自监督对称非负矩阵在GDP聚类分析中的应用
2022-09-15刘万金赵芳芳
刘万金,赵芳芳
(兰州财经大学,甘肃 兰州 730020)
0 引言
国内生产总值(GDP)反映一个国家或地区经济的变化,作为国民经济核算的核心指标,具有重要的研究意义。不同省份之间的GDP 各不相同,分析我国GDP的类别差异对解决区域不平衡、提高GDP 具有重要的意义。聚类分析对数据进行无监督划分,度量不同类别之间的差异性,利用聚类分析方法对我国不同省份之间GDP的研究不断涌现。吴晓红[1]利用谱系聚类把我国7大行政区分了3类;范敬雅、邹玉梅[2]利用高斯混合模型对我国人均GDP 进行聚类,根据贝叶斯准则选取最优聚类数;李泽宇[3]提出基于灰色关联度聚类分析的我国GDP结构比较;黄贤超[4]将GDP数据划分为3大产业值,利用Kmeans进行聚类分析;汪飞[5]对我国西部各省区人均GDP、GDP增长率进行聚类分析,分析人均GDP、GDP增长率高低的差异。
非负矩阵分解(Nonnegative Matrix Factorization,NMF)是将非负约束整合到一般矩阵分解中[6-7]。它的目标是找到维数较低的非负矩阵,使它们的线性组合可以近似原始矩阵。非负定性导致基于部分的表示,因为它只允许添加非否定性元素。具体来说,NMF 利用基矩阵与系数矩阵的线性组合来近似原始数据,其中基矩阵和基向量都是非负的。鉴于非负矩阵分解的优点,非负矩阵分解被广泛应用于机器学习、数据挖掘与数据处理领域。李军、邓育[8]从空间和时间两个角度出发,采用非负矩阵分解算法对出租车的行为进行聚类分析,进而分析出租车的时空行为特征、省份空间结构及省份出行活动之间的关联,为省份出租车管理与发展提供参考;卢瑞瑞等[9]将L1/2正则化稀疏约束与能源分解相结合,提出基于用户用电行为数据的L1/2正则化稀疏约束和同质性约束的能源分解聚类分析方法;马圆圆[10]等将基于非负矩阵分解的无监督聚类方法运用到甲骨文卜辞数据,进一步挖掘卜词中存在的潜在信息。余江兰[11]将核L21范数非负矩阵分解应用于图像聚类;唐晓芬[12]提出基于最大相关熵距离的非负矩阵分解算法,在基因数据中产生了较好的聚类效果。非负矩阵对线性可分数据效果较好,对于非线性数据,非负矩阵分不能直接应用。对称非负矩阵分解(Symmetric Non-negative Matrix Factorization,SNMF)[13]是一类特殊的约束NMF,它将记录样本成对相似性的亲和矩阵分解成聚类指示矩阵及其转置的乘积,不但对线性数据可分,而且对非线性数据也可分。赵昆[14]等提出基于对称非负矩阵分解的复杂网络模糊聚类。对称非负矩阵分解看作一种图聚类算法,对变量的初始化很敏感,而初始化矩阵的好坏将严重影响其聚类性能。为解决此问题,Jia[15]等人充分考虑SNMF 对初始化的敏感性,提出自监督对称非负矩阵分解算法(S3NMF)。
函数型数据分析(Functional Data Analysis,FDA)[16]的概念首先由加拿大学者Ramsey 提出,利用函数曲线作为数据分析对象,分析数据的内在结构特性,基于函数型数据的聚类分析被称为函数型聚类分析(Functional Cluster Analysis,FCA)。N. Coffey[17]利用线性混合样条和P 样条平滑之间的联系消除数据噪声,利用效应模型对表达谱进行聚类;高海燕[18]提出基于非负矩阵分解和函数型数据相结合的函数型非负矩阵分解类算法;黄恒君等[19]提出同时考虑拟合和聚类效果的函数型聚类一步法;刘宝宇[20]基于函数型视角,对比系统聚类与函数型聚类的优缺点,将我国31省份GDP总值利用函数型聚类分析分为5类。
本论述从非负矩阵角度出发,选取1999~2021 年我国31 省GDP 数据,构造新的亲和矩阵,利用S3NMF进行矩阵分解,最后借助Kmeans 对S3NMF矩阵分解的结果进行聚类,得出基于自监督对称非负矩阵分解的我国31 省GDP 类别分析,同时,基于函数型聚类分析结果进行对比[20],结合实际数据分析S3NMF 聚类分析的效果。
1 相关理论
1.1 NMF
NMF[20]是将矩阵 X ∈ ℝm×n分解为两个非负矩阵W ∈ℝm×r和 H ∈ ℝr×n(r ≪ min(m,n))的乘积的一种形式,即X ≈WH。相应优化算法已被来解决NMF 优化问题[21-22]。
NMF 使用欧几里德距离来测量重建误差,优化问题如下:

其中‖ ‖.F表示矩阵的Frobenius 范数,X ∈ℝm×n是训练集,W ∈ℝm×r和 H ∈ℝr×n分别称为基矩阵和系数矩阵。元素X,W,H 都是非负的。相应的乘法更新规则如下[6]:

1.2 S NMF
对于n×n 阶相似矩阵 A,对称非负矩阵[13]目标函数为

其中H 是一个大小为n×k 的非负矩阵,k 是聚类数。SNMF与谱聚类(SC)具相近的目标约束函数,相关性较高[13,23]。SC的目标函数为

其中 I ∈ ℝk×k是单位矩阵,SNMF 通常被看作图聚类的一种算法。
2 S3NMF、Kmeans、FCA
2.1 S3NMF
Jia 等人提出 S3NMF 算法[15],克服了对称非负矩阵分解对初始化敏感性。首先生成一组随机非负矩阵(b 是集合的大小),由对称非负矩阵分解获得b 个聚类划分,构造质量更高的相似矩阵。

在不同初始化下生成一组更优聚类划分。重复该过程,直到达到终止准则或最大迭代次数。约束优化模型为:

其中,αm是 α ∈ ℝb×1的第 m 个元素,权重向量平衡每个分区的贡献,1 ∈ℝb×1表示全1向量,约束 αT1=1避免了 α 的平凡解(即 α=0),α ≥0 保证每个 αm都是有效权重,τ ∈(1+∞)。更新规则如下:

2.2 Kmeans
Kmeans 聚类算法[24]利用不同点之间的欧氏距离来度量不同点之间的相似度。给定固定点,当不同点到固定点之间的距离较近时,则该固定点将与离其最近的一类点被聚到同一个类别中,依次类推,直到样本中所有点到聚类中心距离最近且类中心不再变化时,最终实现归类,聚类完成。
Kmeans 聚类算法步骤如下所述:
(1)从样本中随机选取k 个类中心。
(2)对剩下的样本,计算其到类中心的距离,并把离类中心近的样本与相应的类中心归为一类。
(3)重新计算各个类的中心。
(4)重复以上2至3步骤直至每个聚类不再变化。
2.3 FCA
函数型聚类基于曲线的相似度进行聚类[20]。第i条曲线xi(t)与第j条曲线xi(t)之间的相似度采用式(9)所定义的曲线距离来度量,也即欧氏距离。

将xi(t)与xj(t)用相同的K 维样条基函数Φ(t)展开得:
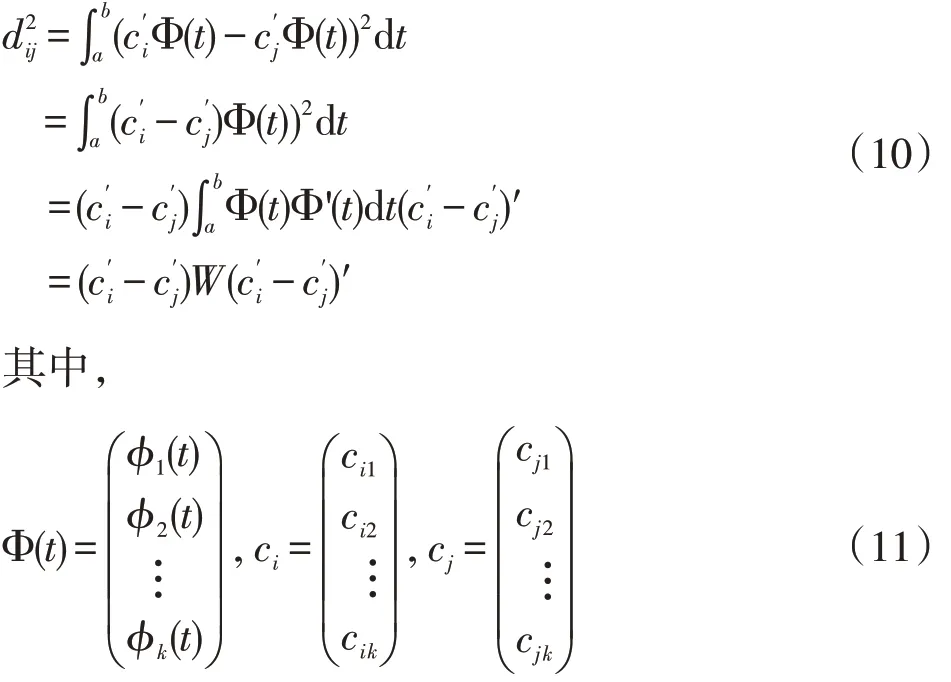
3 聚类分析
3.1 数据来源
我国是一个地域辽阔、人口众多的发展中国家,利用聚类分析的方法对各省市GDP 指标进行合理的分类,对国家的经济发展有着重要的现实意义。本论述选取我国 31 省市 1999~2021 年 31 省 GDP 数据进行聚类分析,基于S3NMF 分析我国31 省市GDP 的类别差异。文章数据来源:中国经济社会大数据研究平台(https://data.cnki.net/)。使用计算软件为:Matlab 2018 b,CPU 配置:Intel(R)Core(TM)i7-10875H CPU@2.30 GHz。
3.2 聚类结果及分析
3.2.1 S3NMF聚类
对我国31 省份GDP 总值数据,构造新的亲和矩阵,利用S3NMF 进行分解。Kmeans 利用样本与样本之间的距离进行聚类。S3NMF 对分解后的矩阵利用Kmeans聚为5类,聚类结果见表1所列。

表1 S3NMF聚类结果分类表 单位:亿元
由表1可知,我国31省市按照GDP总值分为5类,其中上海市、江苏省、浙江省、山东省、广东省、四川省为第一类,就第一类省份而言,高新技术产业发达,人才驱动经济发展;北京市、河北省、安徽省、福建省、河南省、湖南省、湖北省为第二类,就第二类省份而言,经济产业比较丰富,产业结构较为完善;山西省、辽宁省、云南省、陕西省为第三类,就第三类省份而言,以特色产业为导向驱动经济增长;内蒙古自治区、江西省、广西壮族自治区、重庆市、贵州省为第四类,就第四类省份而言,拥有一定优势资源,没有明显强劲产业驱动经济快速发展;天津市、吉林省、黑龙江省、海南省、西藏自治区、甘肃省、青海省、宁夏回族自治区、新疆维吾尔族自治区为第五类,就第五类省份而言,区位优势相对较弱,产业结构不完善,人才流失比较严重。分析聚类结果可以发现,整理后的聚类出现一定的阶梯性,即从第1 类到第5 类整体体现为从东到西整体GDP 由强到弱的变化过程,东部地区GDP总体较高,西部地区GDP整体较低。
3.2.2 FCA聚类
为了对比聚类效果,本论述聚类结果以刘宝宇函数型聚类(FCA)结果为参照进行对比[20],FCA聚类结果整理后,见表2所列。

表2 函数型聚类结果分类表 单位:亿元
由表 2 可知,FCA 将我国 31 省份按照 GDP 总值聚为5类,其中江苏省、山东省、广东省为第一类;浙江省、河南省为第二类;北京市、河北省、辽宁省、上海市、安徽省、福建省、湖北省、湖南省、四川省为第三类;天津市、山西省、内蒙古自治区、吉林省、黑龙江省、江西省、广西壮族自治区、重庆市、云南省、陕西省为第四类;海南省、贵州省、西藏自治区、甘肃省、青海省、宁夏回族自治区、新疆维吾尔族自治区为第五类。
结合表1与表2可知,两种聚类方法产生的共同聚类结果为:(1)将江苏省、山东省、广东省聚为同一类;(2)将北京市、河北省、安徽省、福建省、湖北省、湖南省聚为同一类;(3)将内蒙古自治区、江西省、广西壮族自治区、重庆市聚为同一类;(4)将海南省、西藏自治区、甘肃省、青海省、宁夏回族自治区、新疆维吾尔族自治区聚为同一类。就表1 与表2 具体聚类效果而言,S3NMF 聚类结果省份类别个数分布比较均匀,两者聚类方法的聚类结果整体较为接近,但S3NMF 无法直接进行聚类分析,对分解后的矩阵借助Kmeans 进行聚类,非负矩阵分解具有一定的降维作用,因此,基于S3NMF的聚类结果可能存在一定程度的偏差,但相对而言,基于S3NMF的聚类分析能够产生相对比较准确的聚类划分。
总体而言,我国经济发展仍存在区域差异、产业差异、结构差异,东西部地区差异较大,但各省GDP 都存在较大的发展空间,如何提高GDP 及解决区域发展不平衡问题既有机遇又有挑战,经济相对落后的省份要取长补短,打造区域特色,提高自身经济实力,经济相对较高的城市要不断促进产业成功转型,结合自身特色挖掘创新性经济驱动策略,自身发展的同时带动西部GDP 发展相对缓慢的城市,从而实现东西部共同发展,促进我国GDP整体增长。
4 结论
S3NMF 利用集成的思想、考虑初值敏感性的同时加入监督信息。利用我国31省GDP数据构造亲矩阵,借助Kmeans 对S3NMF分解后的结果进行聚类分析,将我国31省按照GDP分为5类,结合31省自身经济特色与基于S3NMF 矩阵分解的结果综合来看,S3NMF 能够产生相对较为准确的聚类划分,可以将基于S3NMF 分解的聚类方法应用到未知标签信息的聚类问题中。
