基于Sentinel 数据的临海市森林地上生物量估测
2022-09-07曹依林吴达胜方陆明
曹依林,吴达胜,方陆明
(1.浙江农林大学 数学与计算机科学学院,浙江 杭州 311300;2.林业感知技术与智能装备国家林业和草原局重点实验室,浙江 杭州 311300)
森林是地球上面积最大、结构最复杂的陆地生态系统,具有保持水土、调节气候、维护生态平衡等多种生态功能[1-2],是地球上最大的碳库[3-4]。森林生物量是森林生态系统最基本的数量特征,约占陆地生态系统生物量总量的90%[5],是森林碳储量估测的常用替代方式[6],包括了地上生物量和地下生物量。森林地上生物量(Above-ground Biomass,AGB)约占整个森林生物量的70%~90%[7-8],是森林生态系统固碳能力的直观表达和评估森林生态系统碳收支的重要指标,是森林生态系统发挥其他生态功能的物质基础[2,9-10]。
近年来,森林AGB 的研究受到研究人员的广泛关注,在数据源变得愈加丰富的今天,特征选择尤为重要。在森林AGB 估测研究中,特征选择方法常用估测方法本身对特征变量进行筛选,如用随机森林[11-12]、多元线性回归[12-13]等方法来对参数进行筛选,或者引入专门的方法对特征进行相关性分析,如皮尔逊相关系数(Pearson Correlation)[14-15]等。使用特征选择算法结合集成学习算法探索特征数量和组合的研究较少[16-17]。同时,大部分研究结果尚不够理想,估测精度在70%~80%[18]。虽有极少量的研究表明估测精度超过80%,但多数集中在针对少量的森林资源固定样地或自设的调查样地得到的研究结果[19-21]。研究中用大区域尺度上的建模技术探究不同林分下的特征数量及组合,更准确地估测森林AGB,仍然是待解决的难题。
据此,本研究以浙江省台州市临海市为研究区域,利用Sentinel-1 SAR 数据与Sentinel-2 光学遥感影像进行融合,以森林资源二类调查数据和数字高程模型作为辅助数据,对高维数据产生的大量特征使用递归特征消除法筛选出主要的影响因子,选择随机森林(Random Forest,RF)、自适应提升机(AdaBoost)和类别提升机(CatBoost)三种机器学习算法构建临海市森林地上生物量估测模型,并比较其性能指标,以期探究森林地上AGB 的影响因素及高精度的估测方法。
1 研究区域概况
临海市是浙江省县级市,地处浙江东部沿海,地理坐标为28°40′~29°04′ N,120°49′~121°41′ E,海拔在700~1 200 m,东西最大横距为85 km,南北最大纵距为44 km,陆地总面积为2 203 km2。全市森林覆盖率为64.2%,城市绿地覆盖率为41%。属亚热带季风气候,年平均气温为17.3℃,常年平均降水量为1 638 mm,无霜期为241 d,气候温暖湿润。该地区的主要林分类型有阔叶混交林、针阔混交林、针叶混交林、其他硬阔林、马尾松Pinus massoniana林、杉木Cunninghamia lanceolata林6 种。
2 研究方法
2.1 研究数据与预处理
2.1.1 遥感数据及预处理 研究涉及的Sentinel-1、Sentinel-2 遥感影像数据来自于欧洲航天局官网,Sentinel-1产品选用干涉宽模式下的S1 TOPS-mode SLC 数据,包括2017 年10 月13 日、10 月15 日各1 景影像。Sentinel-2产品类型选择L1C 级多光谱数据(MSI),包括4 景影像,获取时间从2017 年10 月底至11 月中旬。
采用哨兵卫星数据处理的开源软件SNAP 对Sentinel-1 进行轨道校正、边界噪声消除、热噪声去除、相干斑滤波、辐射定标、分贝化等预处理;Sentinel-2 数据的预处理包括使用Sen2cor 插件进行大气校正,使用SNAP进行超分辨率合成。然后,使用ENVI 软件将Sentinel-1 和Sentinel-2 影像坐标系转换为CGCS_2000 坐标系,再分别拼接Sentinel-1 的2 景影像和Sentinel-2 的4 景影像。最后,以临海市行政矢量图为边界对拼接后的遥感影像进行裁剪,最终得到研究区域影像,见图1 和图2。由于日期不同以及入射角度和光照等差异,在图像拼接时进行透明处理、匀色、羽化等操作后,连接处仍存在一定的颜色差异。
图1 临海市Sentinel-1 遥感影像Figure1 Sentinel-1 remote sensing image of Linhai city
图2 临海市Sentinel-2 遥感影像Figure 2 Sentinel-2 remote sensing image of Linhai city
2.1.2 DEM 数据处理 研究区的DEM 数据来源于2009 年美国地质勘查局(USGS)发布的ASTER GDEM第二版(v2)数据,包括4 景影像,空间分辨率为30m。使用ArcGIS 软件将4 景图像坐标转换为CGCS_2000坐标系并进行拼接处理,再以临海市行政矢量图为边界裁剪后得到研究区域最终的DEM 影像,如图3 所示。
图3 临海市DEM 影像Figure 3 DEM image of Linhai city
2.1.3 森林资源二类调查数据预处理 本研究使用的森林资源二类调查数据来自于2017 年临海市森林资源二类调查结果,包括59 636 个小班初始数据,由于本文计算生物量使用的是蓄积量—生物量转换公式,故对森林资源二类调查数据中蓄积量值为空的小班进行剔除,继而剔除灌木、非林地、耕地等小班,之后再使用三倍标准差法剔除异常小班,最后得到有效小班数据24 183 个,按林分类型划分为六类:阔叶混交林8 408个、针阔混交林5 693 个、针叶混交林1 977 个、其他硬阔林3 725 个、马尾松林2 852 个、杉木林1 528 个。
三倍标准差法又称拉依达法,以三倍标准偏差作为可疑数据筛选的标准,如公式(1)所示。

式中,n为样本个数;xi为第i个样本的值;为总样本的算术平均值;σ为标准差。正常值为范围内的数值,超出该范围的值则为异常值。
2.2 生物量计算公式
国内外许多研究表明,森林蓄积量和生物量之间存在显著的回归关系。本研究采用方精云等[22]提出的生物量转换因子函数法根据蓄积量求得生物量,具体计算方法如公式(2)所示。

式中,B为单位面积生物量(t·hm-2);V为单位面积蓄积量(m3·hm-2);a、b 均为常数。不同林分类型对应的a、b 参数如表1 所示,除针叶混交林的参数引自文献[23],其余林分的参数引自文献[22]。

表1 生物量和蓄积量转换模型参数Table 1 Parameters for biomass and stand volume conversion model
使用生物量转换因子函数法结合森林资源二类调查数据对研究区小班的六类林分的地上生物量进行统计,结果如表2。
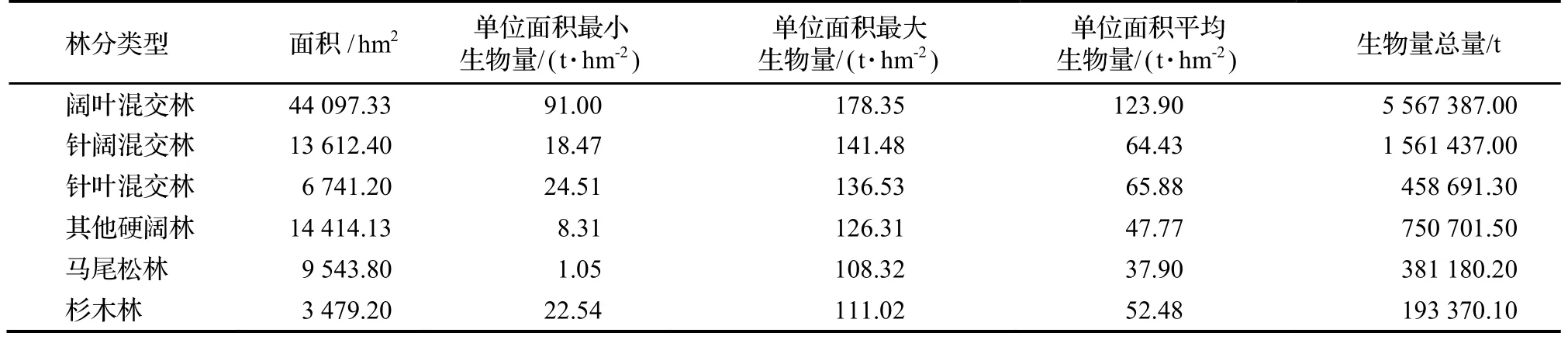
表2 基于生物量转换因子函数法计算各林分森林地上生物量结果Table 2 AGB based on biomass conversion model
2.3 构建初始自变量因子集
2.3.1 光学遥感自变量因子(1)光谱特征因子 Sentinel-2 可覆盖13 个光谱波段,其中,B1、B9、B10 三个波段的空间分辨率较低(仅为60 m),同时考虑到B10 波段作为卷云波段未进行大气校正,B1 深蓝波段和B9 水汽波段与本研究的相关性不大,因而去除这3 个波段,剩余的10 个波段参与后续实验。为进一步丰富研究数据维度,基于上述10 个波段计算得到9 个常用植被指数和从红边波段提取的5 个植被指数也参与后续实验,如表3。

表3 植被指数及计算公式Table 3 Vegetation index and computational formula
(2)纹理特征因子 本研究的纹理图像使用灰度共生矩阵(GLCM)计算,选取7 种窗口大小(1×1、3×3、5×5、7×7、9×9、11×11、13×13)及2 种角度(45°右斜线方向、135°左斜线方向)计算森林纹理特征值,分析不同窗口和角度下各纹理因子对AGB 的预测能力。各组纹理特征均采用默认步长进行计算。
纹理特征包括:均值(Mean)、方差(Variance)、协同性(Homogeneity)、对比度(Contrast)、相异性(Dissimilarity)、熵(Entropy)、角二阶矩(Angular second moment)、相关性(Correlation)8 个因子。
2.3.2 雷达遥感自变量因子 使用了4 个Sentinel-1 雷达遥感因子,分别为后向散射系数(VV、VH)、极化比值(VV/VH)和极化差值(VV-VH)。
2.3.3 DEM 自变量因子 从数字高程模型(DEM)中提取海拔、坡度和坡向3 个因子。
2.3.4 森林资源二类调查自变量因子 从森林资源二类调查数据中选用自变量因子郁闭度(YU_BI_DU)、年龄(NL)、起源(QI_YUAN)和地貌(DI_MAO)4 个因子。
2.4 自变量因子数据集成
将2.3 节共计43 个自变量因子的数据都以森林小班为单元进行集成,即每个小班为一条记录,每条记录均包含了43个数据项,最终得到24 183 条记录作为本文的实验样本。继而将24 183 个样本按7∶3 的比例划分为训练集和测试集参与后续的建模和估测。
2.5 递归特征消除
在AGB 估测中,特征变量的选择是影响估测效率及效果的重要因素之一。高维的特征因子丰富了信息的维度,但过多的特征变量容易导致训练速度过慢,同时也可能导致过拟合等问题。为加快模型训练速度,提高模型的泛化能力,本文在正式估测AGB 之前,采用递归特征消除法(Recursive Feature Elimination,RFE)进行特征选择。RFE 通过逐步移除特征重要性最低的某个特征来达到降维的目的,其算法流程如图4。
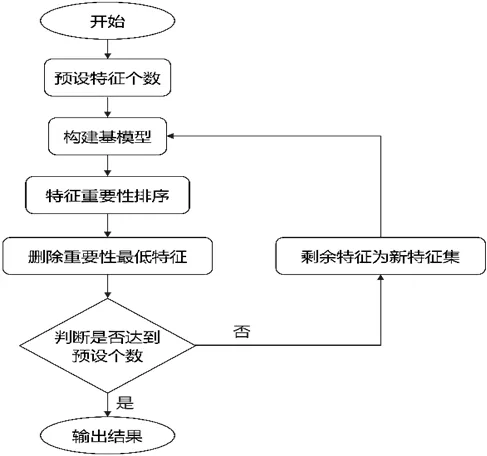
图4 RFE 流程图Figure 4 Flow chart of recursive feature elimination
2.6 机器学习算法
本文所涉及的三种算法(RF、AdaBoost 和CatBoost)均采用Python 编程实现,使用网格搜索的方式得到最优参数。因三种算法中,仅有CatBoost 能自动处理类别变量,而RF 和AdaBoost 并不具备这种能力,本研究使用独热编码(One-Hot)对这两种算法涉及到的分类变量值进行预处理。
2.6.1 RF 随机森林算法(RF)是一种建立在决策树上的集成学习算法,应用Bagging 模型对多棵决策树进行组合[24-25]。对于回归问题,随机森林通常采用均值的方法将所有结果整合。本研究设置树的数量(n_estimators)为150,最大特征数(max_features)设置为特征个数的平方根,最大深度(max_depth)设为16。
2.6.2 AdaBoost 自适应提升算法(AdaBoost)是一种Boosting 类型的迭代算法。首先,建立一个弱学习器模型,通过对各样本评估,调整其权重大小,从而在后续的新模型中可以更专注于前模型的难点[26-27]。最终结果的获取通过各学习器加权平均得到。AdaBoost 模型构建使用基学习器(base_estimators)为DecisionTreeRegressor,基学习器提升次数(n_estimators)为150,学习率(learning_rate)为0.05,损失函数(loss)为linear。
2.6.3 CatBoost CatBoost 算法来源于“Category”和“Boosting”,属于Boosting 算法的一种。该算法基于对称决策树的高准确性GBDT 框架,最显著的特点是可以高效合理地处理类别特征。CatBoost 算法首先对类别特征做一些统计,计算某个类别特征出现的频率,之后加上超参数,生成新的数值特征[28-29]。在参数设置上,CatBoost设置迭代次数iterations=200,深度(depth)为8,学习率为0.05。
2.7 模型评价指标
本研究通过十折交叉验证法进行模型评估,评价指标包括:决定系数(R-squared,R²)、均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和估测精度(Prediction,P),计算公式如下:
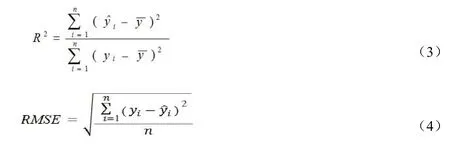

式中,n表示样本数,yi为实测值,为预估值,为实测值平均值,。
3 结果与分析
3.1 纹理特征选择结果
本文利用SelectKBest 方法来衡量纹理特征因子的重要性程度,对14 组共计112 个纹理特征因子的重要性进行排序(如图5),再优先选取重要程度相对较大(>20)的纹理特征加入到估测模型的自变量集中。可以看出,在135°下各窗口特征重要性>20 的特征数量最多,均为4 个,且在该角度下13×13 窗口的特征重要性占比最高。据此选取窗口大小为13×13、角度为135°的纹理特征加入到自变量因子集参与建模与估测。
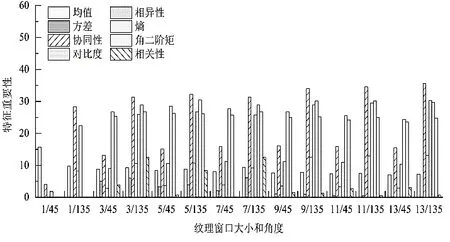
图5 不同窗口大小/角度下纹理特征的重要性Figure 5 The importance of texture features at various window sizes/angles
3.2 自变量选择
本研究所涉及的初始自变量共计43 个因子,包括10 个光学遥感波段因子、4 个雷达遥感影像因子、14 个植被指数、8 个纹理特征、3 个地形因子以及4 个森林资源二类调查数据。其中,二类调查数据中的起源和地貌2 个因子为类别特征,直接进入后续实验;其余的41 个特征,采用递归特征消除法进行逐步删减,每次移除特征重要性最低的某个特征。对不同数量和组合的自变量分别基于RF、AdaBoost 和CatBoost 算法对6 种林分的AGB 进行估测,计算出决定系数(R2)和均方根误差(RMSE),并进行对比分析,结果如图6。
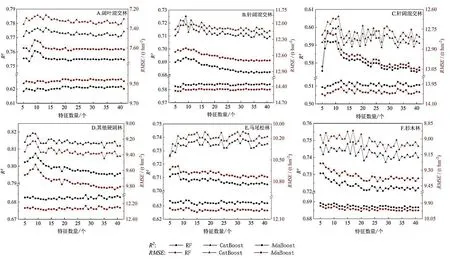
图6 各模型在不同特征组合和林分下的性能指标Figure 6 Performance index of different models based on various feature combinations and various forest types
为了兼顾模型的效率及效果,本文尽量选取性能指标好同时特征数量少的模型及特征数量。依据这一原则,在RF、AdaBoost、CatBoost 模型中,阔叶混交林分别选用9、19、13 个特征,针阔混交林分别选用9、14、7个特征,针叶混交林分别选用7、12、11 个特征,其他硬阔林分别选用9、8、8 个特征,马尾松林分别选用8、11、15 个特征,杉木林分别选用5、5、15 个特征。
3.3 AGB 建模与估测
分别针对6 种林分使用与其对应的最佳特征组合对其AGB 进行建模,计算得到各自林分类型的R2、RMSE、MAE和P性能指标,如表4。从表4 可知,CatBoost 模型的效果最佳,RF 模型次之,AdaBoost 模型最后。针对6 类林分类型,CatBoost 的最优特征组合如表5 所示。
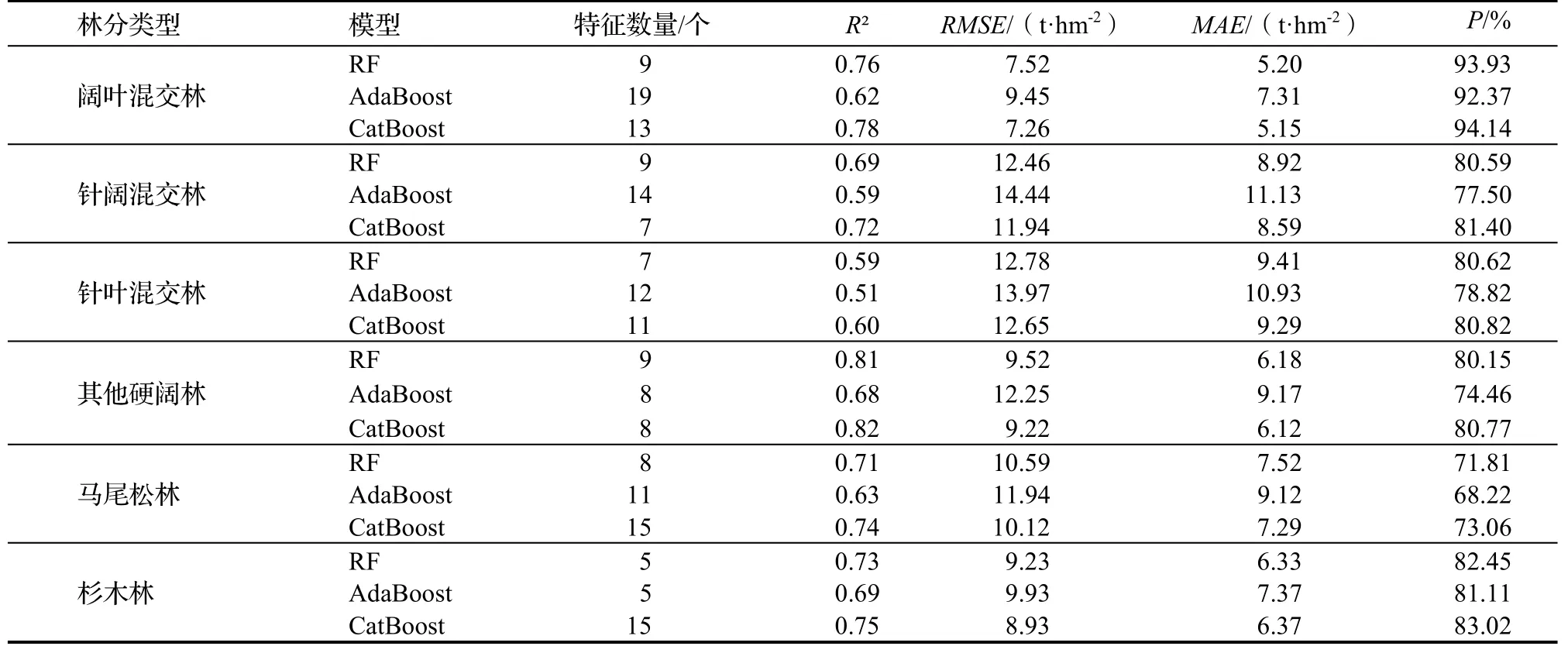
表4 RF、AdaBoost 和CatBoost 的建模性能指标Table 4 Modeling indexes for RF,AdaBoost and CatBoost

表5 CatBoost 最佳特征组合Table 5 The best combinations of features for Catboost
为进一步探究递归特征消除法对模型性能的影响,分别使用特征优选后构建的模型与所有特征构建的模型进行性能指标(R2和RMSE)对比,结果如图7。从图7 可知,特征消除后的18 个模型估测效果均得到不同程度的改善。递归特征消除法从整体上删减了冗余特征,降低了特征之间的共线性,减少了过拟合,进而使基于降维后特征构建的生物量估测模型的泛化能力更强,估测精度更高。
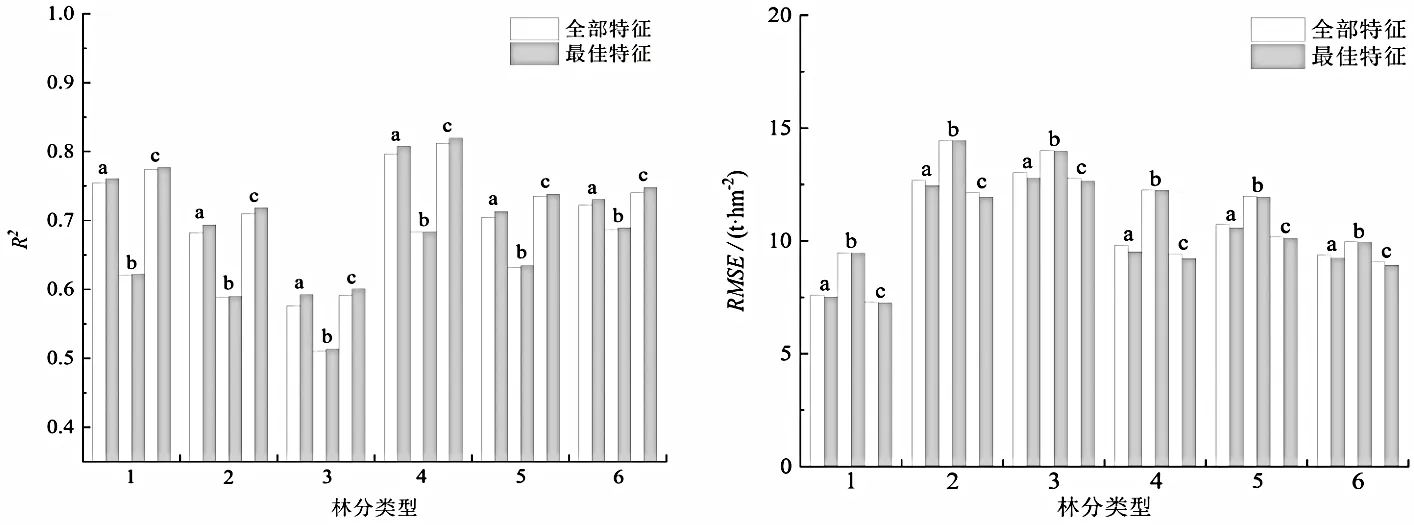
图7 基于全部特征和最佳特征的估测结果的性能指标对比Figure 7 Comparison on performance indexes of estimation based on all features or the best features
3.4 AGB 估测结果分析
使用样本数据的30%作为测试集估测6 种林分的AGB,与基于森林资源二类调查的蓄积量根据公式(1)计算得到AGB 值作为实测值进行对比,6 种林分的生物量情况如表6。
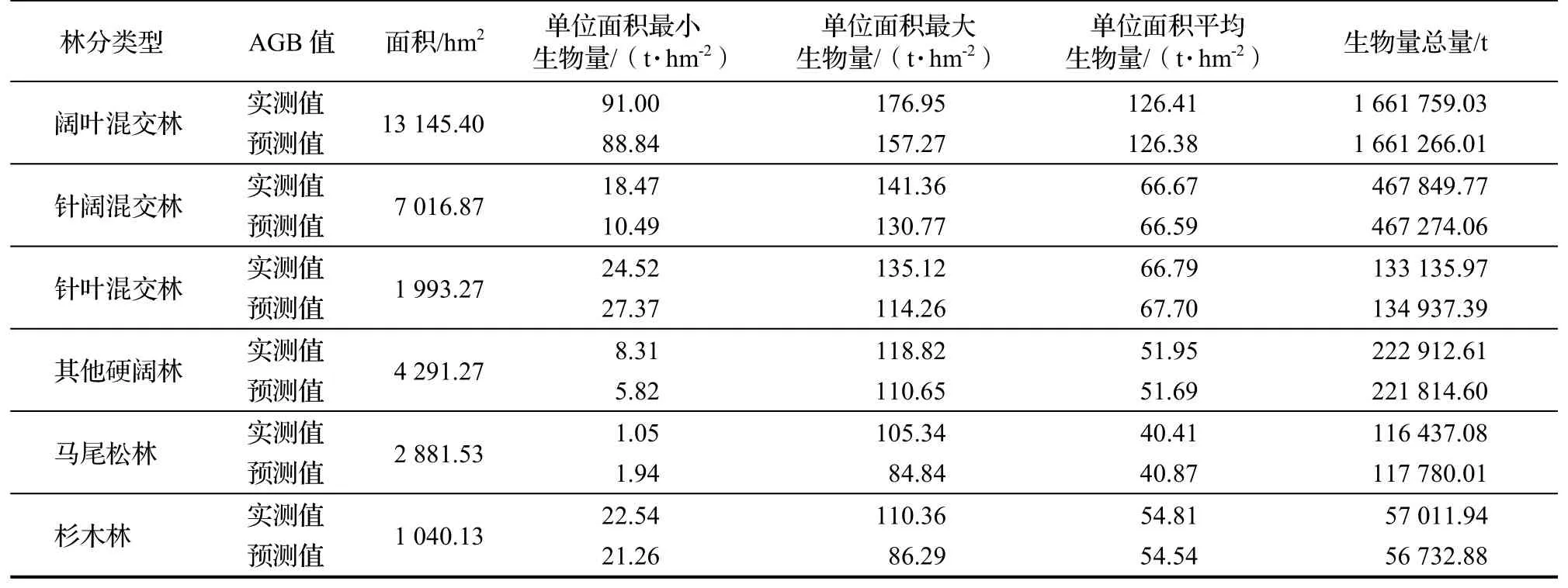
表6 测试集中6 林分森林地上生物量的分布情况Table 6 AGB of estimation and measured of different forest types
从表6 可知,6 种林分的单位面积最小生物量和单位面积最大生物量的估测值与实测值相差较大,但单位面积生物量平均估测值与平均实测值则非常接近,说明以单个小班而言估测结果可能存在一定的误差,但从区域角度而言,估测结果的误差较小,具有非常重要的参考价值。
4 讨论
经递归特征消除法处理后的最佳特征组合中,纹理特征对提高估测精度有较大贡献,特别是13/135/Correlation、13/135/Variance。窗口大小、角度、步长等参数的选择对纹理特征的提取有一定的影响,从而影响模型精度,若今后的研究中再加入灰度差分向量(SADH)和差直方图(GLDV)下更多窗口和角度的纹理因子,则存在进一步提升估测精度的可能性。
CatBoost 在建模和估测时,能够自动处理类别特征,使得数据处理更加便捷化和优化,从而大幅降低模型的时间复杂度并得到最佳的估测效果。但在做递归特征消除时的训练速度相比另外两个算法较慢,原因可能是面对多维度的连续性特征,CatBoost 算法需将特征进行分箱,以减小内存的使用,但也增加了训练时间。AGB估测常涉及到连续性的特征(如海拔),如何进一步调优CatBoost 参数以适应处理连续性特征,值得深入探究。
递归特征消除法通过逐次移除重要性最低的某个特征,能够选择出最适合基学习器(如RF、AdaBoost 和CatBoost)的特征组合。AGB 估测中的特征选择方法通常直接使用机器学习模型,如随机森林、多元线性回归等,通过特征重要性排序进行筛选,但是没有考虑自变量个数递减的过程中特征重要性发生变化的问题。另外,常用的还有皮尔逊相关系数(Pearson Correlation)法,该系数是一个用来反映两个变量之间相似程度的统计量,在机器学习中可以用来计算特征与类别间的线性相关程度,但不太适合用于多变量组合时的特征优选。
当前,森林地上生物量的研究大多只是针对少量的森林资源固定样地或自设的调查样地[2-3,17]而开展,或者是只针对某一特定树种类型进行研究[14-15,18,20]。在对特征选择的方法上,常用皮尔逊相关系数法或者估测方法本身对特征变量进行筛选[11-15]。本研究使用递归特征消除法,探究不同优势树种林分下估测AGB 的最优特征数量及组合,并比较了三种机器学习算法,能够为中、大尺度森林AGB 估测提供一定的参考作用。
5 结论
本文针对森林地上生物量估测研究中多源数据集成下导致特征维度过高、特征选择方法与机器学习方法相结合的研究还较少,在中、大尺度区域估测精度不高等问题展开研究。以临海市作为研究区域,整合Sentinel-1、Sentinel-2 遥感影像数据、DEM 数据、森林资源二类调查数据,使用RF、AdaBoost 和CatBoost 三种机器学习算法分别对阔叶混交林、针阔混交林、针叶混交林、其他硬阔林、马尾松林、杉木林6 种林分建立模型并估测其森林AGB,取得了较好的研究效果。具体结论如下:
(1)从特征组合来看,集成光学遥感、雷达遥感、地形因子及森林资源二类调查数据能够更全面地利用多源数据的信息,有效提高森林AGB 的估测精度;
(2)递归特征消除法降低了模型的复杂度,消除了自变量之间的共线性,能在保持甚至提高模型估测精度的前提下,加快模型训练速度;
(3)从6 种林分的AGB 的估测结果来看,6 种林分的AGB 的主要影响因素与个数不尽相同,这也缘于不同树种有不同生物学和生态学特点,其中有3 个因子是共同的,即年龄、郁闭度和海拔;
(4)基于RFE 的CatBoost 的方法模型可以较好地完成中、大尺度下的森林地上生物量估测,既具备较快的估测速度,又具有较高的估测精度。该方法对各林分AGB 的建模精度为:阔叶混交林94.14%、针阔混交林81.40%、针叶混交林80.82%、其他硬阔类林80.77%、马尾松林73.06%、杉木林83.02%。总体平均估测精度超过80%,高于当前大部分的森林AGB 估测结果。CatBoost 模型效果优于RF 和AdaBoost 模型效果。
