自适应图近邻的张量低秩表示多视图聚类
2022-09-09杨暄皓潘柏丞蔡松岳
杨暄皓 潘柏丞* 蔡松岳
(1.西南大学电子信息工程学院 重庆市 400715 2.重庆大学计算机学院 重庆市 401331)
多视图聚类在模式识别和机器学习领域引起了广泛的关注。它具体应用于人体动作识别,图像聚类,疾病识别,图片分割,人脸识别,文档聚类等方向。
多视图聚类是对比于单视图聚类形成的一个概念,单视图聚类是对一个视图组成的数据进行聚类,而多视图聚类是对不同来源和不同描述方式组成的多视图数据进行聚类。由于利用了不同视图的信息,多视图聚类的性能通常要优于单试图聚类。当前较为流行的多视图聚类方法有基于图的方法和基于张量的方法等。
基于图的方法通常是将原始的多视图数据划分成一个表示点与点之间关系的图。文献和文献将拉普拉斯矩阵加入目标函数中来达成一个图正则化的作用。王等人将一种被称为概念分解(Concept Factorization)的矩阵分解技术与图正则化结合,试图通过分解出的投影矩阵进行图正则化,增强聚类效果。聂等人提出了一种基于自适应图近邻的聚类方法,这种方法通过每个点的近邻的距离自适应地学习图的相似矩阵。
基于张量的方法是将所有视图的表达矩阵结合成一个三维张量,然后用张量低秩表示的方法对视图间信息充分利用,从而提高聚类性能。张等人最早提出张量多视图聚类,但是所使用的范数还是基于矩阵奇异值分解的,对视图间的信息运用的并不是很充分。谢等人提出了一种基于张量奇异值分解的方法,这种方法弥补了张的方法的缺点,兼顾视图间的信息使得谢的方法具有优异的效果。
除了以上两种方法,还有大量其他类型的多视图聚类方法。例如基于矩阵分解的方法,子空间聚类方法,深度学习或基于神经网络的方法,基于支持向量机的方法,线性判别分析的方法,共训练方法等。
本文提出的模型是基于张量与图的方法。通过张量低秩表示,使得本文的模型可以使用高维的信息,增强聚类效果。在张量低秩表示上加入了自适应图近邻的方法,表现了局部图中点与点之间的距离,从而自适应地学习相似矩阵,对我们所要得到的表达张量形成一个正则化,使聚类的性能增强。
本文的主要贡献总结如下:
(1)本文提出一种自适应图近邻的张量低秩表示模型(LRTRAGN),在张量低秩表示的基础上增加了自适应图近邻约束,能提升算法的聚类性能。
(2)本文提出了一种基于交替乘子法的优化方法,用于优化提出的自适应近邻的张量低秩模型。
(3)本文将提出的方法与其它先进的聚类方法在多个真实数据集上进行对比,表现出了该方法的优越性和先进性。
本文剩下的部分如下组织。第一节说明符号和定义以及介绍最近关于多视图聚类的一些研究工作。第二节提出自适应图近邻的张量表示模型(LRTRAGN),并对该模型进行优化。第三节是该模型与其它先进方法在聚类表现上的对比与分析。第四节是对本文的总结。
1 基础知识
本节我们将介绍本文中用到的符号和关于多视图聚类的最近的一些研究工作。
1.1 符号和定义

一个张量的块对角矩阵表示为:
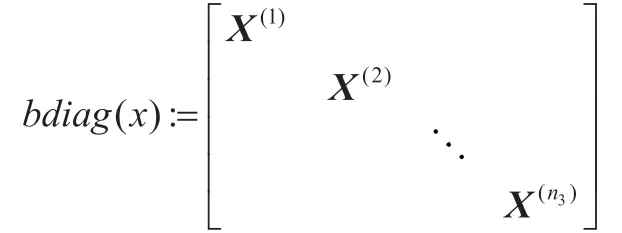
块循环矩阵表示为:

定义3(f-对角张量(f-Diagonal Tensor)):当一个张量的所有正切片全为对角矩阵时,它被称为f-对角张量。

其中*代表张量乘法。

1.2 最近的工作
根据低秩张量表示的思想,谢等人提出了一个基于张量低秩的多视图统一自表示聚类模型:

图近邻聚类的思想是当两个点距离越近时,它们是同一类的概率就越高;所以取一个点的所有近邻,最小化它与每个其它近邻的欧氏距离与相似概率相乘的积。聂等人提出了自适应图近邻模型:
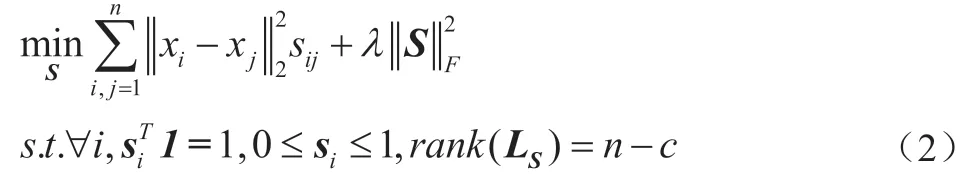
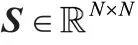
2 自适应图近邻的张量低秩表示模型
我们将自适应图近邻的思想加入张量低秩表示中,可以得到:


但是问题(4)依然难以直接解决,但是根据文献的方法,我们可改写问题(4)并得到最终的目标函数为:
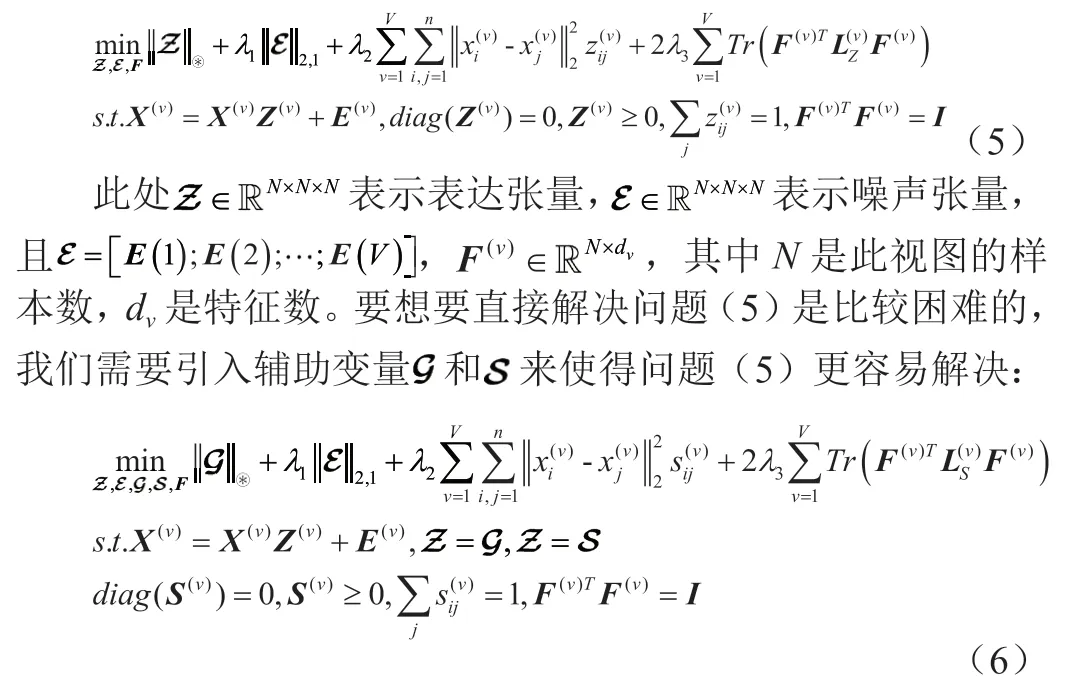
我们采用交替方向乘子法来解决问题。我们可以得到问题(6)的增广拉格朗日形式如下:


从问题(10),我们可以得到:




算法1是对本算法的总结。我们设置收敛条件如下:
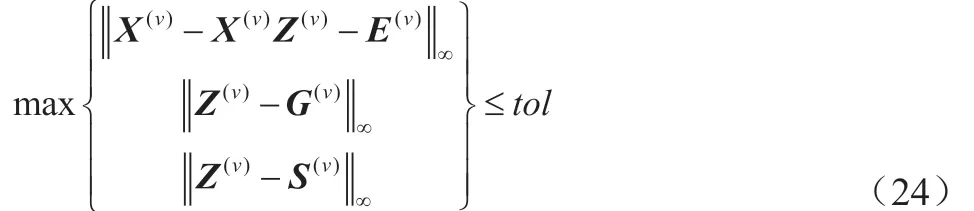
此处tol是一个较小的正参数,本文中设为10。

算法 1 自适应邻居的张量低秩表示算法(LRTRAGN)输入:多视图数据images/BZ_182_698_2319_808_2374.png,参数(1)初始化:根据K近邻方法得出初始矩阵 ,让, ,并用初始的 通过(13)构造初始的 。, , ,,images/BZ_182_1056_2495_1141_2537.png,,,。(2)While not converged do(3)用等式(9)更新 ;(4)解决问题(12)更新 ;(5)解决问题(13)更新 ;(6)解决问题(16)更新images/BZ_182_691_2805_727_2856.png;(7)根据式子(19)更新images/BZ_182_691_2868_722_2909.png;(8)分别根据等式(20),(21),(22),(23)更新, , , 。(9)End While输出:images/BZ_182_355_3078_398_3122.png和images/BZ_182_438_3078_470_3122.png。
3 实验结果
本节我们将介绍实验所用真实数据集,对比方法和实验指标。然后,我们对实验结果进行对比分析。
3.1 数据集与对比方法
BBCsport: BBCsport数据集是来源于BBC新闻网站的体育新闻。它有两个视图,包含544个文档,其中有5类体育主题。
UCI: UCI手写数据集包含了从“0”到“9”的十类手写数据。每个类别有200个样本,所以一共包含2000张图片。本数据集包含三个视图,包括240维的像素,76维的傅里叶系数,6维的形态特征。图1为UCI数据集部分样本图。

图1:UCI数据集部分样本
3.2 对比方法
SSCbest:一种稀疏表示的单视图子空间聚类方法。
LRRbest:一种通过低秩表示寻找子空间字典的联系的单视图子空间聚类方法。
RMSC:一种多视图谱聚类方法,它基于马尔可夫链方法,通过低秩和稀疏表示来寻找最优的可能性转移矩阵。
LT-MSC:一种多视图聚类方法,它将多个视图的代表矩阵重构成一个代表张量,通过张量低秩表示提高算法性能。
MVCC:一种带有局部流形约束的多视图聚类方法。
CSMSC:一种同时考虑了代表矩阵之间的一致性与互补性的子空间多视图聚类方法。
MLRSSC:一种同时考虑了仿射矩阵的低秩性和稀疏性以及不同视图间代表矩阵的一致性的子空间多视图聚类方法。
tSVDMSC:一种将表达矩阵构造为表达张量并对其使用张量低秩表示的多视图聚类方法。
3.3 实验指标
我们在对比实验结果时选取了6个流行的参数,包括准确度(ACC),归一化互信息(NMI),调整兰德系数(AR),F-分数(F-score),精确率(Presision),召回率(Recall)。对于所有的指标而言,值越高,那么表现出来的聚类效果就越好。
3.4 实验效果对比
表1和表2是在真实数据集上的对比实验结果。我们将所有的实验运行10次,然后取均值和标准差作为实验结果。在所有表格中,加粗字体表示此数据是对比方法中的最优。
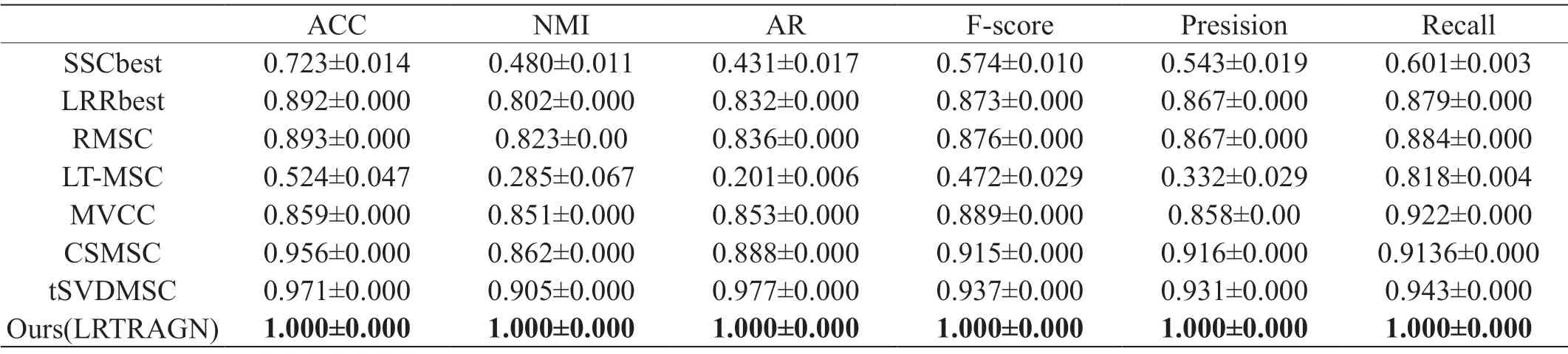
表1:不同方法在BBCsport数据集上的表现

表2:不同方法在UCI数据集上的表现
LRTRAGN在BBCsport和UCI数据集上的所有指标的表现都是最优。LRTRAGN与tSVDMSC和LT-MSC都是基于张量的方法,并且LRTRAGN可视为tSVDMSC的改进方法。LRTRAGN分别在BBCsport与UCI上比tSVDMSC提高约9%和3%的性能;比LT-MSC提高了约95%和27%的性能。LRTRAGN与MVCC都对目标函数运用了基于图的正则项,但LRTRAGN分别在BBCsport与UCI上比MVCC提高了约15%和50%的性能。以上实验对比充分说明了LRTRAGN的优越性和先进性。
4 结论
本文提出了一种自适应邻居的张量低秩表示模型,用于解决多视图聚类问题。通过低秩张量表示和图近邻的方法,该模型将视图间的高维信息以及局部图的近邻信息高效地运用了起来。通过在两个真实数据集上,与多种先进方法对比的实验凸显出了该模型的先进性和有效性。
