融合多类型数据的胃癌风险预测模型
2022-09-15陈先来贾一珍唐红英
陈先来,贾一珍,安 莹,唐红英
(1.中南大学 大数据研究院,长沙 410083;2.中南大学 医疗大数据应用技术国家工程研究中心,长沙 410083;3.中南大学 计算机学院,长沙 410083;4.中南大学湘雅医院 临床护理学教研室,长沙 410008)
0 概述
胃癌是威胁人类健康的重要疾病之一,根据国际癌症研究机构(IARC)最新的研究结果显示,2020年全球约有108 万新发胃癌病例数,位居全部恶性肿瘤第6 位,而在2012 年仅为95 万[1],因此,全球胃癌的发病数呈上升趋势。在我国胃癌属于高发疾病,每年新发病例数约40 万,死亡约35 万,新发病例数与死亡病例数均占全世界胃癌病例数的40%以上。预计到2030 年,我国将有63 万胃癌患者,胃癌死亡率将位居恶性肿瘤第3 位,成为重大的公共卫生问题[2]。
在临床诊断上,胃癌诊断的准确性依赖于胃镜、X线造影、CT 等影像学方法和病理组织活检。这些方法不仅价格昂贵,而且需要实践经验丰富的医务人员。该方法使患者感受到一定程度的痛苦,无法用于大规模人群的风险筛查。因此,一种准确、便捷的胃癌筛查方法成为研究热点。
随着医疗信息化建设的不断发展,在医疗活动中,每天都会积累大量的电子健康记录(Electronic Health Record,EHR)数据。因此,基于EHR,利用机器学习方法对患者患病风险进行分析和预警的相关技术逐渐得到研究人员的广泛关注[3]。这类方法对患者身体没有创伤。近年来,深度学习方法在数据挖掘与建模领域取得了显著的进展,相关研究人员提出Deepr[4]、Dipole[5]、R-MeHPAN[6]等用于患者疾病风险预测的模型。然而,这些方法都是针对通用的疾病风险预测任务,并不一定适合于胃癌风险预测。在胃癌风险预测领域中,大多数研究都基于病理或影像图片进行预测,但是在临床诊断中,这些数据的获得需要付出较大的代价。此外,这些方法主要聚焦于某一类型的单一结构化医疗数据,未联合胃癌诊疗过程中产生的大量多样化医疗健康数据。
本文通过融合不同类型的数据,从多个维度对胃癌风险预测任务进行建模,提出基于多类型异构数据的胃癌风险预测模型。考虑到不同结构数据之间的差异性,采用预训练语言模型对入院记录文本数据进行特征提取,通过降噪自动编码器(Denoising Auto-Encoder,DAE)提取实验室检验数据的特征,并将提取的两个特征相融合。此外,通过对低维度的结构化数据向量表示的维度进行扩增,以避免低维度的特征表示被维度更高的特征淹没。
1 相关研究
1.1 疾病风险预测
临床辅助决策系统是利用规则库、机器学习等技术为临床医师提供决策支持的计算机系统,早期的研究主要基于规则和知识进行推理的专家系统。这类方法简单便利,但是需要大量的人工操作来构建相应的规则。随着机器学习方法的不断发展,研究人员围绕胃癌的风险预测,以海量医疗数据驱动,结合机器学习和深度学习技术,积极开展研究工作。文献[7]使用决策树构建胃癌患者临床信息分析模型,主要从医院信息系统(Hospital Information System,HIS)中提取与患者胃癌术后复发有关的数据,构建胃癌术后复发危险因素分析模型,从而改善胃癌的诊疗效果。文献[8]提出一种利用本体进行关联规则发现的新方法,解决了结果集含有大量无意义和冗余规则的问题,从而缩短Aprior 算法的运行时间。文献[9]使用分层赋时着色Petri 网对胃癌的诊疗过程进行建模,通过模拟不同临床状态与需求的患者,设计最佳诊疗方案,为诊疗提供决策支持。
深度学习技术的发展给胃癌的早期筛查和临床诊疗带来了新的思路,依托各类医疗影像数据进行胃癌筛查的相关研究层出不穷。文献[10]使用视觉几何组(Visual Geometry Group,VGG)-16 构建深度预测模型,以鉴别内窥镜图像是否为早期胃癌图像。文献[11]设计基于临床内窥镜成像数据的胃肠人工智能诊断系统,用于诊断上消化道癌症,在来自6 家医院的多中心对照数据集上的实验结果表明,该系统与内窥镜医师的诊断灵敏度相似,有助于社区医院提高上消化道癌症诊断的准确率。文献[12]提出基于卷积神经网络(Convolutional Neural Network,CNN)的模型,对肿瘤浸润淋巴细胞进行检测,具有较高的准确率。文献[13]使用来自某三甲医院的1 885 张胃镜图片,基于ResNet50 和VGG-16 模型构建3个单独的二元分类模型并进行对比实验,结果表明,该模型能够较早地发现溃疡病灶,有助于临床辅助溃疡病灶检出并鉴别良恶性溃疡。文献[14]设计了计算机辅助诊断系统来帮助内窥镜医师识别放大窄带成像(M-NBI)图像中的早期胃癌病例,该系统还能筛选出含有癌症的关键区域。文献[15]提出一种基于Ada Boost 的多列卷积神经网络(MCNN)和智能连接电子胃镜系统,实现了胃癌的动态智能筛查。研究人员提出一种基于多尺度输入的深度学习模型MIFNet,通过将多尺度图像和特征相融合[16],进一步提高胃癌病理图像分割的准确性,对临床辅助诊断具有重要意义。
这些研究在一定程度上提高了胃癌筛查的准确率和覆盖率,但是仍然存在一些不足。一方面,这些方法主要聚焦于某一类型的单一结构化医疗数据,没有联合临床胃癌诊疗过程中产生大量的多样化医疗健康数据,容易遗漏部分信息;另一方面,基于机器学习和数据挖掘方法的预测模型往往受限于特征工程和算法自身的不足,严重依赖于人工的特征工程,导致模型泛化能力弱。除此之外,现有基于深度学习的筛查模型只能依赖于某些机构提供的少量单维度数据。
1.2 特征融合
深度学习可以在更高维度上对数据进行抽象和建模,从而发现数据中潜在的规律。临床医疗数据的显著特点是多样性,即临床医疗数据包含各种方式收集的结构化以及非结构化数据[17]。受病理学家在实际临床诊断中的启发,研究人员提出融合多源异构数据的疾病风险预测方法,这些方法具有比单一类型结构的数据更优异的性能。文献[18]结合肿瘤蛋白表达、病理图像和拷贝数,提出基于深度学习的癌症患者生存期预测模型。文献[19]提出一种叠加网络的鲁棒集成深度学习模型,可以融合五类多模态时间序列和一组背景信息,通过对多个变量进行联合预测,在多类递进和回归任务中都具有优异的性能。
虽然上述方法均具有优异的性能,但是每类数据都具有自身独特的特征,导致不同类型的数据特征之间难以良好融合。例如,文本、图像等非结构化的数据通常具有高维的特征表示,而结构化数据的维度较低,如何将两者有效集成会极大影响预测模型的性能。根据融合级别,融合方法可以分为数据融合、特征融合和决策融合[20]。在融合前每个模态的信息损失越小,信息融合越可靠,信息融合的结果就越好[21]。实验结果表明,每个模态的信息,特别是信息丰富的高维模式,应该在融合前尽可能完整,然后在初始融合后将维度降低到期望的水平,这样的融合才能够有效地捕捉多模态异构数据的复杂关联关系。目前,大多数数据融合是图像以及文本[22-23]的融合。然而,这些数据都是高维的,很少有研究涉及到低维结构化数据与高维非结构化数据的融合。
自动编码器是一种无监督的机器学习算法,广泛应用于数据降维。在现有的研究中,很少使用自动编码器或其变体来改进数据的维度。降噪自动编码器是在自动编码器的输入中添加随机噪声,使解码器部分恢复出真正的原始数据。因此,DAE 能够学习到原始输入数据中鲁棒性更优的特征表示。在本文构建的模型中,利用降噪自动编码器来扩展结构化数据的维度,以避免在早期过程中丢失高维特征的部分信息,能够更高效、全面地捕获电子病历数据中的特征信息,实现更优的预测性能。
2 胃癌风险预测模型
近年来,研究人员提出许多用于胃癌风险预测的深度学习模型,但是这些模型多聚焦于某一类数据,没有联合临床诊疗过程中产生的多种医疗健康数据,可能造成某些信息的遗漏。为了融合不同类型结构的数据,从更全面的角度对患者的患病风险进行预测,本文提出一种用于胃癌风险预测的多类型数据融合深度学习模型,该模型分为文本数据处理模块、结构化数据处理模块以及特征融合模块,分别对应EHR 数据中不同的数据类型。本文模型的整体架构如图1 所示。
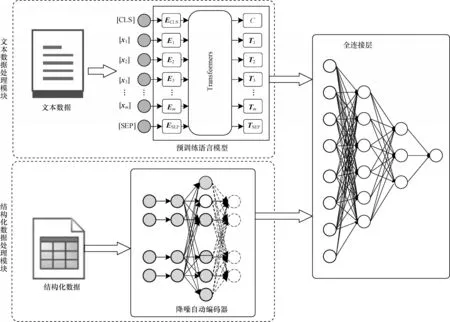
图1 本文模型结构Fig.1 Structure of the proposed model
文本数据处理模块利用预训练语言模型对EHR记录中的入院记录进行建模,建模时主要使用入院记录中的主诉和现病史部分,主诉部分记录了患者入院时的主要症状,现病史部分是对患者疾病的发展状况和已经进行的治疗手段的简要描述,这些内容包含大量重要的信息。结构化数据处理模块基于DAE 对结构化的实验室检验数据进行特征抽取,由于结构化数据的维度远低于文本数据,在模型中加入降噪自动编码器对结构化数据的向量表示的维度扩增到适当的程度,最后对获得的向量进行拼接,从而实现患病风险预测。
2.1 文本数据处理模块
来自入院记录中的主诉和现病史描述了疾病的主要症状和发展过程,其中包含大量关键信息。采用适当的算法提取这些记录中的关键信息,有助于对患者的患病风险进行预测。但是由于医疗数据的匮乏,传统的word2vec、Glove 等文本表示方法无法获得准确的向量表示。基于迁移学习的预训练语言模型经过大规模数据集的预训练,在小样本上经过微调后便能达到较优的领域表示效果。在自然语言处理(Natural Language Processing,NLP)任务中,基于大型语料库的预训练语言模型可以学习到通用的语言表示,以避免从头开始训练新的模型[24],例如BERT[25]、ELMO、XLNet 等。BERT 模型结构如图2所示。
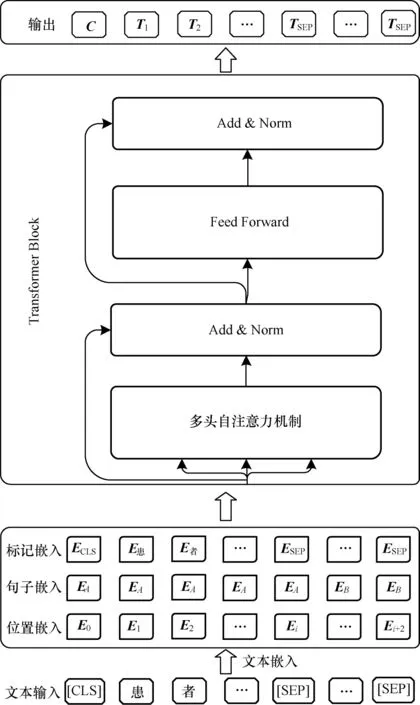
图2 BERT 模型结构Fig.2 Structure of BERT model
文本数据通过WordPiece 方法嵌入后用于模型的输入。此外,为了获取不同字之间的序列信息和完成NSP 预训练任务,BERT 模型还加入了句子嵌入和位置嵌入信息,将以上3 个嵌入向量相加后经过若干个Transformer 编码器来得到相应的输出。
Transformer 编码器是基于多头自注意力(Multihead Self-attention)机制的seq2seq 结构,BERT 使用了其中的Encoder 部分。多头自注意力机制是由多个自注意力向量拼接构成,使模型从不同表征子空间中获取更多层面的特征,从而捕获句子全面的上下文信息。假设嵌入后的文本向量,其中,n为文本的最大长度,k为文本的嵌入维度,则按照式(1)分别计算得到Query、Key 和Value 向量:
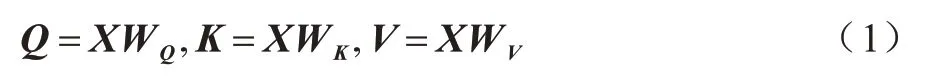
其中:Q、K和V分别表示Query、Key 和Value 向量;WQ、WK、WV表示参数矩阵。单个自注意力计算如式(2)所示:
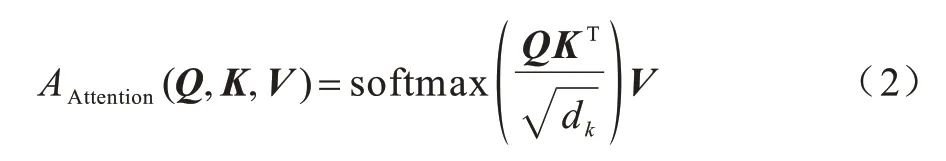
其中:dk表示神经网络的隐藏层单元数;表示对注意力的值进行调整,避免其过大。多头自注意力机制是由多个自注意力并行计算后合并得到。其中head,即自注意力的个数是人为设置的超参数。整体过程的计算如式(3)所示:

其中:Wo表示附加的权重矩阵;concat()表示拼接函数。
为了增强语义的表达能力,BERT 模型采用遮蔽语言模型(Masked Language Model,MLM)和句对预测(Next Sentence Prediction,NSP)两个预训练任务对模型进行预训练。MLM 任务是给定一个句子,随机掩盖其中的部分词,利用剩余部分信息预测掩盖的词。该任务使得BERT 模型实现深度的双向表示。NSP 任务是给定一篇文章中的两个句子,判断第二个句子是否是第一个句子的下一句,使得BERT模型学习到两个句子之间的关系。
为了进一步减少模型的参数量和优化预测性能,研究人员提出BERT 的优化版本,例如,Facebook提出RoBERTa[26],针对BERT 的预训练任务,提出动态掩盖方案,取消了NSP 任务和采用更大的批次大小,在多个测评基准上取得了较优BERT 结果。斯坦福大学联合谷歌发布的ELECTRA[27],将一个小版本的BERT 作为生成器,采用对抗训练的方法对被掩盖的词进行预测,使用判别器对每个字是否被替换进行判别,得到了更强的拟合能力。RoBERTa是BERT 的进一步强化版,而ELECTRA 是目前性能最优的预训练语言模型。
在本文提出的文本数据处理模块中,分别采用BERT、RoBERTa 和ELECTRA 三种模型提取入院记录文本信息。其中,每个模型都有多个不同的预训练版本,较“轻”的版本具有更少的参数量,训练时间较短,但是对文本信息的提取能力较差;而较“重”的版本则相反。综合考虑各因素,在本文的文本数据处理模块中,BERT 选择使用由谷歌发布的Base 版本模型,RoBERTa 选择由哈工大与科大讯飞联合实验室公布的Base_ext 版本模型,ELECTRA 选择哈工大与科大讯飞联合实验室公布的Base 版本模型。
2.2 结构化数据处理模块
文献[28]的研究结果表明,当维度差异较大的数据直接融合时,低维度的信息将被高维度的信息淹没。在胃癌风险预测任务中,结构化数据的向量维度远小于文本数据嵌入后的向量维度,为了避免其被高维的文本数据表示向量淹没,需要将结构化数据的向量表示维度调整到与文本数据的向量表示维度相当的水平。若在数据融合前对高维的文本信息进行降维,会丢失部分信息。因此,通过扩增结构化数据向量表示维度的方法来避免输入模型的信息失真。本文使用改进的降噪自动编码器来达到上述目的。DAE 是一种无监督的机器学习模型,其输出是对输入的重构。此外,DAE 的输入是经过扰动之后的原始数据,使得模型学习到鲁棒性更优的特征表示,避免通过简单的函数映射来重建数据。同时,来自临床的电子病历数据还存在大量的缺失数据,DAE 可以降低缺失数据对预测结果的影响。
为了适应扩增向量维度的需求,本文对传统的DAE结构进行改进。改进的DAE 结构如图3 所示。
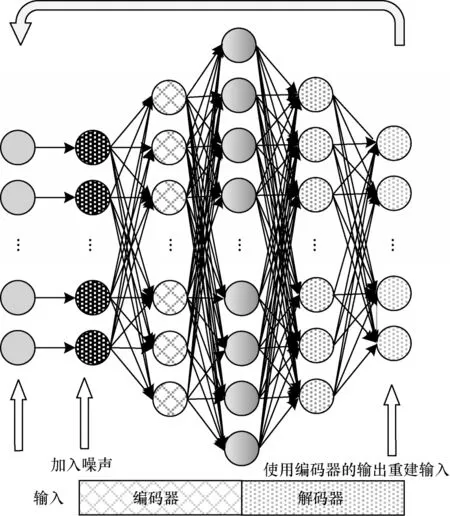
图3 改进的降噪自动编码器结构Fig.3 Structure of improved denoising auto-encoder
为了增加数据的维度,本文将隐藏层的节点数设置为大于输入层的数目,并添加dropout 层,采用随机丢失原始输入中一部分数据的方式来实现DAE对模型数据加入噪声的机制。此外,为了进一步增强网络的稀疏性,本文还使用正则化技术。模型的计算如式(4)所示:

其中:x为原始输入的结构化数据;为添加噪声后的模型输入数据;W、b为模型参数。在编码器部分学习非线性变换f(·)并将输入转换为其隐藏向量hz。在解码器部分通过另一个非线性变换g(·)来重建原始输入x。本文使用L1 正则化解决复杂度和过拟合问题。整体的损失函数如式(5)所示:
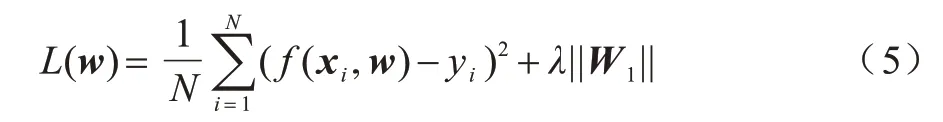
其中:xi为原始输入数据;yi为解码器重建的结果;w为模型参数;λ为正则化系数。
2.3 文本数据与结构化数据的特征融合
对于文本数据,预训练语言模型将每条入院记录转换为高维向量的特征表示。同时,为确保不同的数据可以在相同的尺度上被融合,结构化数据处理模块将维度较低的结构化数据扩增到较高的维度进行特征表示,在得到每种类型数据的向量表示之后,一般而言,有多种进行向量融合的方法,例如相加、相乘、拼接等。由于向量拼接方式能够最大程度地保留不同向量中的信息,因此本文选择拼接方式作为特征融合方法。通过三个全连接层对向量进行适当压缩,利用带有sigmoid 激活函数的神经网络层对患者的胃癌风险进行判断,其过程如式(6)所示:

其中:Sn、Tm分别为结构化数据和文本数据的向量表示;n、m为它们的维度;concat()为向量拼接;f(·)为最后一层带有sigmoid 激活函数的全连接层;y为模型的预测结果;W、b为模型参数。
本文模型分为三个阶段进行训练。首先,针对文本数据处理模块中的预训练语言模型,单独使用患者的入院记录文本进行训练;然后,单独使用患者的实验室检验数据对结构化数据处理模块中的DAE进行训练,同时采用较高的学习率以帮助模型尽快收敛;最后,使用DAE 的编码器和训练好的预训练语言模型的权重对整个模型进行初始化,在较低学习率下对整个模型进行微调。
3 实验与结果分析
3.1 数据描述与清洗
本文使用的数据来源于多所三甲医院,收集了近10 年消化科42 318 位患者的EHR 数据。本文未获取原始电子病历中涉及个人隐私的信息,例如患者姓名、住院号码、身份证号码等。此外,由于EHR数据存在冗余、缺失等问题,因此剔除了部分缺失率过高的记录和字段,对冗余记录进行去重处理。本文抽取这些患者的入院记录、病案首页与实验室检验记录,其中,入院记录主要包含患者的基本信息、主诉、现病史、个人史、体格检查等内容,采用正则表达式、字符匹配等方法提取入院记录中的主诉和现病史部分,并且对空格、换行等字符进行清理。对于实验室检验,本文按照检验项目绘制箱形图以剔除异常值。由于不同检验项目的数据分布差异极大,因此采取Q3+10IQR 和Q1-10IQR 作为异常值阈值。为避免发生误删,本文对异常值占比超过10%的检验项目进行人工核查。经过上述筛选过程,最终获得性别、年龄等5 项人口学数据以及酮体、胆红素、血红蛋白等93 项实验室检验指标。
本文共获得18 390 份有效电子病历数据,其中3 565 份数据为正例。为了保证数据集的平衡性,本文使用欠采样方法对数据集进行平衡,最终获得7 165 份电子病历数据,其中包含胃癌患者记录3 565 份,非胃癌患者记录3 600 份。
3.2 实验设计
本文所提出的模型基于Python 3.8 编程语言,采用Keras 2.3 以及TensorFlow 2.1 工具包进行实现。为进一步优化模型,在不同的训练阶段采用不同的参数设置,具体如表1 所示。
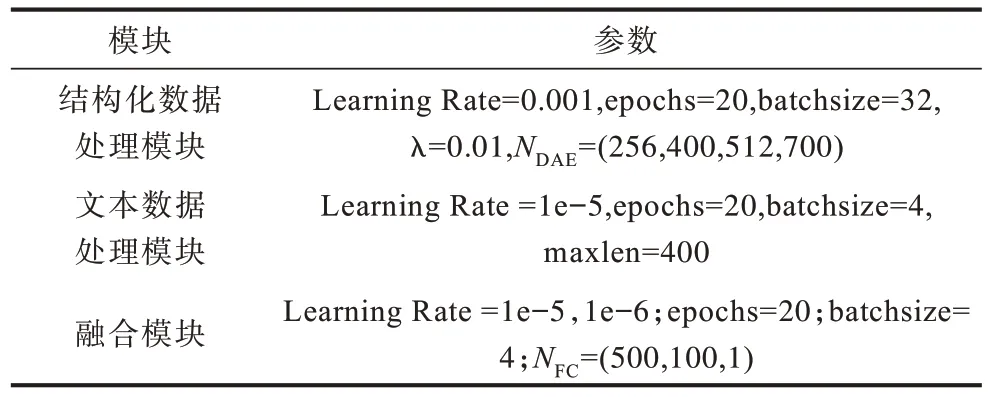
表1 本文模型的训练参数Table 1 Training parameters of the proposed model
在表1 中,Learning Rate 是模型的初始学习率,λ是正则化层的正则化率,maxlen 是输入的最大文本长度,NDAE和NFC是相应隐藏层的神经元数量。此外,本文还使用动态学习率和dropout 策略,其中,动态学习率策略设定从第10 轮开始学习率每轮下降20%。用于实验的数据集按照6∶2∶2 的比例划分为训练集、验证集和测试集,每个实验都使用五折交叉验证来保证实验结果的稳定性。整个模型分为3 个阶段进行训练,首先,使用结构化数据单独训练DAE,然后,在分类任务中使用文本数据对预训练语言模型进行训练,最后,将两个模型合并在一起,使用较低的学习率进行训练。
3.3 评价指标
本文采用在分类任务中广泛使用的评价指标对模型性能进行评价,包括准确率(AAccuracy)、精确率(P)、召回率(R)、F1 值以及AUC。各指标的计算如式(7)~式(10)所示:
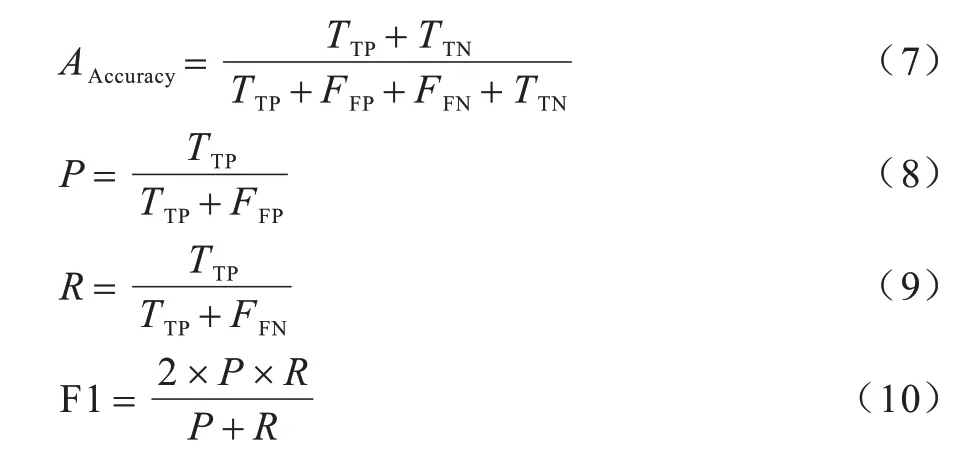
其中:TTP为预测正确的正例数;TTN为预测正确的负例数;FFP为预测错误的正例数;FFN为预测错误的负例数。
3.4 结果分析
3.4.1 不同文本数据处理模块的性能分析
本文采用3.1 节描述的数据集对常见的预训练语言模型进行测试,并与文本处理方法进行对比,主要包括传统的机器学习模型,例如,支持向量机(Support Vector Machine,SVM)、逻辑回归(Logistic Regression,LR)、朴素贝叶斯(Naive Bayes,NB)以及常见的深度学习模型(如TextCNN、BiLSTM)。不同模型的预测结果对比如表2 所示。
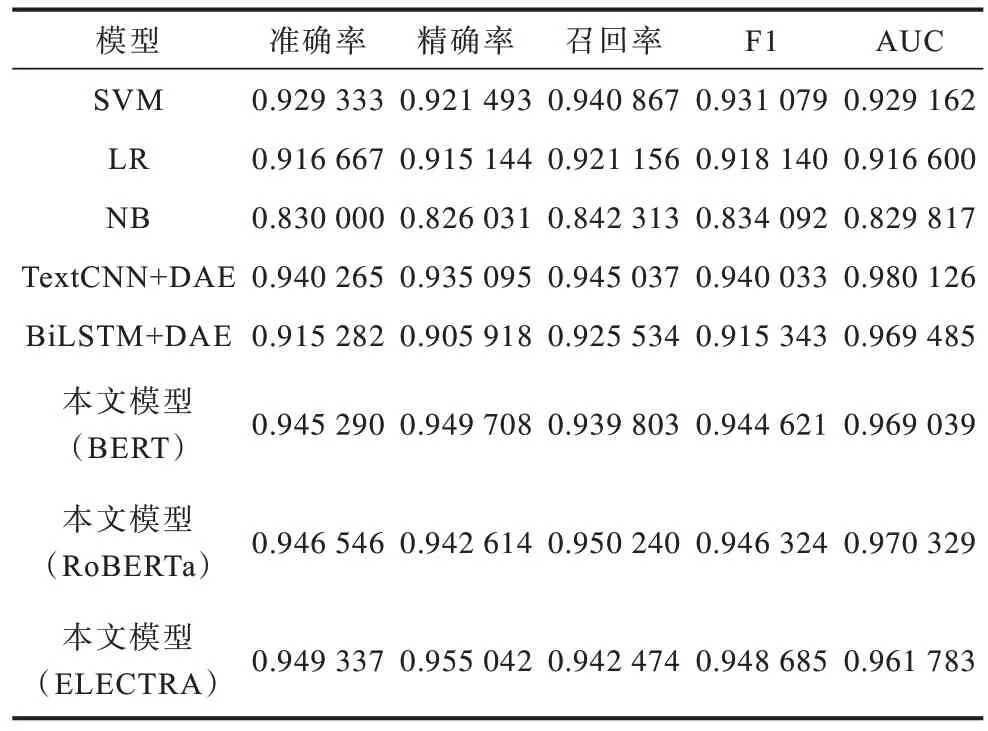
表2 不同模型的预测结果对比Table 2 Prediction results comparison among different models
SVM、LR、NB 表示全部使用相应的模型对患者的实验室检验记录和入院记录文本进行处理得到的预测结果。TextCNN+DAE、BiLSTM+DAE 表示相应的模型作为文本数据处理模块,使用DAE 作为结构化数据处理模块得到的预测结果。本文模型(BERT)、本文模型(RoBERTa)、本文模型(ELECTRA)分别表示使用BERT、RoBERTa 和ELECTRA 预训练语言模型作为文本数据处理模块,使用DAE 作为结构化数据处理模块得到的预测结果。
从表2 可以看出,经典机器学习模型中SVM 取得了0.929 333 的准确率,但仍然低于预训练语言模型中表现最差的BERT 的准确率0.945 29。这是因为机器学习方法只能基于给定的规则对数据进行拟合,难以学习到不同结构数据之间的潜在关联关系,而预训练语言模型可以对入院记录中的文本特征进行更好的表征,再加上DAE 和特征融合模块可以挖掘到不同结构数据间的关联关系,更充分地提取患者EHR数据中的特征。在深度学习模型中,BiLSTM+DAE效果较差,准确率只有0.915 282,而TextCNN+DAE表现较好,准确率达到了0.940 265,这表明单纯的序列模型并不适合对医疗文本进行建模,卷积模型反而能取得较好的效果。但是它们的表现均低于预训练语言模型,其中,本文模型(ELECTRA)的准确率高达0.949 337,这主要得益于ELECTRA 创新性的对抗训练方法及其对预训练任务的改进。
3.4.2 不同类型数据下的性能分析
为进一步对比本文所提出的模型在不同类型数据下的性能,本文分别测试了不同模型在仅使用文本数据、结构化数据以及联合使用情况下的准确率,对比结果如图4 所示。
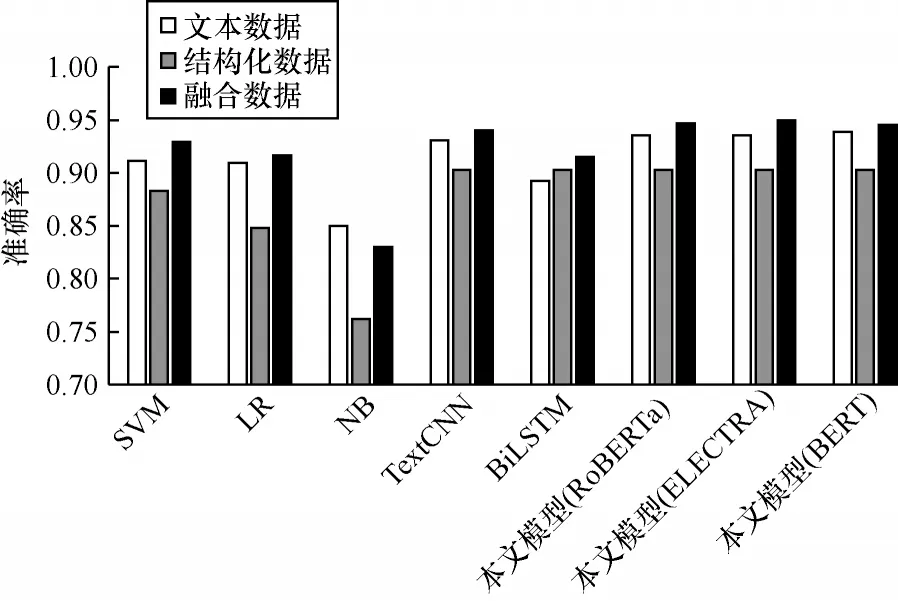
图4 在使用文本数据、结构化数据以及融合数据的情况下不同模型的准确率对比Fig.4 Accuracy comparison among different models in the case of using only text data,structured-data and fusion data
不同花纹的条柱分别表示各个模型仅使用入院记录文本、实验室检验数据以及将这两种类型的数据融合后的预测结果。从图4 可以看出,除NB 外,其他模型使用融合数据都取得了优于使用单一类型数据的预测性能,其原因为来源于电子病历的不同结构的数据都有其特有的信息,只有融合更多的信息才能取得更优的预测效果,进一步表明使用多源异构数据有助于提升胃癌预测的准确性。在不同模型中,除BiLSTM 之外,基于文本数据的预测结果均要优于基于结构化数据的预测结果,其原因为患者入院记录中含有更加详细和有用的信息,在一定程度上表明文本记录在患者风险预测任务中的重要性。
3.4.3 DAE 与预训练策略的价值分析
为进一步验证预训练策略的优势,不同模型未使用和使用不同预训练策略的准确率对比如图5所示。
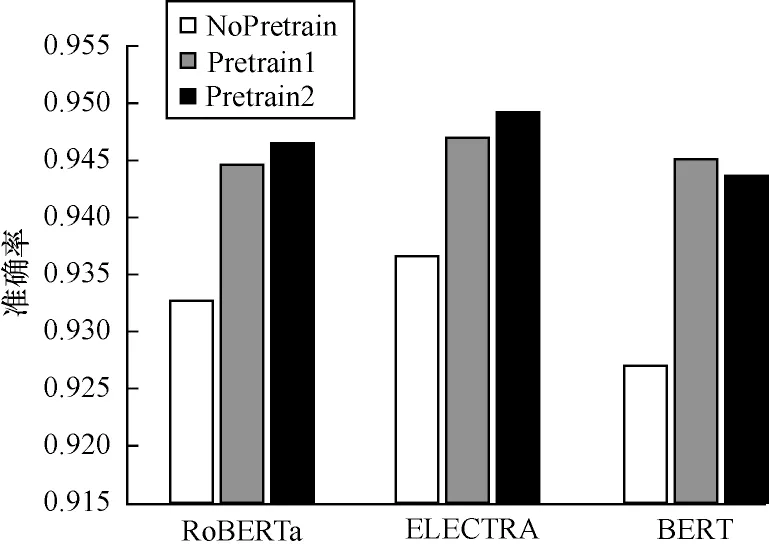
图5 不同模型使用和未使用预训练策略的预测准确率对比Fig.5 Prediction accuracy comparison among different models with and without pretraining strategies
在图5 中,NoPretrain 表示未单独对文本数据处理模块进行训练,Pretrain1 和Pretrain2 表示在最后的训练阶段分别使用1e-5 和1e-6 作为初始学习率进行训练。从图5 可以看出,不论使用何种初始学习率,使用预训练策略的模型准确率均要优于未进行预训练的模型,这表明本文提出的预训练策略能够有效提高模型的性能。
在使用和未使用DAE 的情况下,不同模型的准确率对比如图6 所示。图6 使用普通的多层感知机代替DAE,以及在最后的训练阶段分别使用1e-5 和1e-6 作为初始学习率进行训练,分别标注为NoDAE、Pretrain1、Pretrain2。从图6 可以看出,模型使用DAE 能够有效提高预测性能。此外,当使用较低的初始学习率(Pretrain2)时,RoBERTa 和ELECTRA 模型的预测性能较优,这是由于较低的学习率能够帮助梯度下降算法避免错过最优解,使得模型学习到更合适的参数。
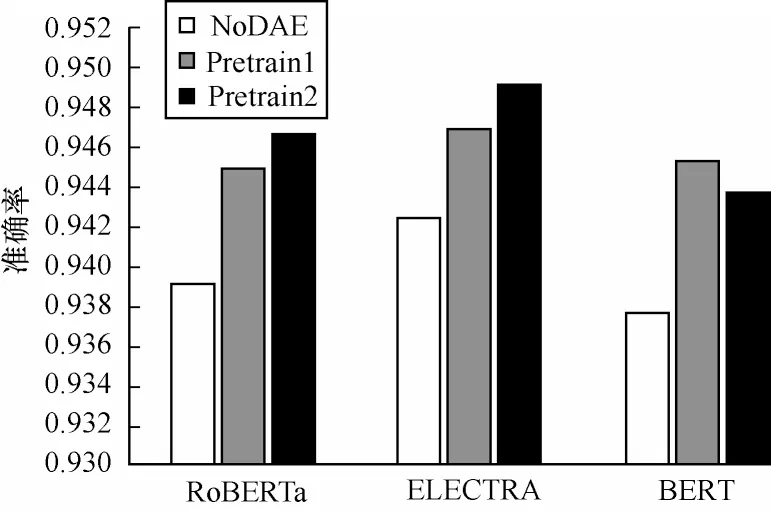
图6 不同模型使用和未使用降噪自动编码器的准确率对比Fig.6 Accuracy comparison among different models with and without denoising auto-encoder
4 结束语
针对基于单一结构数据的预测模型难以全面对患者的患病风险进行准确预测的问题,本文提出融合结构化数据与文本数据的胃癌筛查预测模型。通过结合患者诊疗过程中产生的实验室检验数据与入院记录文本数据,同时对低维度的结构化数据向量表示的维度进行扩增。实验结果表明,相比传统的机器学习模型和深度学习模型,本文模型具有较优的预测性能,为开展大规模人群的胃癌风险筛查提供技术支持。后续将通过引入更多类型的电子健康记录数据,并将其与知识图谱技术相融合,为医生和患者提供更加详细的分类预测结果。
