基于ARM架构国产化私有云的大数据平台适配性研究
2022-09-15严爱民杨乘胜
严爱民,党 龙,杨乘胜
(1.华电陕西能源有限公司,陕西 西安 710016;2.南京华盾电力信息安全测评有限公司,江苏 南京 210000)
0 引言
自2018年“华为、中兴”等安全事件发生以来,信创产业进入快速开展阶段。经过多年发展,已实现芯片、基础硬件、操作系统、中间件、数据服务器等国产化替代产品研发,并从实验阶段逐步转入产业化发展阶段[1]。云平台作为基础技术底座,具备高可用性、稳定安全、弹性伸缩等优势,可以灵活应对复杂环境中的业务,有效降低基础资源的建设和运维成本,使企业提升内部效率,实现信息共享、协同办公、互联互通。而ARM架构由于其先天的低功耗优势,基于ARM架构的服务器已经越来越多地出现在云平台应用中。与此同时,随着数据持续以指数级别增长,为保证数据时效性、充分挖掘数据价值,企业纷纷基于云平台搭建自己的大数据平台,提升大数据处理能力,满足各类数据应用需求[2]。
1 企业IT建设特点
(1)国产化程度不足。企业应用的IT底层标准、架构、生态等大多都由国外大型互联网企业制定,存在诸多安全风险隐患,需在核心芯片、基础硬件、操作系统、中间件、数据库等领域实现国产替代。
(2)IT资源异构程度较大。经过多年信息化发展,各企业拥有了大量信息系统,每个信息系统是在不同时期由不同的项目组完成建设,所采购的软硬件来自不同厂商的不同产品,导致大量异构IT资源并存,资源利用效率不高,系统弹性扩展能力不足。
(3)数据价值有待挖掘。企业经过多年发展,积累了大量历史数据,并且数据规模持续不断以指数级增长,亟需构建自主可控、高可靠、高性能、可扩展的大数据处理平台,加强企业数据分析挖掘能力,充分发挥数据资产价值。
2 国产化云平台建设
与x86架构相比,ARM使用精简指令集(RISC),RISC支持的指令比较简单、功耗较小、价格便宜,拥有高并发处理效率、升级速度快等特点。经过多年发展,各ARM架构版本可以衍生出多种处理器内核,支持针对不同应用场景推出不同产品。同时,通过架构/指令集层级授权、内核层级授权、使用层级授权3种层级授权,实现与全球多个半导体厂商合作。
目前,ARM架构国产化CPU芯片厂商主要有飞腾、鲲鹏等,国产操作系统发展出深度、中标麒麟、银河麒麟、UOS等优势产品,形成华为等国产化云平台解决方案。为了满足企业快速上云、实现国产化替代应用需求,选择知名云厂商成熟产品搭建企业私有云平台,开展大数据平台适配性研究,满足大数据应用需求。平台架构,如图1所示。
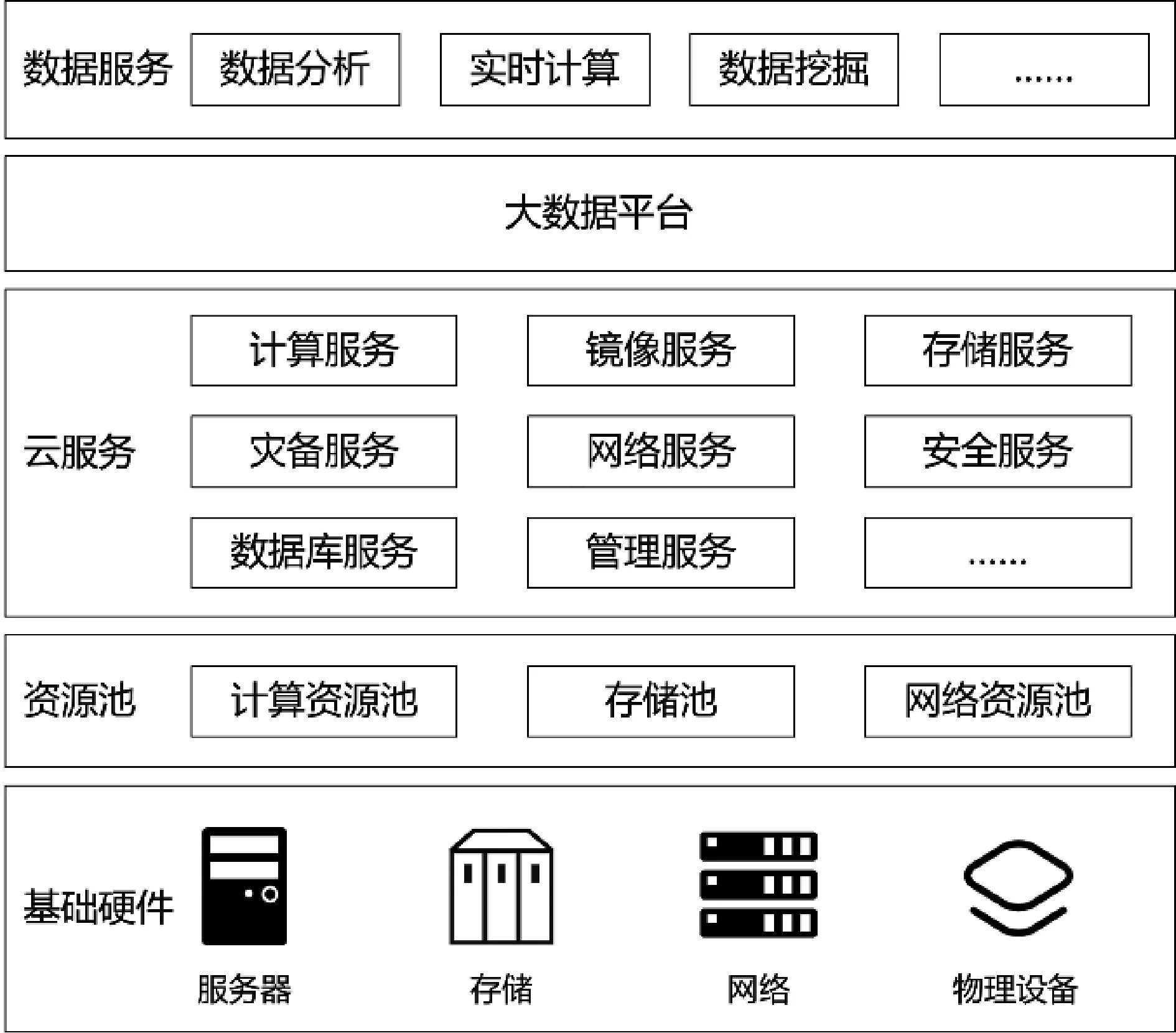
图1 ARM架构国产化私有云平台架构
基础设施层主要提供服务器、存储、网络等基础硬件。平台层提供计算服务、镜像服务、存储服务、灾备服务、网络服务、安全服务、数据库服务、管理服务等云服务,向上支持搭建大数据平台,实现对外提供数据分析、实时计算、数据挖掘等数据服务。
3 大数据平台建设
随着Hadoop,Spark,Flink,Kafka,Hive,HBase等大数据相关开源技术的发展[3],很多企业都搭建了自己的大数据平台。本文数据平台架构主要分为数据采集、数据存储、数据计算、数据应用4层。平台架构,如图2所示。
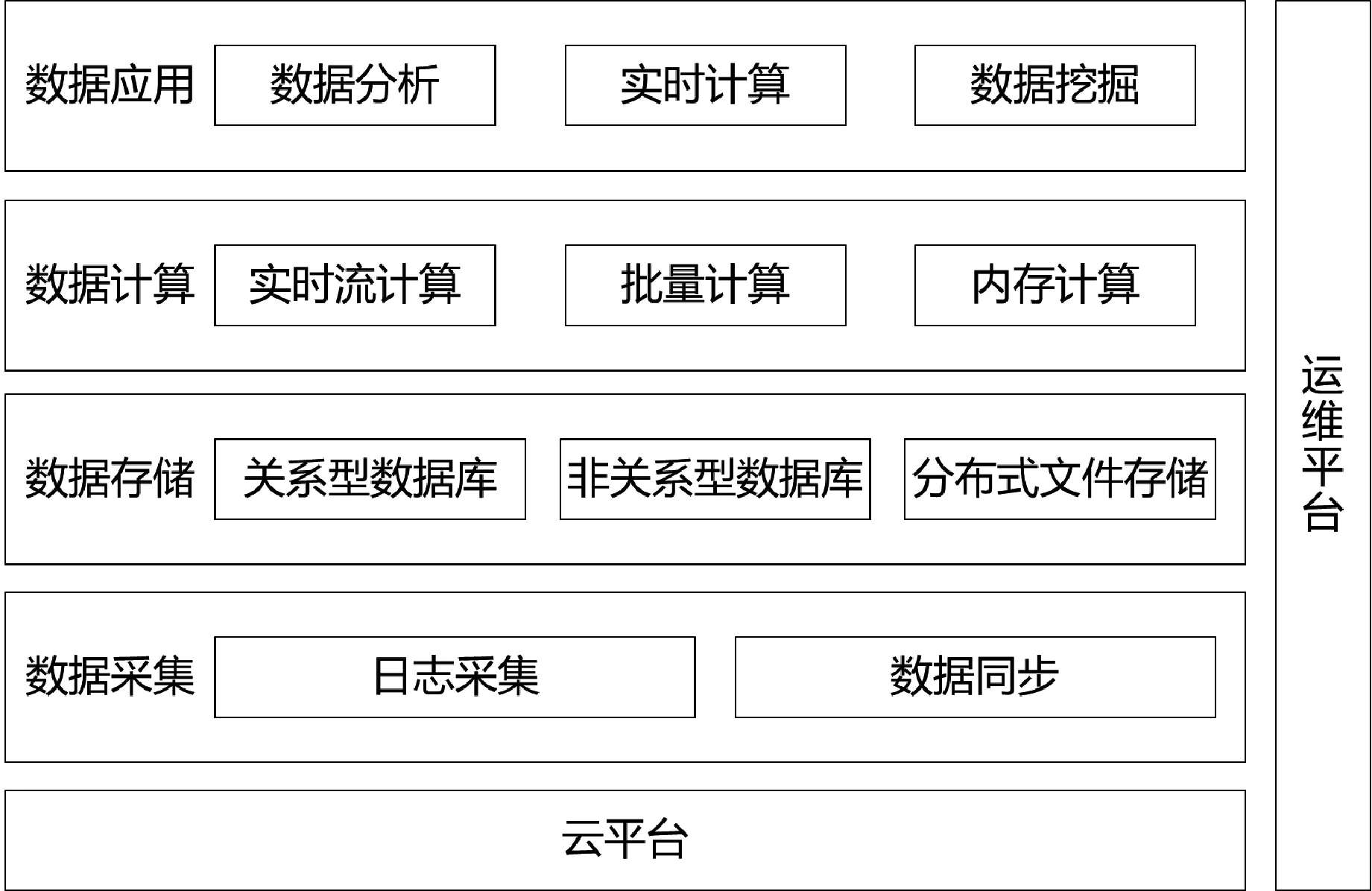
图2 大数据平台架构
3.1 数据采集
数据采集层可以分为日志采集和数据源同步。日志采集主要由日志埋点、爬虫采集、业务日志等,Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数据进行简单处理,并将处理后的数据发送到各数据接受方的功能。目前,使用Flume+Kafka是最主流的解决方案。
数据库同步主要是将存储在业务数据库(Mysql,Oracle,SQL Server)中的数据同步复制到大数据平台中存储。
3.2 数据存储
数据主要分为结构化数据和非结构化数据两种。数据存储层主要可以通过关系型数据库、非关系型数据库以及分布式数据库进行存储。存储可以通过Redis集群、Mysql集群、MongoDB集群以及HDFS和HBase。
HDFS是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,具备高容错性、高可靠、高吞吐等特点。
HDFS采用Master/Slave架构。一个HDFS集群是由一个NameNode和一定数目的DataNodes组成。NameNode是一个中心服务器,负责管理文件系统的名字空间以及客户端对文件的访问。集群中的DataNode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组DataNode上。DataNode负责处理文件系统客户端的读写请求。在NameNode的统一调度下进行数据块的创建、删除和复制。
HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,更适合于非结构化数据存储的数据库,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。
3.3 数据计算
数据计算是数据处理的关键环节,通过计算才能对外输出相应的结果。目前,常用的计算有批量计算以及流式计算,主要通过开源MapReduce,Hive,Spark,Storm以及Flink实现。
MapReduce是开源分布式计算的第一个流行的计算框架,它将所有计算抽象成Map和Reduce两个阶段。在计算时,MapReduce将大型作业分解为可以跨服务器集群执行的单个任务,并行地对各个子任务进行Map或Reduce操作,并将结果写到文件中。如此反复得到最终的结果。Hive是基于MapReduce的架构,具有稳定可靠特点,但是计算速度较慢;Spark则是基于内存型的计算,一般认为比MapReduce的速度快很多,但是其对内存性能的要求较高,且存在内存溢出的风险。Storm,Spark Streaming,Flink则是目前常用的流计算框架。
3.4 数据应用
数据应用层基于数据计算结果对外提供数据分析、实时计算、数据挖掘等数据服务,开展人工智能等分析,深入分析行业数据特点,梳理行业数据产品需求,建立适用于不同行业的数据应用产品,实现数据为业务赋能。
3.5 国产化适配
目前,商用计算平台上部署Hadoop架构已较普及,但在国产化全自主可控的软硬件环境下平台的适配工作才刚起步。本文通过与中标麒麟操作系统的调优适配,实现了Hadoop架构大数据平台的国产化迁移。为确保分布式运算环境效率,选用5台性能相同的国产化计算机,适配步骤如下:
(1)准备国产化机器安装国产化操作系统。
(2)准备私有云依赖,国产化环境下编译安装。
(3)准备Hadoop相关依赖,国产化环境下编译安装。
(4)配置Hadoop。
(5)启动Hadoop。
国产化分布式集群平台软硬件运行环境如表1所示。

表1 软硬件运行环境
4 性能测试
4.1 软硬件环境
为了测试适配的基于ARM架构私有云的大数据平台性能,本研究搭建2个大数据平台,一个使用国产华为鲲鹏服务器,一个使用Intel x86架构服务器。
使用TPC-DS测试工具分别对Hive在信创环境和x86环境进行了查询性能的测试,服务器配置,如表2所示。
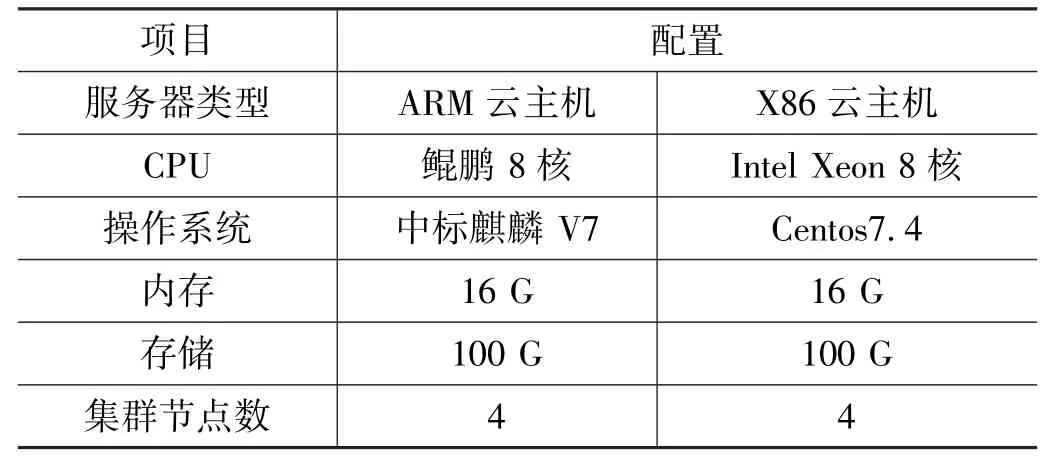
表2 大数据平台软硬件配置
4.2 测试结果
通过TPC-DS工具分别向信创和X86环境下的HDFS生成10 G测试数据,然后将10 G数据传输到Hive中存储。查询时间的结果,如表3所示。

表3 Hive执行sql时间 (单位:s)
测试结果显示,在10 G量级的数据下,基于ARM架构国产化私有云的大数据平台的查询性能和稳定性,性能已经接近同等配置的x86服务器,能够满足实际应用中对海量数据的存取要求。
5 结语
本文提出了ARM架构国产化私有云及其上大数据平台解决方案,并适配性研究。实验验证了大数据平台国产化迁移的可行性,基于ARM架构国产化私有云的大数据平台性能与同等配置下x86服务器性能相似,能够满足实际应用中对海量数据的处理需求。
