基于心电图的心肌梗死识别分类研究
2022-09-07王新峰漆梦玲徐洪智
王新峰,漆梦玲,徐洪智
1.吉首大学软件学院,湖南吉首 416000;2.中山大学计算机学院,广东广州 510275;3.中山大学孙逸仙纪念医院医学研究中心,广东广州 510120
前言
心肌梗死(Myocardial Infarction, MI)通常称为心脏病发作,是一种急性且严重的心脏状态。世界卫生组织2019年报告显示,心血管疾病(CVD)是全球第一大死亡原因,而CVD 死亡中有85%为MI[1],中国MI 死亡率总体呈上升趋势。急性MI 具有高发病率、高致残率、高病死率等特点,其医疗非常讲求时效[2],错过黄金4 h救治时间,将会造成不可逆的损害(心肌组织死亡),严重会导致死亡。因此,做到早期识别和诊断MI,将极大提高人民的生活质量。
心电图(Electrocardiogram, ECG)是一种用于记录一段时间内心脏生理活动的非侵入性诊断工具[3]。它是最常用的识别和诊断CVD 的工具。近年来,ECG 已被广泛用于各种任务中,如疾病检测[4]、特定波的定位和注释[5]、身份识别[6-7]和死亡预测[8]。ECG研究可分为两类:(1)基于人工提取的心电临床特征。例如,体表ECG QRS-T夹角对急性前壁MI的临床诊断具有积极意义[9],心跳波中的PR、QRS和QT 3个区间是非动脉粥样硬化性CVD 的重要危险因素[10]。4 种ECG 标志物Q 波、左心室肥厚(LVH)、QRS 持续时间和JTc 的组合显着改善了CVD 患者的猝死和心律失常风险分层[11]。这类方法的优点是临床可解释性强,缺点是提取过程繁琐,可能会遗漏一些有价值的信息。(2)基于原始ECG 信号。近年来,ECG 自动判读算法取得了重大进展,尤其是深度学习技术的发展[12]。深度神经网络(DNN)在许多领域的复杂非线性关系建模和可扩展性方面表现出优越性,包括疾病分类[13]、蛋白质结构预测[14]和图像识别[15]。特别是,一些基于深度学习的方法在特定子任务中已经达到甚至超过了心脏病专家的表现[16-18]。随着深度学习的快速发展,已有很多学者将深度学习应用于MI 的研究。例如,将CNN 与多头ECG 信号用于MI 的分类[19],使用改进的循环神经网络模型堆叠式的双向LSTM 模型用于ECG 分类比卷积网络更具优势[20]。基于ECG信号的Gabor CNN模型自动检测冠状动脉疾病、MI 和充血性心力衰竭[21]。结合CNN 和长短期记忆(LSTM)模型将ECG 信号分类为冠状动脉疾病、MI 和充血性心力衰竭[22]。与传统的机器学习方法相比,除了较差的可解释性,深度学习模型具有特征提取、自动选择、海量数据处理等优势。因此,它通常是CVD分类的首选。
通过对现有研究的分析发现,目前基于ECG 的研究主要存在以下问题:(1)使用的ECG 数据集样本少,且多为非公开数据集。(2)侧重于挑选特定的波进行分类识别,而不是对完整的ECG 诊断记录进行。(3)分析方法单一。为了克服上面的问题,本研究第一个同时使用基于临床特征的机器学习方法和基于原始ECG 信号的深度学习方法,在英国生物信息平台UK Biobank上进行MI的识别分类研究,并对两种方法进行可解释性探究。
1 实验材料
1.1 数据集
实验数据集来自英国最大的公开生物信息资源平台UK Biobank,该平台包含超过50 万人的基因信息、ECG 和诊断病历信息等[23]。从平台中挑选出12导联ECG 的记录共42 648 条,从病历信息中挑出所有包含MI的记录464条。作为对照组,按1:2比例挑选非MI 的样本共928 条。最终的实验数据集由1 392条ECG记录组成。
1.2 原始ECG信号处理
原始ECG 记录由UK Biobank 成像评估中心的心电图设备生成(Camusb 6.5, Car-DioSoft V6.51, 带有4 个肢体引线和6 个胸部引线)。每个记录是标准的12 导联ECG,时长10 s,采样频率为500 Hz。记录的数据存储在XML 格式中。使用Python 中的XML.Dom 模块从XML文件中提取记录的原始ECG信号,并将其转换为[12, 5 000]的矩阵(12 为导联数量,5 000为10 s*500 Hz)。
1.3 手工提取临床特征
每个原始12 导联ECG 样本信号为矩阵[12,5 000],传统机器学习方法很难处理这么大的数据量。为了方便使用机器学习方法,利用临床的专业知识,从每个导联中提取通用且能被计算到的临床特征,特征提取内容如图1 所示,主要为R 波、S 波、T波及相关信息的不同组合,包括最大值、最小值、平均值、面积和间隔长度等共提出34 个特征。再将12导联的特征平铺为1*408 长的向量。将原始信号转换为数据集其中m为样本1 392,n为特征408。
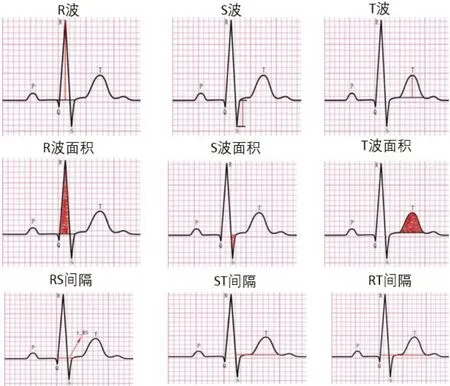
图1 临床特征的意义Figure 1 Significance of clinical features
2 分类方法
为了全面评估ECG 对MI 的识别效率并建立基准,本研究从提取的临床特征和原始ECG 信号两种信息类型入手,使用机器学习和深度学习共10 种方法进行实验。在分类结果之后,做了XGBoost 和ResNet 网络两种方法的可解释性,整体研究流程如图2所示。
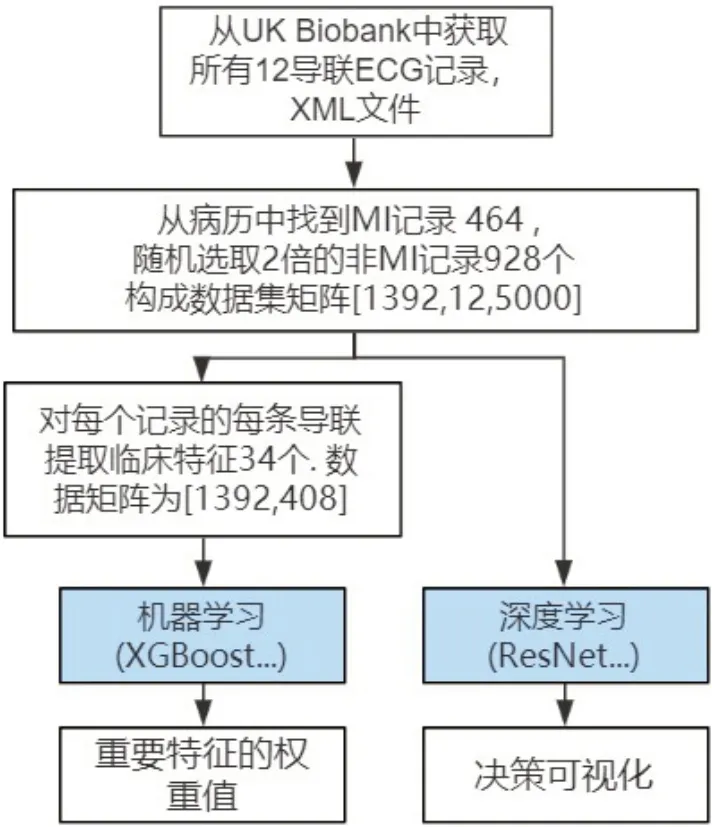
图2 整体研究流程图Figure 2 Overall research flowchart
2.1 基于临床特征的机器学习
决策树模型是常用的基础监督式学习模型,很适合分类任务,它不需要对数据有任何的先验假设,就可以快速地根据数据的特征找到决策规则。极端梯度提升算法(eXtreme Gradient Boosting,XGBoost)是一种广泛使用的决策树的增强集成模型,它在决策树的基础上采用了集成策略,利用梯度提升算法不断减小前面生成的决策树的损失,并产生新树构成模型,确保了最终决策的可靠性[24],其在机器学习领域拥有最先进的性能[25]。因此,基于临床特征建立区分MI和非MI患者的模型,XGBoost是最好的选择。
XGBoost的基模型不仅支持决策树,还支持线性模型。本研究使用树模型,因为该模型的特点是可以量化每个特征的重要性,另一个优点是可并行训练速度快。树模型实现原理是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,就是学习一个新函数,去拟合上次预测的残差。XGBoost的目标函数由两部分组成:第一部分为用来衡量预测分数和真实分数的差距,另一部分则为每棵树的复杂度的和,如下公式所示:
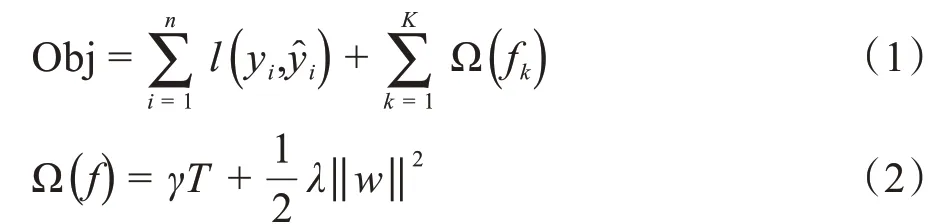
其中,yi为真实值为预测值,在复杂度中,T为叶子结点个数,w表示叶子节点的分数,γ为参数控制叶子结点的个数。XGBoost 方法的实现基于Scikit-Learn Python 库[26],在XGBoost 方法中参数繁多,且不同参数组合对模型最后的结果有一定的影响。为了找到更好的分类结果,通过网格搜索的方式对9个超参数进行搜索并确定最优值,具体如表1所示。
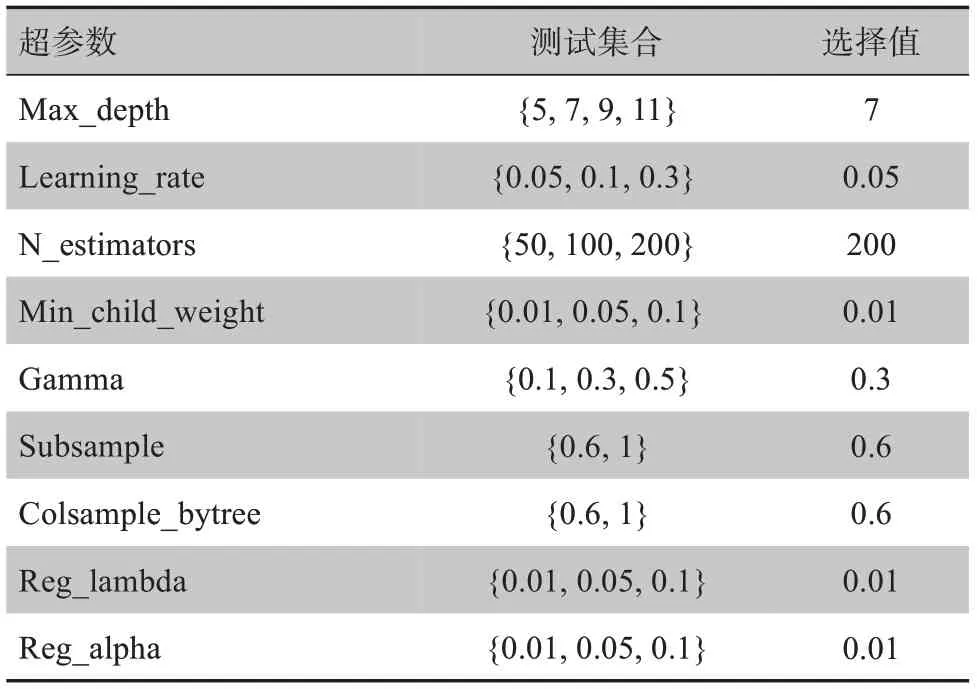
表1 XGBoost中使用的超参数信息以及执行网格搜索的参数范围Table 1 Hyperparameters used in XGBoost and the parameter range for grid search
作为比较,也进行了其他4 种机器学习方法的实验,包含SVM、决策树、逻辑回归和随机森林,4 种方法的实现也基于Scikit-Learn Python 库。决策树和随机森林使用默认参数,逻辑回归的惩罚参数为“L2”。在SVM方法中的“linear”内核功能的性能是4个内核功能中的最佳的内核参数(linear,poly,rbf,sigmoid)。
2.2 基于原始信号的深度学习
原始信号的长度为5 000,需要很深的卷积网络来处理,而当网络层数较深时会出现梯度消失的情况。ResNet 网络通过引入残差单元能很好地克服深度网络中梯度消失现象。残差单元原理是通过在输入和输出之间建立了一条直接的关联通道,从而使得强大的有参层集中学习输入和输出之间的残差。基于ResNet的时间序列分类架构长期以来一直被成功应用于各种大规模研究[27-28]。
本项目中采用的ResNet模型结构如图3所示,其中包含3个残差单元(Residual Unit),设x为残差单元中的网络输入,经过残差单元处理后输出为y,则残差单元结构的计算过程为:
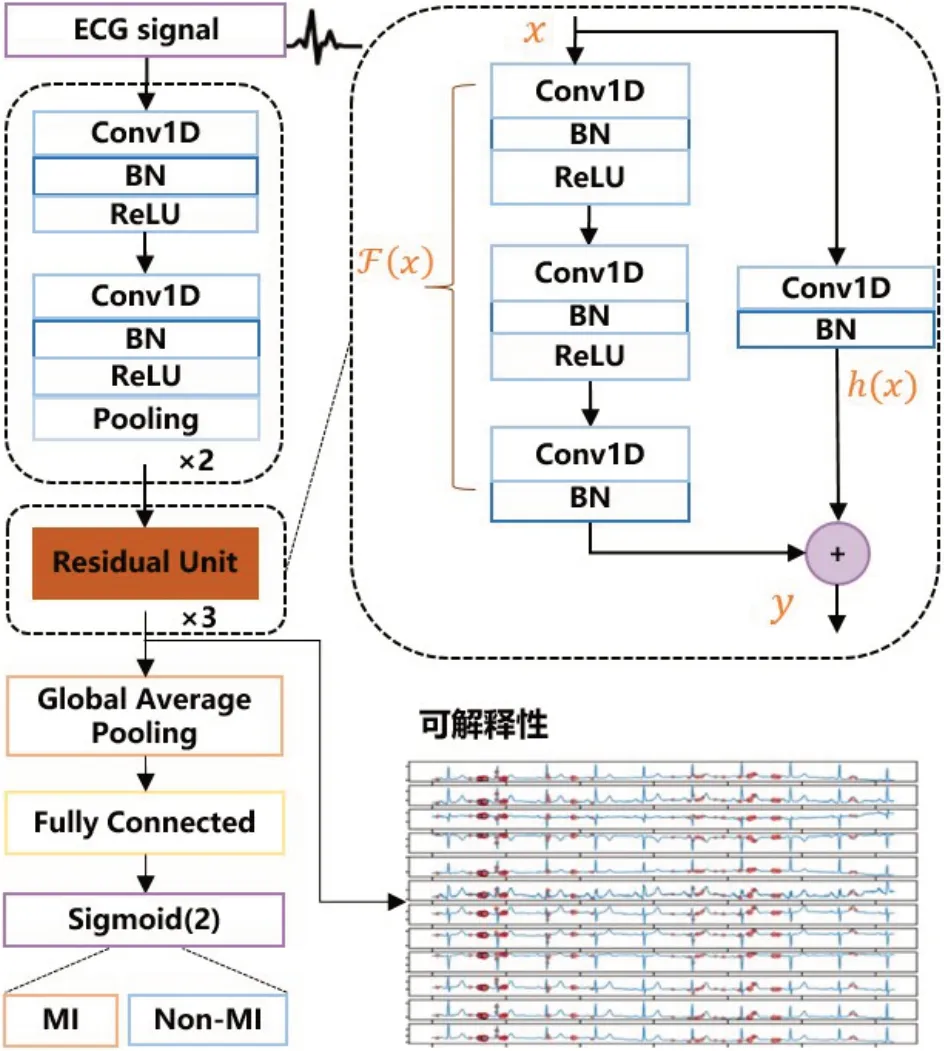
图3 ResNet网络结构及可解释性位置Figure 3 ResNet network structure and interpretability position
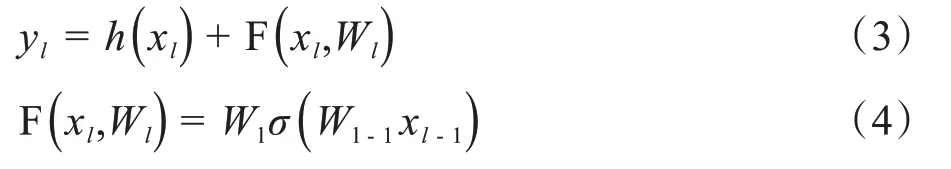
其中,σ表示Relu 激活函数,=λlxl,为1*1 卷积操作,用于升维。则残差网络中任意单元的输出yL可表示为:
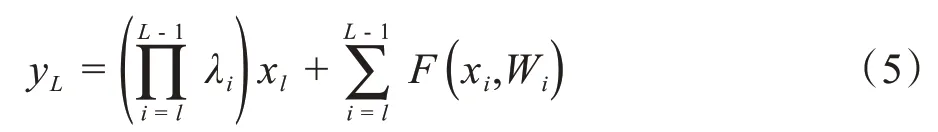
而普通卷积网络的输出为:

设网络损失函数为ε,可以得到残差单元中梯度:
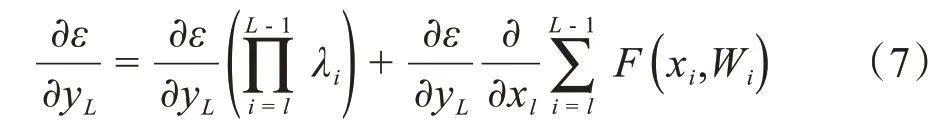
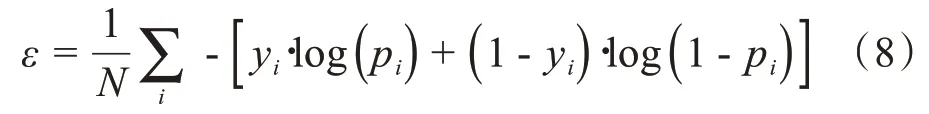
其中,yi表示样本i的label,pi表示样本i预测为正类的概率。作为对比,还实现了4 个已有的网络模型(CNN,LSTM,Inception,Attention[29])。
2.3 模型评价指标
分类模型评价指标先用通常的ROC 曲线下面积(Area Under Curve,AUC)和F1指标。F1的定义如下公式所示:


其中,TP 为真正的阳性样本的数量,TN 是真正的阴性样本的数量,FP 是假阳性样本的数量,FN 是假阴性样本的数量。
2.4 实验的实施
在实验执行过程中,为了得到更加稳定的结果,对数据集进行了5 次交叉验证。数据集被分为5 个部分(折叠),每次用4个折叠训练1个模型,剩下1个折叠用于测试。将5 折交叉验证的结果取平均值作为最终结果。所有的分类方法均使用相同的数据集划分结果,以消除数据集对不同方法的影响。
3 结果与分析
3.1 分类精度评估
表2显示基于临床特征和原始ECG信号的分类结果。在机器学习方法中,XGBoost的分类AUC为0.690,是最优的,对应的F1准确性为0.766。随机森林和逻辑回归结果分别为0.68和0.66,比XGBoost低但差距不大。决策树和SVM方法的结果仅仅为0.543和0.566,差距明显。主要原因是实验数据集样本来源广泛,不同样本间的特征差异大且异常值较多(图1)。与临床特征的结果相比,基于原始ECG信号的分类结果得到了明显改善,ResNet模型的AUC为0.728,比XGBoost提升了近4%,说明深度网络自动提取特征比手动提取的特征包含更多的信息。Attention模型达到0.717,最差的CNN结果也达到0.713。说明在相同的输入下,不同的网络模型之间差别在2%之内,表明深度模型的稳定性强于机器学习方法。
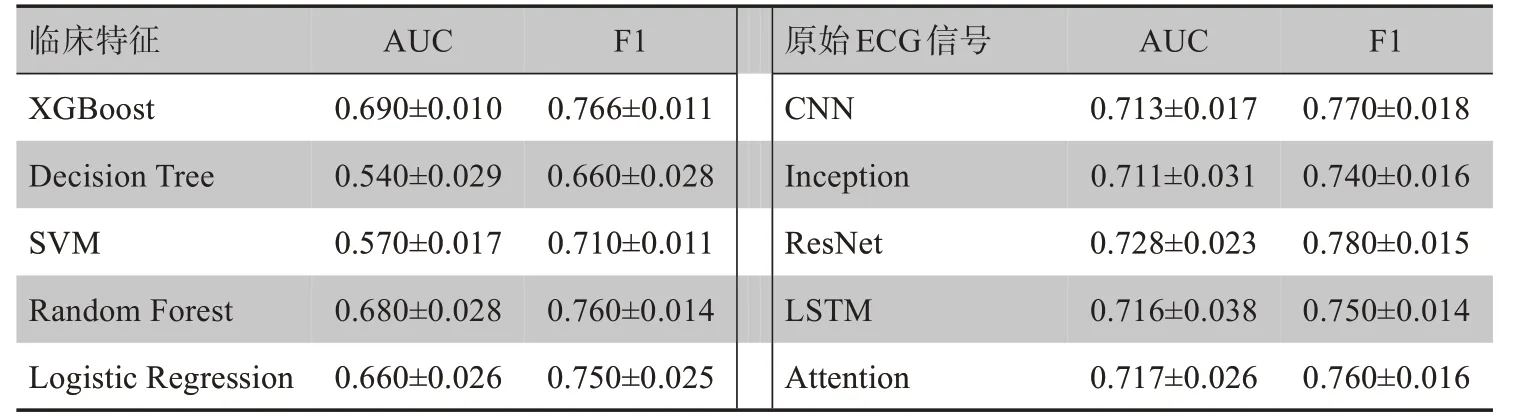
表2 基于ECG的分类AUC和F1结果Table 2 AUC and F1 results of ECG-based classification
3.2 按性别与年龄分类结果
不同性别和年龄段的分类结果如图4所示,从图中可知男性的分类结果比女性高4%,在55~70年龄段的结果比40~55年龄段高6%。这个结果与“心肌梗死易发于年龄大的男性中”是相符合的。
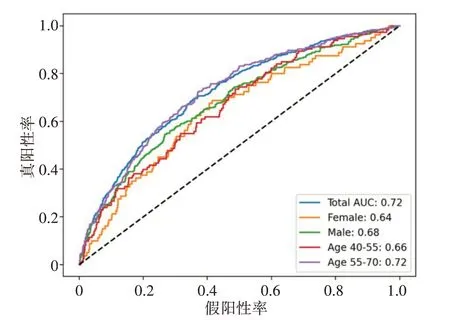
图4 不同性别和年龄段的分类结果Figure 4 Classification results by gender and age groups
3.3 重要的临床特征
机器学习方法的优点是具有很好的解释性,XGBoost 方法会对每个临床特征值计算1 个权重,图5 显示XGBoost 方法中前20 特征的权重图。前3 个重要特征是lead11 的inte_ST、lead5 的inteT_mean 和lead5 的inteR_mean,表明S 波和T 波的相关值在MI的分类结果中的权重更大。
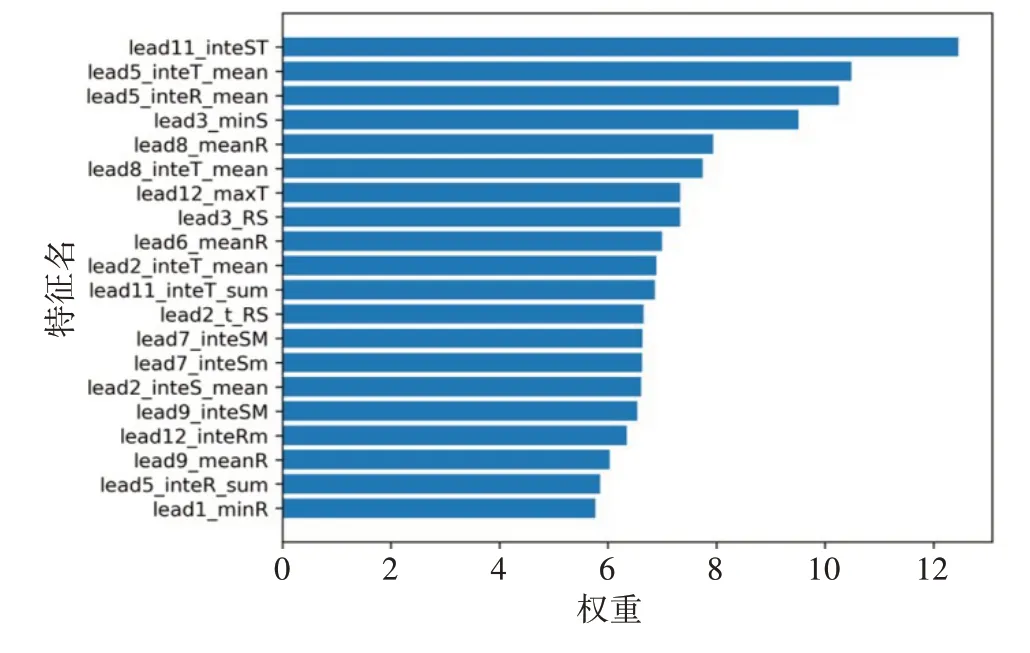
图5 前20个特征的权重值Figure 5 Weights of the top 20 features
3.4 深度学习的可解释性
与传统的机器学习算法相比,数据驱动的深度学习算法通常被视为黑匣子,限制了它们在临床环境中的接受度。近年来,通过临床医生对涉及医学背景的分类决策特征的调整,人工智能的可解释性得到了广泛的发展并具有良好的前景。一些研究表明,基于深度学习尤其是心电数据对时间序列的解释是可行的[30]。本研究使用梯度加权类激活映射(Grad-CAM)方法来可视化模型认为输入数据中哪些区域对预测结果更重要[31]。如图6所示,红色圆点代表ResNet网络模型的关注点,在左边MI 样本中用红虚线框中的区域与非MI样本上的区域有着显著不同。框中的部分是心跳出现ST 抬升现象,这是临床上对MI 诊断的一个很重要的依据。在右图的非MI样本中,网络关注点零散,没有集中关注在ST波上。
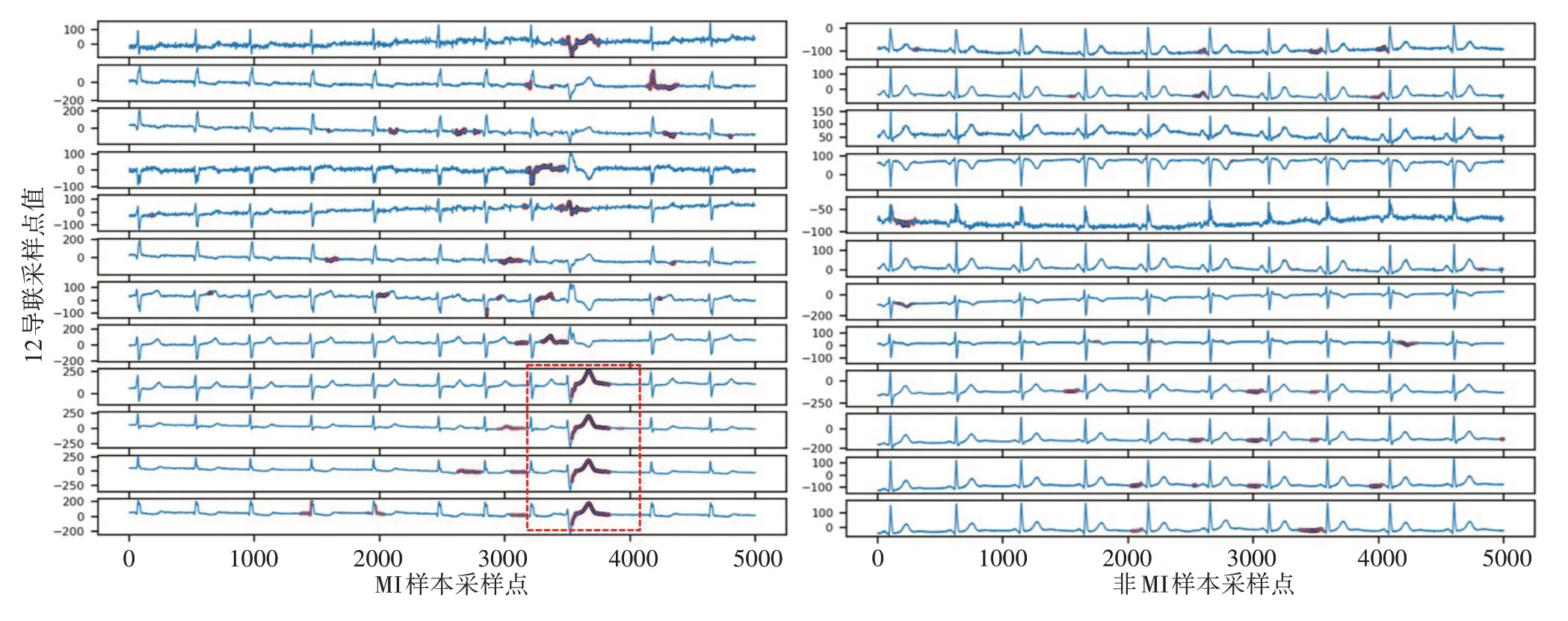
图6 ResNet模型在MI与非MI的关注点Figure 6 Focus of ResNet model in MI and non-MI
4 总结
本项研究首次在英国生物信息平台UK Biobank上提出了MI 的基准预测结果,涵盖了基于临床特征的机器学习方法和基于ECG 信号的深度学习方法。结果表明基于临床特征的预测证明提取的临床特征具有一定的价值,但还是会遗漏一些信息,效果并不好。使用深度网络模型直接在原始ECG 信号上自动提取信息效果更佳,预测的AUC 为0.728,得到了质的提升,在非侵入的ECG 上能得到0.728 的预测是有价值的。随后,对XGBoost 和ResNet 方法的结果进行了可解释性分析,发现ST 波与MI 的相关性更密切。
目前本研究仅限于UK Biobank 数据集的MI 疾病上,虽然深度网络的解释性能捕捉到MI与非MI的区别,但缺乏量化标准。另外,从提取的特征中发现这些样本的值波动很大,如果能有更专业的医生对样本进行初步筛选,结果有可能会提高。
