小样本下基于深度学习的声呐图像分类研究
2022-09-09陈禹乐李博梁红杨长生
陈禹乐, 李博, 梁红, 杨长生
1.西北工业大学 航海学院, 陕西 西安 710072;2.中国船舶集团有限公司第705研究所 水下信息与控制重点实验室, 陕西 西安 710077
随着新时代我国海洋战略的不断深化,探测海洋和开发海洋的需要也在不断增加。水下航行器技术有了长足的进步,AUV和UUV等航行器的运载声呐已经成为水下信息获取的重要途径。基于成像声呐的自动目标识别技术(automatic target recognition,ATR)[1]已经成为了水下信息处理领域的一个重要研究课题。
现有的水下目标分类识别方法通常是人工提取特征[2]再经过分类器进行识别。基于深度学习的识别方法[3]可以直接从输入数据中自动提取特征、压缩特征向量并拟合目标映射,能够学习多层次的类别特征,从而避免手工提取过程中的特征损失,提高泛化能力,该方法为水下目标识别提供了新思想。Williams等提出了一种由多个卷积层和池化层构成的二元分类模型,对64×64的水下河床声呐图像进行识别分类[4], 相比传统方法取得较高目标识别率。季文韬[5]在VGG16网络模型的基础上,测试对比了在不同迁移学习策略下模型的分类效果。在水下目标的探测与识别中,已有众多学者将DNN和CNN等多种典型的神经网络用于提升水下目标的探测与识别的效果[6-7]。但目前基于深度学习方法的水下目标分类研究中广泛采用的是为了解决光学图像分类问题而构建并优化的网络。这些网络得益于数以百万计的光学图像积累在光学数据集上具有极高的识别正确率[8]。而真实水下环境中声呐传感器会受到随机噪声、观测角度以及目标材料的声呐反射特性等影响,导致声呐图像分辨率低、边缘不连续,在实际网络仿真时往往难以提取深层特征[9]。
金磊磊等[10]针对声呐图像特征提取困难的问题,在常规卷积神经网络的基础上提出融合图像显著区域分割和金字塔池化的水下自动目标识别模型,该模型在提高水下目标识别率的同时加快了目标图像预测速度,但并未进行小样本情况下的识别分类研究。由于声呐图像具有重建方法复杂多样[11]、获取困难和观测数据严重不足的特点,所以数量远少于光学图像。这种数据样本缺乏的情况被称为小样本(few shot learning,FSL)情况[12]。针对小样本条件下水下目标分类问题。巩文静等[13]提出一种基于MobilenetV2的声光图像融合目标分类方法,分析仿真结果发现该方法在纯声学图像上识别准确率仍然不理想。盛子旗等[14]使用基于样本仿真和迁移学习的YOLOv3方法,在侧扫声呐图像水雷目标检测任务上取得了优于传统的特征提取及检测方法的效果,但深度神经网络在小样本情况下进行训练得到的模型仍存在突出的过拟合问题。因此在光学图像识别上表现优异的深层网络模型直接用于声呐图像识别任务往往表现较差,识别准确率大幅下降。在小样本情况下经过单一策略优化后的模型也存在局限性,无法取得良好的识别精度。
为了解决小样本情况下卷积神经网络在声呐图像数据集上训练识别率较低的问题,本文建立了声呐数据集的预处理(pre-processing,PP)流程,提出了一种带有偏好的标签平滑策略(favored label smooth,FLS),同时通过实验得到了迁移学习(transfer learning,TL)参数的最佳冻结层数。本文融合以上3种优化方法,有效解决了小样本情况下卷积神经网络模型的训练过程不稳定和识别精度不足的问题。
1 数据集与网络模型的建立
1.1 声呐图像数据集介绍
声呐图像由于采集困难和获取成本高昂,目前业界没有统一公开的声呐数据集。所以为了进行本文的图像分类研究,本节建立了包含前视声呐、三维成像声呐和侧扫声呐等多种成像设备所生成的声呐图像数据集。此数据集不仅样本数量满足训练要求,同时包含多种成像方式的声呐图像有利于网络模型获得更好的泛化性。
三维成像声呐通过多个波束可以在水平(X)、垂直(Y)和距离(Z)3个维度上对目标进行成像。前视声呐通过向前方一定角度θ范围发射并接收反射回波进行成像。侧扫声呐在载体前进的过程中,逐行地记录排列回波数据,得到二维海底图像。通过整理和筛选,将3种成像声呐的图像归为5类,分别为飞机、轮胎、管道、石块和瓶子,共489张声呐图片。声呐图像数据集每类数量如表1所示,图1为各类声呐图像样例。

图1 5类声呐图像样例

表1 5类声呐图像数据样本个数
1.2 图像预处理
成像声呐回波信号会受到水下环境的各种干扰,产生畸变、波动和衰减等复杂的变化,导致声呐图像背景噪声较强。声呐图像获取成本高、目标样本稀缺一直是制约声呐图像识别精度的难题。为了降噪和提升小样本下数据集的泛化性,对1.1节所建立声呐数据集进行了预处理。采用3×3中值滤波降噪在最大化保留原始信息的基础上去除环境噪声。基于降噪后的图片分别进行了水平镜像翻转(mirror flip)操作,3次幅度为90°的旋转;随机裁剪(random crop),裁剪范围为图片长和宽的[0.9,1.1]倍,再通过图像插值(image interpolation)恢复原图大小。将1.1节中所得到489张图像随机选取98张作为测试集(20%),剩下的经过以上3种图像增广方式,训练集和验证集数据量被增加到原来的3倍,由391张变为1 173张。
为了使输入具有统一的规范性,提高输入的可靠性,将声呐图像经过降噪和增广后进行了规范化操作,即将图像尺寸重置为(224,224),并进行了灰度转换和归一化操作。
1.3 基础网络模型
卷积神经网络(convolutional neural network,CNN)是一种受到生物视觉感知启发而设计出来的前馈神经网络。与传统的神经网络不同,CNN由输入层、卷积层、池化层、全连接层和输出层组成。这些基础层结构可以任意组合叠加得到深层网络,深层CNN可以提取高阶特征,非常适合解决图像识别问题。深度卷积神经网络通过卷积层和非线性激活函数的结构来提取待分类图像的特定特征。在经过卷积层和归一化函数(softmax)处理后,所得到的特征矩阵的尺寸每次都在减小,这会导致部分特征的消失。为了解决这个问题,本文选用在光学图像分类上取得优异成果的深度残差学习(deep residual learning)网络[15]作为分类模型。本文网络模型在一台AMD Ryzen 9 3990X CPU,RTX 3070 GPU,内存为64 G的台式机工作站上采用1.9.1版本的Pytorch框架以及5.1.5的Spyder IDE进行仿真实验,操作系统为Windows10。由表2可见ResNet-18在上述实验中识别准确率最高,故选取其作为本文的基础网络模型。但在仿真实验的过程中发现网络模型会出现过拟合和收敛过程不稳定等现象,可见在小样本下将残差网络直接用于识别的效果并不理想。
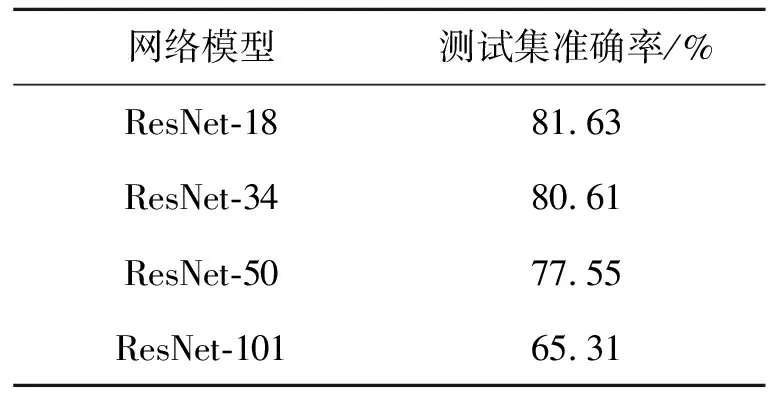
表2 4种典型残差网络准确率
2 标签平滑
为达到减缓网络过拟合程度同时提高识别准确率的目的,提出在分类网络中引入标签平滑(label smooth,LS)。通过在基础网络模型上创建一个新的损失函数,同时实现现有的交叉熵(cross entropy loss)函数和标签平滑功能。
2.1 标签平滑原理
标签平滑又叫标签平滑正则化(label smooth regularization,LSR)[16],是指对样本的二进制标签向量y进行一次正则化更新:
y=(1-ε)y+ε/n
(1)
式中:ε为一个较小的超参数;n为分类的类别数(标签向量的位数)。定义yk为第k类目标的二进制标签向量值,target为当前类的真实标签值,标签向量的one-hot编码第i位数值为i,则有
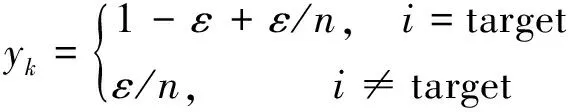
(2)
令α=-ε+ε/n,则有

(3)
单个样本的交叉熵损失函数定义为

(4)
此时,错误标签处的二进制向量值yk(i≠target)不再为0,因此由损失函数的计算公式(4),将L最小化的过程不会再使得模型向预测正确和错误标签logits差值无限增大的方向学习,便解决了网络过于自信的问题。
为了验证在ResNet-18上改变LS中参数α对实验结果的影响,本文在不同α下使用LS方法进行仿真实验,网络迭代50轮次得到了如表3所示实验结果。

表3 改变α对ResNet-18网络训练结果的影响
通过表3可以看出,LS方法在一定程度上提高了网络的识别率,当α=0.08时,LS方法的效果达到了最佳。但如图2a)所示混淆矩阵,第4类石块目标仍有很大概率被误判为第1类飞机目标。
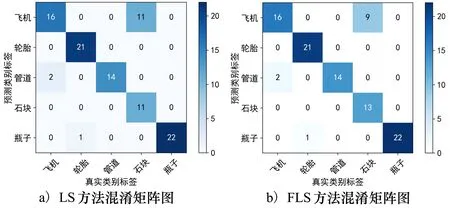
图2 在α=0.08,β=0.15基于LS方法
2.2 一种改进的标签平滑方法
由2.1节可知,随着α的增大,网络的训练集损失收敛值也随之增大,这样对整个训练过程不利。由于在训练过程中某些类别存在错误率显著高于其他类别的情况,需要对标签平滑公式(3)做出一定的优化,以使得网络在不过于自信的前提下降低训练集的损失,使参数设置可以更贴近于整个数据集的分布。
通过分析图2a)基于LSR方法绘制的混淆矩阵,本文分析网络的训练结果后提出一种改进的LSR方法。将训练结果中测试集预测误差最大的类别称为最大错误类别m,定义最大错误类别m下的类别标签的one-hot编码为yk=m,其他类别标签的one-hot编码中最大错误类别的对应位置yk≠m,则有:
式中,β为提前设定的超参数。
由于这种标签平滑方法对真实标签类别有显著的偏袒,并削弱最大错误类别的自信度。因此本文将(5)式和(6)式的方法称为偏好标签平滑正则化(favored label smooth,FLS)。同样采用ResNet-18在第1节建立的声呐数据集上保持FLS的参数α不变,改变参数β训练50轮次得到表4所示实验结果。

表4 改变β对ResNet-18网络训练结果的影响(α=0.08)
从表4的结果可以看出,当α=0.08时β=0.15达到该方法在本文数据集上性能的最大值,可以发现标签平滑降低了验证集损失,并显著抑制了过拟合现象。由图2b)混淆矩阵可见,FLS方法大幅减少了石块目标的分类错误数,增加了最大错误类别的分类准确率。当β=0.4时,FLS方法甚至不如不进行FLS的结果,说明过多地倾向于某一标签会造成网络准确率的下降。所以在实际使用FLS方法时应根据训练情况合理选择β的数值,进而达到分类模型的最优识别准确率。
3 迁移学习
标签平滑方法通过降低网络的自信度提高了模型的对声呐图像的识别性能,为了在声呐数据集上使得深层卷积网络获得一个较为合理的初始参数,提升训练中对多层次特征提取的效果,本节引入了迁移学习(transfer learning)[17]。迁移学习通常是借助一个样本数量多且容易获得的数据集对网络参数进行预训练。由于难以获取足够量的声呐图像用于迁移学习,并且提取图像的轮廓、纹理等底层信息所对应的中低级特征对于不同的分类任务是通用的,本文使用ImageNet的子集mini-ImageNet进行预训练,该数据集大小约为3 GB,共有100类数据,每类数据600张图片。对于利用光学图像训练结果提升声呐图像识别能力这类异构任务迁移问题,常见的解决方法为网络参数微调(fine tune)[18]。微调是迁移学习的一种方法,这种方法冻结预训练模型的部分层,固定冻结层中的参数不会随着训练而改变,这样有利于图像底层特征的提取。对于基准ResNet-18而言,可供冻结的前5个部分一般有5种冻结方式。将冻结的部分数称为Nf,Nf=5代表冻结前5层,以此类推,Nf=0代表不对网络参数进行冻结。将通过mini-ImageNet预训练的ResNet-18的网络参数按不同的冻结方式导入用于训练声呐图像数据集的网络,并在与前文相同的训练环境和标准下进行训练,结果如表5所示。

表5 改变冻结层数ResNet-18网络微调训练结果
从表5的结果可以看出,微调的方法可以显著提高网络的测试集准确率,说明通过mini-ImageNet预训练的网络参数成功地被迁移到了用于声呐图像识别的网络上。当Nf=3,ResNet-18网络模型取得了最高的目标识别率。
4 基于小样本下多策略融合识别方法
在前文讨论中,本文通过图像预处理(PP)的方法丰富了数据量;并提出采用标签平滑正则化方法(LS)有效优化了对网络模型的训练;同时在标签平滑基础上根据训练结果进一步提出带有标签类别偏好的改进方法-偏好标签平滑(FLS),使得网络向着更加稳健和泛化的方向训练,有效降低了网络的自信程度,提高了准确率;而后基于迁移学习(TL)中微调的方法,将网络参数通过对mini-ImageNet进行训练以获得预训练权重,这提高了网络对特征信息的提取能力,有效提升了分类精度。基于这几种优化方法的讨论本文提出了一种结合多种优化策略的小样本声呐图像识别方法。策略融合的本质是挑选几种合理可行的优化方法,针对各种方法的特点进行适当的组合,从而在融合后的网络模型上取得理想的识别准确率。对网络模型的优化而言策略融合成本极低,提出的多策略融合方案可以横向再次扩充出更多的策略进行组合。

图3 结合多种优化策略的小样本声呐图像识别方法
图3给出了本文提出的结合多种优化策略的小样本声呐图像识别方法的示意图。具体步骤为:
1) 将声呐图像数据集进行降噪和数据增广等数据预处理操作,作为网络的训练数据;
2) 利用带偏好的标签正则化方法对训练数据的标签进行平滑优化;
3) 基于迁移学习,将通过大量数据预训练的网络模型参数以微调的方法导入卷积神经网络中;
4) 利用卷积神经网络进行训练和分类识别。
下面验证本文提出的结合多种优化策略的小样本声呐图像识别方法的有效性。在与前文相同的训练环境和标准下,在未进行数据增广和降噪的原始数据集上使用融合图像显著区域分割(GMR)和金字塔池化(SPP)的常规卷积网络模型[10]、基于迁移学习的YOLOv3模型[14]以及ResNet-18网络模型进行仿真实验(实验1~3),而后在经过预处理(PP)后的数据集上,将基础ResNet-18网络模型与偏好标签平滑(FLS)和迁移学习(TL)分别组合得到如表6所示的多种网络模型,分别选用上述各个模型进行仿真(实验4~7),结果如表6所示。基于表4和表5的实验结果,下列仿真实验所用到的FLS中α=0.08,β=0.15。TL中取Nf=3。

表6 各模型仿真实验结果
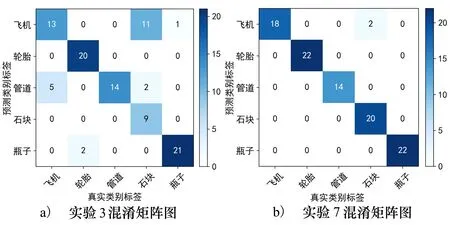
图4 实验3和实验7混淆矩阵图

图5 各模型迭代曲线
综合实验1,2和7的结果,可见本文网络模型收敛快,10轮次左右就达到最高验证集准确率,迭代过程平稳,且测试集识别准确率显著优于其他模型。通过表6中实验3和实验4的仿真结果可见,在经过数据增广和降噪后的数据集上,ResNet-18准确率提升约了3%,说明了本文数据预处理可以有效提升网络识别准确率。综合实验5和6的仿真结果,相较于基准网络而言,本文选取的几种优化方法组合后均能取得一定的识别准确率提升。实验3和7的结果表明使用本文提出的结合多种优化策略的小样本声呐图像识别方法时,网络模型取得了96.94%的识别率,相较基础网络(ResNet-18)提升了约18.4%,达到了准确区分各类目标的要求。从图5的准确率及损失曲线可见,本文优化方案大幅抑制了模型过拟合现象,有效地提高了训练过程的稳定性。从图4b)混淆矩阵数值分布可以得到准确率为0.979 6, 该方案明显减少了最大错误类别(石块)的分类错误数量,证明了本文方法的有效性。
5 结 论
本文结合声呐图像特点,建立了声呐图像的预处理流程,针对卷积神经网络在小样本图像识别过程中的不足,在原有深度残差学习网络基础上提出了一种带偏好的标签平滑方法,抑制了网络训练中的过拟合现象,同时利用网络参数微调的方法解决了异构任务的迁移学习问题。结合以上3种优化方法提出了一种小样本下声呐图像多策略融合识别方法。经过分析训练实验所得到混淆矩阵,该方法对各类目标均取得了超过90%的识别准确率,取得了显著优于经过单一策略优化后算法的分类精度。
