考虑负载平衡的海量数据信息优化存储方法
2022-09-07姜静思
姜静思
(武汉交通职业学院 湖北 武汉 430080)
0 引言
作为一种以互联网为基础的新型计算方式,云计算最突出的特点就是其可以按照用户的实际需求个性化地提供相应的资源[1]。这不仅为人们的生活和工作带来了极大的便利,同时也衍生出了更加人性化的服务模式[2]。但是值得注意的是,在这一背景下,网络数据信息的规模开始呈现出爆发式增长的趋势,对相关存储技术也提出了更高的要求[3]。现阶段,大多数存储都是建立在分布式网络节点集群的基础之上的,因此确保各节点负载均衡[4],实现对有限资源的有效管理成了数据存储进一步研究的主要方向[5]。从宏观角度分析,海量的数据信息规模也促使负载均衡策略成为数据存储发展的必经之路[6]。
为此,本文提出考虑负载平衡的海量数据信息优化存储方法,并通过试验测试的方式分析了设计存储方法在资源利用合理性以及存储负载均衡性方面的价值。通过本文的研究,以期为数据信息存储相关研究提供有价值的参考。
1 海量数据信息优化存储方法设计
1.1 存储链路关键度分析
数据存储是将待存储的数据经过某一传输链路上各个节点的传递,将其发送至目标节点,这就意味着对应存储链路的关键度越高[7],其可执行传输任务的总量越多[8]。为此,本文首先对存储链路的关键度进行分析。首先,本文设置了一个无向连通参数G,利用其表示网络存储链路的关键度,则公式如下:
其中,V表示由存储网络中所有节点构成的集合,E表示由所有节点构成存储链路的集合。需要注意的是,存储环境中的每个节点都具有唯一的标识参数。
在此基础上,在考虑负载平衡的前提下,对存储的优化可以理解为是将存储任务分配到具有最大负载空间的链路上[9]。对各个链路对应的传输效率进行分析,本文引入了平均期望负载参数,利用其反馈链路期望的最大传输流量,该值越高,则表明其传输效率越高,对应被选择的概率也越高。具体的计算方式可以表示如下:
其中,AVE(l)表示存储链路1的平均期望负载值,f(i,j)表示连通节点i和节点j的任意链路可负载的流量,n表示节点i和节点j之间链路数量。
需要注意的是,受实际运行情况的影响,存储链路当前执行传输任务情况将直接影响其负载容量,因此,在对其实际负载情况进行分析时,需要充分考虑链路的当前负载,对应可执行传输流量可以表示为
其中,P(l)表示l链路的实际可执行传输流量负载,p(l)表示l链路当前执行传输流量负载。
以此为基础,本文将P(l)作为关键度分析的基础参数,P(l)值越高,则表明对应链路的关键度越高,相反地,P(l)值越低,则表明对应链路的关键度越低。
1.2 考虑负载均衡的数据信息优化存储
在确定存储链路关键度的基础上,本文采用蚁群算法实现对存储的优化。其具体的执行方案见图1。
按照图1所示的方式,在获取到各个传输链路的流量信息后,根据其当前执行传输流量负载情况,计算存储网络中链路的带宽利用情况。当带宽利用率较高时,表明该链路的负载也较大,此时利用蚁群算法,将带宽利用率作为寻优参数。在蚁群算法具体的实施过程中,本文将存储链路关键度作为蚁群寻优的距离,此时只需要计算出源节点到目的节点之间最短的路径,得到的链路即为负载最小的传输路径,将其作为数据存储的链路,确保网络负载均衡。为此,蚁群算法的具体步骤如下。
(1)对参数进行初始处理。
(2)蚂蚁k(1,2,...,m) 根据链路上的信息素浓度,确定其选择概率。其中,信息素浓度的计算方式可以表示为
其中,ρ表示信息素浓度,也就是链路的带宽空闲率,λ表示链路节点的访问热度,Q表示链路的额定传输带宽,a表示信息素对蚂蚁的影响因子大小,cost(i,j)表示完成节点i和节点j之间数据传输所需的开销。
通过式(1)可以看出,存储路径上信息素的存量与链路节点的访问热度直接相关。因此,在信息素浓度相同的条件下,蚂蚁对信息素依赖程度会出现异常。
为此,本文在蚁群算法中引入了启发因子,利用其反映路径上存在的信息素对蚂蚁选择路径时的相对重要性,其计算方式可以表示为
其中,h表示启发因子,也就是节点i与节点j之间链路上信息素浓度对蚂蚁的影响程度,c表示蚂蚁对信息素依赖程度,L表示链路的长度,e表示对节点i与节点j之间链路喜好的程度次数,s表示节点i与节点j之间链路的拟合系数。
(3)在此基础上,蚂蚁根据链路上的信息素浓度完成对传输链路的选择,直至存在ρ=ρmax,且h=bmax时,将对应的链路做出最终选择,使得完成存储的负载合理地分配到各个节点上,保证网络的负载平衡。
(4)需要特别注意的是,由于存储请求往往存在并发情况,可能会导致节点关键度信息在寻优过程中出现更新。因此本文在完成对目标链路的选择后,制定了校验机制,将当前时刻的存储链路关键度参数与计算过程使用的存储链路关键度参数进行比较。当二者相同时,则表明并发请求并未影响链路的关键度,可继续执行蚁群算法的计算结果;当二者不同时,则表明并发请求对链路的关键度造成了影响,需要更新蚁群算法的参数信息,进行新一轮的寻优计算。由此确保存储可以实现负载平衡。
2 实验测试
2.1 物理节点设置
在本文构建的测试环境中,共使用了6台物理机进行测试优化信息存储方法。对具体的设置情况进行布设时,将其中两台物理机作为搭建NFS服务的核心,其具体的作用是为存储虚拟机提供配置信息(内存、CPU、硬盘等)。将另外4台物理机作为部署XenServer环境的核心。在此基础上,本文将所有XenServer 部署在同一个数据池中,通过这样的方式使得所有物理机能够共享相同的计算资源。不仅如此,在这样的环境下,所有虚拟机也可以借助数据池的同源属性,将任意一个物理机作为动态部署目标,此时物理机之间可以顺利地执行虚拟机的迁移。具体的物理架构图见图2。
按照图2所示的方式,完成对测试环境物理节点的设置。
2.2 虚拟节点设置
在上述物理节点的基础上,本文对测试环境中虚拟节点的设置是建立在XenServer服务基础之上,并为其构建了动态机制。上文中已经提到,本文设置的物理机存在于同一数据池中,因此XenServer即使部署在特定物理机上,虚拟机也不会对特定的物理机产生依赖。在此基础上,通过预先在虚拟节点上安装Ubuntu Server以及对应Mongo DB存储构架,使得虚拟机具备存储功能。在对Mongo DB的节点进行具体划分时,按照存储节点和非存储节点,设置了以辅助功能为基础的配置节点和路由节点,对应的数量均为1个,存储节点的数量为12个。在此基础上,为每个虚拟节点配置了大小为5G的运行空间和大小为20G的存储空间。
2.3 测试方法
在上述基础上,本文设计测试方法是通过调节存储请求并发量,测试物理节点和虚拟节点的利用率。其中,前100 s存储请求并发量由0匀速增长到100,100~150 s时间段内,并发数稳定在100状态,并在结束时将并发请求数量降低至0。
利用黄永生[4]和闫娟雅[5]提出的方法同时进行存储测试,对比3种方法的测试结果。其中,对于每个物理节点上资源的使用率,本文是通过采集其实时CPU、内存、带宽的使用量与对应资源的实际总量进行计算的。对于虚拟节点上资源的使用率,本文同样采用上述方法计算得出。
2.4 测试结果
对比3种存储方法下,物理节点和虚拟机节点的负载情况,分别见表1和表2。
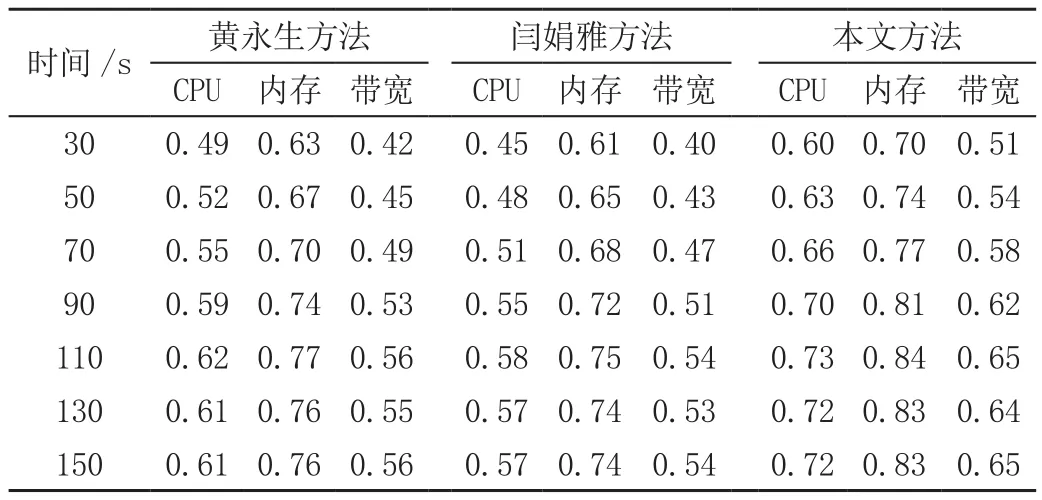
表1 不同方法下物理节点利用率对比表
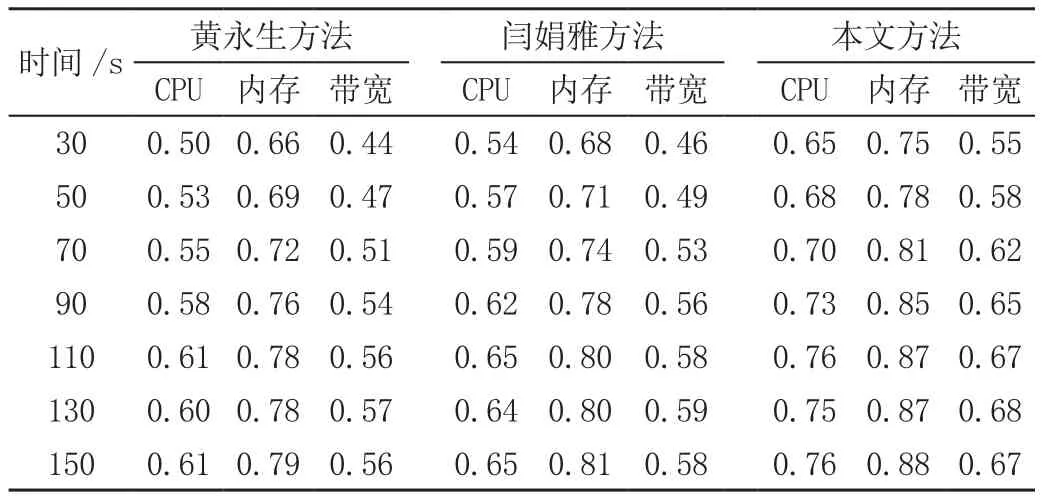
表2 不同方法下虚拟节点利用率对比表
从表1和表2中可以看出,对比3种数据存储方法,虽然整体上物理节点和虚拟节点的利用率均呈现出随着存储请求并发量的增加逐渐上升的趋势,但是具体的利用率存在明显差异。其中,黄永生方法和闫娟雅方法物理节点对CPU、内存以及带宽的利用率明显低于本文方法,且虚拟节点利用率与物理节点利用率之间的变化关系并不一致;闫娟雅方法中,虚拟节点利用率的提升幅度明显大于物理节点利用率的提升幅度,黄永生方法中,虚拟节点利用率的提升幅度明显小于物理节点利用率的提升幅度。而相比之下,本文存储方法下的物理节点和虚拟节点的利用率均明显高于对比方法,且二者的发展是存在一定协调关系的。这表明本文提出方法可以保障对存储过程的负载平衡。
为了进一步验证分析结果,对平均访问时间进行对比,其结果见图3。
从图3中可以看出,对比3种方法,黄永生方法和闫娟雅方法的平均访问时间随着并发存储请求规模的增加,上升趋势更加明显,当并发存储请求数量达到100时,其访问时间分别达到了35.8 ms和33.6 ms。相比之下,本文方法下的访问时间发展趋势受并发存储请求规模的影响较小,当并发存储请求数量达到100时,其访问时间仅为22.5 ms。这是因为本文提出方法实现了对存储负载的均衡管理,避免了由于单一负载异常引起的访问延时,大大提高了对请求的处理效率。
3 结语
在云存储需求不断提高的时代背景下,提高存储性能和对有限资源的利用率主要取决于分布式集群各节点负载的均衡情况。本文提出考虑负载平衡的海量数据信息优化存储方法,实现了对物理机以及虚拟机资源的有效利用,大大缩短了存储访问时间。通过本文的研究,希望可以为信息时代下数据存储工作的开展提供有价值的参考。
