基于卷积神经网络的信息融合技术应用研究
2022-09-07张君君
张君君
(郑州工业应用技术学院 河南 郑州 451100)
0 引言
信息融合是针对同一事物的多源特征数据进行综合分析,消除信息之间分误差,获得对感知对象更全面客观的理解。近年来,随着通信技术、人工智能等技术的飞速发展,信息融合技术在国防军事[1]、医疗成像[2]、环境监测[3]和工业制造[4]等多个领域应用广泛。随着人们对信息的需求在逐渐增加,极大地推动了信息融合技术的研究。信息融合技术包含的分支很多,其中图像融合是其中应用最广泛的分支之一。
随着社会的发展和科学技术的进步,人类生活中每天都产生海量的信息数据,图像具有直观、易理解、信息量大的特点,在接收、处理和传输信息的过程中都扮演着重要的角色,在国防建设和国民经济发展中发挥着不可替代的作用。目前,数字传感器和快速成像技术的进步使得图像获取更加便捷高效,但由于不同传感器之间的物理特性存在差异,因此,使用不同传感器对同一目标场景进行特征采集,将会获得不同的信息特征,降低了图像信息的使用效率。为此,国内外诸多学者针对图像信息融合技术开展了大量的研究,如Vishwakarma A等[5]提出基于Karhunen-Loeve变换的多传感器图像融合方法,实验结果表明该方法相比传统方法的PSNR和SSIM值平均分别增加了1%和2.2%,图像融合指标的平均值增加了9.04%;Paramanandham N等[6]利用变换和空间域技术的优点,提出了一种用于多形态图像的混合图像融合算法,在初始图像融合框架中,使用级联小波变换仅对源图像进行一次分解,并根据融合规则对变换后的系数进行合并,使用罗伯茨算子提取边缘信息,并引入决策规则以从聚焦部分中选择边缘,实验结果表明,该算法在视觉感知和定量评估方面均优于常规图像融合技术;Ilyas A等[7]提出了一种多焦点图像融合算法,该算法将具有相似颜色和图案的局部连接成为像素组,使用它们来分离图像的聚焦区域和散焦区域,实验结果表明,与现有的图像融合技术相比,该方法可产生更高质量的融合图像。胡雪凯等[8]提出了一种基于自适应加权的多尺度图像融合算法,通过对融合图像的主观和客观评价分析,这种新算法能够解决单一图像传感器采集图像时的缺陷,提高了融合图像质量;李明明等[9]利用K-means聚类和NSCT技术应用到图像融合研究中,实验结果表明,该算法可以较大程度地保留图像纹理信息和提升图像的对比度;张宽等[10]研究了基于鲁棒性主成分分析与脉冲耦合神经网络的图像融合方法,相比于基于主成分分析与二代小波变换的图像融合算法,该算法能够更好地提取目标信息和突出细节信息。
近年来,深度学习的理论和技术迅速发展,作为深度学习典型算法之一的卷积神经网络(convolution neural networks,CNN)具有特征提取能力强、人为干扰因素少、图像识别精度高等优势,在图像处理领域取得了显著的成果[11-14]。基于上述分析,本文基于卷积神经网络区域图像融合方法进行图像融合处理,更加精确高效地提取图像特征信息,提高图像数据的融合质量,以期为卷积神经网络算法在图像数据融合研究工作中提供科学参考,对图像融合理论研究及应用具有重要的现实意义。
1 研究原理与方法
1.1 卷积神经网络原理
卷积神经网络(CNN)是一种典型的深度学习网络模型,是一类特殊的人工神经网络(ANN),使用网格状结构表示和处理图像数据。一般来说,一个简单的CNN架构中有4层,分别是卷积层(Conv)、激活函数(ReLU)、池化层(Subsampling)和全连接层(FC)。模型结构见图1。
在CNN模型中,每个卷积层将输入图像数据转换成特征信息,下一个卷积层通过一组过滤器的卷积运算将特征映射转换为另一个特征映射,进一步获得新的特征图像。在进行卷积运算之后,采用激活函数常对图像数据进行非线性操作,激活函数表示为:
式中:kij表示卷积核,bj表示残差。
池化层通常用来优化参数量、减少训练时间以及防治过拟合的情况,通过池化能够提取更多的特征信息;全连接层是CNN模型的最后一部分,一般是一个卷积层形式,核大小为1×1。
1.2 区域图像融合方法
将有焦点的区域和无焦点的区域同时输入到CNN模型网络中,无焦点的区域边缘比聚焦的区域对应的边缘更平滑,水平方向和垂直方向的梯度图像Gx和Gy含有检测聚焦区域的重要信息。通过集成学习使用CNN网络模型,并利用构建的数据集将它们提供给新建的体系结构,将提高聚焦区域检测的准确性,从而增强初始决策图。区域图像融合方法的思路如下:有两个图像a和b;图像a的一部分是有焦点的,而图像b的一部分是无焦点的。在进行图像融合处理之前,假设输入图像通过图像配准方法进行对齐,对于输入的多焦点图像,如果是彩色图像,则需要将其转换为灰度图像来构建决策图;构建决策图后,对彩色多焦点图像进行融合。在输入的多焦点图像中提取小块区域进行重叠处理,作为初始训练CNN网络模型的数据集,然后,初始训练的网络模型返回有焦点的标签(表示为0)和无焦点的标签(表示为1)。在这个过程中,每个像素在进行有焦点和无焦点的运算过程中需要重复使用。区域图像融合方法表达式如下所示。
式中:r、c、M分别表示输入图像的行、列和决策图;b是从输入的多焦点图像中提取的用于构建宏观区域的图像宽度和高度的大小,对于小图像和大图像,b的值可以分别设置为16和32。
2 实验分析与讨论
2.1 实验环境与数据
本节讨论了基于CNN模型图像融合方法的性能,该算法在Ubuntu Linux 16.04.7 LTS操作系统上使用PyTorch(0.4.0)进行编码和训练;主机电脑硬件环境是CPU为Corei7-1165G7 CPU @ 4.70 GHz,RAM为32 GB。
原始图像数据从Lytro系列图像数据集中选取的彩色图像,见图2。
2.2 实验结果与分析
为了验证本文采用的CNN模型图像融合算法的有效性,在进行图像融合时分别采用了基于NSST算法[14]、MWGF算法[15]对原始图像数据进行融合,与文中CNN模型算法图像融合结果进行对比分析。为了客观合理地评价各种算法的性能,选取了平均梯度(AG)、空间频率(SF)、互信息(MI)、边缘信息传递因子(QAB/F)和视觉保真度(VIFF)5个评价指标对融合后的图像质量进行评估。各种算法的图像融合结果见图3,图3(a)为CNN算法融合图,图3(b)为NSST算法融合图,图3(c)为MWGF算法融合图。
基于3种算法融合得到的结果图,分别统计AG、SF、MI、QAB/F和VIFF这5个评价指标值,结果见表1。
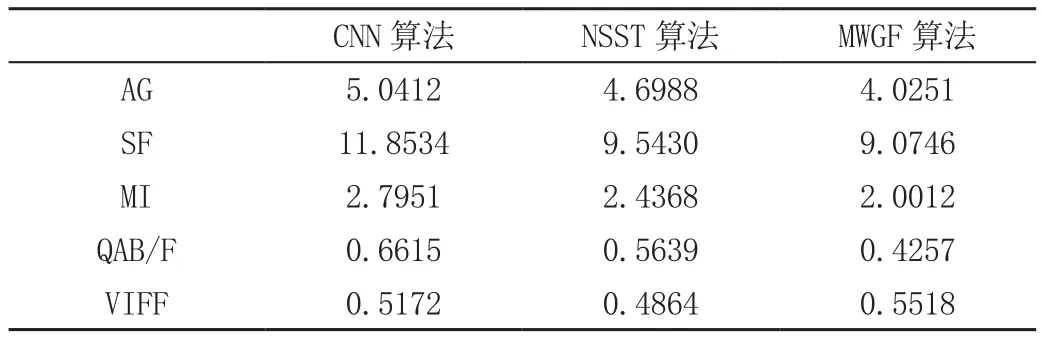
表1 3种算法图像融合结果性能评价表
从表1的融合结果评价指标可以看出,CNN算法的VIFF指标略低于MWGF算法,但其余的AG、SF、MI和QAB/F指标均明显优于NSST算法和MWGF算法;通过人眼视觉评价发现基于文中使用的CNN算法输出的融合图像更符合视觉效果。综上可知,CNN算法在图像融合应用中图像视觉保真能力略弱于MWGF算法,但在活跃度、清晰度、边缘信息等方面的能力优于两种对比算法,图像融合的效果和精度更优。
总体而言,选择对比的两种算法是近年来在聚焦图像融合方法中比较新颖的算法。然而,与源图像的聚焦区域相比,这些方法的初始分割决策图的精度比较低。通过可视化观察发现本文实验的CNN图像融合方法在没有任何后处理算法的情况下,其初始分割决策图明显优于其他有或没有后处理算法的方法。
3 结语
本文介绍了一种基于卷积神经网络的多焦点图像融合方法,该方法的主要思想是使用3个CNN的集合,对多焦点的图像数据集进行了简单排列,以获得更高的融合精度。通过视觉评价和客观质量指标评价结果表明,文中使用的CNN算法在图像融合应用中图像视觉保真能力略弱于MWGF算法,但在活跃度、清晰度、边缘信息等方面的能力优于两种对比算法,图像融合的效果和精度具有优越性。
