用于IToF 传感器的极低功耗RISC-V 专用处理器设计
2022-09-15黄正伟刘宏伟
黄正伟,刘宏伟,,徐 渊
(1.深圳大学 电子与信息工程学院,广东 深圳 518060;2.深圳技术大学 大数据与互联网学院,广东 深圳 518118)
0 概述
随着5G 通信技术和人工智能的快速发展,万物互联的时代已经来临。3D 感知作为一种数字成像技术,能够获得物体之间的深度(距离)信息和三维立体信息,因此,3D 感知在计算机视觉、自动驾驶、人机交互、医疗康复和工业安全领域得到广泛应用[1]。ToF(Time of Flight)是目前业内实现3D 感知技术最主要的方案之一,它通过精准地测量光飞行到被测物体再反射回传感器所消耗的时间,计算被测物体与传感器之间的深度,从而得到物体的三维信 息[2]。ToF 的测距方法有2 种,一种是DToF(Direct Time of Flight)直接测距法,另一种是IToF(Indirect Time of Flight)间接测距法[3]。DToF 利用高精度计时器直接计算从光发射到接收的时间差,从而计算得到深度。与DToF 测距方法不同,IToF 测距法让多组不同相位的采样计算窗口对反射光进行测量,并将测量的数据送入处理器,计算发射光与反射光之间的相位差,从而间接地得到光的飞行时间并计算出最终的深度[4]。DToF 测距法和IToF 测距法各有特点,前者的功耗低,精度不会随深度的增加而下降[5],但其分辨率低,难以集成;后者的分辨率高,易集成,但功耗高,精度随深度的增加而降低[6]。
物联网和人工智能的发展使得人们对3D 传感器的需求量日益增加,但是同时带来了功耗等成本问题。从功耗角度出发,设计一款用于IToF 传感器的极低功耗专用处理器具有重要的现实意义。RISC-V 是加州大学伯克利分校提出的第五代开源精简指令集架构[7],与X86 和ARM 指令集架构相比,RISC-V 结构简单,灵活且通用[8],它要求的基本指令集少,但具备的指令集多。RISC-V 不仅不对处理器的实现作过多要求,而且预留了大量的自定义指令编码空间,鼓励设计者对处理器的结构和功能进行创新[9]。目前,开源的RISC-V 处理器(如蜂鸟E203 和PULPissimo)均支持较多的指令集,但是它们针对某一领域在功耗和资源使用上的优化已至极限。例如,开源的处理器在计算深度时需要处理器的多个模块配合多条指令才能完成计算,多个模块的执行会带来资源使用和运行功耗的提高。因此,开源的RISC-V 处理器解决不了IToF 传感器所带来的功耗问题。
本文从专用领域架构出发,设计一款名为IToFminiRV 的拥有IToF 硬件加速器的极低功耗RISC-V专用处理器。IToF-miniRV 的内核资源极少,能够实现RV32IM 通用指令集以及自定义的IToF 型指令。RV32IM 通用指令集包括RV32I 和RV32M 指令集,RV32I 指令集中包括加法、减法、跳转、比较、移位等基本指令,是RISC-V 中必须实现的基本指令集。RV32M 指令集包括乘法、高位乘法、除法、无符号除法、求余等指令,是一种根据需求而灵活设计的非必须指令集。IToF 型指令是自定义的扩展指令,主要负责控制IToF 硬件加速器的执行,而IToF 硬件加速器主要负责对深度和光幅度进行计算。
1 IToF 传感器的测距原理
IToF 测距法又称间接式飞行时间测距法,IToF传感器首先使信号发射器连续发射经过调制的光,然后通过像素阵列收集并解调反射回来的光。发射光和反射光之间的相位差通过转换和运算,就能得到光飞行的时间以及被测物体与传感器之间的深度[10-11]。如图1 所示,信号发射器一般采用光源为850 nm 波长的发光二极管或固态激光管,对人眼来说是不可见光(可见光的波长范围是400 nm~750 nm)。IToF 传感器用于收集与发射光拥有同样频谱的光,同时将光子能量转换为电子电流。需要注意的是,IToF 传感器接收的光中包括反射光和环境光,深度信息存在于反射光中,因此,高的环境光分量会降低测量精度。
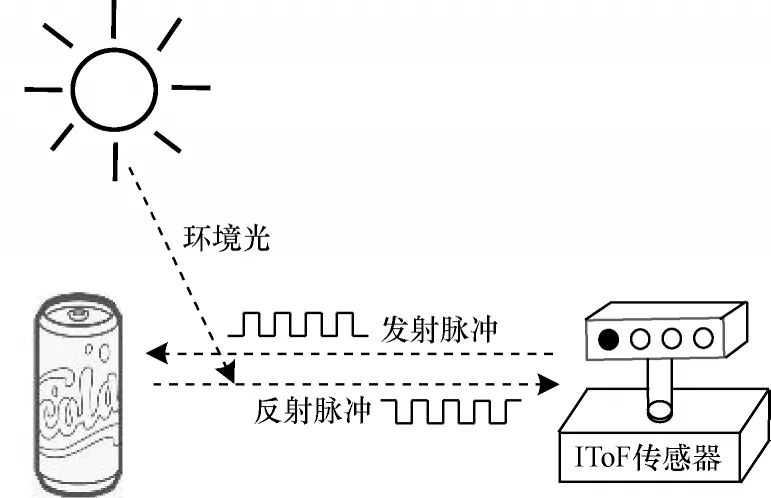
图1 IToF 法的测距原理Fig.1 Ranging principle of IToF method
IToF 传感器一般由像素阵列、相关双采样(CDS)读出电路、数模转换电路(ADC)、激光器驱动电路和数字控制电路组成[12],如图2 所示。激光器驱动电路是发射光光源,用来发射调制光。像素阵列负责采集光并对光进行解调,同时通过光电导效应将光信号转换成电信号。相关双采样读出电路用来处理像素阵列输出的电信号。因为像素阵列输出的电信号中存在噪声信号(如复位噪声信号),会影响传感器测量的信噪比,所以像素阵列的读出电路需要采用相关双采样的方法消除噪声以增强信噪比。像素阵列输出的信号中包含噪声信号和光敏信号,而复位脉冲电平噪声信号是噪声信号的主要成分。CDS方法是指在像素阵列的光电信号积分开始时刻和结束时刻分别进行输出信号采样,前者采样到的是复位电平,后者采样到的是信号电平,其中,2 个采样时刻的时间间隔要远小于常数C·RRon的值(C指采样保持电容,RRon指复位管的导通电阻),这样采样到的2 个电平的噪声电压几乎一致,又因为采样时间是相关的,所示只需要通过将2 个采样电平进行相减处理,就能够基本消除复位噪声的干扰,从而提升输出信号的信噪比。ADC 对模拟电信号进行量化和编码。数字控制电路用于协调其他电路,并将量化编码的值交付给处理器进行相关公式运算,从而得出传感器与被测物体之间的深度。
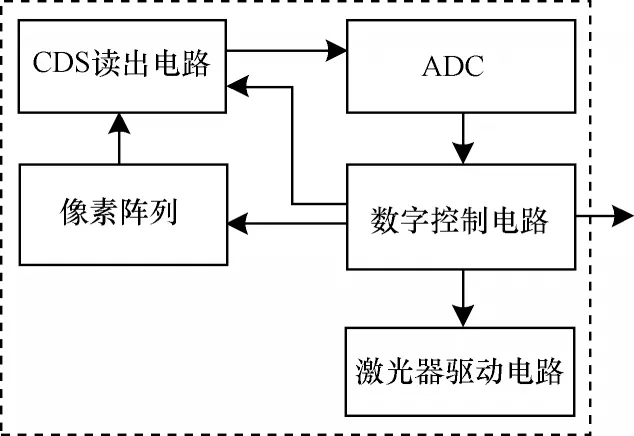
图2 IToF 传感器的系统架构Fig.2 System architecture of IToF sensor
处理器通常采用4-Quad 法计算得到传感器与被测物体之间的深度[13]。如图3 所示,4-Quad 法要求像素阵列采用4 个不同相位的采样计算窗口对接收光进行测量。

图3 4 组采样窗口的采样反射光示意图Fig.3 Schematic diagram of sampling reflected light of four groups of sampling windows
4 个采样窗口C1、C2、C3、C4的相位分别比发射光的相位延迟0°、180°、90°、270°。Q1、Q2、Q3和Q4分别是4个采样窗口采集到的光转换成电信号的能量。4 组电信号能量经过ADC 的量化编码后,处理器将编码的值通过4-Quad 法中如式(1)~式(4)所示的运算,从而得到传感器与被测物体之间的深度等重要信息。
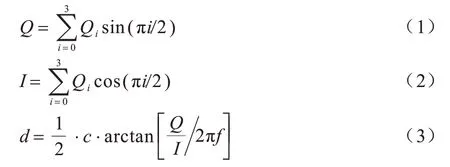

其中:Q为反射光中的正弦分量;I为反射光中的余弦分量;c为光速;f为发射光的调制频率(单位为MHz);d是被测物体与传感器之间的深度;A被称为反射光的亮度或幅度,是评估深度测量精度的重要指标。
2 基于RISC-V 的专用处理器设计
2.1 IToF 硬件加速器设计
4-Quad 法中深度和反射光幅度运算的速度主要受限于硬件中的除法运算、反正切运算和开平方运算。因此,IToF 硬件加速器首先对除法运算、反正切运算和开平方运算进行加速,然后再对计算公式进行优化,最终达到加速的效果。
IToF 硬件加速器设计一个可自定义位宽的带符号除法运算电路模块,并通过路径分割的方式对其进行加速。该除法运算模块包括初始化模块、路径分割模块和递归模块。以N为位宽,初始化模块将被除数初始化成位宽为2N的表示其绝对值的变量,把除数初始化成位宽为N+1 的表示其绝对值相反数的变量,同时声明一个判断商正负的标志信号。路径分割模块采用寄存器堆对递归模块之间的数据进行缓存,从而提升电路运行速度。递归模块是除法运算模块的核心,对运算过程中的中间变量进行算术和逻辑运算,通过N次递归后就能得到最终的商和余数,其中,商值用来提供IToF 硬件加速器中反正切模块和深度距离计算公式中不可或缺的参数值,余数是附带的输出信息。
图4所示为除法运算模块在硬件中实现的算法流程。
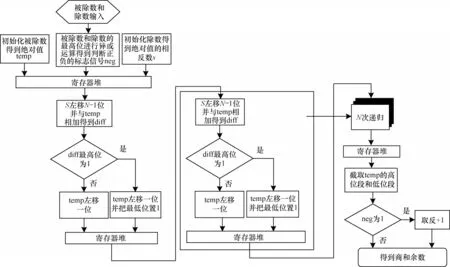
图4 除法运算模块算法流程Fig.4 Algorithm procedure of division operation module
IToF 硬件加速器基于文献[14]提出的算法和反正切公式,推导出新的四象限反正切变换公式,并提出一种基于查找表和二叉树的方法,从而求取反正切值。如图5 所示,该方法把直角坐标系分为a、b、c、d、e 这5 个区域,并在a 区域内采点,将点的x值固定为4 095,这样有利于后续公式的优化并节省硬件的计算和存储资源(x可根据不同系统的精度需求和优化策略设置成任意值),y值作为查找表的地址,从0 开始,以1 为步进增加到4 095,y每增加一次,就计算一次点的反正切值并存入查找表。因此,查找表中存储的反正切值的弧度范围为0~π/4。当点处于a 区域时,直接通过查找表就能获取反正切值,当点处于其他区域时,四象限反正切变换公式先计算偏移量,再将点转移到a 区域,最后通过查找表与偏移量的累加得到反正切值。四象限反正切变换公式如式(5)~式(8)所示:
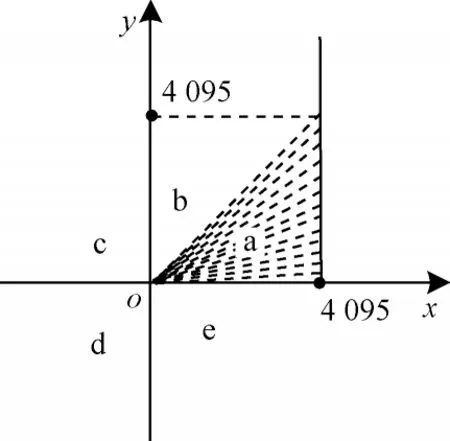
图5 直角坐标系中的采点示意图Fig.5 Schematic diagram of sampling points in rectangular coordinate system
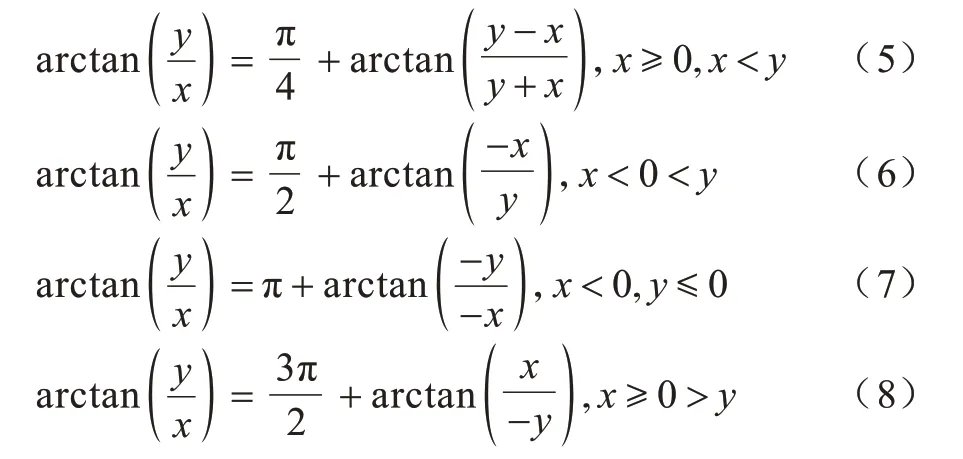
此时,查找表中存储的弧度值属于浮点数,浮点数需要浮点模块进行处理,这会大幅提高处理器的功耗以及对FPGA 资源的使用。因此,本文将0~2π 的弧度值离散化为0~30 000 的整数,经过式(9)的转换,查找表中的值会从0~π/4 的浮点数映射为0~3 750 内的整数。
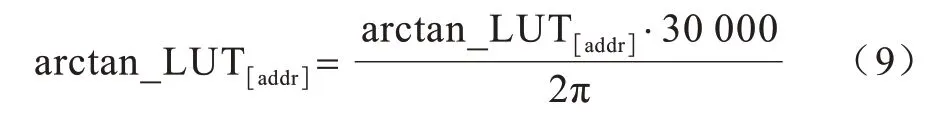
将四象限反正切变换公式和查找表在硬件电路中进行实现,就能得到一个输出分辨率为的反正切电路模块。图6 所示为反正切运算模块在硬件中实现的算法流程。
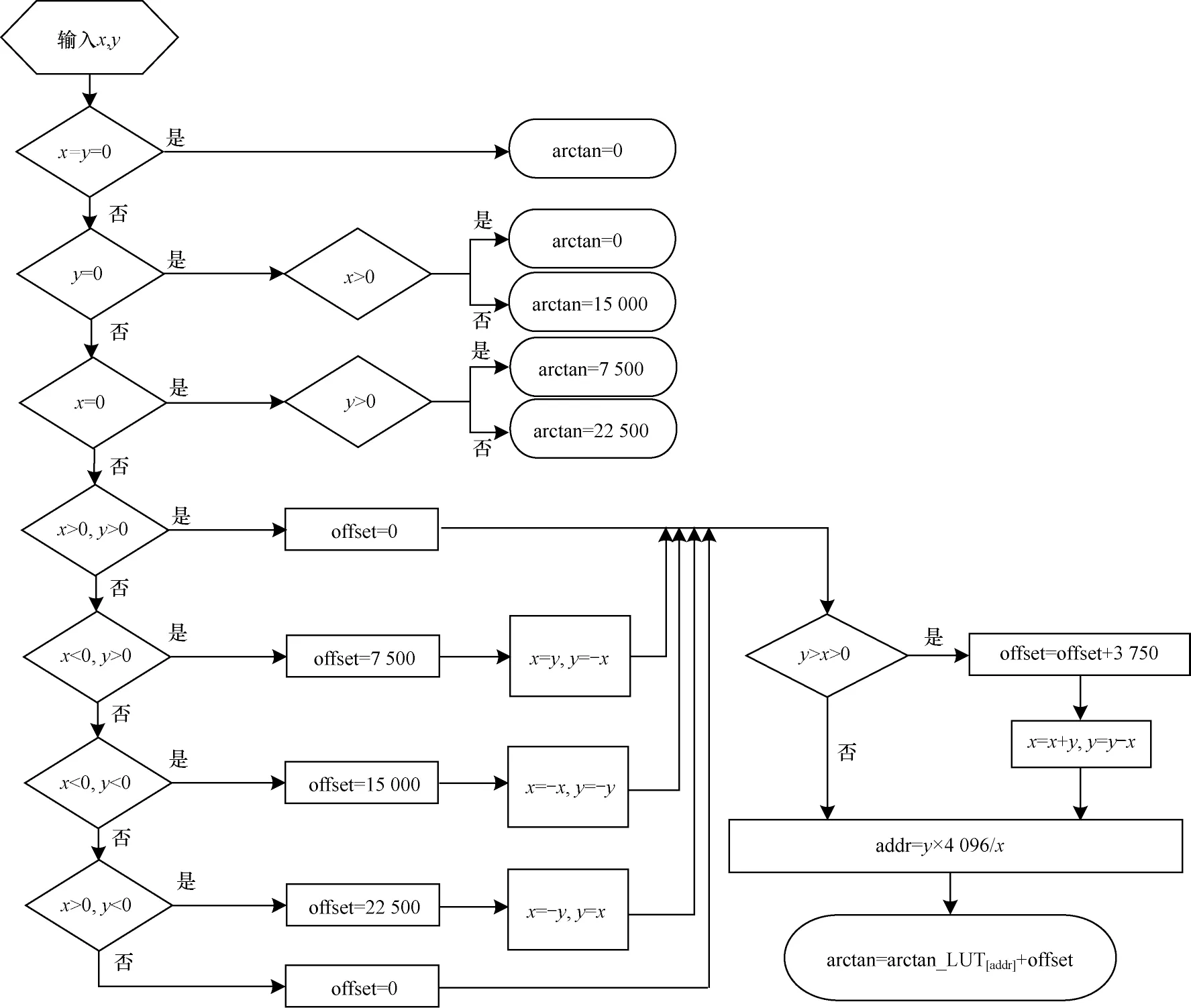
图6 反正切运算模块算法流程Fig.6 Algorithm procedure of arctangent operation module
IToF 硬件加速器根据二进制平方运算的计算过程,逆推导出一种逐次逼近的、可自定义位宽的开平方模块,其包括数据预处理模块、函数M(W,I)模块、路径分割模块和递归模块:
1)数据预处理模块根据输入数据的位宽对模块内的参数进行修改,并根据参数的值初始化用于保存递归运算结果的存储器。
2)路径分割模块用于缓存递归模块的输出数据。
3)递归模块负责对中间变量进行逻辑运算从而逼近最后结果。
4)式(10)是函数M(W,I)的表达式,函数M(W,I)模块的本质是以逻辑运算和算术运算的动态方式,给每一阶段的递归模块提供参数及其参数运算得出的对比值,相比于查找表这种动态方式,M(W,I)模块能节省大量的硬件存储资源。
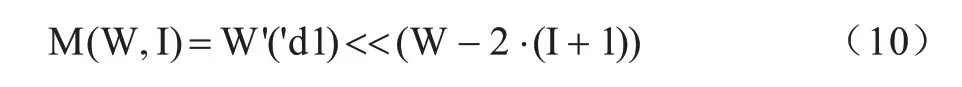
图7 是开平方模块的算法流程,其中,对虚线框内的运算步骤进行N-1 次递归操作。
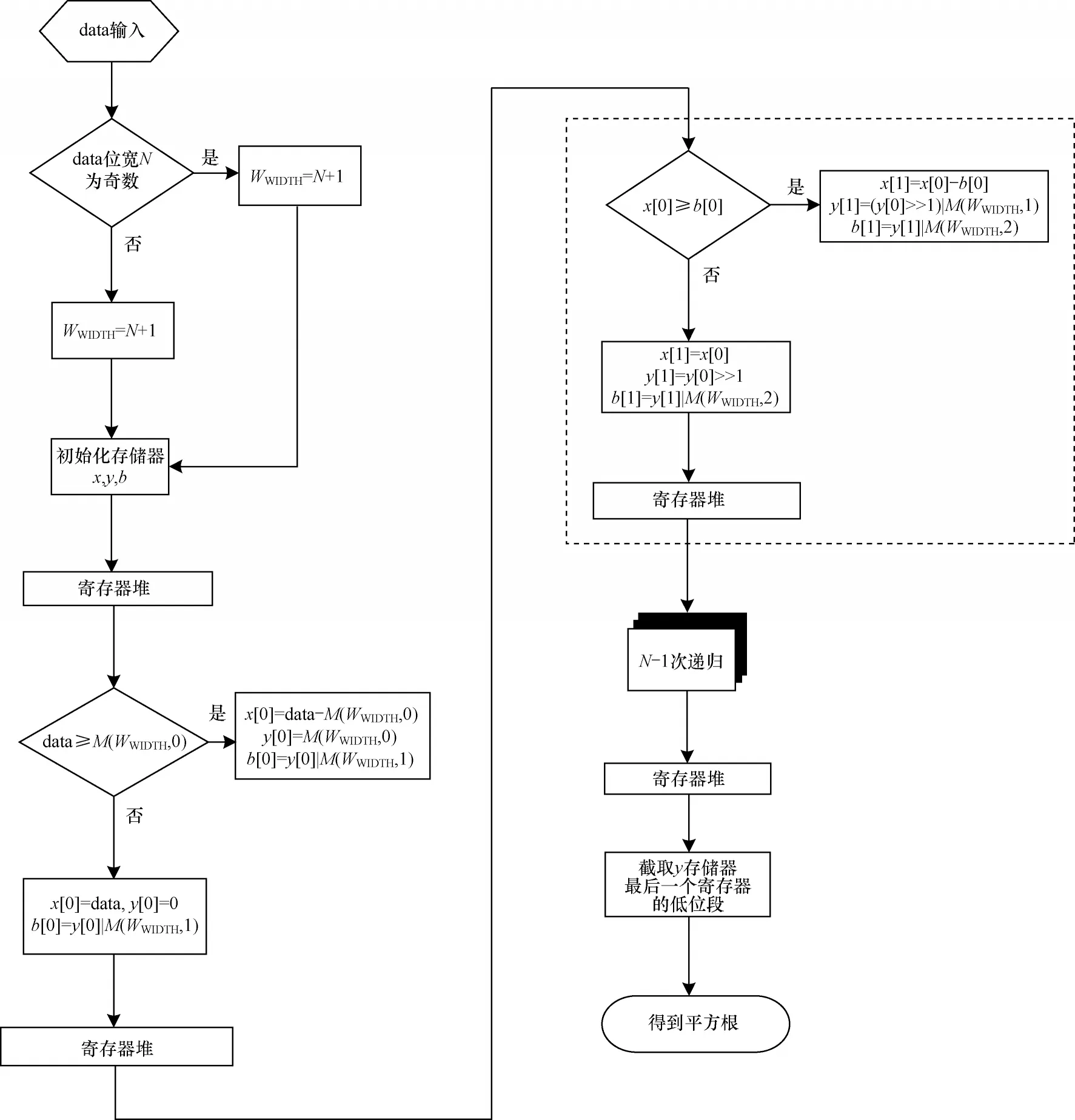
图7 开平方运算模块算法流程Fig.7 Algorithm procedure of square root operation module
基于以上的算法实现,深度计算公式可简化为式(11):

其中:d是小数点在第11 位的定点数;n是发射光的调制频率(单位为Hz)。
例化除法运算模块、反正切运算模块和开平方运算模块,构建一个完整的IToF 硬件加速器,其系统架构如图8 所示。
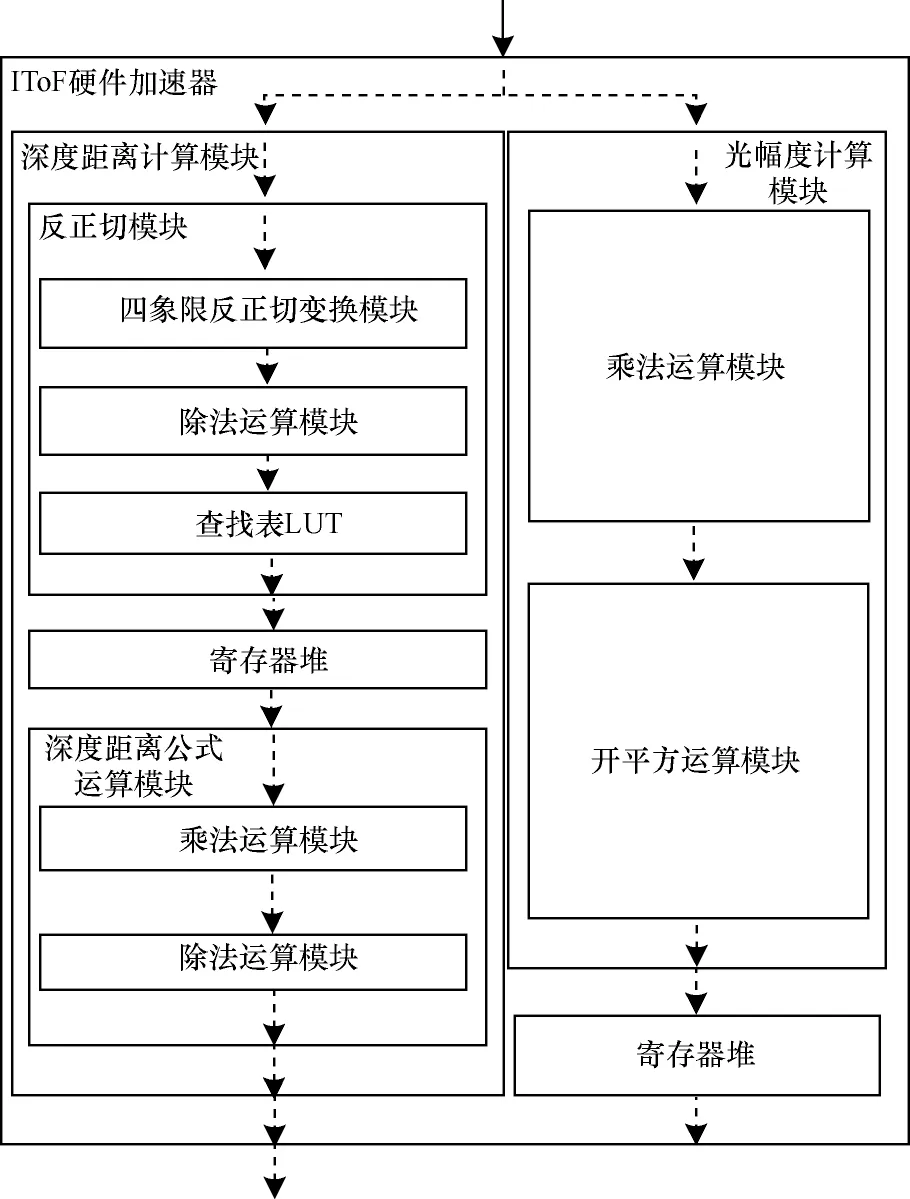
图8 IToF 硬件加速器系统架构Fig.8 System architecture of IToF hardware accelerator
2.2 基于RISC-V 的极低功耗处理器设计
RISC-V 是一个具有典型三操作数、加载-存储形式的精简指令集架构,其包括3 个基本整数指令集(RV32I、RV64I、RV128I)和6 个扩展指令集(M、F、A、D、Q、C)[15],并且提供了自定义指令的编码空间。RISC-V 只对I 指令集提出了实现要求,对于其他指令集,设计者可根据需求自行实现和定义。目前,芯来科技公司推出了一款基于RISC-V 的超低功耗处理器——蜂鸟E203[16],该处理器以2 级流水线为主体,支持RV32IEAMC 指令集,其功耗面积和性能不逊色于ARM 最小面积的处理器Cortex-M0+。瑞士苏黎世联邦理工大学和意大利博洛尼亚大学联合设计研发了一款名为PULPissimo 的超低功耗RISC-V处理器,PULPissimo 具有良好的灵活性,其内核既可以被配置为以4 级流水线为主体且支持RV32IMC 指令集的RI5CY,也可以被配置为以2 级流水线为主体且支持RV32IC 指令集的zero-riscy。目前,PULPissmo 主要被用于多核PULP 芯片的系统控制器[17]。
本文从极低功耗出发,设计一款支持RV32IM指令集的处理器,该处理器拥有32 位的地址空间和整数指令,以3 级流水线为主体[18],采用静态分支预测技术。处理器还拥有自定义的主从一对一的oto总线,为扩充处理器的资源和功能创造了条件。
本文处理器的系统框架如图9 所示,处理器的内核主要包括指令获取模块、静态分支预测模块、预译码模块、数据传输模块、指令译码模块、指令执行模块、控制模块、中断模块、通用寄存器堆和csr 寄存器堆等。处理器的外设包含具有哈佛结构的指令和数据存储器模块、指令仲裁器模块、计时器模块、通用I/O 模块和串口通信模块。处理器的内核主要完成对指令的获取、译码和运算。处理器的外设主要为处理器内核提供指令和数据的存储空间,以及为处理器添加常用的资源和功能。在通常情况下,处理器处理一条指令需要3 个时钟周期:在第一个时钟周期内,指令获取模块通过指令仲裁器从指令存储器模块中读取指令,并把指令分别派送给预译码模块和分支预测模块进行解析;在第二个时钟周期内,指令译码模块对指令进行译码,并根据译码的信息从通用寄存器堆或csr 寄存器堆中读取源操作数,并将源操作数交付给数据传输模块;在最后一个时钟周期内,指令执行模块根据译码的信息对操作数进行逻辑或算术运算,并把运算的结果写入寄存器堆或通过总线写入数据存储器。
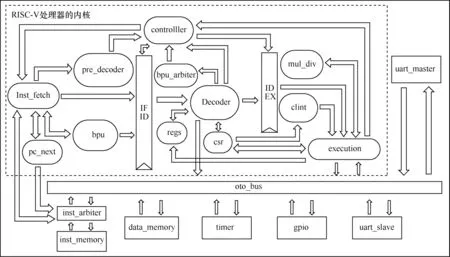
图9 极低功耗RISC-V 处理器系统架构Fig.9 System architecture of ultra-low-power RISC-V processor
在某些特殊情况下,处理器在处理多条指令时会出现数据冲突、结构冲突等异常:数据冲突一般指上一条指令没有及时更新下一条指令所需的源操作数,导致处理器运算错误的情况;结构冲突一般指同一个时钟周期内一个模块需要同时应答多条指令的请求,从而出现运算错误的情况。处理器中的控制模块会根据异常的原因对数据传输模块和指令获取模块进行数据冲刷和指令丢弃等处理。数据冲刷即丢弃某个数据传输模块中缓存的数据,不让其传入下一个阶段进行计算或存储,从而避免错误的运算结果被保存在寄存器堆或数据存储器中。指令丢弃即控制模块结合当前处理器的运行状态判断出当前指令会引起处理器异常所进行的操作,其目的是不让当前指令进入译码阶段,从而避免后续的异常。待处理器结束当前状态,被丢弃的指令会被重新获取并执行。
2.3 专用处理器系统构建
领域扩展自定义指令是构建专用处理器系统的关键步骤。例如,文献[19]基于RISC-V 扩展了针对GNSS 信道编码的专用指令,文献[20]基于RISC-V扩展了用于低开销SM4 算法实现的专用指令,文献[21]基于RISC-V 扩展了用于卫星信号通信的专用指令。
本文IToF-miniRV 以极低功耗RISC-V 处理器为基础,将IToF 硬件加速器挂载到RISC-V 处理器上,并为其在处理器中的识别与操控定义一种IToF 型指令,该类指令的格式如图10 所示。

图10 IToF 型指令格式Fig.10 IToF type instruction format
在IToF 型指令格式中:opcode 位段为操作码,用于处理器对该指令进行识别[22];funct3 位段为指令的功能码,用于处理器对IToF 硬件加速器进行多种操 控[23],目前处理器对IToF 硬件加速器有start、pause 和remake 这3 种操作,其funct3 位段分别对应于00001、00010、00000;number 位段为指令的一个参数,用于指示处理器计算的数据量;frequency 位段为IToF 硬件加速器需要的发射光调制频率参数。
图11 所示为IToF-miniRV 的系统框架,其中,IToF_DSA 是IToF 硬件加速器,Pixel_memory 用 于存放4 组采样窗口的数据。处理器在指令执行阶段启动IToF_DSA,IToF_DSA 开始从Pixel_memory 中读取数据,经过53 个时钟周期后,每隔一个时钟周期就计算出一组深度值和光幅度值,并将其组合成32 位的数据,存储在数据存储器中,直到计算完指令中指定的数据量。在此期间,处理器可以在任意时刻暂停IToF_DSA 的计算,从而释放总线让处理器执行其他指令,也可以根据即时的调试需求重新开始IToF_DSA 的取值、计算和存储,从而更新并覆盖数据存储器中已有的深度和光幅度数据。
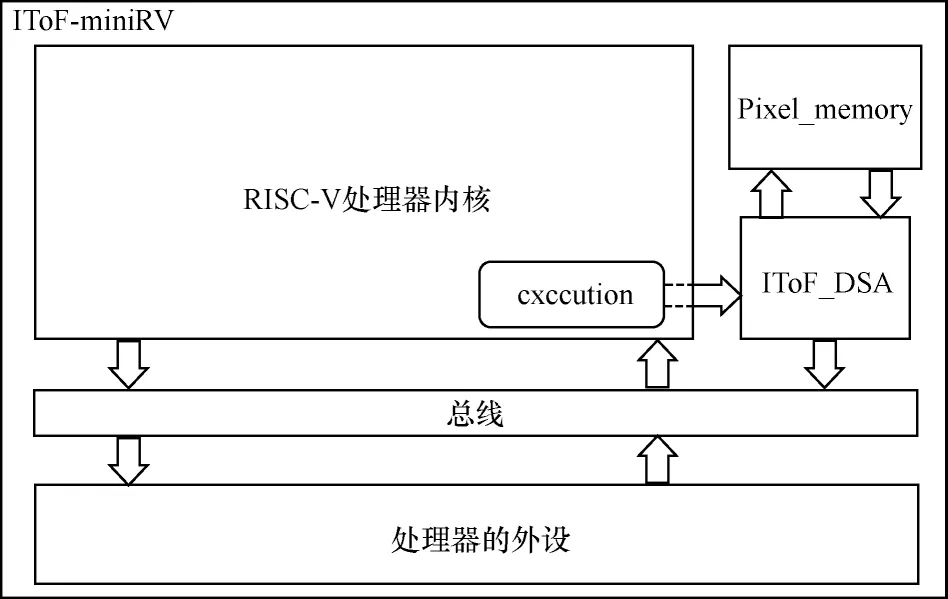
图11 IToF-miniRV 的系统架构Fig.11 System architecture of IToF-miniRV
3 实验结果与分析
本文实验数据来源于IToF 传感器在发射光调制频率为54 MHz 时采集到的像素数据,每一组像素数据为48 bit,包含4 个采样计算窗口测量的数据。表1 列出了IToF-miniRV 在50 MHz 时钟频率下计算64 组、256 组、1 024 组、4 096 组像素数据时的性能指标,数据对比如图12、图13 所示。

表1 IToF-miniRV计算不同数据量像素数据时的性能指标Table 1 Performance index of IToF-miniRV when calculating pixel data with different data volumes
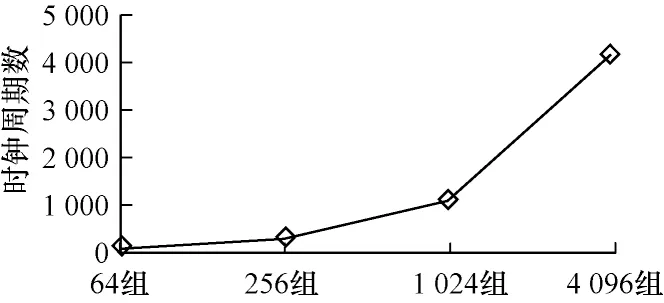
图12 计算不同数据量像素数据所需的时钟周期数Fig.12 The number of clock cycles required to calculate pixel data with different data volumes
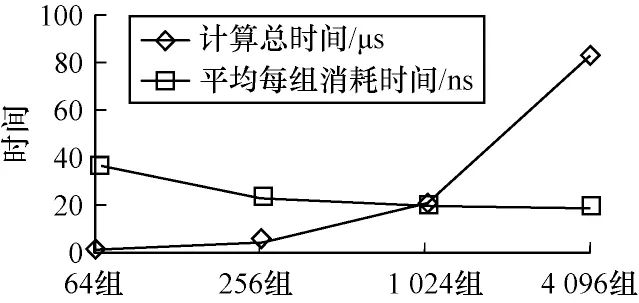
图13 计算不同数据量像素数据所花费的总时间和平均时间Fig.13 The total and average time taken to calculate pixel data with different data volumes
从表1 可以看出,计算数据量越大,平均每组数据消耗的时间越少,当计算的数据量不少于256 组时,平均每组数据消耗的时间小于25 ns。从图12 可以看出,随着像素数据量的增大,其所需的时钟周期数提高并逐渐趋于线性关系,这是因为随着数据量的增大,IToF 硬件加速器初始化所需的时钟周期数占总周期数的比例越来越小。IToF 硬件加速器经过初始化过程后,每过一个时钟周期就能计算完一组数据,使其所需时钟周期数与数据量呈线性增长关系。由于计算总时间为时钟周期数与时钟周期的乘积,因此图13 中的计算总时间也会随着数据量的增大而逐渐以线性趋势增加。同理,因为经过初始化过程后,每一个时钟周期就能计算完一组数据,随着数据量的增长,平均每组数据花费的时间无限趋近于时钟周期20 ns。
图14、图15 分别是实物测量场景图和实物测量结果。表2列出了实物测量的深度和光幅度的相关数据。

图14 实物测量场景图Fig.14 Physical measurement scene graph

图15 实物测量结果Fig.15 Physical measurement result
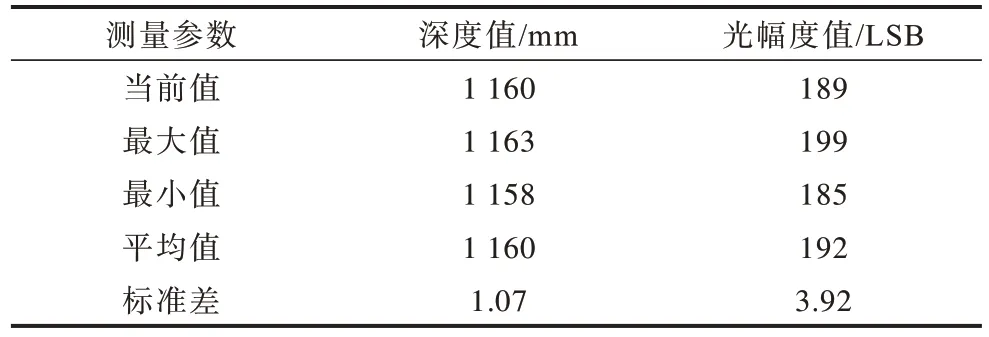
表2 深度和光幅度的实物测量数据Table 2 Physical measurement data of depth and light amplitude
将超低功耗处理器蜂鸟E203 和PULPissimo 下载到Xilinx Zynq-7000 芯片上,得到它们在FPGA 上各项资源的使用和功耗情况。表3列出了IToF-miniRV、E203 和PULPissimo 处理器在Zynq-7000 芯片上的资源使用情况对比结果。
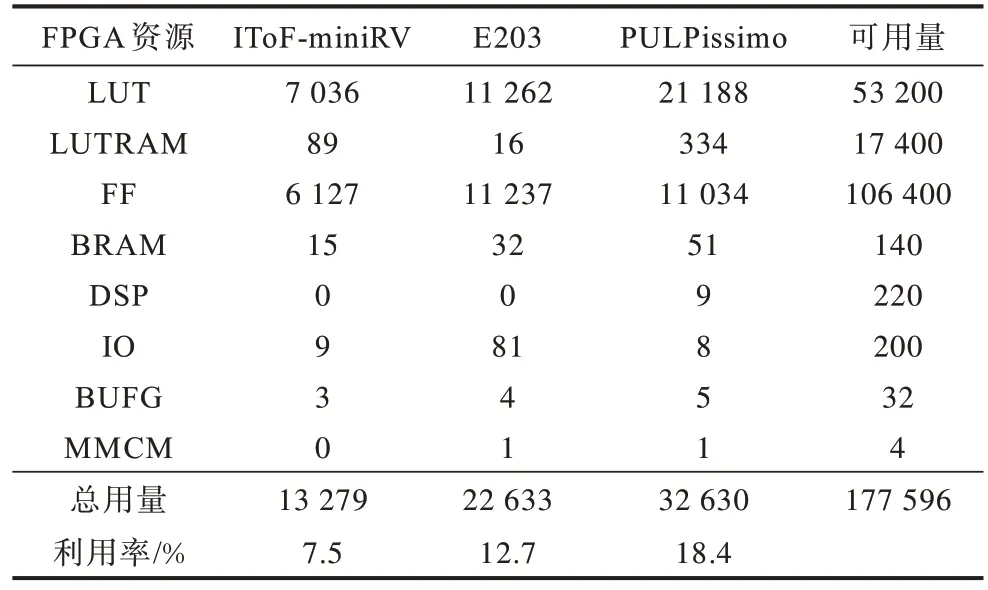
表3 IToF-miniRV、E203、PULPissimo的资源使用情况对比Table 3 Comparison of resource usage of IToF-miniRV,E203 and PULPissimo
从表3 可以看出,IToF-miniRV 总资源利用率为7.5%,相对蜂鸟E203 的总资源利用率12.7%减少了5.2 个百分点,相对PULPissimo 的总资源利用率18.4%减少了10.9 个百分点。
表4列出了IToF-miniRV、蜂鸟E203和PULPissimo在Zynq-7000 芯片上的功耗对比。其中,蜂鸟E203的工作时钟频率为16 MHz,PULPissimo 的工作时钟频率为65 MHz。

表4 IToF-miniRV、E203、PULPissimo 的运行功耗对比Table 4 Comparion of operating power consumption of IToF-miniRV,E203 and PULPissimo W
从表4可以看出,IToF-miniRV的总功耗为0.166 W,比蜂鸟E203 的0.266 W 降低了37.6%,比PULPissimo的1.614 W 降低了89.7%。
4 结束语
本文提出用于加速IToF 深度和光幅度计算的硬件加速器,同时设计一种支持RV32IM 指令集并具备自定义IToF 型指令功能的极低功耗RISC-V 处理器,将两者相结合构成一款用于IToF 传感器的极低功耗RISC-V 专用处理器IToF-miniRV。实验结果表明,IToF-miniRV 能够减少资源使用并具有较低的运行功耗,其FPGA 资源使用率相比蜂鸟E203 和PULPissimo 分别减少5.2 和10.9 个百分点,运行功耗分别降低37.6%和89.7%。下一步将对IToF-miniRV的内核进行时序优化,使整个处理器能够在更高的时钟频率上工作,同时对IToF-miniRV 进行版图的生成、优化以及流片。
