基于改进特征金字塔网络和注意力机制的场景文本检测
2022-09-09邹伟平冯辉扬龙鑫
邹伟平 冯辉扬 龙鑫
(1.南昌大学信息化办公室(与网络中心合署)江西省南昌市 330031)
(2.南昌大学数学与计算机学院 江西省南昌市 330031)
1 引言
不同于传统的扫描图像文本,自然场景中的文本具有形状和字体多样、尺度不一、背景复杂等特点,因此该领域的文本检测更具挑战性。当前基于语义分割的检测方法由于能检测任意形状的文本因此受到了更多的关注。
基于语义分割的方法主要受全卷积神经网络(Fully Convolutional Networks,FCN)的启发预测像素级别的文本标签,因此能够检测出任意形状的文本。Deng等人提出的 Pixellink 算法对像素点进行文本与非文本预测以及预测文本像素的8 个方向上是否存在连接。Long等人提出的TextSnake 算法通过预测文本中心线并通过围绕中心线使用不同半径和连接角度的圆盘覆盖文本区域。Wang等人提出的PSENet 算法通过渐进式尺度扩展后处理以提高检测精度。Liao等人提出的DBNet 通过加入自适应二值化提高输出图对阈值的鲁棒性,是一种目前应用广泛的基于分割的文本检测算法。
对于高分辨率输入图像,文本检测模型感受野不足是目前存在的普遍问题;对于目前使用广泛的特征金字塔输出的不同尺度的特征图直接进行上采样后拼接,会引入大量的冗余信息造成检测效果的下降。针对上述问题,本文研究提出了可切换空洞卷积与注意力导向的特征金字塔网络(SDAFPN),提高模型感受野并融合粗细粒度特征,引入注意力导向模块(AM)以增强特征的语义信息且减少空洞卷积对文本边界信息的破坏;针对特征融合阶段引入冗余信息的问题,提出了特征增强融合模块(FEFM),在特征层级、空间位置、输出通道上增加注意力机制,增强模型对尺度、空间、任务的感知能力。
2 改进的文本检测算法
2.1 整体算法架构
本文在DBNet 的基础上融合了SDA-FPN 与FEFM,其整体结构如图1 所示。算法采用ResNet 作为主干网络,使用下采样率为1/4,1/8,1/16,1/32 的特征图作为SDAFPN 的输入,记为{F2,F3,F4,F5},且把F5 输入到可切换空洞卷积与自注意力模块(Switchable Dilated Convolutions and Self-Attention Module, SDSM)与AM 模块中,然后与经过1×1 卷积的F5 按位相加得到特征图P5,再通过SDAFPN 的自顶向下与横向连接获取不同尺度的特征输出记为{P2,P3,P4,P5}。把不同尺度的特征图输入特征增强融合模块FEFM 进行特征融合得到融合后的特征图F,最后把特征图F 输入到DBHead(Diあerentiable Binarization Head,DBHead),即可得到最终的文本区域。
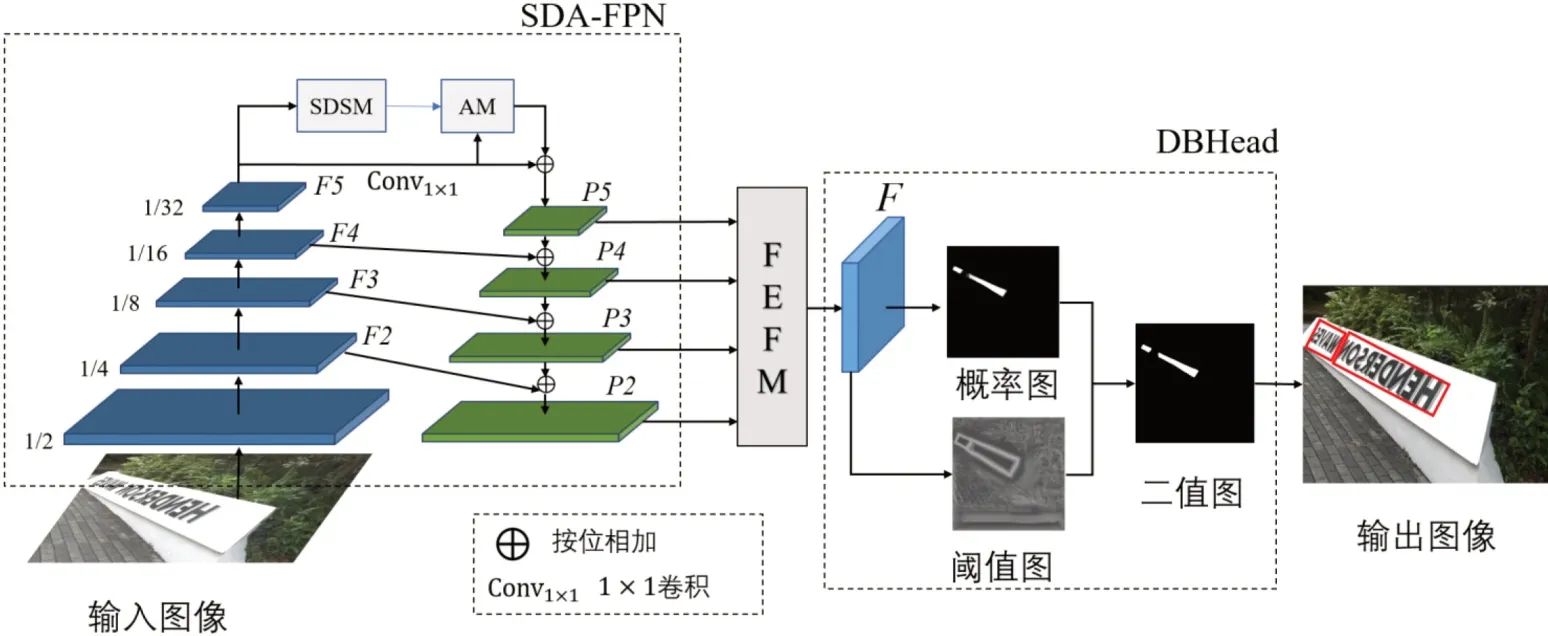
图1 :整体算法网络结构图
2.2 可切换空洞卷积与注意力导向的特征金字塔网络
本文提出的SDA-FPN 具体结构如图2 所示,该网络包含了可切换空洞卷积与自注意力模块(Switchable Dilated Convolutio-ns and Self-Attention Module,SDSM)与AM 模块,SDSM 模块通过双分支结构实现了粗细粒度特征的融合;AM 模块能够增强特征语义信息并减少空洞卷积对文本位置信息的破坏。

图2 :可切换空洞卷积与注意力导向的特征金字塔网络结构图
2.2.1 可切换空洞卷积与自注意力模块(SDSM)
SDSM模块有两个分支,分别为融合了可切换空洞卷积的密集连接分支与使用了自注意力模块的分支。两个分支分别获取到不同感受野的细粒度特征与保留了初始输入信息的粗粒度特征。最后将两个分支输出的特征图进行拼接并送到1×1 卷积实现粗细粒度特征的融合。
可切换空洞卷积能够根据任务需求选择不同空洞率的卷积,其结构如图3 所示,包含两个上下文模块及SAC(Switchable Atrous Convloution)模块。使用y=Conv(x,w,r)表示一个输入为x,权重为w,空洞率为r 的3×3 卷积,则本文使用的SAC 可表示为:

图3 :可切换的空洞卷积结构
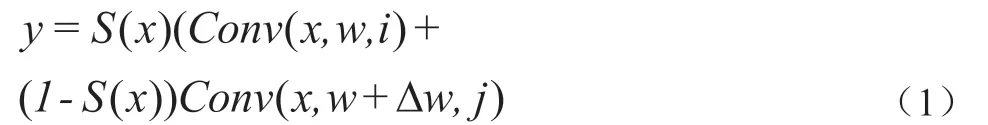
其中i 表示第一个卷积的空洞率,j 表示第二个卷积的空洞率,S(x)为经过5×5 全局平均池化与1×1 卷积的开关函数,Δw 为可训练参数。两个不同空洞率的卷积使用一种权重锁定机,对于空洞率为j 的卷积只需要学习Δw 即可,Δw初始化值为0。对密集连接的可切换空洞卷积空洞率(i,j)可设置为(1,3),(3,6),(6,12),(12,18)和(18,24)。
2.2.2 注意力导向模块(AM)
AM 模块包含上下文注意力模块(CxAM)与内容注意力模块(CnAM)以分别增强特征的语义信息与边界位置信息。CxAM 与CnAM 的结构如图4 所示,CxAM 与CnAM都是基于自注意力机制且结构大体相似,CnAM 的Q、K 是由骨干网络的特征F5 得到,因为F5 包含更多的位置信息,V 则与CxAM 一样由特征F 经过1×1 得到。
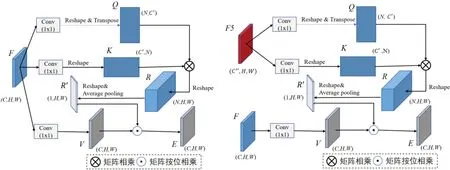
图4 :上下文注意力模块CxAM(左)与内容注意力模块CnAM(右)



将特征V 与注意力矩阵R'按位相乘即可得到输入特征F 的注意力表示 。最后把CxAM、CnAM 输出的特征图以及SDSM 模块输出特征F 按位相加得到特征F',再把F'与经过1×1 卷积的特征F5 按位相加则可以得到特征金字塔的特征P5。
2.3 特征增强融合模块(FEFM)
本文受动态检测头(dynamic head)启发,提出了特征增强融合模块FEFM,其结构如图5 所示,通过结合注意力机制增加特征对尺度、空间、任务的感知能力。

图5 :特征融合模块(FEFM)
首先对输入特征P(i=2,3,4,5)增加特征层级的注意力,使用P与其邻近的特征P,P进行加权融合,若i=2 或5 则只使用其上方或下方特征图进行加权融合。通过1×1卷积计算各层特征对应的注意力系数把注意力系数与对应的特征层按位相乘后拼接即可得到尺度感知增强后的特征L(i=2,3,4,5)。接下来使用空间注意力模块增强特征的空间位置感知能力,最后使用动态Relu(Dynamic Relu,DyRelu)激活函数对S增加输出通道的注意力。
3 实验
3.1 数据集与评价指标
本文自然场景文本检测中常用的公开数据集ICDAR2015。ICDAR2015共包含1500张图片,其中1000 张作为训练集,500 张作为测试集,图像分辨率是1280×720。使用常用的文本检测指标即准确率(Precision)、召回率(Recall)、F 值(F-measure)对算法进行评估。
3.2 实验分析
3.2.1 消融实验
为了验证本文提出的SDA-FPN 与FEFM 的有效性,本小节通过在数据集ICDAR2015 上对模型进行消融实验。表1 为消融实验结果。

表1 :各部分对实验结果的影响
通过对表1 分析可知,本文提出的改进对比DBNet 的准确率都有轻微下降,而DBNet 的召回率偏低,漏检现象严重。 添加了SDA-FPN 的DBNet 召回率提高了3.7%,准确率下降了1.6%,F 值提高了1.4%。添加了FEFM 的DBNet,准确率与F 值分别下降了5.5%和1.6%,召回率提高了1.3%。结合了SDA-FPN 与FEFM 的DBNet,对比DBNet 虽然准确率下降了1.6%,但是召回率增加了5.7%,F 值提高了2.6%。
3.2.2 对比实验
ICDAR2015 实验结果如表2 所示,本文提出的方法在准确率上达到88.6%,仅比DBNet 低了1.6%,高于表2 中的其余算法。本文方法的召回率达到80.1%,比TextSnake低了0.3%,高于表2 中其余算法。F 值达到84.2%,高于表2 中其余算法。因此本文方法在ICDAR2015 数据集上获得了不错的综合性能。

表2 :ICDAR2015 数据集检测结果
图6为在数据集ICDAR2015中的测试效果展示实例图,如图中红色箭头区域所示,本文算法对于密集文本以及长文本的漏检问题有明显的改善。

图6 :ICDAR2015 测试效果展示实例图
4 结束语
本文针对当前自然场景文本检测算法模型感受野不足的问题,提出了可切换空洞卷积与注意力导向的特征金字塔网络SDA-FPN,并提出特征增强融合模块FEFM 以减少特征融合阶段引入的冗余信息。实验结果表明,本文算法在多方向文本数据集ICDAR2015 上综合指标F 值为 84.2%,比DBNet 提升了2.6%。未来的工作考虑对自然场景图像的小文本检测进行更加深入的研究。
