤气是一种重要的二次能源,其回收率影响企业生产成本和环境,对企业具有重要的经济和环境意义。其中,冷轧生产过程消耗大量煤气,并且生产过程中发生大量的化学反应。煤气消耗的影响因素复杂,夹杂着周期性波动、随机扰动,这对煤气消耗量的预测带来了一定难度。在实际生产过程中,煤气的分配仅凭人工经验操作,导致煤气不能充分利用;而且煤气的突然过剩,容易导致设备熄火,并将多余煤气释放到大气中污染环境;而煤气的短缺则会导致用户停产。因此,有必要为冷轧过程设计一个有效的煤气消耗量预测模型。
随人工智能、人工神经网络的迅速崛起,支持向量机、神经网络等方法被大量用于预测。LYU等提出了一种基于灰色径向基函数(RBF)神经网络的高炉煤气量预测模型。利用灰色理论对历史数据进行预处理,获取丰富的信息,结合 RBF 神经网络,实现了30 min内有效的趋势预测。李志刚等以高炉煤气为主要研究对象,提出了一种基于LSTM与自回归差分滑动平均(ARIMA)组合的预测模型,提高了煤气预测精度。随后,又通过调试和改进建立了PSO-BP 神经网络高炉煤气受入量预测模型,实现了对煤气的合理调度和平衡调整。SUN等提出了一种基于事件驱动、机制驱动和数据驱动的混合预测方法,在预测高炉煤气量的同时考虑了高炉操作事件,使预测更加准确。徐化岩和马家琳针对钢铁企业高炉煤气系统设备工况复杂、煤气量波动频繁、难以准确预测的问题,依据小波分析方法、BP 神经网络、最小二乘支持向量机的性质建立了基于数据驱动的高炉煤气的复合预测模型。以上智能算法在一定程度上实现了预测,但在准确性和稳定性方面仍存在一些问题,并且在基于数据预测的过程中忽略了数据本身特性对预测精度的影响。
随着深度学习的快速发展,基于深度神经网络的新一代人工智能已广泛应用于各种领域。其中,LSTM是一种特殊的时间递归神经网络(RNN),能有效地保存长期记忆信息,具有良好的预测能力。NEERAJ等利用LSTM建立了电力负荷预测模型,具有较高的预测精度。ZHOU、王强等人使用LSTM预测了刀具在可变条件下的剩余使用寿命。
经验模态分解(Empirical Mode Decomposition,EMD)是一种分析非线性数据的方法,可以提取数据本质特征。HUANG等将经验模态分解用于电流信号分析。GRASSO等使用EMD技术分离了不同的频率波形。SHRIVASTAVA 和SINGH使用经验模态分解对刀具颤振信号进行了预处理。LI等将经验模态分解应用于齿轮箱局部故障诊断中的振动信号分析,发现利用经验模态分解能够更有效地检测振动信号。EMD方法解决了使用传统方法会导致有价值的信息被抛弃、复杂现象无法准确呈现的问题。
煤气消耗数据的非线性、非平稳,导致煤气消耗量难以准确预测。并且预测时需要大量的先验信息,非常耗时,时间跨度大。因此,可以利用EMD对煤气消耗数据进行预处理,提取复杂序列中的本质特征,为后续预测提供参考。凭借其独特的记忆优势和解决长时间序列相关问题的优势,LSTM可以很好地预测冷轧过程中的煤气消耗量。因此,为满足调度员的需求,本文作者建立一种基于EMD-LSTM的煤气消耗量预测模型。
1 方法及原理
1.1 EMD基本原理
经验模态分解可基于数据本身,将复杂信号分解为一系列IMF和一个(),分解信号时,不需要预先设置任何基函数。因为这一特点,理论上EMD方法可预处理任何一种信号的数据,因此被广泛应用。
()=∑IMF,+()
(1)
每个IMF分量都应满足以下2个特点:
(1)在整个时间范围内,局部极值点和过零点的数量必须相等或最多相差一个;
(2)在任何时间点,局部最大包络和局部最小包络的平均值必须为0。
IMF代表数据的固有振动模式。根据IMF的定义,IMF每个振动周期只有一个振动模式,不存在其他复杂波。作为混合序列的煤气消耗数据也可以分解为如式(1)所示的形式。分解后的IMF分量包含不同的局部特征信号。因此,利用EMD分解煤气消耗数据是可行的。
1.2 长短时记忆神经网络
LSTM在解决长时间序列相关性问题上具有独特优势,是深度学习中比较流行的方法。LSTM的内部结构由遗忘门、输入门、输出门和存储单元组成。由于其独特的“记忆”优势,LSTM网络得到了越来越广泛的应用。图1所示为LSTM的网络结构。
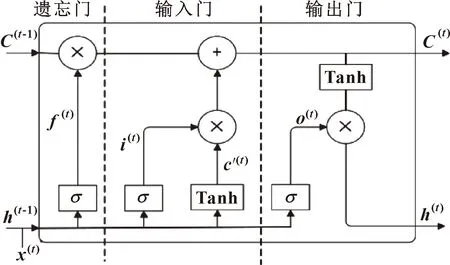
图1 LSTM结构
遗忘门决定了前一时刻的单元状态需要保留到当前时刻的程度。
()=[(-1)+()+]
(2)
输入门分为两部分:Sigmoid层决定哪些信息需要更新,并输出为();Tanh层创建候选向量′()。最后,组合这2个向量来创建更新值。数学表达式为
()=[(-1)+()+]
(3)
′()=tanh[(-1)+()+]
(4)
单元状态()是遗忘门()与上一时刻单元状态(-1)乘积和()与()乘积的和。
=(-1)⊗()+()⊗()
(5)
输出门是输出到LSTM控制单元状态的当前输出值,由Sigmoid层和Tanh层两部分组成。
()=[(-1)+()+]
(6)
()=()⊗tanh[()]
(7)
其中:为激活函数;、、、、、、、为权重;(-1)为前一个神经元的输出结果;、、、为偏置;⊗为元素乘法符号。
由于Tanh的导数大于Sigmoid函数的导数,Tanh激活函数通常用于解决RNN梯度消失问题。Sigmoid函数估计输入数据与先前隐藏状态的权重和激活,值在0~1之间,指示允许流入多少相关信息。各个门之间以特定的关系相互作用、过滤和保存信息。这种结构可以有效解决梯度消失问题。
2 基于EMD-LSTM的煤气消耗预测模型
EMD-LSTM适用于同类型的时间序列预测。首先,通过EMD从煤气消耗序列中提取煤气消耗特征,捕捉可变操作条件下的复杂时间序列关系;然后,使用LSTM研究钢板规格、轧制条件和煤气消耗的关系。如图2所示,EMD-LSTM煤气消耗预测模型主要由两部分组成。

图2 基于EMD-LSTM的煤气预测流程
2.1 基于EMD的信号预处理
使用EMD对煤气消耗数据进行预处理。具体步骤如下所示:
(1)识别煤气消耗序列()的所有极值点,用三次样条插值函数绘制()的上下包络线;
(2)求上下包络线的均值,画出平均包络();
(3)从原始信号()中减去平均包络(),得到第1个分量();
(4)确定()是否满足IMF的2个条件,如果满足,则信号为IMF分量;如果不满足,以信号为基础,重复步骤(1)—(4),IMF分量通常通过几次迭代获得;
(5)获得第1个IMF分量后,从原始信号中减去IMF1,作为新的原始信号,然后重复步骤(1)—(4),以获得IMF2分量,以此类推,直到最终残差变为单调函数,EMD分解完成。
2.2 LSTM煤气消耗量预测
文中选取某钢厂一个月的煤气消耗量,前90%的数据样本用于模型训练,后10%数据用于监测预测模型的准确性。煤气消耗的影响因素非常复杂,因此应选择主要影响因素来确定合适的输入参数。选择合适的输入可以提高煤气预测模型的有效性。
确定输入参数后,应确定LSTM的结构。考虑到模型的计算速度和预测的准确性等相关因素,进行大量测试以确定隐含层数、批次、迭代次数等参数。
在LSTM模型的构造中,使用自适应矩估计算法优化预测模型的参数。它可以更新网络的权重,动态调整各个参数的学习速率,使各个参数的更新更加独立。
各个分量预测完成后,累加每个模型的预测值,作为冷轧煤气消耗量的最终预测结果。
3 实验分析
3.1 工作条件
冷轧工艺一般包括原材料、酸洗、轧制、退火、精整等,以热轧产品作为冷轧带钢的原材料。原料冷轧前先进行酸洗,去除热轧带钢表面的氧化皮,确保产品表面清洁。冷轧是材料变形的主要过程。经过多道次轧制后可以获得所需尺寸、形状的带材。退火的目的是消除再结晶之后的硬化。精加工包括检验、剪切、矫治、分拣和包装,以获得最终产品。图3所示为冷轧工艺的整体布局。

图3 冷轧工艺布局
以唐山某钢铁企业四镀锌冷轧生产线为研究对象,采集了2020年10月的实际生产数据,数据样本4 544个。采用EMD-LSTM模型预测冷轧煤气消耗量。样本数据分为两个子集:训练集和测试集。前4 090个数据点作为历史数据训练模型,剩余的454个数据点用于评估预测性能。
3.2 煤气消耗数据特征提取
图4所示为实际生产过程中煤气的消耗情况。EMD分解可以降低变量的非线性和不稳定的影响,提取数据中包含的主要信息。信号分解EMD结果如图5所示。

图4 煤气消耗实际值
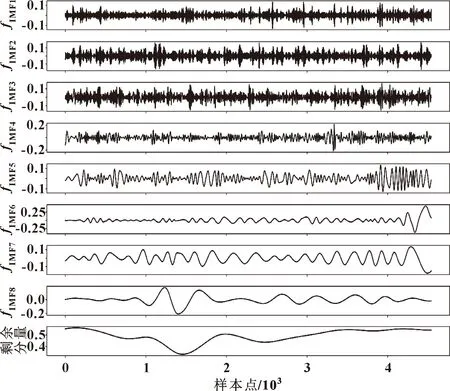
图5 基于EMD分解的煤气消耗序列
3.3 LSTM模型与训练
经分析,煤气消耗量的主要影响因素有:钢板宽度、钢板厚度、碳含量、硅含量、硫含量、磷含量、加热炉酸洗速度、加热炉酸洗温度、退火炉速度、退火炉加热段1温度、退火炉加热段2温度、退火炉均热温度。建立LSTM网络,使用12个变量作为预测模型的输入,预测各个煤气消耗量分量,模型参数采用自适应矩估计算法调整。每个分量迭代次数设置为5,批次设置为15,隐含层设置为32。
3.4 结果和讨论
为验证EMD-LSTM模型的预测能力,与BP、EMD-BP、LSTM和EMD-LSTM的煤气预测结果进行比较。
如图6和图7所示:BP模型的预测值与煤气消耗实际值差距较为明显,它只能预测煤气消耗的大体趋势;经过EMD分解提取本质特征后,煤气消耗量的预测精度大大提高,但在极值点处仍存在较为明显的误差,需要进一步改进。两种模型预测结果表明,对数据进行预处理可以在一定程度上提高模型的预测能力。

图6 BP模型煤气预测值
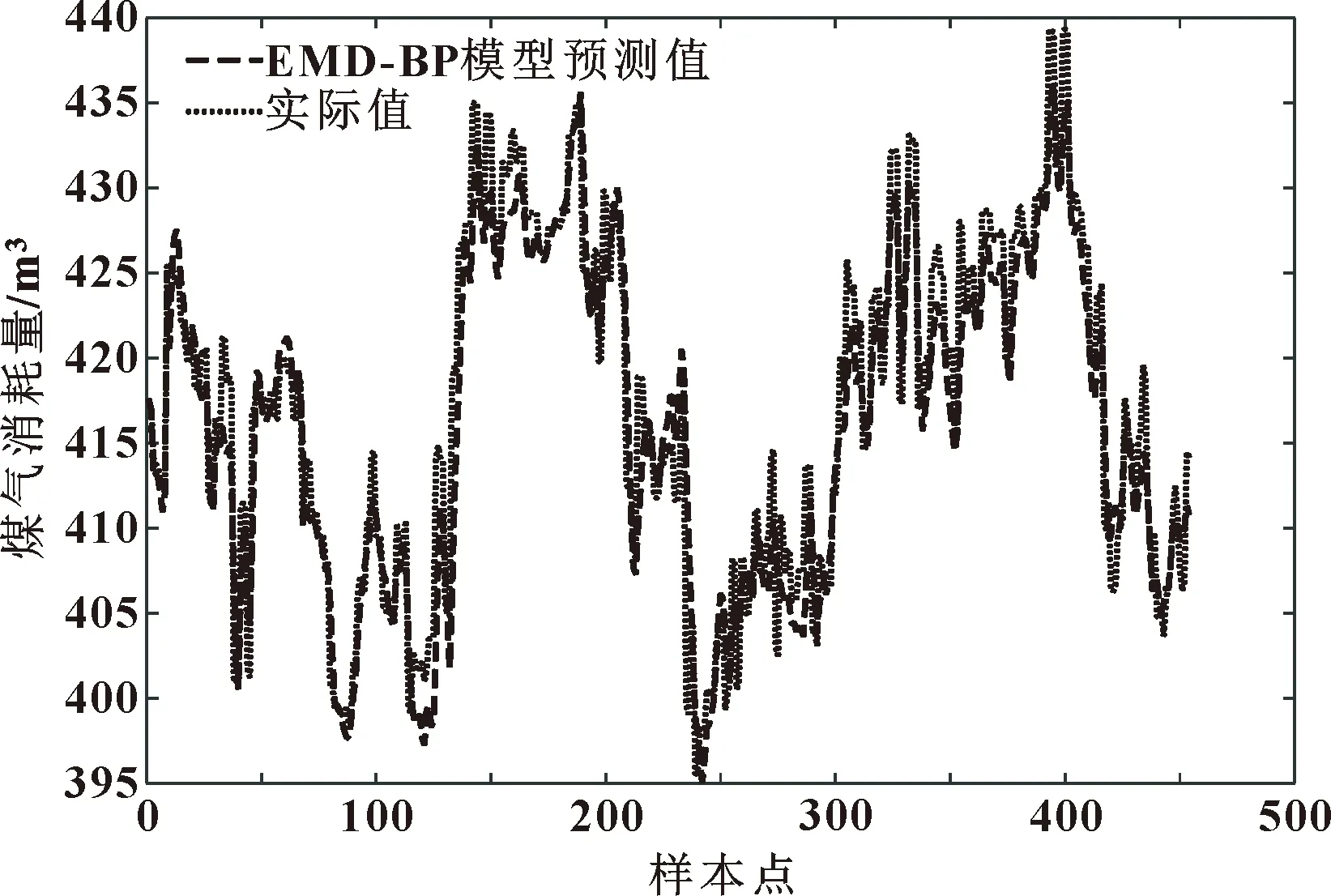
图7 EMD-BP模型预测值
在阅读了大量文献后,本文作者发现理论上LSTM对时间序列有更强的预测能力,可以充分利用数据中的有效信息。因此,验证LSTM的预测能力。
由图8可以看出:LSTM预测曲线与实际煤气消耗曲线趋于一致,预测精度明显高于BP模型;然而,在部分极值点处,预测值略低于实际值。

图8 LSTM模型煤气预测值
通过以上分析,将EMD分解与LSTM相结合,利用EMD提取煤气消耗数据的本质特征,对副产品煤气消耗量进行LSTM预测。
如图9所示:与BP、EMD-BP和LSTM相比,EMD-LSTM的预测结果与实际值基本相近,表明它完美结合了两个算法的优势,可用于预测冷轧过程中的煤气消耗量。
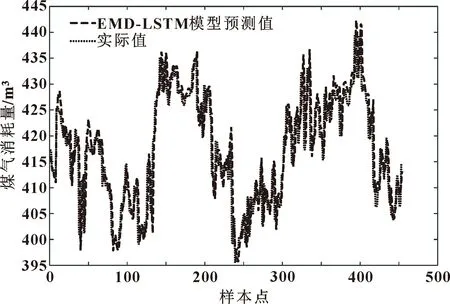
图9 EMD-LSTM模型煤气预测值
对于煤气消耗预测,使用平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)和均方根误差()来评估预测模型的性能。
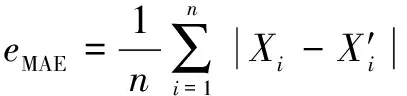
(8)
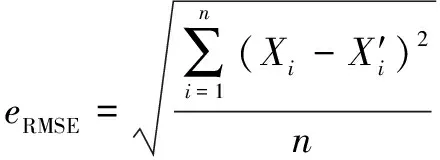
(9)
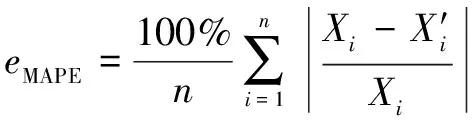
(10)
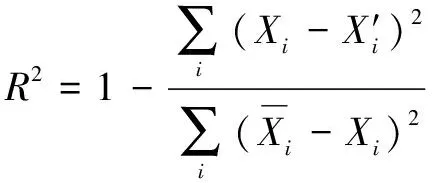
(11)
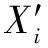
表1所示为4种模型预测性能的比较结果。可知:EMD-LSTM相较于其他算法具有较低的MAE(1.634)、RMSE(2.121)、MAPE(0.39%)和较高的(0.957),这表明预测值与实际值的拟合程度较高,预测能力良好。从上述4种模型的预测结果看,EMD-LSTM模型充分利用了EMD分解在非线性数据特征提取和时间序列长期记忆中的LSTM效应,克服了单一模型的缺点,提高了煤气消耗量的预测效果。
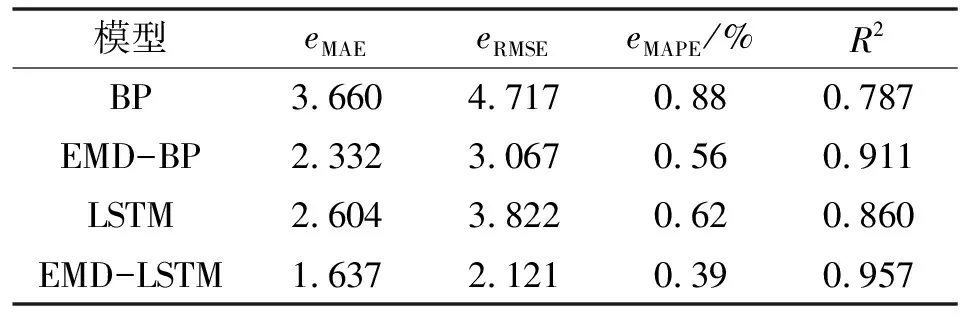
表1 不同方法的预测性能比较
4 结论
针对工业过程中数据存在非线性、非平稳的现象,提出了一种EMD-LSTM方法,并用某钢铁企业实际冷轧生产数据进行了验证。首先,利用EMD将煤气消耗量序列分解成若干频率分量,从中提取煤气消耗量本质特征。然后,建立了一个煤气消耗量预测模型,对各分量进行预测。最后,将各个预测值相加,得到最终的预测结果。从仿真结果可以得出以下结论:
(1)EMD-BP方法与BP 方法进行对比,得到采用 EMD对数据进行预处理可以有效提高模型的预测能力;
(2)LSTM方法与BP方法相比,得到LSTM方法能够利用大量先验信息,有效解决长期依赖的问题,具有更高预测精度;
(3)预测结果表明:EMD-LSTM方法结合了两个方法的优势,大大提升了煤气预测精度,MAPE低至0.39%,达到0.957。该方法可以用于冷轧煤气消耗量的预测,为钢铁企业节约生产成本、降低环境污染及煤气调度提供参考。
