基于二维CTC和注意力序列的场景文本识别模型
2022-09-14孙洁朱玉全黄承宁
孙洁,朱玉全,黄承宁
(1.南京工业大学浦江学院 计算机与通信工程学院,江苏南京,211200;2.江苏大学 计算机科学与通信工程学院,江苏镇江,212013)
0 引言
自然场景文本是指存在于任意自然场景下的文本内容,例如车牌、路标、广告牌、店铺招牌等。自然场景下的文本识别不同于光学字符识别(Optical Character Recognition,OCR)[1],前者难度较大,例如清晰文本在通过图像展示后变成倾斜、密集且模糊的文本,文本具有完全不同的字体、颜色和大小等[2],背景复杂使得背景物体和文本很难区分等。自然场景下的文本识别(scene text recognition,STR)[3]通常先利用文本检测技术得到文本位置信息,再使用文本识别技术得到根据位置信息裁剪的图像中的文本内容。自然场景文本识别算法很多,其中基于循环神经网络(recurrent neural network,RNN)的文本识别算法主要有两个框架,分别是卷积循环神经网络(convolutional recurrent neural network,CRNN)[4]+连接时序分类(connectionist temporal classification, CTC)模型和基于注意力(Attention)机制的序列到序列(sequence to sequence,Seq2Seq)模型。CRNN+CTC的收敛速度相对较快,但存在识别精度低,解码信息丢失问题,又因为CTC模型所需要的特征序列的高度为1,文本在高度上的变化限制了该方法的识别能力。基于注意力机制的Seq2Seq模型识别精度高于CRNN+CTC模型,英文识别率较高,但存在收敛速度慢,对于自然场景下的中文文本识别效果一般等问题。针对上述问题,提出一种基于二维CTC和注意力机制序列的文本识别模型。
1 相关工作
■ 1.1 二维CTC模型
以往的大多数算法主要是通过设计CTC或基于注意力的编码解码器框架,将文本视为一维信号,并将转换场景文本识别视为序列预测问题。但是与一维数据不同,文本一般都分布在图像空间中,空间位置信息在自然场景下特别是对于中文识别来说是非常重要的,因此可利用文本的二维性质来实现更高的识别精度。二维CTC可以自适应地关注空间信息,同时排除背景噪声的影响;它也可以处理各种形式(水平、定向和弯曲)的文本实例,同时给出更多的中间预测。在CTC中,给定一组概率分布,它寻求产生相同目标序列的各种路径,所有路径的条件概率之和进行标记的概率,该概率用于测量标记和预测的可能性。对于二维CTC,为路径搜索添加了额外的维度:除了时间步长(预测长度)以外,还保留了高度的概率分布。它可以确保考虑到所有可能的高度路径,并且不同的路径选择可能仍会导致相同的目标顺序。
二维CTC网络的输出可以分解为两种类型的预测:概率分布图和路径转换图。首先,将Ω定义为字母表。与CTC类似,二维CTC的概率分布由带有|Ω|-类标签的Softmax输出层预测。每个位置上第一个单元的激活都表示占位符的可能性,这意味着没有有效的标签。以下单位对应于|Ω|的概率分别为1个字符类。概率分布图的形状为H×W×|Ω|。H和W代表预测图的空间大小,它与原始图像的大小成比例。
二维CTC还要求在高度尺寸上进行归一化。实际上,另一个单独的Softmax层会生成形状为H×W的额外预测路径过渡图。概率分布图和路径转换图这两个单独的预测用于损失计算和序列解码。二维CTC继承了CTC的对齐概念。在二维CTC的解码过程中,高度位置和字符类别上的最大概率被减少到序列预测中。二维CTC的对齐方式如图1所示。除了CTC的先前帧对齐方式之外,二维CTC还选择高度范围内的路径。然后,在所选路径上字符的预测概率将被联合成帧预测,从而使解码过程成为原始的CTC对齐。
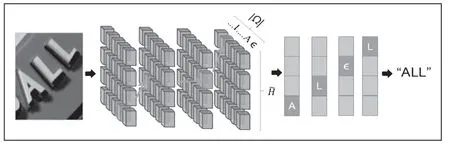
图1 二维CTC对齐方式
二维CTC损失的目标为所有有效路径提供条件概率P(Y|X)。此条件概率用于测量标签和预测之间的差异。假设路径从左向右扩展,这对于大多数序列识别问题是很普遍的。给定具有高度H和宽度W的二维分布,定义路径转换γ∈RH×(W-1)×H。γh,w,h'表示解码路径从(h,w)到(h',w+1)的转移概率,其中h',h∈[1,...,H],w∈[1,...W-1]。每个位置的路径转换概率之和等于1,计算公式为式(1):

二维CTC相对于一维来说,本质上是将高度变换为尺寸,从而减轻了丢失或连接信息的问题,并提供给CTC解码的更多路径。
给定相同的扩展标签Y',当(Y's=ε)或者(Y's=Y's-2)的情况的递归公式为式(2):
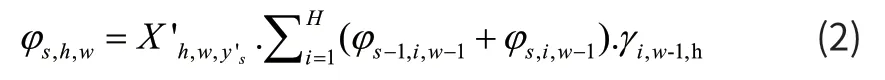
对于其他情况,计算公式为式(3):
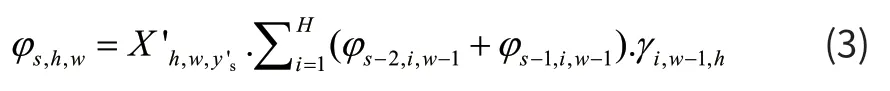
从方程中可以看出,每个时间步长的条件概率是沿着高度维度分别计算的。 高度维度中的路径通过相应的转移概率进行加权,并汇总为分布表示形式。
因此,二维CTC的动态编程过程的计算公式为式(4):
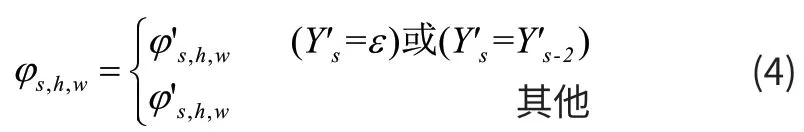
将其中的φ第一个状态定义初始化,计算公式为式(5):
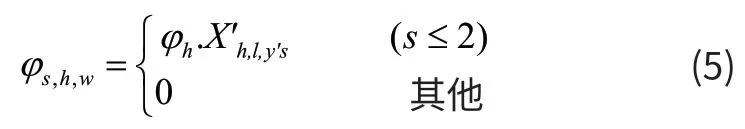
此时二维CTC的条件概率总结的计算公式为式(6):
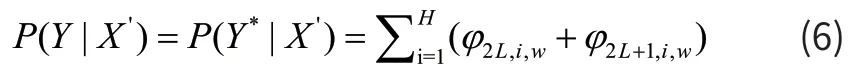
最终损失函数的计算公式为式(7):
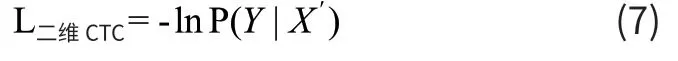
■ 1.2 基于注意力机制的Seq2Seq文本识别方法
1.2.1 Seq2Seq模型
序列到序列(sequence to sequence,Seq2Seq)模型[5]是在2014年被提出。该模型本质上是一种多对多的循环神经网络模型,即输入序列和输出序列长度不一致的循环神经网络模型。Seq2Seq模型是利用编码(Encoder)-解码(Decoder)的抽象架构,如图2所示。
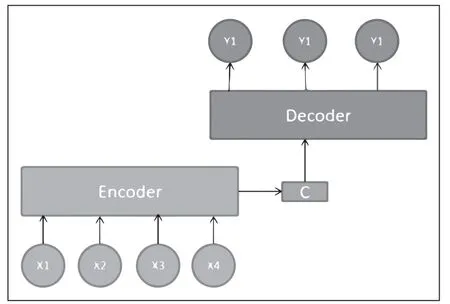
图2 Seq2Seq模型
基础的Seq2Seq模型一般是利用两个LSTM或者RNN网络,一个作为Encoder(编码)部分,另一个作为Decoder(解码)部分,Encode意思是将输入序列转化成一个固定长度的向量,Decode意思是将输入的固定长度向量解码成输出序列。还存在一个连接两者的中间状态向量C。Seq2Seq模型是根据输入序列X来生成输出序列Y。在RNN中当前时刻的隐藏状态是由上一个时刻的状态和当前时间的输入x共同决定的,即如式(8)所示:

编码过程中Encoder通过学习将输入序列编码成一个固定大小的状态向量C,这个向量C则是这个序列的语义,即在编码阶段一个字/词(实际是字/词的向量)的输入,输入句子结束后,产生中间语义向量C,如式(9)所示:
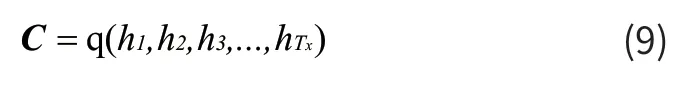
其中,hi指的是编码器编码后的隐向量,t指的是当前时刻,Tx指的是最后时刻,f和q是非线性函数。
继而将语义向量C传给Decoder,Decoder再通过对状态向量C的学习每一步的解码和已经输出的序列Y来预测下一个输出yt,如式(10)所示。
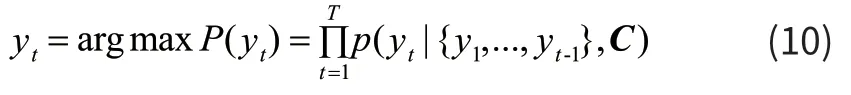
在RNN中化简得式(11):

其中St是RNN中的隐藏层,C代表之前提过的语义向量,yt-1表示上个时刻的输出,反过来作为这个时刻的输入。而g则可以是一个非线性的多层的神经网络,产生词典中各个词语属于yt的概率。
Seq2Seq模型在输出序列上,每一个时刻传入的都是固定长度的语义向量C,当输入的序列变长时会导致语义向量无法完全表示整个输入序列的信息,同时也会出现先输入的序列中包含的语义信息会被后输入序列中的语义信息覆盖。输入的序列越长,在获取输入序列的信息就越少,从而导致解码的准确率下降。
1.2.2 引入注意力机制的Seq2Seq的模型
注意力机制是模仿人类注意力而提出的一种解决上述问题的办法,简单地说就是从大量信息中快速筛选出高价值信息。主要用于解决LSTM或者RNN模型输入序列较长的时候很难获得最终合理的向量表示问题,模型在编码解码的过程中,不仅仅是关注生成的语义向量C,同时增加了一个注意力区域,并将其与输出进行关联,从而达到信息筛选的目的。如图3所示。

图3 加入注意力机制的Seq2Seq模型
相比之前的Encoder-Decoder模型,引入注意力机制模型最大的区别在于每一个输出文本在计算时,参考的语义编码向量C(C1,C2,C3)都是不一样的,也就是它们的注意力焦点是不一样的。
Bahdanau等人[6]提出基于注意力机制的Seq2Seq的模型已成功应用于大量的序列转导问题(Luong等[7])。这些模型(Xu等人[8];Chorowski等人[9]以及Wang等人[10]等等)以常规的形式使用编码器递归神经网络(RNN)处理输入序列,以产生称为存储器的隐藏状态序列。然后,解码器RNN自回归生成输出序列。在每个输出时间步,解码器都直接由注意力机制的限制,该机制使解码器可以利用编码器的隐藏状态序列,通过使用编码器的隐藏状态作为存储器,该模型能够消除较长的输入-输出时滞[11~12],与缺乏注意力机制的Seq2Seq模型相比,具有明显的优势。
在基于注意力序列的文本识别模型中,主要有两个部分组成分别是卷积层和双向LSTM的编码模块及LSTM+注意力的解码模块[13~14],如图4所示。
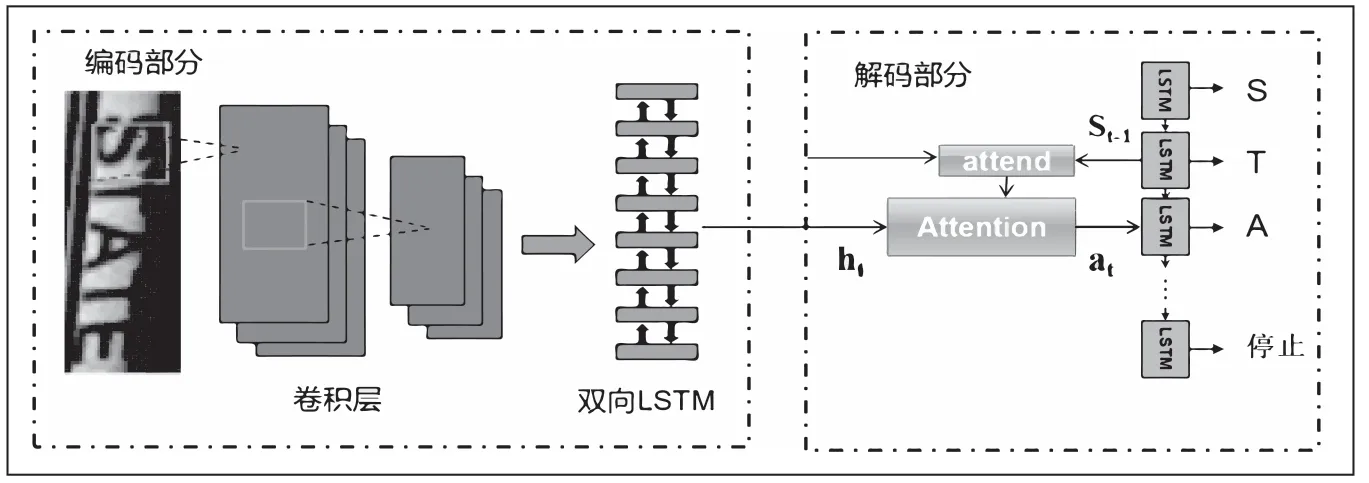
图4 Seq2Seq+注意力的文本识别框架
编码部分首先利用卷积层提取文本图像特征。在提取图像特征之后将特征图转化为特征序列,假设之前的特征图的尺寸大小为h·w·d(h代表高度,w代表宽度,d代表维度),转换为序列特征后,得到宽为w的向量,向量中每一个序列的大小为h·d。由于卷积神经网络提取的图像特征受到感受野的限制,为了扩大上下文的特征信息,这里将双向多层的LSTM网络应用于序列特征的提取,双向多层的LSTM网络可以同时兼顾两个方向的长期依赖关系,最后输出相同长度的新特征序列。
解码部分中采用基于注意力机制的解码器。该解码器将编码部分中提取的特征序列转换为字符序列,首先对T个时刻的序列特征进行迭代,产生长度为T的符号序列,表示为[y1,...,yT],在时刻t,解码部分根据编码部分输出的ht,内部状态的St-1以及上一步的预测结果yt来预测一个字符或者一个停止符号。具体的,解码部分首先通过注意力机制来计算权重向量at,公式为式(12)和(13):
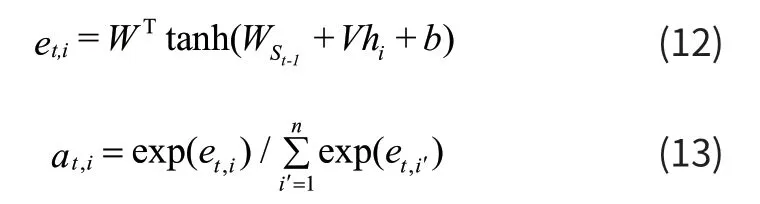
其中W和V为可训练的权重,解码部分根据注意力的权值系数,将输入的ht的列向量通过线性组合成新的向量,称为gt,在向量gt中at,i随着每一个时刻t的变化而变化,并且每一个时刻都是不一样的,公式表现为式(14):

向量gt包含了编码的整个上下文的一部分,将它输入到解码部分的循环单元时,循环单元会输出一个向量yt和一个新的状态向量st,公式为式(15):
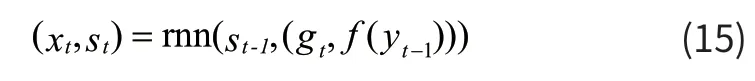
2 基于二维CTC和注意力机制序列的文本识别模型
在自然场景文本识别中不同于在A4纸上的打印文本,自然场景中的文本大多都是空间排列不规则的文本,并且噪声很大。虽然CRNN+CTC的收敛速度相对较快,而基于注意力机制的Seq2Seq模型的收敛速度慢,但是精度要比CRNN+CTC模型高,但也存在缺陷,一方面CRNN存在解码信息缺失的问题,另一方面CTC模型,所需要的特征序列的高度为1,文本在高度上的变化限制了它的识别能力,而基于注意力机制的Seq2Seq 模型在一定程度上对于自然场景下的英文识别率较高,但是对于自然场景下的中文识别效果一般[15~16]。针对上述问题,提出一种融合二维(2-D)CTC和注意力机制序列的文本识别模型。
基于二维CTC和注意力机制的Seq2Seq的文本识别框架分为两个部分,编码部分和解码部分如图5所示。
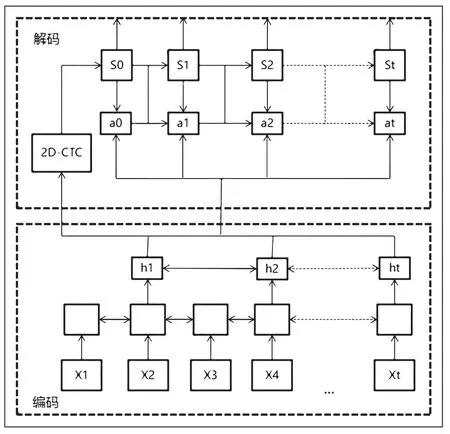
图5 二维CTC和注意力机制的Seq2Seq文本识别框架
编码部分,由卷积神经网络和多层双向LSTM组成,负责将图像转换为特征序列。解码部分由基于连接二维CTC和注意力机制的Seq2Seq的模型构成,基于注意力机制的Seq2Seq在解码时,将所有特征集中在中间语义C上,此时计算每个特征的注意力权重,解码过程计算方式为式(16)~(18):

其中hi,j表示第i个关系中第j个h经过编码后的特征向量,aj表示平滑归一函数处理后的权值参数,ej表示注意力的权值,g表示对hi,j和hj进行线性变换,表示点乘⊗操作。
最后生成下一个状态st和下一个标yt签,计算公式为(19)和(20):
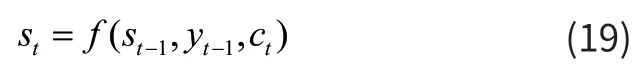

此时注意力的损失函数计算方式如式(21):
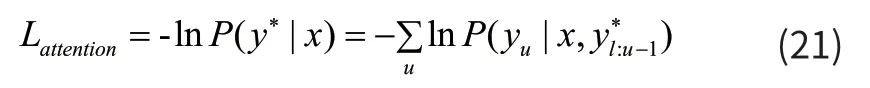
该模型的思想是使用一个二维CTC目标函数作为辅助任务,在多任务学习框架下训练注意力模型编码器。与注意模型不同,CTC的前向-后向算法可以实现语音和标签序列的单调对齐,并且CTC需要的特征序列的高度为1,不能兼顾空间信息,而二维CTC可以兼顾文本的空间信息。整个模型的损失函数如式(22)所示:

3 实验结果与分析
本节对上述两种文本识别方法和本文的文本识别算法在公开的数据集上进行实验对比,文本识别和检测所采用的数据集不同。一般情况下,文本识别的数据集中的文本要比文本检测的数据集中的更加规范,更多种类以及背景简单。因为很多数据集不能进行端到端的方法,所以采用ICDAR2013数 据 集[17]、ICDAR2015数 据 集[18]、SVT数 据集以及ICPR WTMI2018(以下简称IW2018)中英文混合数据集。作为训练集也作为测试集。ICDAR2013数据集中共有462张图像,包括229张训练图像,233张测试图像,ICDAR2013数据集中的图像都为水平的英文文本。ICDAR2015数据集有1500张图像,1000张训练图像和500张测试图像,ICDAR2015数据集中的图像大多为倾斜的英文文本。典型图像如图6(a)所示。ICPR WTMI2018中英文混合数据集中有20000张图片,10000张训练图片和10000张测试图片,其中图像全部来源于网络图像,主要有合成图像、产品描述和网络广告构成。其中主要为竖直,水平和倾斜的文本,并且字体种类繁多,大小不一,背景复杂。典型图像如图6(b)所示。Street View Text(SVT)数据集共有350张数据集,其中100张训练集,250张测试集,图像中为水平的英文文本。SVT数据集是从谷歌街景中获取,数据集中的图像大多为低质量的图像。

图6 数据集典型图像
在损失函数中取一个参数λ用来约束二维CTC和注意力的权重,本文对λ分别取0 ,0.1,0.3,0.5,0.8和1这6个值并在ICDAR2015数据集下对识别率和收敛情况进行实验分析。对于λ取0和1可以看出为单独使用二维CTC或者注意力机制来进行解码。其他值为0~1之间的任意取值,并对于不同的取值,有不同的效果。
收敛速度如图7所示,可以从图中的关系看出,随着迭代次数的增加,取值越大收敛越快,主要原因是注意力解码产生的参数较多导致收敛速度降低,而二维的CTC并不会产生过多参数,所以当二维CTC的比重大越大收敛速度越快。
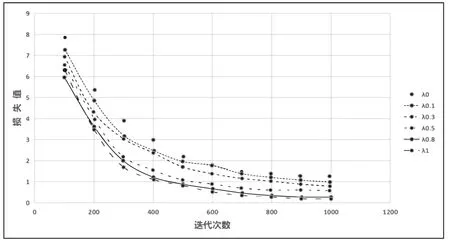
图7 λ取不同值的收敛速度情况
识别率如图8所示,当λ取值为0.3时识别率最高,单纯的使用二维CTC和注意力机制的识别率都不是最高,当取值为0.1和0.8时在单独使用二维CTC或者注意力机制的识别率之间。实验表明了连接二维CTC和注意力机制的有效性。
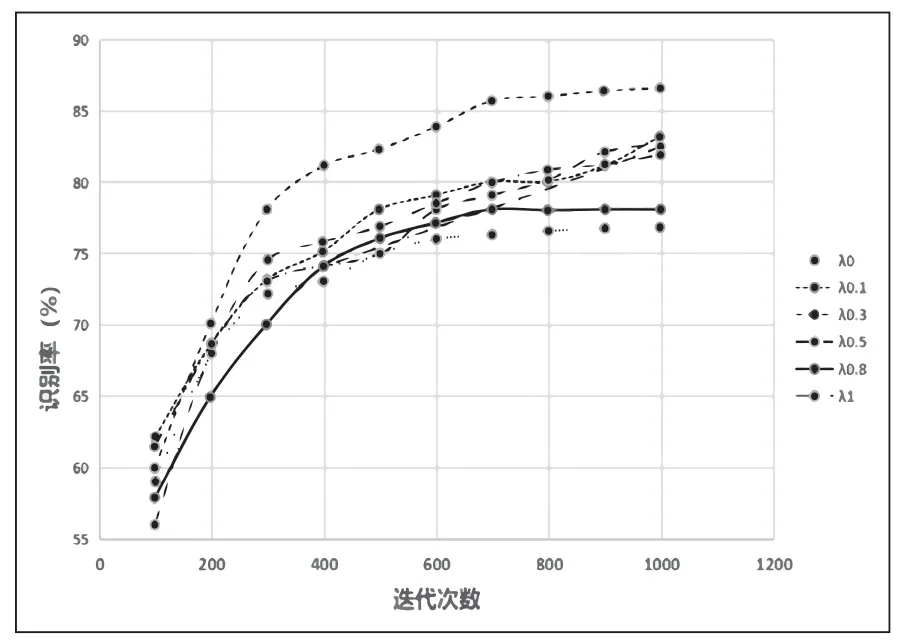
图8 λ取不同值的识别率情况
自然场景文本识别的评价指标一般有两种,一种是字符识别准确率,一种是单词识别准确率。字符识别准确率表示字符识别正确的个数占总字符的比例。此评价指标比较直观。单词识别准确率一般使用编辑距离,编辑距离使用一种衡量两个字符序列差异大小的方法,简单地说,当一个字符需要转换成另一个字符所需要的步骤数,包括删除、插入和替换。一般的步骤数越小表示两个字符的相似度越大,文本识别的准确率就越高,一般的编辑距离可以由动态算法计算得到。本文采用在ICADR2013手写汉字识别竞赛中的识别准确率(AR)作为评价指标,公式为式(23):
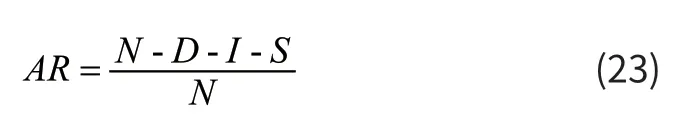
其中N表示总字符的数量,D、I、S分别表示删除、插入、替换的步骤数。
使用CRNN+CTC的模型和CNN+Seq2Seq+注意力模型以及其他识别方法与本文将改进的检测算法与融合二维CTC和注意力机制的Seq2Seq结合的模型在几个公开数据集上进行实验对比。如表1所示。
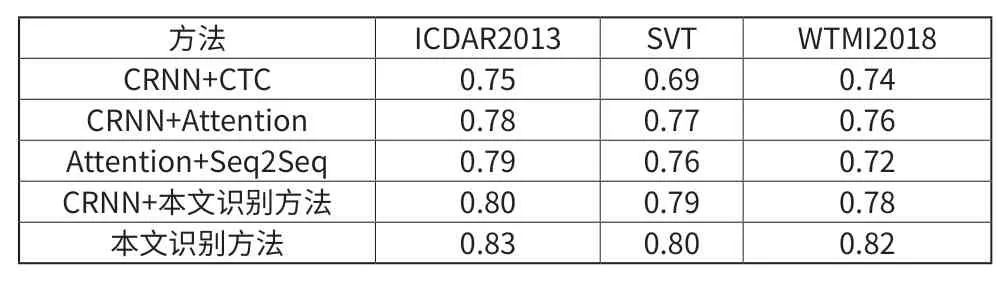
表1 集中方法的识别准确率
通过其CRNN的特征提取网络与本文的识别算法结合与其他文本识别算法对比可以看出,改进的文本识别方法的有效性。最后将上述检测方法和识别方法结合发现,准确率都高于其他方法。
4 结束语
本文针对CRNN+CTC文本识别模型和基于注意力机制的Seq2Seq文本识别方法存在的问题,提出一种基于二维CTC和注意力Seq2Seq机制的文本识别模型。通过二维CTC将带有空间信息的特征序列输入到注意力的Seq2Seq的解码机制上,从而进一步提升识别不规则和弯曲文本序列的准确率,极大地改善了不规则文本信息缺失的问题,同时改进了Seq2Seq模型在自然场景的中文文本识别效果较差的问题。实验证明,该文本识别算法可以有效地减少信息缺失,降低失误率,提高各类文本识别的准确率。该模型虽然对于一些倾斜和一些不规则的文本有了较好的识别效果,但是对于黏连以及多行的文本识别效果还是略显不足,未来会对此进行进一步的研究。
