在适老化服务中智能语音技术的应用研究
2022-09-08胡宏
胡 宏
江苏号百信息服务有限公司
0 引言
通过拨打运营商特服号码进行业务受理退定、积分兑换、预约挂号等业务是运营商给市民提供的便捷线上电话受理服务,这种方式给市民提供了一条直接的沟通渠道。然而在实际使用中,我们发现了一些问题,老年客户群体在使用电话进行业务办理时,往往使用不是非常顺畅。其焦点问题在于业务受理退定、积分兑换、预约挂号等业务通常需要输入服务密码,老年客户群体往往记不住自己密码或不知道服务密码是什么,因此在业务受理时,话务员通常要花很多时间对老年客户群体进行辅导和确认,服务效率大为降低。面对老年客户群体,如何在提升服务质量的同时提高服务效率,成为摆在运营商面前的新课题。
近几年来,智能语音技术发展迅速,其中语音识别、声纹识别两项核心技术进步速度尤为突出。利用语音识别技术将人类语音中的词汇内容转换为计算机可读信息的输入,在很多人机交互场景中得到广泛应用。语音识别技术在电信运营商内部的应用也愈发广泛成熟,各大运营商的客服热线均使用了此技术,随着语音识别率的提升,客户体验感越来越好。声纹技术则是智能语音技术的另一项重要分支,又称为说话人识别,即通过声音来辨别谁在说话,其核心技术是根据语音信号中说话人的个性化信息来识别说话人生物信息。随着声纹识别技术的大幅进步,在电话信道中识别出说话人是否为本人,已经具备可能性。语音识别技术和声纹识别技术各有所长,两者结合应用可以产生很好的作用。
基于运营商电话语音通道,语音识别技术和声纹识别技术可以成为运营商在适老化服务领域破题的关键钥匙。通过建立“智能采集+声纹识别+语音识别”为内核的智能适老化语音系统,形成智能化适老化服务体系,提供真正意义上的适老化便捷服务。
1 智能适老化语音系统架构及流程设计
智能适老化语音系统的总体框架如图1所示。
系统分为3层,分别是话务接口层、鉴别能力层和应用层。话务接口层主要应用运营商的话务能力,提供外呼录音采集和实时电话镜像及提醒服务。鉴别能力层主要提供了声纹识别和语音/语义识别能力。而综合管理模块则提供了数据服务、统计服务和其他各项能力。
智能适老化语音系统的运转流程如图2所示,具体流程如下:(1)通过智能语音外呼进行录音预采集,并通过语音语义识别辅助判断音频有效性,建立客户录音库;(2)转化电话录音到声纹特征库;(3)通话实时镜像采集,启动声纹实时采集并判断;(4)推送判断结果至话务系统,辅助话务员进行鉴权操作。

图2 智能适老化语音系统场景实现
智能适老化语音系统核心模块为语音语义识别模块、声纹识别模块。语音语义识别模块采用国际领先的语音识别引擎,可根据智能客服领域常用词汇构建语言模型和声学模型,从而将语音识别为最终对应的文本内容。语义理解采用先进的语义匹配算法,能够实现机器人按照既定逻辑进行AI交互,简洁的图形化配置UI大大降低了AI配置门槛。
声纹识别管理模块,核心功能模块包含声纹采集、声纹注册、声纹确认、声纹辨认等,通过标准服务输出能力。利用被动与主动式声纹注册,无感式声纹识别,当老年客户群体致电时,系统能够准确判断是否为本人。
2 外呼录音采集的实现
智能适老化语音系统实现的前提条件是对客户有效录音的采集。录音的采集分为两个步骤,第一个步骤是通过智能语音的方式对客户进行外呼,获取客户声音文件;第二个步骤为通过语音语义识别进行辅助判断,来确定获取的客户声音文件是否是可以有效生成声纹的文件。
2.1 智能语音外呼录音采集
在进行智能语音外呼采集前需先进行智能语音采集流程的模型建立。通常来讲,语音采集需要客户跟读3-5段话,每段话尽量简单,每段话有效字数尽量长,图3为示例模板。

图3 智能适老化语音系统电话汇报流程图
智能语音外呼录音采集的子步骤分为2步:
(1)声纹采集授权:客户通过公众号、网页等方式进入声纹注册页面,阅读声纹采集说明之后对声纹采集行为进行客户授权。
(2)通话注册:客户授权后,由平台发起声纹注册电话,智能机器人引导客户跟读若干句对话,后台对对话进行录音,通话结束后,客户的个人信息和对话录音将被绑定映射送往语音语义识别辅助判断子模块进行处理。
2.2 语音语义识别辅助判断
录音采集后,进入语音语义辅助判断模块,如图4所示。语音语义辅助判断模块的主要方法有语音识别(ASR)辅助筛选、录音时长判断、语速判断等等,语音语义识别辅助判断主要有以下4个步骤:
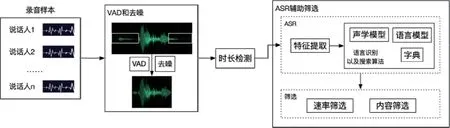
图4 语音语义识别辅助判断流程
(1)源数据准备,在客户被告知的情况下对客户的电话通话录音进行获取并处理,每位客户留存一条以客户的号码命名的通话录音,并且本条通话录音是只包含客户对话声音的单通道文件,将通话录音格式转为wav文件。
(2)静音和底噪切除,对录音进行静音检测(VAD)操作,去除每段通话录音中大段的静音;检测录音中小于阈值且持续超过一定时长的底噪录音,将该部分切除。接着将去除静音和底噪的录音进行合并。
(3)时长检测,检测去静音去噪音后的录音时长t_wav,检测通话录音时长是否超过阈值τ,保证样本的长度,时长不满足需求的直接筛除,时长满足阈值要求则进入下一步。
(4)对上一步筛选的通话录音进行ASR辅助检测,主要对录音的语速和内容进行检测。
通过4个步骤的录音则被认定为可以做声纹采集入库的有效录音。
3 声纹库的建立和声纹识别流程
想要对客户进行声纹鉴权,除了获取客户的录音,还需要三个模块,首先是包含客户注册声纹信息的声纹库;其次是需要识别模型,还需要根据声纹样本对识别模型进行优化迭代训练,保证识别算法的泛化性;最后是封装了声纹识别模型的身份鉴别模块。当有客户需要进行身份鉴别,根据客户映射关系,调动声纹库的相关声纹特征,和待鉴别声纹一起输入算法,进行相似度计算,然后根据阈值判定身份,再将结果同步给前端。因此,根据功能上的需求,本模块包括声纹库模块、模型训练优化子模块以及身份鉴别子模块,如图5所示。
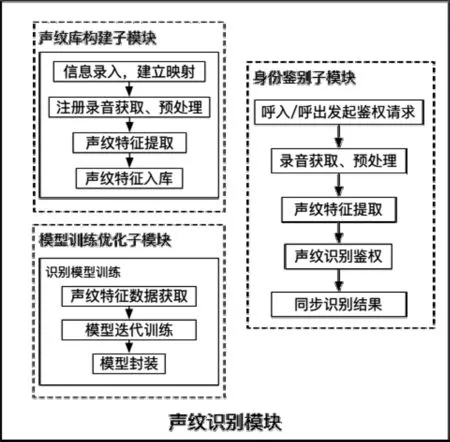
图5 声纹库及识别模型构建模块和声纹身份鉴别模块
3.1 声纹库构建子模块
声纹库构建子模块主要负责注册语音以及注册信息的映射存储。当收到客户的注册请求并采集到客户的注册语音后,声纹库构建子模块将注册相关信息取出,与注册录音映射存储起来。接着对获取的注册录音进行处理,获得声纹特征之后根据再映射关系存入到声纹库中,具体操作如图6所示。

图6 声纹库构建子模块
(1)信息录入建立映射:客户通过公众号、网页等注册方式提起声纹注册请求之后,客户的个人信息以及客户的注册录音将传入本模块,声纹库构建模块对二者构建映射,通过身份证等唯一信息标识存储到声纹信息库中。
(2)处理注册录音:注册录音中可能存在静音、噪声等干扰段,声纹处理后台首先对录音信息进行预处理,去除噪声、静音、按键音等干扰音,保证录音的质量。
(3)声纹特征提取:对预处理后的声音进行梅尔倒谱系数(MFCC)变换和通用背景模型高斯(UBM-GMM)变换,提取成数字序列,并存入到声纹库中。后续通过身份证或者手机号等唯一信息标志可以直接取出对应的声纹进行进一步的比对工作。
(4)返回注册结果:将注册结果返回给请求端。
3.2 模型训练优化子模块
身份鉴别子模块主要负责识别模型生成和客户身份鉴别。模型生成主要是采集通话信道的录音,进行声纹识别算法迭代训练;来电客户身份鉴别在通话流程开展,后台获取对话录音后自动调用算法进行声纹识别。得到结果后异步更新数据库,客服人员后续可以在前台页面上看见本次通话是否是本人,如果发现异常可以及时处理,其流程如图7所示。

图7 模型训练优化子模块
模型训练优化子模块主要负责对识别算法的构建和迭代优化。模型主要针对声纹库中的声纹特征不断进行迭代训练和优化,保证模型的准确性和泛化性,具体训练优化步骤如下所示:
(1)数据采集:前期暂无真实通话数据的阶段,主要收集公共数据集,共计2000条,来进行算法训练,作为基准训练数据(项目开始后用真实通话录音进行算法迭代),该数据的80%用来训练,20%用来测试。
(2)数据预处理:将每条录音经过静音检测技术(VAD),获取去静音的声音片段,接着再对其进行去噪、去按键音、语音增强等步骤,对录音中的有效片段进行提取。
(3)训练ubm、ivector:调整参数,将数据送入声纹模型,迭代训练ubm和ivector,直至算法模型收敛。
(4)模型测试:用测试数据集对收敛模型进行准确率测试,重复以上步骤直至算法准确度达到标准。
(5)模型封装:将训练好的模型封装成调用方法,以便声纹对比时调用。
3.3 身份鉴别子模块
身份鉴别子模块主要负责客户身份鉴别。客户的身份鉴别在通话流程开展,后台获取对话录音后自动调用算法进行声纹识别。得到结果后同步更新数据库,通话流程控制端则根据反馈的鉴别结果来控制是否为通话者提供免鉴权服务,流程如图8所示。
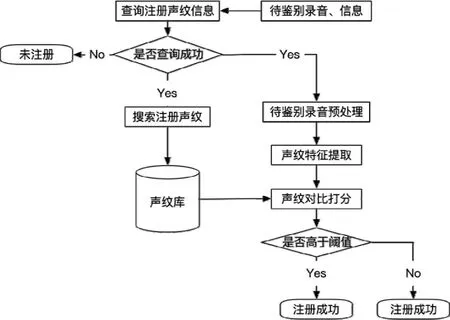
图8 身份鉴别子模块
(1)识别录音采集:客户按照对话脚本进行对话,在对话过程中,碰到需要鉴权的步骤,后台主动获取通话的单声道录音,并将对身份鉴别模块发起身份识别请求。
(2)数据预处理:身份鉴别后台获取录音后对其进行VAD、去按键音、降噪等预处理工作,接着对声音进行MFCC变换和UBM-GMM变换,初步提取待鉴别声音特征。
(3)i-vector提取:将处理好的注册声音特征信息和待比对声音特征信息送入训练好的声纹模型中,提取i-vector特征。
(4)声纹识别:根据两段录音的i-vector信息对两段录音的相似度进行plda打分,如果高于阈值则识别为同一个人,如果低于阈值则不是同一个人。
(5)比对结果更新:将比对结果同步返回给通话流程端,通话流程根据鉴别结果来判断是否为通话者提供免鉴权服务。
4 实时电话镜像及提醒的实现
智能适老化语音系统使用场景为在话务员和老年客户通话时,可以给话务员进行是否是本人的鉴权提示,此功能在通话中应是无感知的,因此需要无感地在通话过程中采集客户的声音流信息。实时电话镜像并解析的方法是实现此功能的最佳办法,其技术方法步骤如下:
(1)呼叫中心服务器上联交换口镜像抓包(SIP信令)。当话务员和客户建立通话时,启动镜像抓包程序,使用TCPDUMP工具对信令传输网口进行全时段抓包操作,然后对数据包中的SIP信令执行过滤、保存操作。
(2)数据包解析。对抓取到的SIP数据包进行解析,获取主叫、被叫和时间戳基本信息、主叫媒体传输端口、被叫媒体传输端口等信息,保存主被叫实时音频流信息。
(3)与当前通话主被叫信息进行对比,并传送当前主叫音频流(客户)数据送至声纹识别模块。
(4)获取声纹对比结果,以websocket方式将结果推送至话务员界面。
通过以上操作,可以无感地给话务员推送当前客户身份声纹鉴权结果,方便话务员进行后期操作。
5 结束语
智能适老化语音系统在积分兑换业务试点市率先使用,该市积分兑换每日办理业务通话呼入量平均约140通,训练有素的话务员每班有3人,每日话务中,老年人来电约占36%,采用智能适老化语音系统作为辅助服务前后,话务接通率、人工话务接听数、业务完结率及平均话务耗时等参数变化如表1所示。

表1 采用智能适老化语音系统前后的对比
智能适老化语音系统结合电信总机业务,为运营商特服号码提供了便利老年人的服务渠道,疫情期间,线下业务办理受阻,线上业务需求增多,在话务员不足的情况下,智能客服提供了高质量的辅助服务,确保增多的话务量能得到及时承接,提高了话务接通率,加快了单项业务的办理速度,减轻了特服号码话务员的工作,方便老年客户群体在信息化智能服务中获得简单便捷的辅助服务。
