预训练语言模型在科学类QA方向的探索研究
——基于ARC数据集
2022-09-13夏秀坤张曼琳
夏秀坤,张曼琳
(1.河北软件职业技术学院,河北 保定 071000;2.北京智芯半导体科技有限公司,北京 10200)
0 引言
近年来,随着词向量(Word Representations)[1]和词嵌入(Word Embedding)[2]研究取得的巨大突破,基于神经网络模型的NLP技术也取得了显著进展。大多数新兴NLP模型都是基于递归神经网络(Recurrent neural networks,RNN)和长短期神经网络(Long-Short-Term-Memory,LSTM)建立的。然而,词嵌入有其自身的局限性,当单词被嵌入到向量中时,它就不再具有上下文感知功能。谷歌提出的基于Attention理念的Transformer模型[3]将NLP研究带入了新的阶段,许多研究者开始基于Transformer架构设计模型。BERT模型[4]使用了双向Transformer,其结果可以进一步用于其他NLP任务的输入,这些特性使其在研究中被广泛应用。RoBERTa模型[5]在BERT模型基础上进行了一些优化。而谷歌再次提出的T5(Text-to-Text Transfer Transformer)模型[6],对自BERT模型提出以来的多种优化策略进行了整合,使得NLP技术更进一步。这些模型均为预训练模型,为研究者有针对性地探索研究或微调(Fine-tune)提供了方便。
随着新模型的出现,更具挑战性的数据集也随之而来。在众多的数据集中,问答(QA)和推理(Reasoning)是两种比较流行的类别。例如SQuAD1.0和2.0,CoQA,HotpotQA,SearchQA。本文将专注于问答和推理数据集:AI2逻辑挑战(AI2 Reasoning Challenge,ARC)数 据 集[7],并 基 于RoBERTa和BERT模型进行探索。
1 ARC数据集简介
ARC的数据集共包含7787道小学科学类多项选择题,均为纯文本的英语题目。此数据集相较于之前的QA数据集,例如SQuAD1.0和SNLI,拥有更高的难度,需要更强大的知识推理能力。此数据集使用一个语料库作为背景知识,用于在训练过程中提供背景信息。但是这个语料库并不是ARC数据集的唯一知识来源,所以在某种程度上,ARC挑战也可以被视为开放的挑战。
ARC数据集有两个不同的分区:简单集(Easy Set)和挑战集(Challenge Set)。简单集中包含5197个问题,挑战集中包含2590个问题。其中,挑战集的问题无法通过关键词检索和共现法(co-occurrence method)获得答案。这两组中的问题样本如下:
(1)EASY:Which technology was developed most recently?(A)cellular telephone(correct)(B)television(C)refrigerator(D)airplane
(2)CHALLENGE:What does photosynthesis produce that helps plants grow?(A)water(B)oxygen(C)protein(D)sugar(correct)
ARC数据集中,每个集合又分为训练集(Train Set)、测试集(Test Set)和开发集(Development Set)。关于ARC数据集的相关统计数据汇总见表1。
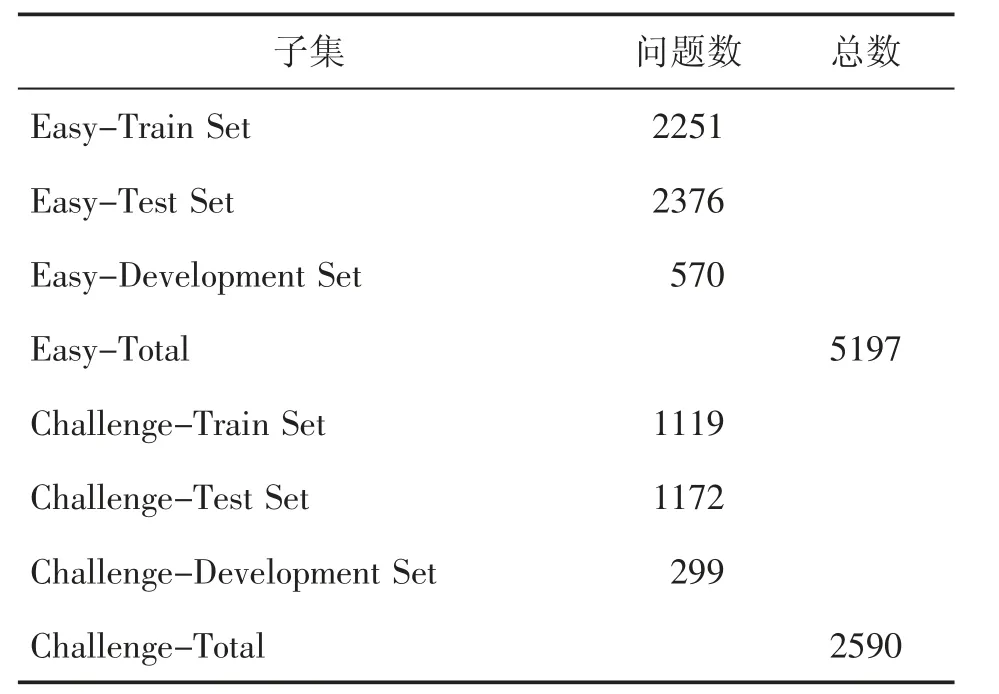
表1 ARC数据集分类统计
2 实验设计
2.1 已有模型缺陷分析
通过研究发现,基于BERT的NLP系统普遍存在两个方面的问题:一是BERT模型处理文档的长度有限;二是BERT模型本身在选择和排序上能力有限。例如,在OpenBookQA和多跳推理问题中,基础的思路是结合外部知识进行推理。首先,从给定资源或搜索引擎中提取外部知识;其次,将问题、选项与外部知识以某种形式相连接,以此作为输入,并对BERT模型进行微调(Finetune)。但这种方式很可能超过BERT模型处理文档的长度极限,同时这种方法也无法正确判定获得的外部知识的优先级。
2.2 提出实验设想
本实验使用RoBERTa模型作为基线模型,旨在研究预训练模型的各个方面(模型架构、模型体量、外部知识运用)对模型表现的影响。为了对这些方面进行对比观察,设计了一系列对比实验。
2.3 基线模型评估与误差分析
作为基线模型的RoBERTa模型,由艾伦人工智能研究所的亚里士多德团队基于RoBERTa-Large模型开发并发布。根据ARC数据集的提交记录,RoBERTa模型的准确率在0.66左右。本实验也对基线模型进行了测试,并得到了类相似的分数。在测试实验中,使用以下超参数:batch size:8;epoch:4;learning rate:10-5。
通过检查测试集中得到错误结果的数据发现,大多数错误是由背景知识与问题答案不匹配引起的。模型运行过程中的搜索算法是首先将每个答案选项与一些背景知识段落进行匹配,然后通过语言模型计算每个答案为正确的概率。如果问题答案与错误的知识段落匹配,那么模型很有可能会给出错误的答案。通过统计分析可将错误归为以下几类:
(1)未能从语料库中提取到有用信息;
(2)从语料库中提取到了干扰信息;
(3)缺乏物理、数学和化学方面的知识,但又无法从语料库中提取相关的有用信息;
(4)缺乏其他背景知识、常识,但又无法从语料库中提取相关的有用信息;
(5)未能理解同义词或反义词;
(6)未能正确处理指代消歧;
(7)无法回答需要统筹考虑所有选项的问题;
(8)未能理解事实的因果顺序。
这些错误指出了一个事实,即正确答案与无关背景知识段落的匹配是导致模型不准确的关键因素。
3 实验过程
本次实验使用训练集和开发集来开发和微调模型,并使用测试集进行最终的验证测试。训练集和开发集由四个数据集合并而来,这四个数据集分别是ARC train(1119题)、ARC Easy-train(2251题)、OpenBookQA train(4957题)、Regents Living Environments train(665题)。而作为最终测试集的是ARC Challenge-test Set。
3.1 RoBERTa模型
在使用RoBERTa模型进行训练时,将问题与选项组成一个句子作为输入文本。实验通过随机调换选项位置的方式来帮助模型更好地区分不同的选项。
实验还尝试使用RoBERTa模型研究外部知识是否有助于提高模型准确性。在本实验中,选择OpenBookQA语料库作为外部知识库。基于检索增强语言模型预训练(Retrieval-Augmented Language Model Pre-Training,REALM)[8]的方法,在三个方面对算法进行了简化:(1)使用局部敏感哈希算法(Locality Sensitive Hashing)[9]去快速存储和查询高维向量;(2)使用一个RoBERTa模型同时作为分类器(Classifier)和嵌入词提取器(Embedding Extractor);(3)通过将问题与知识[CLS]令牌编码的矢量输出相接来连接问题与知识,而不是简单的文本拼接。这些改进是为了缓解模型对计算机算力和内存需求的压力。下面是从OpenBookQA语料库中检索到的知识片段示例:
ARCCH question:Mixing baking soda and vinegar makes the temperature of the solution decrease and release carbon dioxide.Which conclusion about this investigation is not valid?choice1:Mixing the chemicals caused them to absorb heat.choice2:A chemical reaction took place.choice3:New elements were formed.choice4:The procedure caused a gas to be formed.
基于上述算法对知识片段与问题相关性进行评分,具体如下所示。
(1)A new moon happens once per revolution of the moon.
score:0.8764
(2)Earth is our planet.
score:0.0486
(3)Lake Erie is a body of water.score:0.0144
(4)The arctic is desolate.
score:0.0141
在以上基于RoBERTa模型的实验中,使用以下超参数:batch size:16;learning rate:1e-5;gradient accumulate steps:2;weight decay:0.01。
3.2 T5模型
T5模型有T5-small,T5-base,T5-large,T5-3B,t5-11B等不同体量。本实验采用T5-base模型和T5-3B模型来研究不同模型体量对模型表现的影响,并将ARC数据集作为唯一语料库进行训练。模型训练时将问题文本与所有选项拼接起来作为输入文本,并将正确答案及其文本内容作为输出目标。问题样本示例如下:
输入文本:"ARCCH question:George wants to warm his hands quickly by rubbing them.Which skin surface will produce the most heat?choice1:dry palms choice2:wet palms choice3:palms covered with oil choice:palms covered with lotion";
目标文本:"choice1:dry palms"
3.3 BERT模型
此次实验还使用了BERT模型,具体的预训练模型为BERT-base模型。BERT模型最多可接收两个使用[CLS]令牌编码分类的文本语句作为输入,但输出层可以适配不同的矢量长度。在实验设置中先将问题样本进行处理,即将问题的题干与每一个选项作为一次输入文本,这样每个问题就可以转化为四个样本。包含有正确选项的样本将被标记为1,包含错误选项的样本将被标记为0。样本示例如下:
原始样本:
EASY:Which technology was developed most recently?(A)cellular telephone(correct)(B)television(C)refrigerator(D)airplane
转化后样本:
(1)text.a=Which technology was developed most recently?
text.b=(A)cellular telephone
label=1
(2)text.a=Which technology was developed most recently?
text b=(B)television
label=0
(3)text.a=Which technology was developed most recently?
text.b=(C)refrigerator
label=0
(4)text.a=Which technology was developed most recently?
text.b=(D)airplane
label=0
在模型训练完成之后,使模型以同样的方式对处理后的开发集和测试集的数据进行预测,预测值为1表示答案正确,预测值为0表示答案错误。但是这种预测方式可能会造成(1)有多个选项被预测为正确或者(2)没有选项被预测为正确。针对情况(1),选择预测概率值最大的选项作为回答结果;针对情况(2),选择预测概率值最低的选项作为回答结果,以此来保证对每一个问题都有确切的答案。
此次实验同样使用了更小体量的BERTMedium模型进行测试,但其表现并不如BERTbase模型。由于计算资源有限,无法对BERTLarge模型进行训练测试,但是可以预想的是,大体量的模型将会有更高的准确率。
4 实验结果
实验中的模型表现统计结果见表2。

表2 模型准确率统计
下面依据上文中提出的实验设想对实验结果进行分析。
通过控制是否使用外部语料库进行预训练,对比同一模型的表现,即对比RoBERTa-base模型在未使用和使用OpenBookQA语料库情形下的模型准确率,RoBERTa-base(未使用OpenBookQA语料库):42.1;RoBERTa-base(使用OpenBookQA语料库):25.6。从结果上看,使用外部语料库反而降低了模型的表现结果,这与预期结果不符。使用OpenBookQA作为外部语料库的RoBERTa-base模型在实验中的结果并不理想,可能是由于在实验时过于简化了知识检索的过程,使之对外部知识的学习不够充分,从而产生了干扰。
通过控制模型架构,对比相同训练策略下同等体量、不同架构模型的表现,即对比相同训练策略下RoBERTa-base、BERT-base和T5-base模型的准确率(RoBERTa-base:42.1;BERT-base:35.5;T5-base:44.8)。从准确率来看,T5-base模型最优,其次是RoBERTa-base模型,T5-base和RoBERTa-base模型均优于BERT-base模型,但差距并不大。三个模型均为基线模型,即模型体量等级相同。由于RoBERTa是基于BERT模型的优化,而T5模型整合了基于BERT的多种优化策略,故此结果在实验预期之中。
实验发现T5模型比同样大小的RoBERTa和BERT模型有更好的表现,但差距不大。同时,将所有的因素与数据增加相结合都会使模型产生更好的表现结果。
通过控制模型体量,对比相同训练策略与相同模型架构下不同模型体量的模型表现,即对比相同训练策略下T5-base和T5-3B的模型准确率(T5-base:44.8;T5-3B:69.0)可知,T5-3B模型显著优于T5-base模型的性能,即大体量的模型在相同的数据集下可以达到更高的准确率。但是,由于模型体量的增大与性能的提升并不成比例,可以想见相同数据集下,模型体量的增大对模型表现的提升是有极限的,只一味增大模型体量并不是一个高性价比的举措。
从实验结果来看,相同体量的模型,更优化的模型架构会取得更好的实验效果。而本次实验的多次尝试中,T5-3B模型具有最优秀的模型效果,且相对于其他模型准确率有较大的提升,从而可以看出,在算力可承受范围内,相比其他策略,增大模型体量可以更加有效地提升模型表现。
下面使用T5-3B模型在实验中回答正确和错误作为样本案例:
(1)回答正确
ARCCH Question:a star with twice the mass as the sun would?choice1:start its life cycle with a fifission process.choice2:use its fuel source much more quickly.choice3:provide more solar flflares.choice4:result in a nebula.
Target:choice2:use its fuel source much more quickly.
Prediction:choice2:use its fuel source much more quickly.
(2)回答错误
ARCCH Question:what advantage do some plants have over animals in a drought?choice1:plants can use underground water.choice2:plants can live without water.choice3:plants release oxygen.choice4:plants cannot move.
Target:choice1:plants can use underground water.
Prediction:choice2:plants can live without water.
5 结语
本文研究了可能影响预训练语言模型的多种因素。虽然并不是一个系统性的消融实验,但通过实验对比,展示了不同的模型体量、神经网络结构、训练策略是如何导致模型性能差异的。实验发现,T5模型比同样大小的RoBERTa和BERT模型有更好的表现,但差距不大。同时将所有的因素与数据增加相结合都会使模型产生更好的表现结果。最重要的是,基于T5-3B模型显著优于T5-base模型表现的事实来看,大体量的模型可以对知识进行更好地编码索引,从而达到更高的准确率。
虽然扩大模型体量更容易获取广泛的知识从而得到更好的实验表现,但在实际应用中,探索新的算法依旧是有价值的。本文所实验的模型虽然在目前的探索实验中表现不佳,但仍旧不失为一种解决知识检索问题的潜在方法。
