基于网络资源流量的链路预测方法
2022-09-15刘宇航尹小庆
刘宇航,尹小庆,林 云
(1.重庆大学 机械与运载工程学院,重庆 400044;2.重庆大学 管理科学与房地产学院,重庆 400044)
0 概述
链路预测是根据网络中的已有节点信息来预测缺失的节点或链路,它是运用微观层面网络演化机制进行预测的重要方法。依据网络特征提取角度的不同,现有链路预测可分为基于相似性、基于极大似然估计、基于概率模型、基于机器学习这4 类方法。其中,基于相似性的方法结构较为简单,同时普适性强且效率高。相似性方法是基于节点之间的接近程度(即2 个节点连接的概率大小)[1]所定义,节点相似性可以通过分析节点属性网络拓扑结构信息而得到。但是在实际应用中,节点属性信息往往很难获得,并且信息的可利用率和可靠性都很低[2]。相比之下,网络拓扑结构信息非常容易获得,并且一系列实证结果也表明其可靠性较高,因此,利用网络拓扑结构信息获取相似性被研究人员广泛认同[3],对于一对节点x和y,可以利用网络结构信息计算它们的相似性分数[4]。
目前,利用网络结构信息判断节点相似性的方法可分为基于局部信息、基于全局信息、基于准局部信息等方法。局部信息是指节点周围有限的网络结构信息,如节点的度大小、节点的最近邻居,因为该类方法在计算相似度时只利用节点的局部拓扑信息而非所有结构信息,所以计算复杂度低,适用于大型网络,但与此同时,该类方法存在的缺陷是准确度不够。这类相似性方法的评估指标主要有CN[5]、Salton[6]、Sorensen[7]、Jaccard[8]、AA[9]、RA[10]、PA[11]等。利用全局信息的方法考虑整个网络的拓扑结构信息,使得链路预测更为灵活和准确,但同时提高了时间复杂度,处理大型网络时效率较低。这类相似性方法的评估指标主要有Katz[12]、ACT[13]、RWR[14]、Cos+[15]等。基于准局部信息的方法通过多跳路径或局部随机游走的方式,在局部信息的基础上引入更多的拓扑信息,相比于全局方法,其计算复杂度较低,而相比于局部方法,其准确度有所提升,该类方法综合了局部方法和全局方法的优势。这类相似性方法的评估指标有LP[16]、L3[17]等。
基于相似性的链路预测方法仍然不够理想,特别是当面对大型数据集时计算复杂度较高,而面对小型数据集时准确度较低。局部方法受限于精准度,而全局方法又受限于计算复杂度。因此,大量的准局部方法被提出,它们结合局部方法和全局方法的优势来实现计算复杂度和精准度的均衡。
RSP[18]指标可以度量路径与资源接收过程的交互关系,每个节点获得一定的初始资源,然后路径上的中间节点可以从它们的邻居接收资源。大量实验结果表明,RSP 指标性能表现良好。NCNLC[19]指标通过结合节点全局归一化共同邻居属性与局部聚类系数来达到平衡全局和局部信息的目的,并将周围邻居节点的连接强度纳入指标的考虑范围。在时序仿真的预测过程中,NCNLC 表现出优越的性能,整合了全局和局部指标的优势。通过短路径连接另一个端点的强关系可以带来更强的影响力,而通过长路径连接的强关系只能带来较弱的影响力,基于这一思想,SI 被提出[20],其通过区分强影响和弱影响来模拟实验的影响。PSI[21]的目标是通过整合局部路径上的节点信息来提高现有基于路径方法的准确性,它结合了Adamic Adar 和Katz 这2 种应用最广泛的相似度指标的优点,而且性能更优。RA 方法利用共同邻居节点进行资源传输分析,但其忽略了共同邻居节点周围的拓扑结构。TT[22]方法在RA 的基础上进行改进,利用资源传输节点的拓扑紧密性,根据节点周围拓扑集聚程度进行量化,并根据传输节点紧密性对共同邻居传输资源量的影响来刻画节点间的相似性。实验结果表明,相比于基准方法,TT 方法所得指标的普适性更好,预测准确度更高。受端点之间资源交换的启发,ERA[23]在RA 的基础上进行改进,增加更长的路径并通过参数调整不同网络长路径转移的资源量,节点之间通过区分共同邻居和非共同邻居交互的资源量来衡量相似度。
通过上述分析可以看出,准局部指标能够结合局部指标和全局指标的优势,在计算复杂度较低的情况下达到较高的精准度。受到网络资源分配思想的启发[24],通过研究无标度网络中资源流量的动态行为,设定网络中的资源能够自由流动这一动态机制,本文提出一种基于网络资源流量的链路预测方法。为网络设计一种资源流动规则,赋予被预测节点对一定量的资源,使资源自由流动,计算被预测节点对之间的双向流量之和,从而得出相似性分数,其中,流量之和越大,相似性分数越高。该方法通过充分利用节点属性信息、邻域拓扑结构以及路径因素,以提升链路预测的准确度。
1 链路预测相关指标
1.1 相似性指标
相似性指标用来衡量链路预测方法的准确性,以及判断链路存在的可能性。本文给出几种常见的用于对比预测性能的基础指标,包括局部、准局部以及全局指标,分别为CN、Salton、Jaccard、AA、RA、LP、Katz,这7 个指标将作为实验部分的对比参照指标,具体信息如下:
1)CN 表示2 个节点之间共同邻居节点的数目,计算公式如下:

其中:x和y分别代表网络中2 个不同的节点;Γ()表示节点的所有邻居节点集合。
CN 等价于2 个节点间长度为2 的路径数目:

2)Salton 又称余弦相似性指标,计算公式如下:

其中:k代表节点的度。
3)Jaccard 表示从节点对的任意一个节点的所有邻居中选择共同邻居节点的概率,计算公式如下:

4)AA 对CN 指标进行改进,旨在通过为连接较少的邻居分配更多权重来提高共同邻居的准确性,其计算公式如下:

5)RA 由复杂网络的资源配置过程所驱动,考虑节点对的所有共同邻居节点有且仅有一个单位资源,并将它平均分配给所有邻居节点,从而进行资源传递,其计算公式如下:

6)LP 又称局部路径指标,在CN 的基础上引入三阶路径指标,并给予三阶路径一个惩罚因子,其计算公式如下:

7)Katz 指标考虑节点对之间所有路径的集合,路径的长度以指数方式衰减,从而给较短路径更多的权重。由于该指标是基于整个网络的拓扑结构,因此其计算成本通常比局部指标高,而精确度往往也高于局部指标。Katz 指标的计算公式如下:

1.2 本文评价指标
本文使用2 个公认的链路预测常用指标对预测精度进行描述:
1)AUC,表示ROC 曲线下的面积[25],是应用最广泛的链路预测性能评价指标之一。AUC 表示随机选择的一个缺失连边的相似性得分高于随机选择的一个不存在连边的相似性得分的概率[26]。如果采用随机选择的方式,在多次独立重复实验后,AUC的值应当是0.5。链路预测方法需要提高这个概率,即AUC 的值越大,说明该方法越精确。假设进行n次取样,则AUC 的计算公式如式(9)所示:

其中:n'代表测试集中边分数值大于不存在边的分数值的次数;n″表示两者分数值相等的次数。
2)Precision,表示前L条边中有m条边预测准确的比例,即排在前L条的边中有m条属于测试集。与AUC 不同,Precision 只关心前L条边是否预测准确[27],Precision 在某些特定情形下(如只关注排在前L条边的预测准确与否)比AUC 更有意义。Precision计算公式如下:

2 网络资源流量方法
2.1 网络资源流量评估方法
受到网络资源分配的启发,本文将节点对之间路径上的中间节点作为资源传输的媒介,通过计算节点对之间网络资源流量的总和,提出一种RF(Resource Flow)方法以计算节点对的相似性。首先,网络中的每个节点都有一定单位的初始资源,且这个资源可以根据节点的度大小进行传输,进而将2 个节点之间的相似度计算转变为2 个节点之间所有阶路径资源流量的计算,如果2 个节点之间资源流量越多,说明它们的联系越紧密,则相似性越高。
如图1 所示,假设该无向图中存在15 个节点和15 条边,节点1 和节点5 没有直接相连,而是通过一条2 阶路径和一条3 阶路径相连,这2 条路径经过的中间节点被标记为黑色。路径资源流量方法的思想是:给予网络中被预测的节点对(节点1 和节点5)一定单位的初始资源R,该资源会按照均分的原则传输到节点对的所有邻居节点中,邻居节点在接收资源后会继续平均传给其所有的邻居节点。此时,初始资源R就会在网络中进行流动,可以通过计算节点1 流向节点5 的初始资源流量和节点5 流向节点1的初始资源流量之和,得到节点对(节点1 和节点5)的相似性分数。资源流量越多,说明这2 个节点越相似。

图1 资源流动过程Fig.1 Resource flow process
2.2 网络资源流量量化
本文对网络资源流量量化作出如下定义:
定义1假设存在无向网络G(V,E),网络中共有n个节点,i表示节点序号。在初始情况下,赋予每个节点vi∈V的资源表示为:
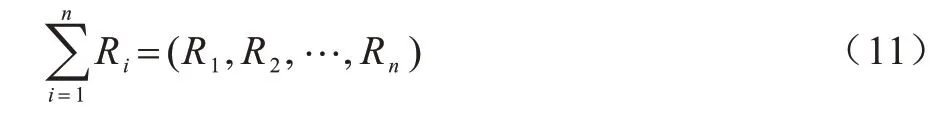
定义2网络分为动态和静态2 种状态,在动态时,网络中的节点会向自己的邻居节点传输资源,而在静态时不会传输。2 种状态的集合表示为:

定义3在动态网络中,节点会向每个邻居节点传输资源,传输的资源量统一按照均分的原则分配给每一个邻居节点,即节点向每个邻居节点传输等量的资源。同时,节点也会接收来自邻居节点传输的资源,接收量取决于邻居节点的传输量。节点向其邻居发送的资源和从邻居处接收的资源分别如下:
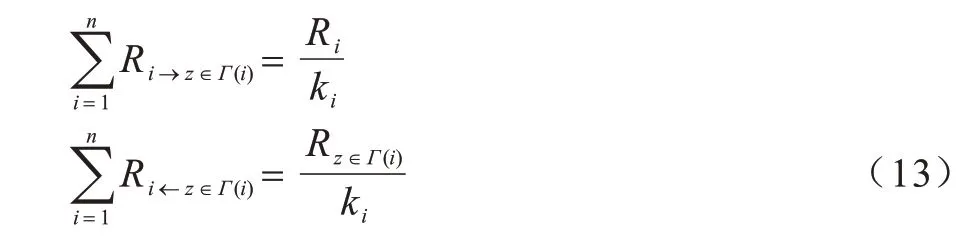
其中:k是节点的度;z∈Γ(i)表示节点vi的邻居节点;Ri→z∈Γ(i)表示vi向其邻居发送的资源;Ri←z∈Γ(i)表示节点vi从其邻居处接收的资源。
定义4为了表示路径中节点对于资源量的传输作用,提出一个新的概念,即路径节点n。给定一对节点(x,y),l为它们之间路径的最大长度。假设在节点x到节点y之间的长度为1~l的路径上存在一些中间节点,将这些节点定义为中间路径节点。x和y之间的中间路径节点可以用集合表示为:

在节点vi到节点vj的某条路径中,依次经过m个节点,第1 个节点为1 阶路径节点,第2 个节点为2 阶路径节点,第m个节点为m阶路径节点。m取值为0~(l-1)范围内的正整数,当m=0 时,代表2 个节点之间没有任何一条路径将它们相连。路径节点的数目为路径数目减1,即l-1。由vi到vj和由vj到vi,路径节点索引值相加为m+1,即:

定义5在一个动态网络中,给定一对节点(x,y),节点之间的路径长度为l,它们之间流动的资源总量可以通过2 个步骤进行计算:首先,节点x和节点y分别将初始资源发送给邻居;然后,在x和y之间路径上的资源流将由中间路径节点分别发送到其邻居节点。每个中间路径节点将从邻居处接收资源,并将资源平均交付给下一个中间路径节点,因此,在交付之前资源量是1/(k-1)。根据RF 指标的定义,随着路径数的增加,资源流量经过的路径节点增多,初始资源会被不断稀释,称其为路径稀释作用。资源流量计算过程如图2 所示。
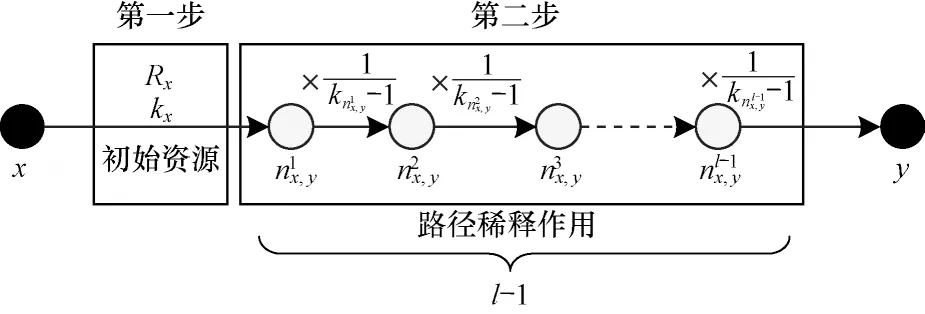
图2 资源流量计算过程Fig.2 Resource traffic calculation process
假设节点x和节点y向相邻节点传输R个单位的资源,节点间路经上的总资源流量计算分为两步:
1)第一步,计算节点x和节点y发送给邻居的初始资源,即:

2)第二步,计算路径长度为l-1 的中间路径节点的贡献值,即:

定义6给定一对节点(x,y),l是它们之间路径的最大长度。表示从节点x到节点y的长度 为m+1 的所有路径个数。x、y之间所有中间路径节点的贡献即为x和y之间双向流动的资源之和,表示如下:

不同节点在网络中的重要性不同,为了突显这个特征,需要给每个节点分配不同的初始资源。一般地,节点的重要性用“中心性”来衡量。本文利用2 阶局部指标(即该节点与其他节点存在共同邻居节点的比例)来进行初始资源分配。如果网络中的一个节点与其他n-1 个节点之间存在的共同邻居数目越多,则认为该节点越重要,给它分配更多的资源,用节点邻居数与其余节点总数的比值来表示,即:

其中:Ri代表第i个节点的初始资源。
2.3 链路预测求解
本文算法的输入变量是无向网络,需要计算节点对(x,y)的相似性和中间路径节点的阶数l。输入无向网络G之后,首先将其转换为邻接矩阵的形式,以得到所有节点和连边的信息,然后计算所有节点的初始资源和它们的度,得到2 个n维向量,数值对应于每一个节点的资源和度。对于给定的节点对(x,y),使用深度优先遍历方法找出网络中的所有路径,假设网络有n个节点,花费的时间复杂度为O(n2)。这些路径中的节点除了起点和终点之外都是中间节点。假设考虑1 阶到l-1 阶的所有中间节点的作用,并且遍历出的所有路径数为k,那么该过程的时间复杂度就为O(k(l-1)),因此,RF 算法总的时间复杂度为O(n2+k(l-1)),l的最大值为n-2,即x经过除x、y节点之外的所有节点到达y,时间复杂度最高为O(n2+kn-3k)。RF 算法描述如下:
算法1RF 算法


3 实验结果与分析
为了评估本文所提链路预测算法RF 的性能,将其与目前最常用的7 种链路预测基准方法进行实验对比与分析。
3.1 数据集
实验使用来自真实世界的11 个不同的复杂网络数据集,这些数据集来源于多种不同的网络,如社交网络、生物网络、交通信息网络以及引文网络等。11 个网络数据集的具体信息如下:
1)NS[28]:科学引文合作网络,代表论文之间的引用合作关系。
2)PB[29]:美国政客之间的博客交互网络。
3)Yeast[30]:大型蛋白质相互作用网络,包含2375个节点和11 693 个链接。
4)Jazz[31]:爵士乐音乐家之间的合作网络,代表音乐作品之间的合作关系。
5)Metabolic[32]:秀丽隐杆线虫新陈代谢网络。
6)BUP[33]:某政客博客网络。
7)UAL[34]:飞机交通系统网络。
8)INF[35]:展览中观众面对面接触的网络。
9)SMG[36]:不同研究领域作者的论文合作网络。
10)Celegans[37]:秀丽隐杆线虫的神经网络。
11)EML[38]:罗维拉大学成员之间的电子邮件交互网络。
11 个网络的基本拓扑信息具体如表1 所示。

表1 11 个真实世界网络的基本拓扑信息Table 1 Basic topology information of eleven real-world networks
3.2 不同参数情况下的RF 预测精确度
考虑到RF 的时间复杂度过高会大幅提高对比实验的难度,此外,针对路径信息的方法,利用2 阶路径和3 阶路径的信息最为准确,从4 阶之后准确度开始下降[39]。因此,本文只考虑1 阶、2 阶、3 阶的中间路径节点,通过设置l值为4 来降低时间复杂度,最终时间复杂度为O(n2+3k),从而在计算复杂度不高的同时最大化地提升准确度。首先,只利用RF 算法计算11 个网络中的AUC 和Precision,横向对比RF 在利用不同阶数的路径节点时的性能表现。本节与下一节的实验中统一设置训练集与测试集的比例为9∶1。
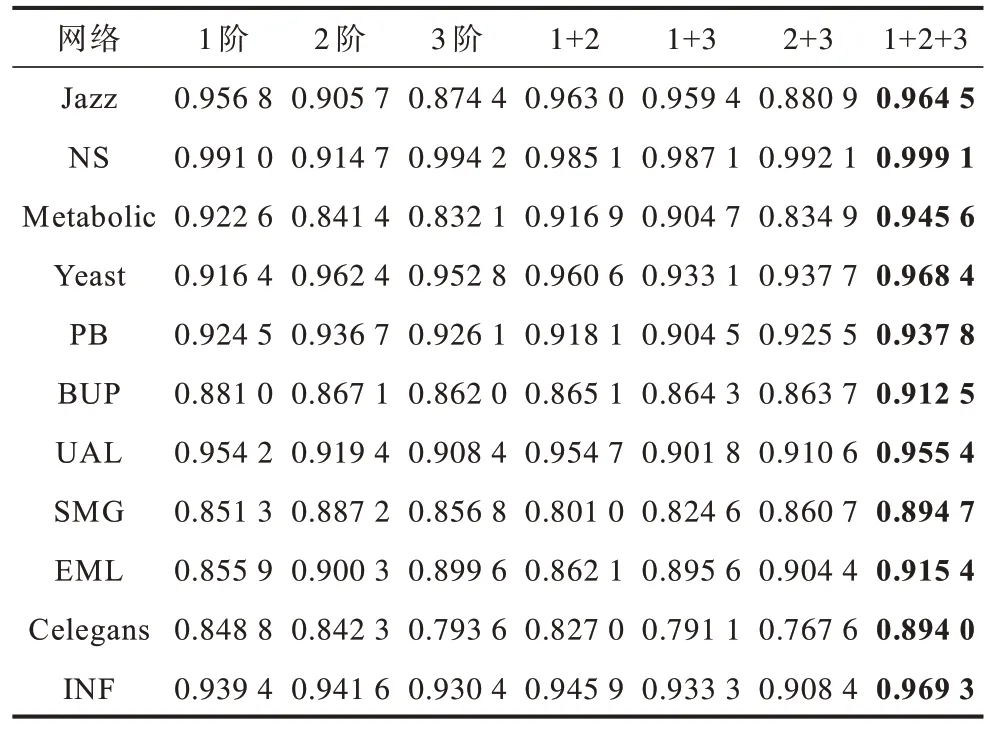
表2 不同参数情况下RF 在11 个网络中的AUC 表现Table 2 AUC performance of RF in eleven networks under different parameters
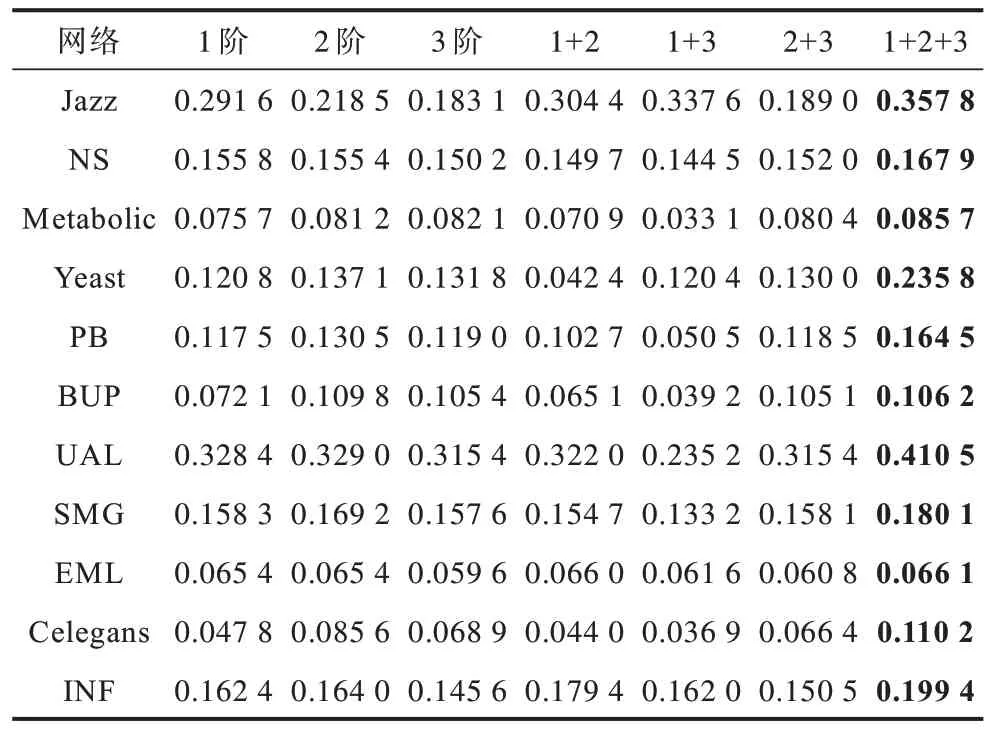
表3 不同参数情况下RF 在11 个网络中的Precision 表现Table 3 Precision performance of RF in eleven networks under different parameters
从图3、图4 可以得出如下结论:
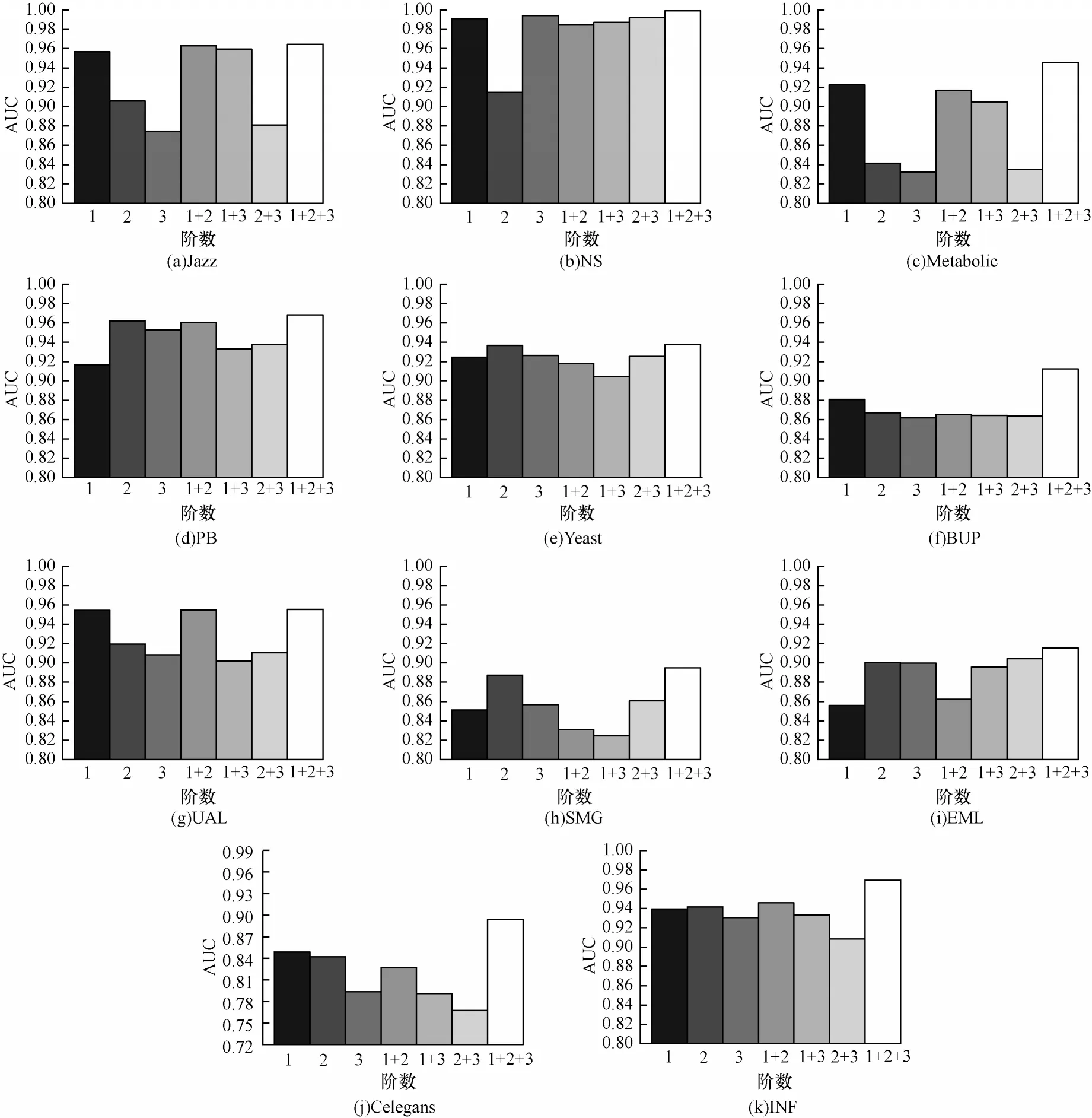
图3 不同参数情况下RF 在11 个网络中的AUC 对比Fig.3 AUC comparison of RF in eleven networks under different parameters

图4 不同参数情况下RF 在11 个网络中的Precision 对比Fig.4 Precision comparison of RF in eleven networks under different parameters
1)对比RF 利用单阶路径节点时的精准度情况。RF-1 在4 个数据集中AUC 表现最佳,在3 个数据集中Precision 表现最佳;RF-2 在5个数据集中AUC 表现最佳,AUC 表现情况良好,在7 个数据集中Precision 表现最佳;RF-3 在2个数据集中AUC 表 现最佳,AUC 表现情况较差,Precision 只在1 个数据集中超过了RF-1、RF-2。因此,如果RF 算法只利用3 阶路径节点,则其AUC 和Precision 的精准度将远低于RF-1、RF-2。RF-2的表现良好,超过了RF-1,这意味着资源在3 阶路径中的传输精度高于2 阶路径,这打破了以往指标对于共同邻居的精度普遍高于3 阶路径这一共识,这一点在文献[17,40-41]中进行了证实,本文也进一步验证了这个情况。
2)对比RF 利用多阶路径节点时的精准度情况。RF-1+2 在6 个数据集中AUC 表现最佳,但Precision只在3 个数据集中表现最佳;RF-2+3 在5 个数据集中AUC 表现最佳,在7 个数据集中Precision 表现最佳;RF-1+3 的AUC 表现最差,未在任何数据集中超过RF-1+2 和RF-2+3,其Precision 也只在1 个数据集中超过了RF-1+2、RF-2+3;RF-1+2+3 在11 个数据集中AUC 和Precision 的表现超过了其他所有的6 种情况,RF-1+2+3 仅利用了4 个阶数的路径节点,其利用网络拓扑信息的程度最高,虽然计算复杂度会提升,但能保证结果较优。
基于以上分析,本文得到RF 的最优指标设置为RF-opt=RF-1+2+3,在后续实验中,会以RF-opt 的数据与其他基准指标进行对比。
3.3 预测精度对比分析
为了验证RF 指标的预测精度,本文将其与上文提到的7 个基准指标在11 个网络中进行对比,包括5 个局部指标(CN、Salton、Jaccard、AA、RA)、1 个准局部指标(LP)以及1 个全局指标(Katz)。表4 展示各指标在11 个网络中的AUC 值对比情况,最优结果加粗表示。从表4 可以看出,RF 指标在7 个数据集中表现最优,虽然RF 只利用了准局部信息,但是其表现并不逊于全局指标Katz,Katz 只在2 个数据集中表现最优。在基于局部信息的相似性指标中,CN、Salton、Jaccard 和AA 指标在不同网络中表现相近,不如准局部和全局指标。RA 指标由于利用了网络资源的机制,相比于其他4 种局部指标表现更优,在Metabolic 数据集中达到了最优效果。RF 指标除了在个别数据集中表现不如RA、LP 和Katz,在其他数据集中表现均为最优,相比于全局指标,RF 作为准局部指标,其在预测精度上更有优势。

表4 100 次独立实验下的平均AUC 值对比Table 4 Comparison of average AUC values under 100 independent experiments
表5 所示为各指标在11 个网络中的Precision值对比。从表5 可以看出,RF 指标在8 个数据集中表现最优,在Yeast 和SMG 数据集中其表现远超其他指标。准局部指标LP 和全局指标Katz 表现良好,普遍优于局部指标,分别在EML 和UAL 数据集中达到最优,这在AUC 和Precision 中都表现出了同样的结果,说明准局部指标和全局指标挖掘了更多的网络信息,因此,它们的精准度高于局部指标。
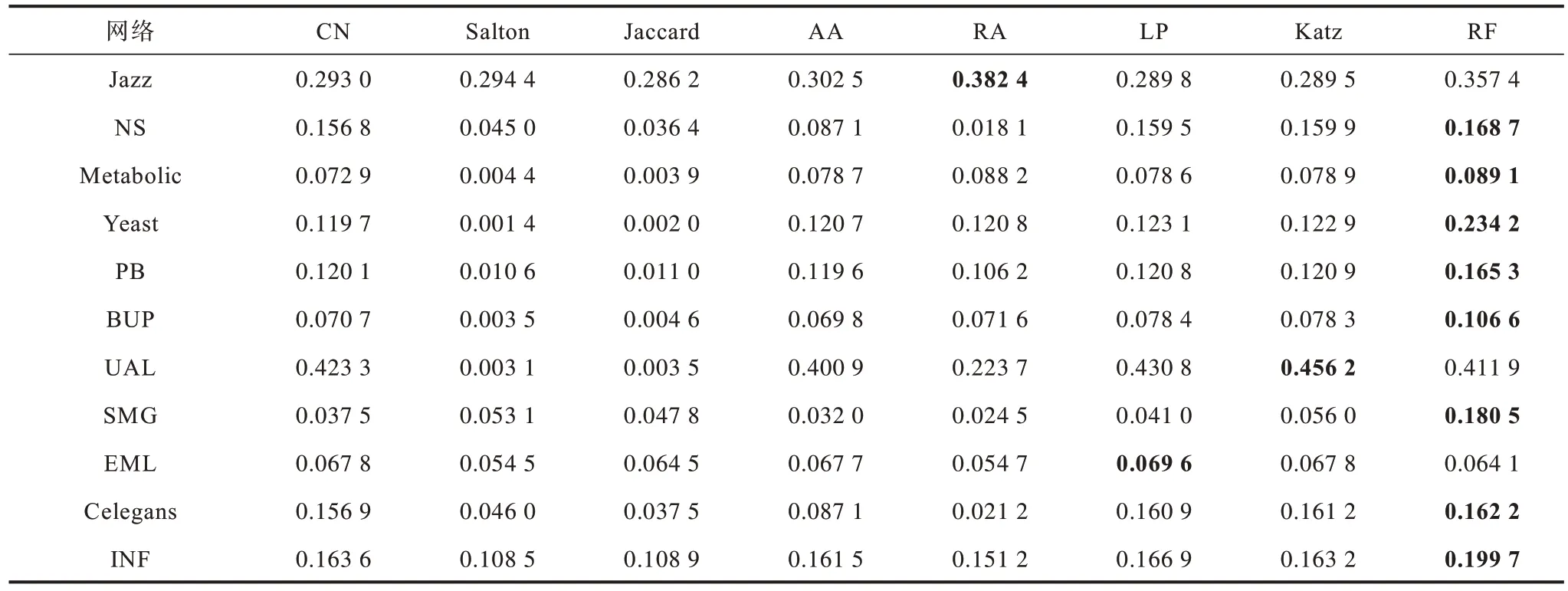
表5 100 次独立实验下的平均Precision 值对比Table 5 Comparison of average Precision values under 100 independent experiments
综上所述,相比于其他7 种基准指标,RF 指标能够达到更优的预测精准度,原因主要有以下3 点:
1)相比于局部指标CN、Salton、Jaccard、AA 和RA,RF 指标对于共同邻居节点的利用程度更高。
2)相比于准局部指标LP,RF 利用了更多的网络信息,考虑到了路径节点本身的度大小对于链路预测贡献不同的情况。
3)全局指标Katz 很少利用高阶路径信息,并且予以非常大的惩罚因数,导致添加了很多数值较小的噪声,提高了计算复杂度。RF 只从1 阶、2 阶、3 阶路径节点出发,避免了噪声信息,同时降低了计算复杂度,因此,其精确度表现更优。
3.4 RF 算法鲁棒性测试
为了更准确地验证RF 的性能,将训练集划分比例从0.5 调整到0.9,步长设为0.1,对8 个算法在11 个网络中的表现进行可视化,从而测试所有指标的鲁棒性,实验结果如图5、图6 所示。从图5 可以看出,当训练集比例从0.5 上升到0.9 时,AUC 值呈现上升趋势,当训练集比例增加时,随着网络已知信息的增加,所有方法的AUC 值随之上升。在训练集比例的变化过程中,局部指标的斜率变化往往大于准局部和全局指标,鲁棒性最差。在所有指标中,Katz在NS、PB、Yeast 数据集中AUC 基本没有波动,鲁棒性较好。RF 指标仅次于Katz 指标,在多个数据集中波动不大,并且都优于其他指标。从图6 可以看出,所有方法的Precision 值总体呈现下降趋势,说明随着训练集比例的升高,测试集比例减小,所有节点预测准确的概率降低。与AUC 结果不同,RF 的Precision 鲁棒性在所有指标中表现最好,在总体波动不大的情况下还能保持较高的数值。在EML 数据集中,RF 的Precision 波动较大,不过波动情况仍然低于其他指标,而在INF 中,LP 和Katz 出现较大的波动,RF 能够保持稳定,此外,RF 在Celegans 中不仅波动最小,而且始终优于其他指标。

图5 不同训练集比例下的AUC 鲁棒性测试结果Fig.5 AUC robustness test results under different proportion of training sets
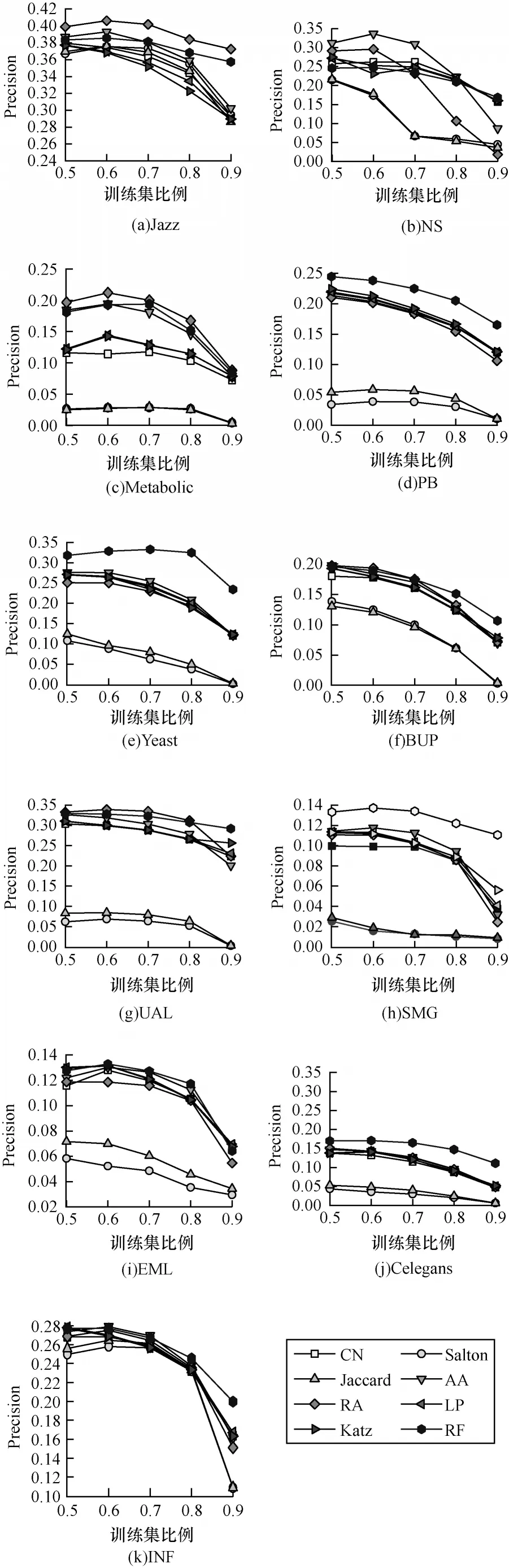
图6 不同训练集比例下的Precision 鲁棒性测试结果Fig.6 Precision robustness test results under different proportion of training sets
4 结束语
链路预测方法受到拓扑结构复杂特征和系统动力学要素的制约,使得局部方法效率较低,全局方法则面临维数灾难问题。网络资源分配机制虽然能够在一定程度上实现资源的合理分配,但是忽略了传输路径节点的有效性和传输方向问题。此外,在当今的复杂网络研究中,数据集规模越来越大,对链路预测方法的效率和精度提出了更高的要求。为了解决上述问题,本文从准局部指标和资源流动角度出发,提出一种基于网络流量的链路预测方法。定义网络中初始资源的生成和资源流动机制,计算双向资源流量以精确刻画节点对之间的相似性,在此基础上提出相似性指标和链路预测算法RF。实验结果表明,将双向资源流量作为相似性的匹配度,可以使得预测精度显著提升,从而证实了资源传输机制的有效性。虽然本文的网络流量研究在上述方面具有一定的改进意义,但仍然存在局限性。由于算法复杂度的限制,网络更高阶的拓扑信息无法得到利用,且在初始资源分配的过程中,本文算法仍然采用较为朴素的公共近邻思想进行分配。下一步将优化算法流程以利用更高阶节点信息进行链路预测,同时,利用神经网络或网络嵌入技术对初始资源分配权重,以及将本文算法应用于加权网络、有向网络和大型网络中,也是今后的研究方向。
