基于Python的古诗文数据爬取与可视化分析
2022-09-09任夏荔
任夏荔
(山西职业技术学院 山西省太原市 030006)
1 引言
众所周知,中国传统文化博大精深,源远流长, 古诗词是中华民族传统文化重要的文化载体,并且以其独特的形态,传递给人们不同的人文内涵,从而形成了我国文化史上一道靓丽的风景线。
随着大数据技术的发展,大数据分析技术也已开始运用于行业中。那么,传统文化中的古诗词与新兴的大数据分析技术发生碰撞,会擦出怎样的火花呢?
本文利用爬虫技术和可视化技术,使用Python 语言,借助其丰富的第三方库,实现了古诗文数据的爬取和可视化,并对可视化结果进行了简要的分析。
2 关键技术
2.1 Python语言
Python 是数据科学与数据分析领域的优先选择,丰富的第三方库、开源社区、及不断优化的使用文档,为许多非计算机领域的学习者提供了广阔的入门与精通渠道。
2.2 网络爬虫
网络爬虫也被形象地称为网络蜘蛛、网络机器人,是一个可以自动下载网易的计算机程序或自动化脚本。网络爬虫就像一只蜘蛛一样在互联网上爬行,它以一个被称为种子集的URL 集合为起点,沿着URL 的丝线爬行,下载每一个URL 所指向的网页,分析页面内容,提取每个URL 并记录下每个已经爬行过的URL,如此往复,直到URL 队列为空或满足设定的终止条件为止,最终达到遍历Web 的目的。
关于网络爬虫的实现,通常有两种方式,一种是使用专门的爬虫软件,另一种则是使用编程语言。就第二种方式而言,有很多语言可以用于实现爬虫,如Python、Java、PHP、C++等。Python 中有许多可用于爬虫开发的库,包括urlib、urlib3、Requests、Scrapy、Beautiful Soup、Selenium 等。本文采用Python 语言结合Selenium 库来完成数据的爬取。
Selenium 是一个Web 应用程序的自动测试工具,支持多种浏览器,模拟人工使用浏览器的操作。
2.3 数据可视化
数据可视化分析是大数据时代的重要研究方向,“一图胜千言”,当数据以生动的可视化图表的形式展示出来时,分析人员往往能够便捷地洞察隐藏在数据背后的有效信息,并据此作出相应决策。
用于实现数据可视化的工具有很多,诸如Tableau、PowerBI、Zeppelin、Python 等。就Python 可视化而言,有许多可用于可视化的库,包括Matplotlib、PyEcharts、Plotly等。本文采用Python 语言结合PyEcharts 库来完成数据的可视化。
PyEcharts 是一个用于生成Echarts 图表的JS 类库,Echarts 是百度开源的一个数据可视化工具包。利用PyEcharts,通过编写少量代码就可方便快捷地生成Echarts风格的各种图表,是大数据时代进行数据可视化的常用方案。
3 总体设计
本文的数据来自于古诗文网(https://www.gushiwen.cn/),本文沿着爬取数据、清洗数据、存储数据、可视化数据的技术路线,技术路线图如图1 所示,着重从以下几个角度对关于思乡类的古诗文展开分析:

图1 :技术路线
(1)古诗文作者更青睐于用哪些词抒发思乡之情?
(2)关于思乡的古诗文中出现频率最高的前10 个词分别是什么?
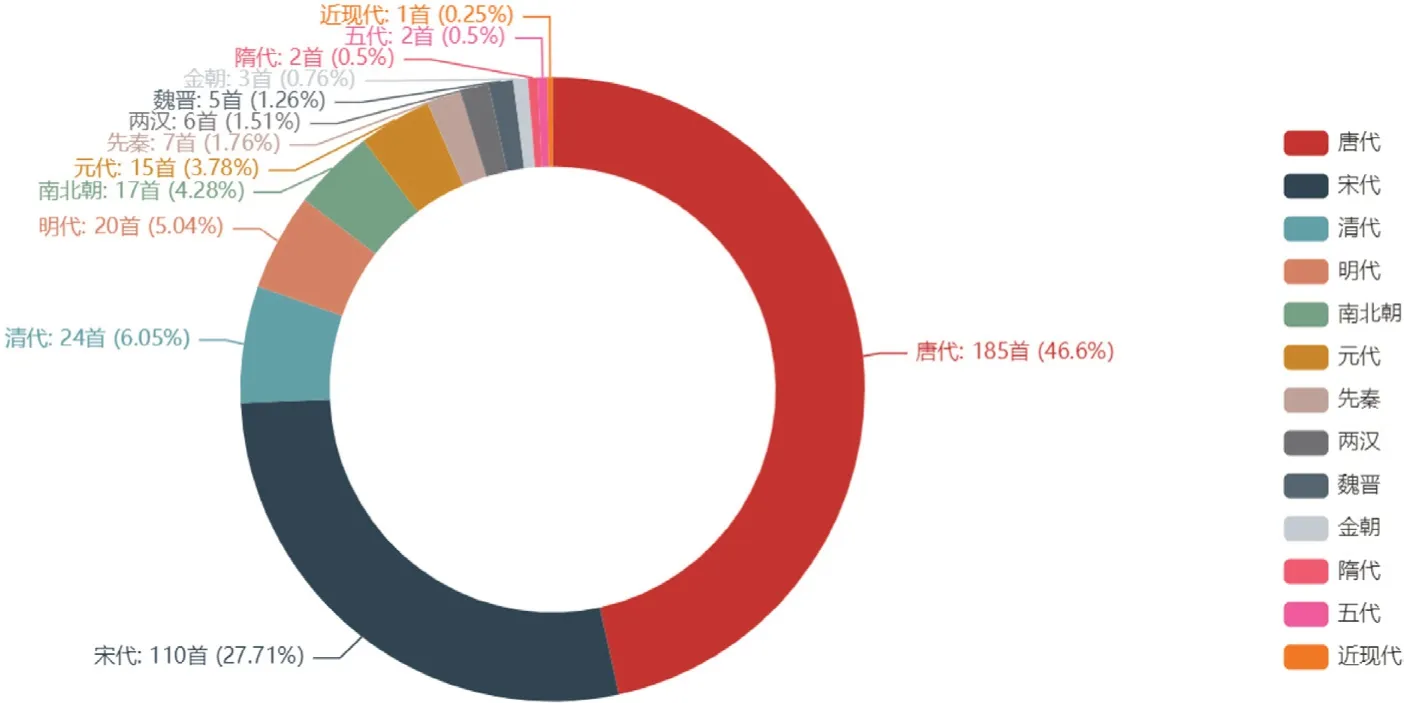
(3)哪个朝代(或时代)的思乡类古诗文最多?
(4)各个朝代(或时代)的思乡类古诗文数量占比情况如何?
4 具体实现
4.1 爬取数据
古诗文网收录了很多诗词曲赋、经典古文,资源全面,分类详细,方便获取古诗文相关资料。通过对古诗文网的分析,发现首页的右侧设有分类栏,“思乡”也在其中,点击“思乡”会跳转到新的页面,其中以链接的形式罗列了关于思乡的古诗名,点击各古诗名即可查看到相应的诗文内容、译文、注释、创作背景、赏析等。本文使用Python 语言结合Selenium 库爬取古诗文网中收录的关于“思乡”的古诗文。具体步骤如下:
(1)使用 web=webdriver.Chrome()打开古诗文网首页,调用web.get()方法传入网址获取页面内容。
(2)调用 web.find_element().click()方法,通过XPATH定位到首页右侧的“思乡”类别,并模拟点击操作,跳转页面。
(3)利用web.switch_to.window(web.window_handles[1])方法,定位到新的窗口,即“关于思乡的古诗”页面。
(4)调用 web.find_elements()[0],通过CLASS_NAME找到所有“思乡”类古诗文链接的