基于云计算图书馆读者兴趣分析与导向系统
2022-09-07岳永斗张婷婷
岳永斗,张婷婷
(无锡商业职业技术学院 江苏 无锡 214153)
0 引言
随着科技的发展,世界范围内产生的数据已由原来的TB级达到PB级,用过去的数据处理技术已经很难适应社会需求。云计算、神经网络等新兴技术发展迅速。在这样的时代背景下,云计算技术以其高灵活性、可扩展性和高性价比等优点,成为当下计算机领域的研究热门。另一方面,于学生群体而言,图书馆是必不可少的知识获取途径。若能将云计算技术与数字图书馆相结合,针对不同用户实现图书的个性化推荐,那么对用户而言将是更加良好的体验,对科教兴国的战略目标也有一定促进作用。本文在本地环境进行模拟实验,将云计算技术与图书馆数据相结合,对读者的文献评分的历史数据进行挖掘,构建文献推荐模型框架,并将文献推荐模型框架生成的图书推荐列表进行转化,最终为采编部生成采购清单。具体做法大致如下:先用Python对原始数据进行清洗,将清洗后的结果上传至虚拟化平台上,使用Hive(数据仓库工具)和Spark对数据进行分析,挖掘数据特征,构建算法模型,用机器学习算法对模型进行训练,最终实现书籍的个性化推荐[1]。
1 相关技术概述
1.1 云计算
云计算是近年来发展起来的一项技术,也叫网格计算,是一种分布式计算。云计算提供3种服务,分别是基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。基础设施即服务是指向用户提供虚拟化的各种资源。前面提到过云是由各种复杂的网络和存储资源通过虚拟化连成的整体,基础设施即服务就是将其中的一部分按需提供给用户。平台即服务是更高一层的服务,除了提供用户所需的基础设施外还提供一些项目开发的环境。软件即服务相比平台即服务是更高一层的服务,不仅提供前两者的资源,还额外加上具体的应用程序。
1.2 Spark
Spark是Hadoop生态环境中的一个组件,同时也是一个相对独立的、基于内存的计算框架。Spark最初设计出来的目的是加快计算效率、简化编程难度,随着时间推移,Spark渐渐地形成一个与Hadoop类似的、独立的生态环境。Spark可以使用存储在Hadoop的所有数据,包括HDFS和HBase中的。且Spark相比Hadoop有更多的优点,比如计算效率。以Logistics算法为例,Spark的计算时间比Hadoop少了数百倍。因为Spark可以将数据载入到内存,而无需像Hadoop般频繁读取,极大地节省了读写数据的时间消耗。Spark的灵活性也是Hadoop无法比拟的。Spark的计算模式是基于MapReduce的,但是Spark还有20余种更灵活的计算方法,且Spark支持更多的功能,例如交互式查询、流式计算,基于GraphX的图计算算法和基于MLlib的机器学习算法。Spark对不同语言的兼容性也很高,Spark本身是使用简洁的Scala语言开发的,但提供了Python、Java、R等语言的接口[2]。
1.3 ALS算法
交替最小二乘法(alternating least squares,ALS),是一种非常经典的拟合算法,通常用于优化和预测,其数学基础是最小二乘法。ALS是协同过滤算法的一种,是在基于用户的协同过滤算法(UserCF)和基于物品的协同过滤算法的基础上进行改进得到的结果,即混合协同过滤算法。ALS算法对数据源的输入,要求是一个三元组,即
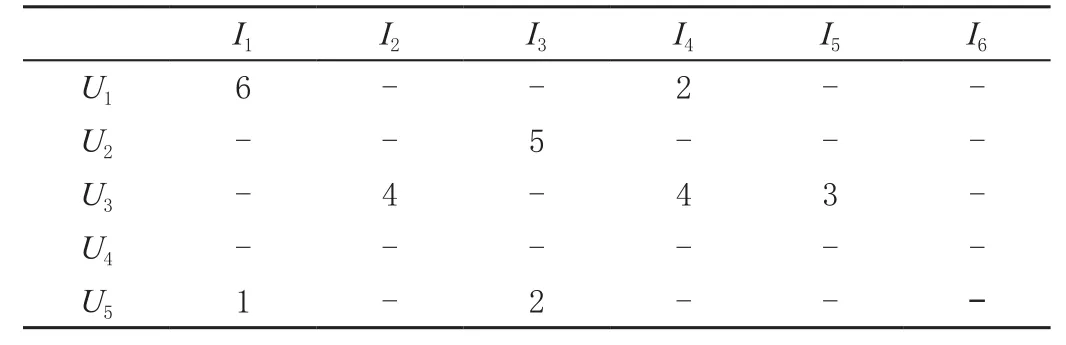
表1 用户-物品矩阵
然而在实际问题当中,有很多个用户和很多的物品,用户只会选择物品当中的其中一小部分进行评分,甚至有的不活跃用户都没有评分记录,这就导致了矩阵当中只有少数部分有相应的评分,而大部分是空的、缺失的。
由于通常这个矩阵规模非常庞大,为了后续的运算,我们需要对其进行降维处理。例如一个m×n的矩阵A,可以看作是R(m×k)和S(k×n)T的矩阵之乘积,如下公式。
图1中,矩阵R代表用户与两者之间的一些关联因子(比如性别、年龄、物品信息等)之间的关系,矩阵S代表物品与关联因子之间的关系。关联因子是高度浓缩的,也就是说k一定是远小于m、n的,这样才有降维的意义。这种做法我们称之为“隐语义因子分析”,而交替最小二乘法就采用了该分析方法。ALS的核心,就是找到对应的矩阵R和S,使得他们的乘积无限接近于原矩阵A。在这个过程中,A的缺失部分会得到填补,也就有了相应的预测值。ALS求R和S是一个收敛的过程,因为一开始的R和S是随机生成的,与实际值相差很远,需要一点点地修正、迭代,得到最接近的值。这个过程需要计算预测值与真实值的误差,于是就有了下面的损失函数:
这个式子当中,aij表示的是原始矩阵A中第i用户对第j个物品的评分,ri是矩阵R的第i行的元素,sjT表示矩阵S的第j列的元素,二者的乘积是第i个用户对第j个物品的预测值。我们要做的就是尽可能地降低L(R,S)的值,这样预测值才能尽可能地接近真实值。由于公式中的R、S都是变量,为了求解L(R,S)的极小值,ALS算法的做法就是先确定其中一个变量,对另一个变量进行调整直到L(R,S)取值最小,然后确定调整后的变量,对原先确定的变量进行调整。重复此步骤直到均方根误差小于预设值,则结束该算法。计算过程大致如下:
(1)确定矩阵S,计算ri的偏导数,令其为0,可得
从而求解。
(2)确定矩阵R,计算sj的偏导数,令其为0,可得
近年来,中国境内勘察设计企业、咨询服务企业紧随国家战略方针,积极投入境外工程项目。但随着境外项目的开展,设计咨询类企业面临着多种多样的市场竞争及外来挑战,如何采用更先进的管理理念来降低成本,协调中国企业境内外项目运转过程中的矛盾,成为设计咨询企业走出去的关键。本文结合设计咨询企业的行业情况、成本核销管理中的现状以及境外项目成本管理特点,探讨设计咨询企业境外项目科学成本管理中的方式与方法,希望为以后的工作起到实际的参考作用。
从而求解si。
(3)重复上述步骤直到均方根误差小于预设值。
这个过程是需要轮流确定矩阵R和矩阵S的,然后使用最小二乘法计算损失函数,这就是交替最小二乘法的名字来源。
2 实验验证与结果分析
2.1 数据集来源及介绍
由于图书馆数据涉及用户隐私问题不好爬取,本文将使用Book-Crossing读书社区的数据作为替代品。数据集来源网站http://www2.informatik.uni-freiburg.de/~cziegler/BX/,数据是由一个外国网友花费4周时间爬取的,共3个表。表BX-Users.csv包含用户信息,共278,858条,共有3列属性,分别是用户ID、用户位置和用户年龄。表BX-Books.csv共271,379条数据,包含图书的ISBN标识、图书的名称、作者(第一作者)、出版年和发布者,后面链接到封面图片的URL,存放在3个不同的列(图片-URL-S、图片-URL-M、图片-URL-L),即小、中、大。这些URL指向Amazon网站。表BX-Book-Ratings包含用户ID、图书ISBN号和评分信息,共1,149,780条数据[3]。
2.2 数据预处理并上传至HDFS
接下来使用Python对数据集进行数据清洗。首先使用pandas模块读入数据表,数据存储格式为DataFrame,然后使用匿名函数统计每个表每一列的缺失值,操作相应的DataFrame,删除不合法图书数据的评分记录、评分为空值的评分记录,最后将结果保存到指定目录下,使用分号作为分隔符。
将数据表上传至/home/Hadoop/ubtshare/BX-new目录下,并去表头,最后使用dfs -put命令上传至集群。
2.3 Spark分析
2.3.1 在idea中编写独立运行程序
下载、安装IDEA,新建项目Book_Recomend_System,配置pom.xml,添加相关依赖,新建scala类ReadFromHive.scala,尝试读取Hive中的表,设置SDK。为读取到Hive中的数据库,还需要将hive-site.xml复制到resource目录下。为存储结果,先在MySQL中新建表bxrecommendresult、user和personalratings,即推荐结果表、用户表和个人评分表。
为了程序顺利运行,向个人评分表插入少许评分记录,见图2。
然后开始编写推荐算法。
(1)ReadFromHive.scala主要负责从Hive中读取数据集。目前共有4个方法。
①read():负责从bx_book_ratings_small读入所有数据,并与表bx_books_small内连接,得到数据标签列index。返回类型为DataFrame。
②readPersonal(userid:Int):负责从MySQL中的personalratings表筛选出指定用户的评分记录,并与表bx_books_small内连接得到数据标签列index。返回类型为DataFrame。
③change(ratings: DataFrame):负责将从bx_book_ratings_small中读到的记录进行格式转换,每一条评分记录转换为一个String类型的值,不同项之间用“::”分隔。返回类型为Array[String]。
④readBookTable():负责从bx_books_small读取字段index、title,对读取结果格式转换,每一条记录转换为“::”分隔的字符串。返回类型为Array[String]。
(2)DeleteFromMysql.scala主要负责从MySQL中删除先前的推荐结果,有1个方法。
delete(userid:Int)
连接MySQL中的bxrecommendresult表,删除其中指定用户的推荐结果。
(3)BookAls_new.scala主要负责构建推荐模型,对数据进行预测分析。有1个自定义类和3个方法。
①自定义类Rating:有3个属性,userid:Int型,对应用户ID;book_rating:Double型,对应用户评分;index:Int型,书籍标签列,与ISBN对应。
②loadRatings(lines: Array[String]):负责用户评分数据格式转换,初步过滤掉非法评分数据。返回类型为Seq[Rating]。
③computeRmse(model: ALSModel, df: DataFrame, n:Long):负责计算校验集预测数据和实际数据之间的均方根误差。返回类型为Double。
④main(args: Array[String]):程序的主体和入口。实现了从数据库读取数据、划分数据集、构建并循环训练模型、为指定用户个性化推荐书籍的整个流程。
(4)InsertToMysql.scala主要负责推荐结果的保存,有1个方法。
insert(array:Array[String])
负责将接收到的字符串按“::”分隔,将分隔后的字串重塑成DataFrame格式,指定字段名称,最后连接MySQL并写入bxrecommendresult表。
运行结果见图3。
2.3.2 在集群中运行
在Project Structure点击Artifacts,添加要打包的项目,删除多余条目。点击OK后,在菜单栏找到Build,点击Build Artifacts,选择Build操作,就可以得到项目的jar包。运行结果见图4。
3 结语
本文首先提出课题的研究背景与意义,表明选取该课题的目的及动机;而后简要介绍本文的主要工作,主要包括相关计算概述,涵盖云计算、Hadoop、Spark、RDD、DataFrame和ALS算法。最后是实验验证及结果,在此展示了理论基础,将其在实践中加以运用。
本次研究存在的问题还有许多,最直观的问题为可视化界面过于朴素。另一方面,数据挖掘的深度不足,目前只是实现了数据清洗和推荐模型的构建,更深层次的信息没有得到发掘;推荐系统所用的算法仅停留在经典的ALS上,缺乏算法上的改进和多样化比较,代码运行时间过长,同时运行效率低。
