利用深度学习开展偏振雷达定量降水估测研究*
2022-09-06皇甫江胡志群郑佳锋朱永杰尹晓燕左园园
皇甫江 胡志群 郑佳锋 朱永杰 尹晓燕 左园园
1.成都信息工程大学大气科学学院,成都,610225
2.中国气象科学研究院灾害天气国家重点实验室,北京,100081
3.中国气象局大气探测重点开放实验室,成都,610225
1.School of Atmospheric Sciences,Chengdu University of Information Technology,Chengdu 610225,China
2.Chinese Academy of Meteorological Sciences,Beijing 100081,China
3.Key Laboratory of Atmosphere Sounding,CMA,Chengdu 610225,China
1 引 言
强降水导致的暴雨洪涝等自然灾害对农业、水资源、经济、民生等方面造成重大影响,获得准确的降水信息对于保障民生、规划水资源的利用、稳定农作物产量至关重要。天气雷达作为主动遥感观测仪器可以进行定量降水估测(QPE),同时天气雷达资料具有高时、空分辨率的特点,而雨量计可以精准测定单点降雨量,通过大量研究证实,将雷达观测资料与雨量计观测资料结合进行降水估测会有更好的效果(林炳干等,1997)。中国新一代天气雷达(CINRAD)获取的目标物强度和相位信息中,利用Z-R关系进行定量降水估测,概率配对法(张培昌等,1992a)、变分校准法(张培昌等,1992b)、平均场偏差订正法(Wilson,et al,1979)、卡尔曼滤波校准法(Fulton,et al,1998)、克里金法(黄小玉等,2009)和最优插值法(李建通等,1996)均是利用单偏振量进行降水估测,其只建立反射率因子(ZH)和降水强度(R)的关系,而降水粒子的信息仅通过反射率因子获取并不能得到很好的效果。双偏振雷达同时拥有两个通道,包含水平和垂直方向,还可以发射和接收相互正交的极化电磁波,可以获得两通道的强度差(即差分反射率因子ZDR)、相关系数(即 ρHV) 和相位差(即差分传播相移 ΦDP),也能计算出差传播相移率(KDP),ZDR和KDP可以更多地反映粒子的信息,如粒子直径和数密度等(张培昌,1988)。Seliga 等(1976)首先提出了双偏振雷达的设想,中国在20 世纪80 年代开始进行双偏振雷达的相关研究,刘黎平等(1996)利用平凉C 波段双偏振雷达的层状云、对流云观测资料,用ZDR分析并解释层状云、对流云内粒子相态及尺度的空间分布规律,为当时人工影响天气作业指挥及效果检验提供了新的手段。目前中国正在对雷达进行升级改造,未来新一代天气雷达均会升级为双偏振体制,预计在2025 年升级改造包括S 和C 波段在内的100 部雷达。中国还在加快布设更多的自动气象站。Wang 等(2012)提出了实时调整Z-R关系式的方案,同时也表明高密度的自动雨量站观测数据可以提供降水估测精度。除了用ZH进行降水估测,ZDR和KDP的特性也适合用于降水估测。Gorgucci等(2000)利用KDP进行降水估测,Lee 等(2006)在分析偏振雷达降雨测量时发现,使用ZH和ZDR的效果要优于传统的Z-R关系式,胡志群等(2008)在利用X 波段双偏振雷达进行降水估测时提出了ZHKDP-R综合估测方法,估测结果与实际观测更加吻合。Bringi 等(2002)利用了ZH、ZDR和KDP三个参数对雨滴谱分布进行分析。在进行降水估测时,含有雷达偏振参量的公式的效果均比Z-R关系的效果好。自动雨量站的优势是观测精度高,能够优化雷达降水估测效果。雷达降水平均场偏差订正方法通过比较雨量站观测降水和雷达估测降水的差值或比值调整Z-R关系的系数,从而降低了雷达降水估测的均方根误差(Chumchean,et al,2006)。张扬(2019)利用双偏振雷达组网与自动雨量站联合进行定量降水估测,初步建立了适合广州S 波段业务双偏振雷达组网估测降水的算法,使得雷达组网估测降水的效果得到了进一步改善。
深度学习是新兴的人工智能研究领域,旨在研究如何从数据中自动地提取多层特征表示,其核心思想是通过数据驱动的方式,采用一系列的非线性变换从原始数据中提取由低层到高层、由具体到抽象、由一般到特定语义的特征。深度学习依赖于大数据,而气象数据正好符合其特点,近些年来,气象学者也尝试用深度学习方法进行气象领域的研究(Haberlie,et al,2019;Reichstein,et al,2019; 任萍等,2020;蒋薇等,2021;黄兴友等,2021)。Yin 等(2021)提出了一种基于深度学习算法的回波填充网络,对雷达遮挡区域进行填充,效果得到了提升。邵月红等(2009)利用BP 神经网络模型估测临沂地区降雨量并与改进后的Z-R关系式进行对比,结果表明BP 神经网络的估测精度明显优于Z-R关系式。郑玉等(2020)基于循环神经网络模型提出了可以有效进行雷达估测强降水的方法,在大于30 mm/h 的强降水下,循环神经网络(RNN)估测降水比Z-R关系的均方根误差和中位绝对误差均有降低,效果有了很大提升。郭瀚阳等(2019)利用改进的循环神经网络算法预报未来1 h 内的逐6 min雷达回波演变特征,较传统外推算法在强对流回波临近预报准确率上有明显提高。本研究以广州S 波段双偏振雷达(CINRAD/SAD)为例,利用低仰角的3 个偏振参量(ZH、ZDR和KDP)的不同组合作为输入因子,利用深度学习算法构建单参量、三参量定量降水估测网络架构,并根据KDP与降水强度大致为线性关系以及小雨偏振量往往误差较大的特点,分别训练出小雨、大雨、总体模型。
2 训练数据集构建
2.1 数据来源
文中采用的雷达探测数据来源于偏振升级后的广州新一代天气雷达(CINRAD/SAD),该雷达采用双发双收的观测模式,因此,广州雷达不仅可以获取水平反射率因子(ZH)、径向速度(Vr)、速度谱宽(SW)3 个常规参量,还可以获取差分反射率因子(ZDR)、差分传播相移( ΦDP)、差分传播相移率(KDP)等偏振参量。广州雷达采用的体扫模式为VCP21,每6 min 完成1 次体扫,共观测9 个仰角层,最低仰角为0.5°,距离分辨率250 m,方位分辨率1°,最大探测距离460 km(陈超等,2019)。文中使用的雷达资料包括2018 年部分时段(9 月5—8 日、12 月8—10 日、12 月30—31 日)、2019 年4 月1 日—9 月31 日、2020 年5 月1 日—9 月30 日,共计82892个体扫资料。
雨量数据来源于中国气象局气象信息中心数据 库, 时 段 为2018 年9 月1 日 至2020 年9 月30 日,包括国家级和区域级的自动雨量站,时间分辨率为1 min,共计538560 个分钟降水数据。
2.2 数据预处理
相对于网络架构而言,数据质量才是深度学习模型好坏的关键。因此,构建训练数据集时首先需要对雷达数据和雨量数据进行预处理。
2.2.1 雷达数据
对于雷达数据,首先利用中国气象科学研究院灾害天气国家重点实验室雷达探测团队研发的质量控制软件去除孤立点杂波、地物杂波等非气象回波(胡志群等,2008;郑佳锋等,2016;王超等,2019),输出雨量计上空0.5°仰角相邻径向及距离库3×3个库的ZH、ZDR和KDP,如图1。
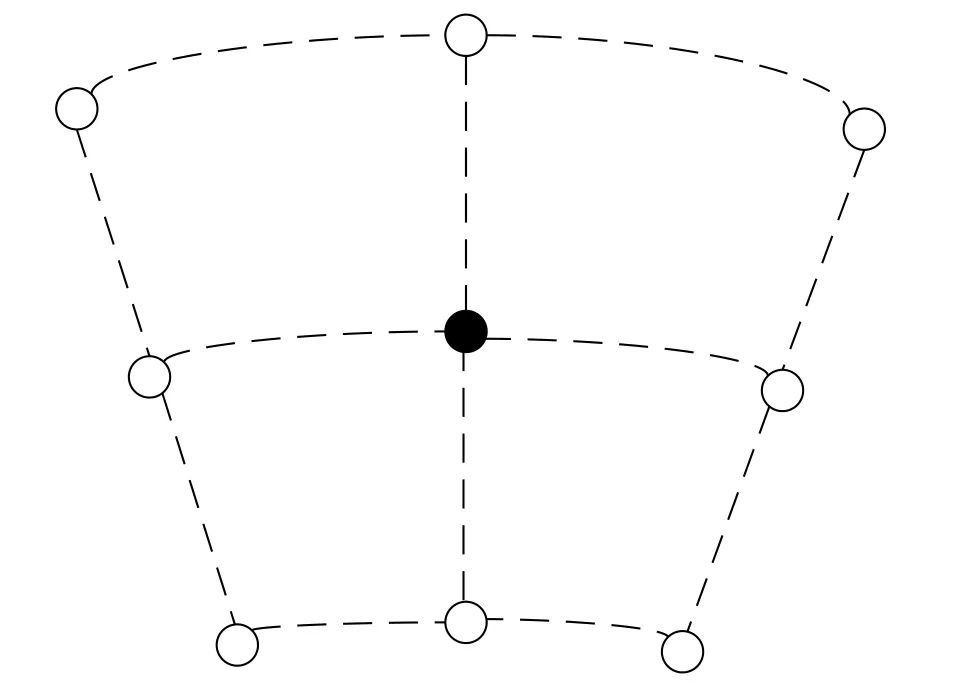
图1 雨量计上空雷达0.5°仰角3×3 个距离库数据示意Fig.1 Schematic diagram of the 0.5° elevation angle 3×3 distance radar data above the rain gauge
剔除掉1 h 内不满足10 个体扫的数据,由于本研究主要讨论降雨情况下的估测,因此将反射率因子小于10 dBz 的数据也进行了剔除,偏振参量的无效值、缺测值、小于0 的值均设置为0,技术路线如图2。

图2 双偏振雷达资料处理技术路线Fig.2 Flowchart of dual polarization radar data preprocessing
2.2.2 雨量数据
雨量数据选取了广州雷达100 km 范围内的1109 个站点,站点分布如图3,自动雨量站在观测过程中部分地区因各种原因无法得到准确数据,如缺测等,根据数据提供的质量控制码对雨量数据进行质量控制。受周边地理环境的影响,广州雷达低仰角波束存在一定遮挡,将雷达63.51°—65.30°方向上的雨量站点剔除。为与雷达时间分辨率保持一致,将分钟雨量合计为6 min,转换为小时雨强(R),将雨强为0 的数据剔除;将雨强大于250 mm/h视为错误数据,并进行剔除。雨量数据预处理技术路线如图4。
图3 自动雨量站分布 (图中间的黑色三角为雷达位置,黑色圆点为雷达探测100 km 范围内雨量站)Fig.3 Distribution of automatic rainfall stations ( The black triangles in the center show the radar position,and the black dots indicate rainfall stations within 100 km of radar detection)
图4 雨量数据预处理技术路线Fig.4 Flowchart of rainfall data preprocessing
2.2.3 雷达数据与雨量数据匹配
对预处理后的雷达数据和雨量数据按照时间相同、空间对应的原则进行匹配,将1 h 内的10 组(雨量-雷达)数据对中雨量=0 大于5 组、ZDR=0 大于3 组、KDP=0 大于3 组的数据进一步剔除。
2.3 构建训练数据集
考虑到模型的通用性,采用min—max 标准化方法再对雷达、雨量数据进行标准化,将数据映射到[0,1]区间,即:
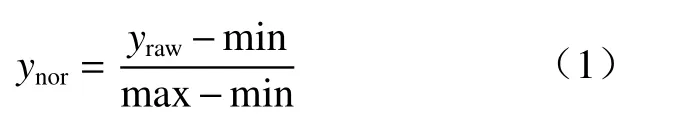
式中,ynor为标准化后的参量,yraw表示偏振参量原始观测值,max、min 分别为参量的最大、最小值,其设置见表1。考虑到KDP与降水强度几乎是线性关系,用KDP=0.5°/km 为阈值,对大于0.5(以下简称大雨模型)、小于或等于0.5(以下简称小雨模型)分别建模,并与不区分雨强的总体模型(以下简称总模型)做对比。

表1 各参数标准化的最大、最小值设置Table 1 Maximum and minimum values of standardized parameters
根据输入因子,分别采用ZH、KDP单参量, 以及同时采用ZH、ZDR、KDP三个参量,分别构建定量降水估测的深度学习网络框架:Z-Rnet、KDP-Rnet、Pol-Rnet。
经筛选后剩余1163380 组有效数据,随机挑选其中75%用作训练集,25%用作测试集,训练集数据中再随机挑选25%作为验证集,每种模型的训练数据量见表2。

表2 各模型训练集数据量Table 2 The amount in the training dataset of each model
3 定量降水估测架构设计
3.1 单参量网络架构
深度学习网络架构包括输入层、隐藏层和输出层,每一层之间的输出和输入实际上是一个线性关系z=Σwixi+b,再通过一个激活函数非线性化,并解决隐藏层数过多可能导致的梯度消失或者梯度爆炸问题。本研究采用的激活函数为线性整流函数ReLu,其公式为
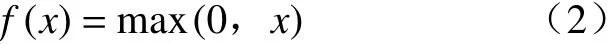
对于单参量网络架构,本研究采用3 个线性层组成的隐藏层,第一、二个隐藏层之后,增加一个ReLu 函数的激活层,单参量建模流程如图5。
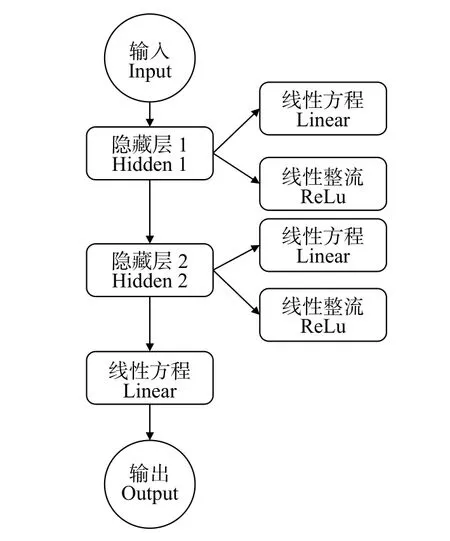
图5 单参量网络架构流程Fig.5 Flowchart of single-moment network
3.2 多参量网络架构
对于多参量网络架构,采用3 个隐藏层和9 个线性层,将每个参量分别训练,输出64 个节点,然后将其合并为一个一维向量,然后再增加一个线性层输出结果,多参量建模流程如图6。
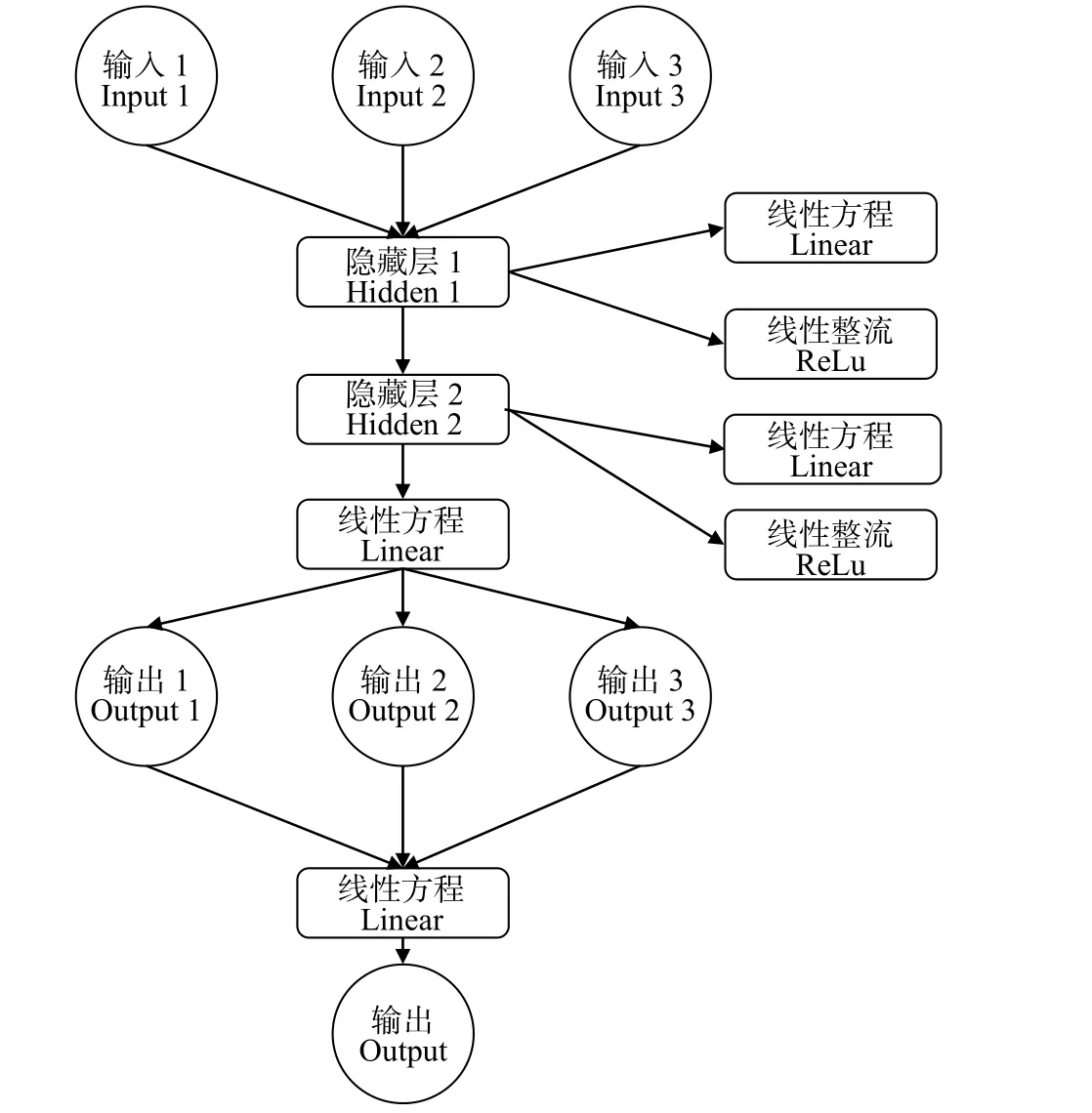
图6 多参量网络架构流程Fig.6 Flowchart of three-moment network
4 模型训练
4.1 超参设置
需要调整的超参包括隐藏层节点数、迭代次数、学习率等,经不断调整测试,获得较好拟合效果的超参设置为:隐藏层节点分别为16、32、64,优化器选用了Adam 梯度下降优化器,学习率为0.001,迭代次数为200。迭代开始时,损失函数值迅速减小,模型快速收敛,随着迭代次数增加模型收敛速度逐步变缓。每次迭代结束,将训练集重新打乱,重新提取75%数据用于训练,25%用于验证,从而有效提高模型的泛化能力。为了提高训练效率,采用早停机制,如果连续迭代20 次验证集的损失函数没有提升,就认为模型已经无法进一步提升拟合效果,停止训练,并输出模型训练结果。
4.2 自定义损失函数
定量降水估测为回归问题,网络架构最后输出的节点数为1,即雨量估测值。在深度学习模型训练过程中,回归问题一般采用均方误差损失函数(MSE,mean squared error)进行评估,其公式如下
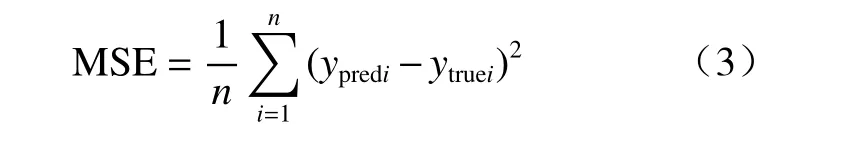
式中,ypredi为估测降水值,ytruei为观测降水值,n为样本个数。实际降雨过程中,降水为偏态分布,雨强越强,出现的概率越低,如果采用均方误差作为损失函数,模型训练过程中小雨拟合效果较好,但是对造成灾害的强降水会有明显的低估,因此文中对损失函数进行了优化,针对广东降雨的实际情况,将降雨强度分成了不同区间,对不同区间采取不同权重,自定义损失函数如下
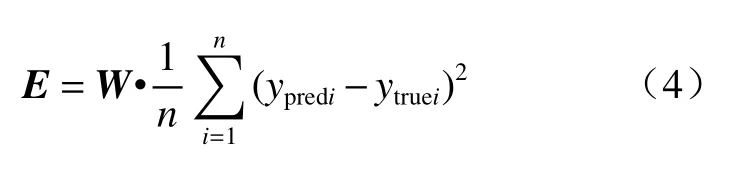
式中,E为损失值,W为自定义权重系数向量。对于不同模型,设置的权重向量见表3。首先将各区间权重数值均设置为1,每训练一次,统计测试集不同区间真实值与估测值的误差大小,增加误差大的区间的权重,经过多次建模测试,最后得出效果最好的权重向量。

表3 自定义损失函数权重系数Table 3 Weight coefficients of self-defined loss function
4.3 评价指标
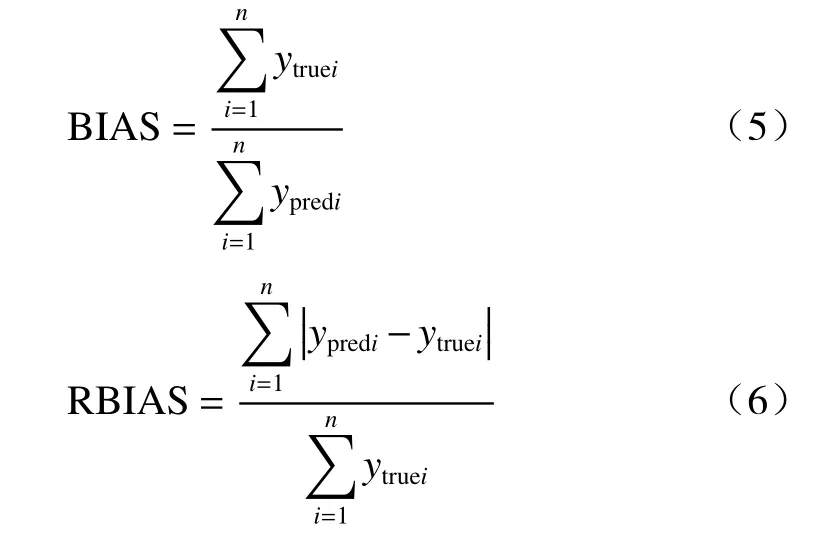
模型采用的评价指标主要有5 个,分别为比率偏差(BIAS)、相对偏差(RBIAS)、均方根误差(RMSE)、平均绝对误差(MAE)、平均相对误差(MRE),公式如下
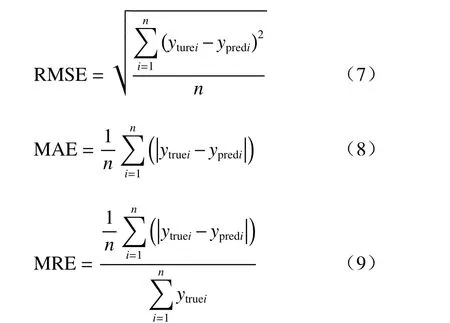
4.4 模型训练及测试
用训练集将模型训练完成后,用测试集测试模型的定量降水估测效果。图7 展示了采用均方误差作为损失函数,单参量KDP、ZH和3 参量(ZH-ZDRKDP)网络架构,大雨、小雨和总模型测试集散点,总体来说,各个模型在雨强5—25 mm/h 区间估测表现良好,但是对于超过50 mm/h 和小于2 mm/h的估测表现一般,尤其是对于雨强超过80 mm/h 的估测往往偏小。表4 给出了采用均方误差作为损失函数的评价指标效果,在大雨模型中,采用多参量进行定量降水估测的效果是最好的,在各个评价指标中均为最低,说明在对大雨的定量降水估测时,加入偏振量KDP和ZDR会增强对大雨估测的效果。在小雨模型中,采用单参量ZH进行降水估测效果最好,说明对小雨进行估测时,只用ZH会更加准确,而偏振量因子KDP和ZDR对于小雨的估测效果提升并不明显。对于总模型来说,估测效果介于大雨、小雨模型之间,说明本研究利用KDP进行大雨和小雨的区分具有积极的意义。同时在大雨模型中,MRE 效果最好,说明对大雨的估测能力更好。
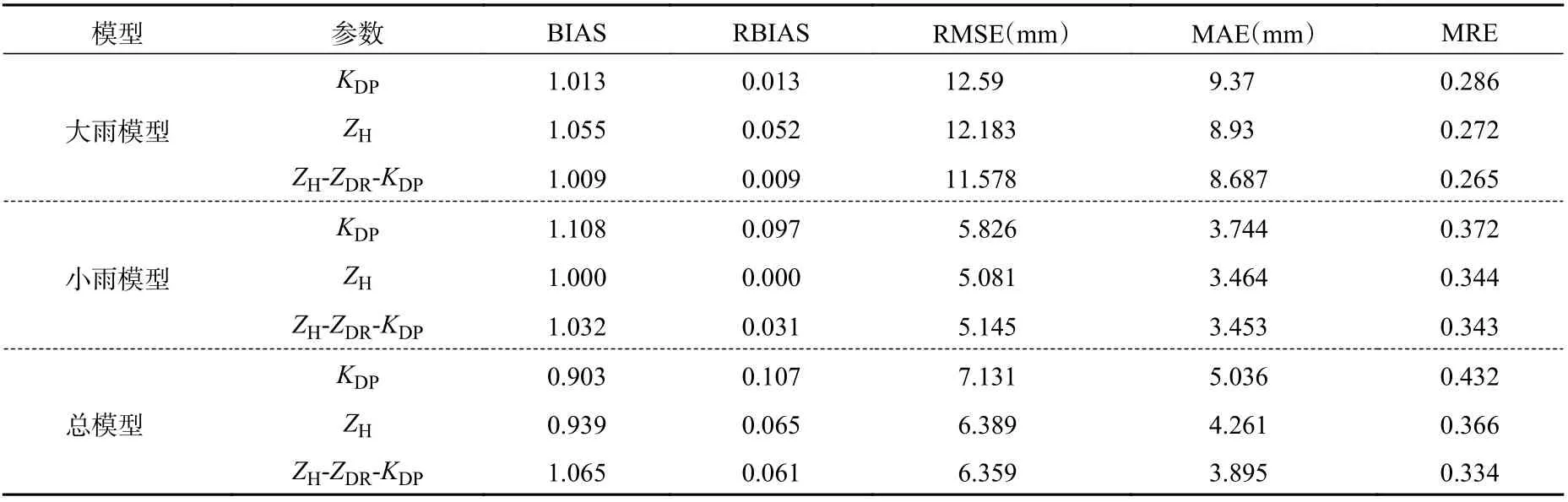
表4 采用均方误差作为损失函数的评估结果Table 4 Model evaluation results by using MSE as the loss function
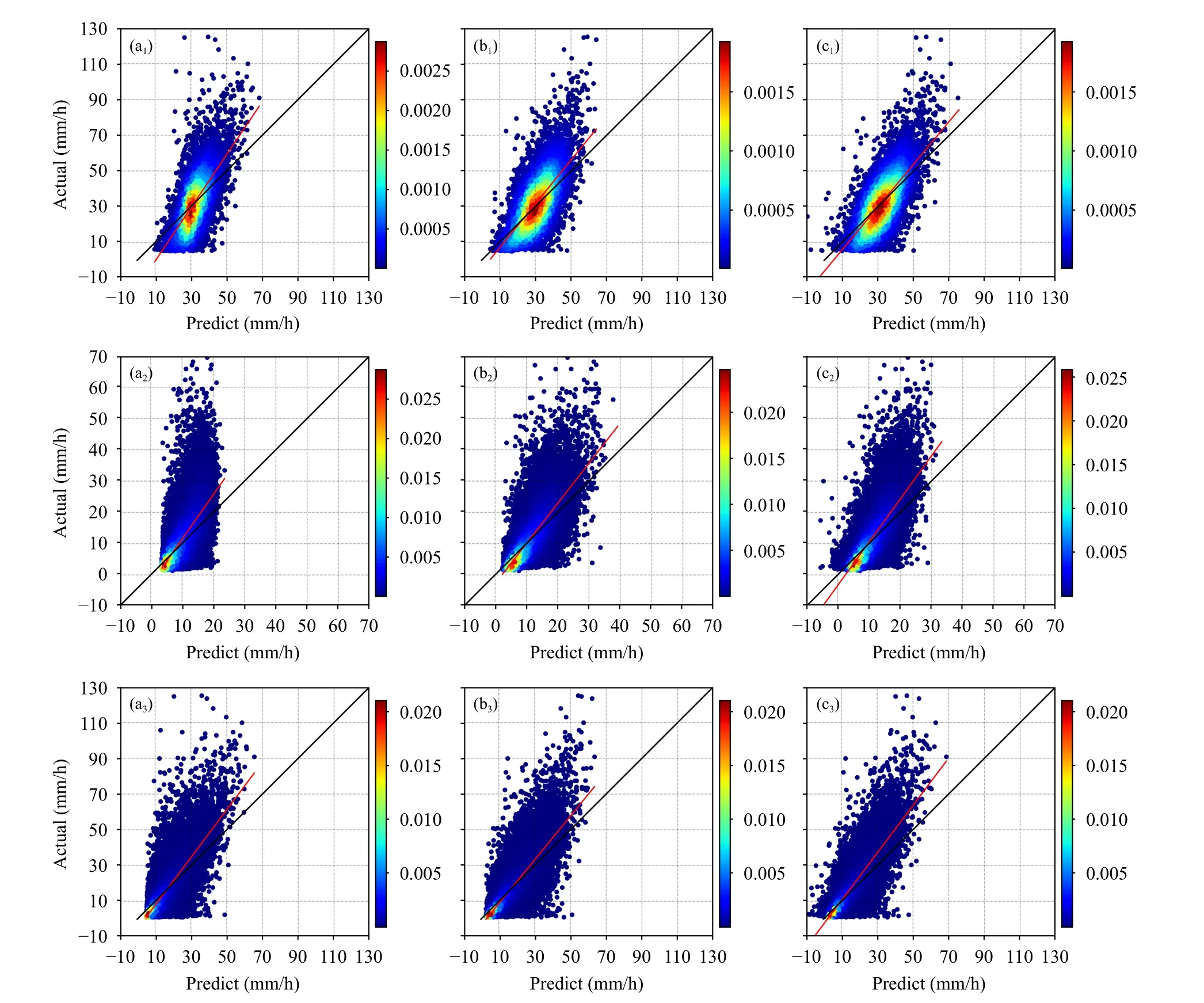
图7 采用均方误差作为损失函数时,大雨模型(a1、b1、c1)、小雨模型(a2、b2、c2)和总模型(a3、b3、c3)中分别采用KDP(a1、a2、a3)、ZH (b1、b2、b3) 和ZH-ZDR-KDP (c1、c2、c3) 作为输入因子的散点 (色阶为解释方差)Fig.7 Scatter plots of heavy rain (a1,b1,c1),light rain (a2,b2,c2),all rain (a3,b3,c3) data models fitted with traditional MSE as loss function and with KDP (a1,a2,a3),ZH (b1,b2,b3) and ZH-ZDR-KDP (c1,c2,c3) as input factors,respectively (The color code indicates the explanatory variance)
虽然采用均方误差作为损失函数的模型表现还好,但是对于强降水的估测值往往比真实值要小,文中提出采用自定义损失函数来改进各模型的效果,通过对各个区间估测值和真实值的差进行分析,对不同区间给予不同权重,重新采用自定义损失函数对模型进行训练。图8 展示了采用自定义损失函数时大雨模型、小雨模型和总模型拟合结果散点,总体来说,在对强降水和部分弱降水增加适当的权重后,效果较采用均方误差作为损失函数的模型有了很大的提升,对强降水和部分弱降水的估测效果有了明显改善。表5 给出了采用自定义损失函数作为损失函数的评价指标效果,可以看到在给予权重进行训练后,除单参量KDP的效果一般,各模型的相对偏差均降到了5%以内,其他评价指标也都有了不同程度的改善。
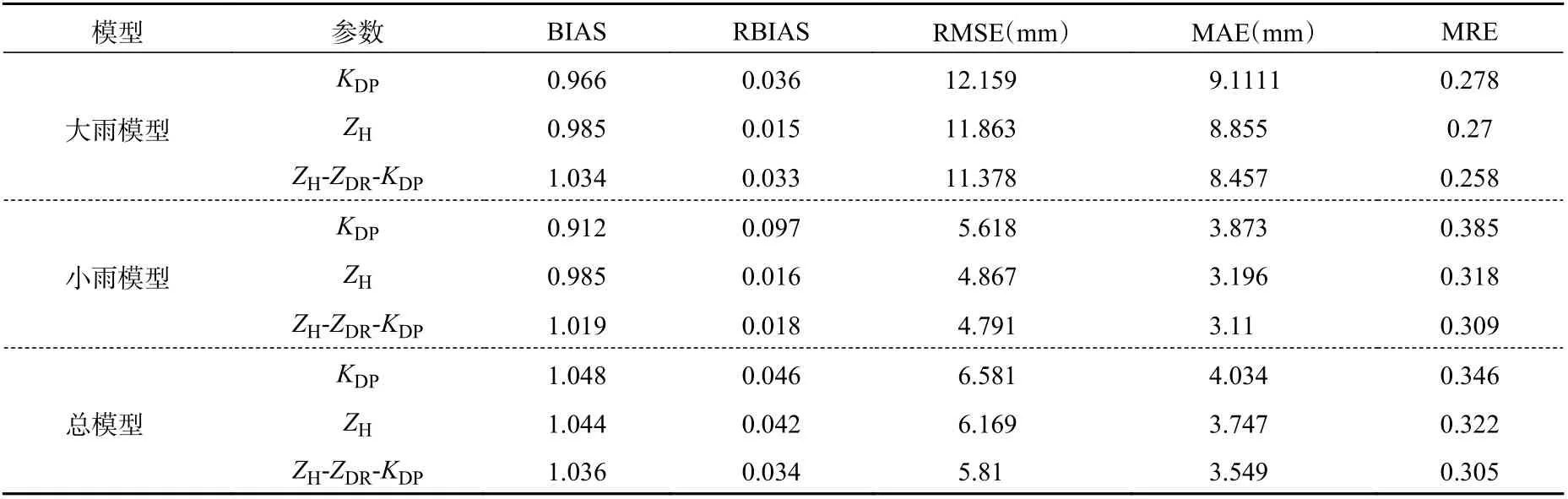
表5 采用自定义损失函数的评估结果Table 5 Models evaluation results by using the self-defined loss function

图8 同图7,但为采用自定义损失函数Fig.8 Same as Fig.7 but with self-defined loss function
通过对以均方误差作为损失函数的模型和自定义损失函数模型的分析发现,针对区间进行优化并给予模型不同权重的效果最好,较常规的均方误差模型有了很大的改善。同时,采用自定义损失函数的模型将ZH-ZDR-KDP作为输入因子的估测效果均为最好,为后续偏振雷达定量降水估测模型通用化和业务化提供了新的方向。
5 模型应用
选取广州CINRAD/SAD 雷达积层混合云为主、对流云为主和层状云为主的3 个个例数据进一步检验模型效果,以0.5°仰角的单参量、3 参量网络架构,对利用均方误差作为损失函数和自定义损失函数进行定量降水估测做模型效果评估。
5.1 积层混合云为主的个例
本次过程选取时间为2019 年6 月11 日00—23 时(世界时,下同),主要受到切变线和急流的影响,最大雨强为86.5 mm/h,平均雨强为10.68 mm/h,共240 个体扫数据,72960 个分钟雨量,其中,雨强大于5 mm/h 的有38700 个,占总数的53.04%。
图9 是2019 年6 月11 日12 时36 分 的 雷 达 回波。如图所示,该个例以积层混合云为主,回波强度主要在20—45 dBz,部分强度可以达到55 dBz。表6、7 分别是模型采用均方误差作为损失函数和自定义损失函数的效果。从定量角度分析,在以均方误差作为损失函数的模型中,大雨模型、小雨模型的相对偏差均控制在8%以内,效果较好。在自定义损失函数模型中,其效果整体比均方误差作为损失函数的效果好,均方根误差、平均绝对误差和平均相对误差的效果均有所提升。整体上看,将模型区分大、小雨的效果也比不区分的效果好,尤其是大雨的效果有明显的改善。
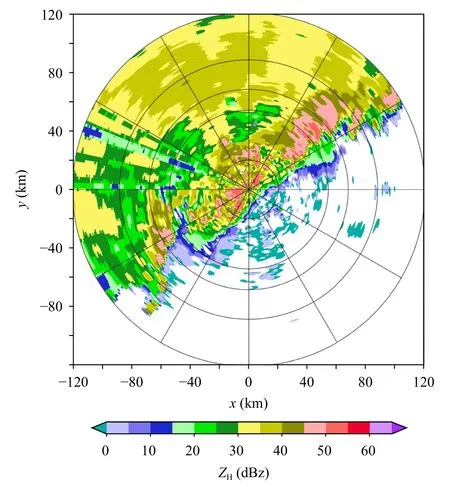
图9 2019 年6 月11 日12 时36 分0.5°仰角雷达PPIFig.9 Radar PPI of 0.5° elevation at 12:36 UTC 11 June 2019
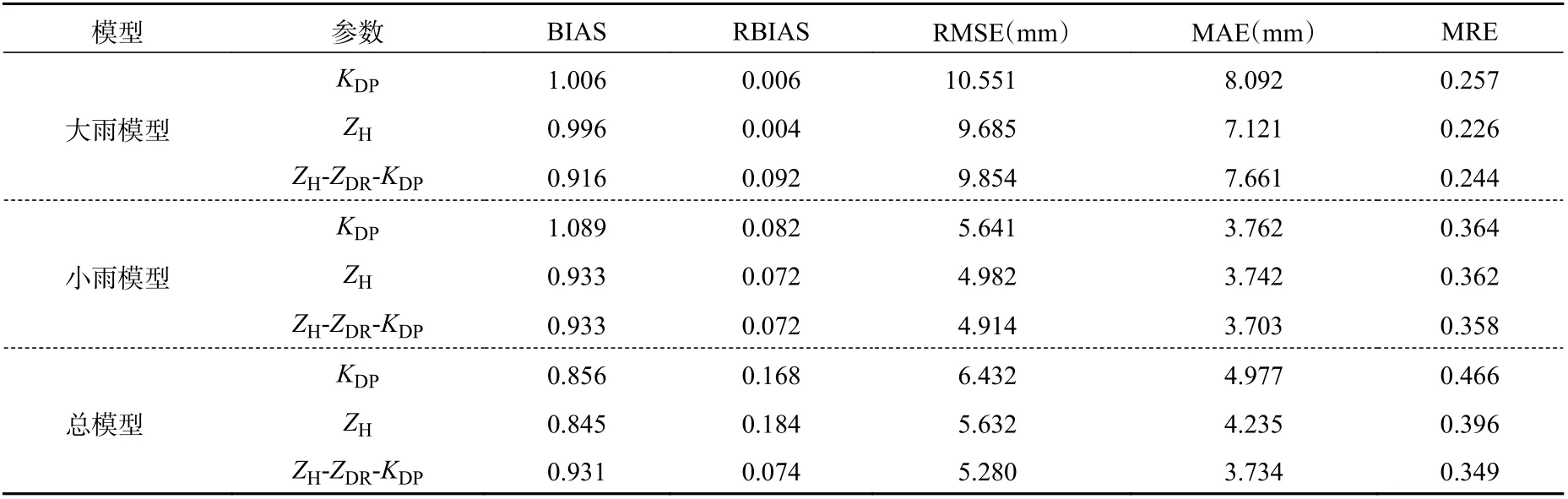
表6 采用均方误差作为损失函数的评估结果Table 6 Evaluation results by using MSE as the loss function
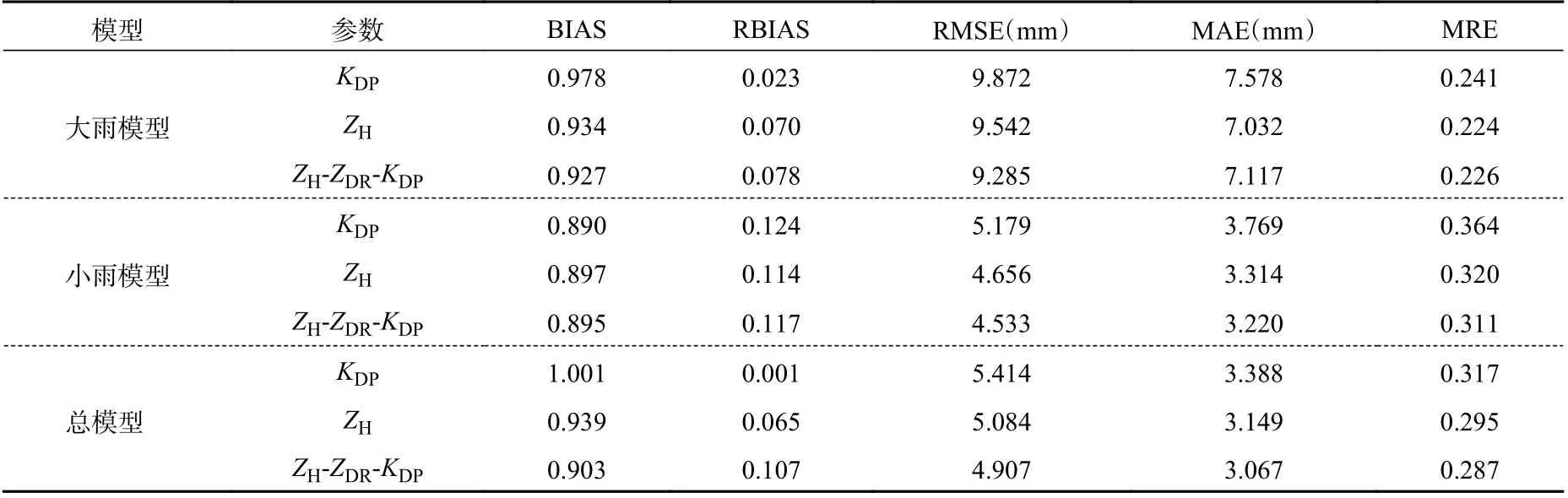
表7 采用自定义损失函数的评估结果Table 7 Evaluation results by using self-defined loss function
5.2 对流云为主的个例
本次过程选取时间为2020 年6 月9 日00—23 时,主要受到切变线的影响,最大雨强为79.0 mm/h,平均雨强为10.50 mm/h,使用240 个体扫数据,25740 个 分 钟 雨 量,其 中 雨 强 大 于5 mm/h 的 有13200 个,占总数的51.28%。
图10 是2020 年6 月9 日10 时48 分 的 雷 达 回波,该个例以对流云为主,在第二和第三象限均有较强的雷达回波,部分强度可以达到55 dBz。表8和9 分别是模型采用均方误差作为损失函数和自定义损失函数的结果。从定量角度分析,在以均方误差作为损失函数的模型中,采用ZH和参数ZH-ZDRKDP作为输入因子的效果要比KDP作为输入因子的效果好很多,说明对于强降水占比较高的天气,采用多参数降雨估测会比单参数有大的提升。在自定义损失函数模型中,其效果整体比均方误差作为损失函数的效果好,对于强降水的估测值与真实值也更为接近。整体上看,在强降水天气个例中,使用3 参量架构估测模型的效果最好。
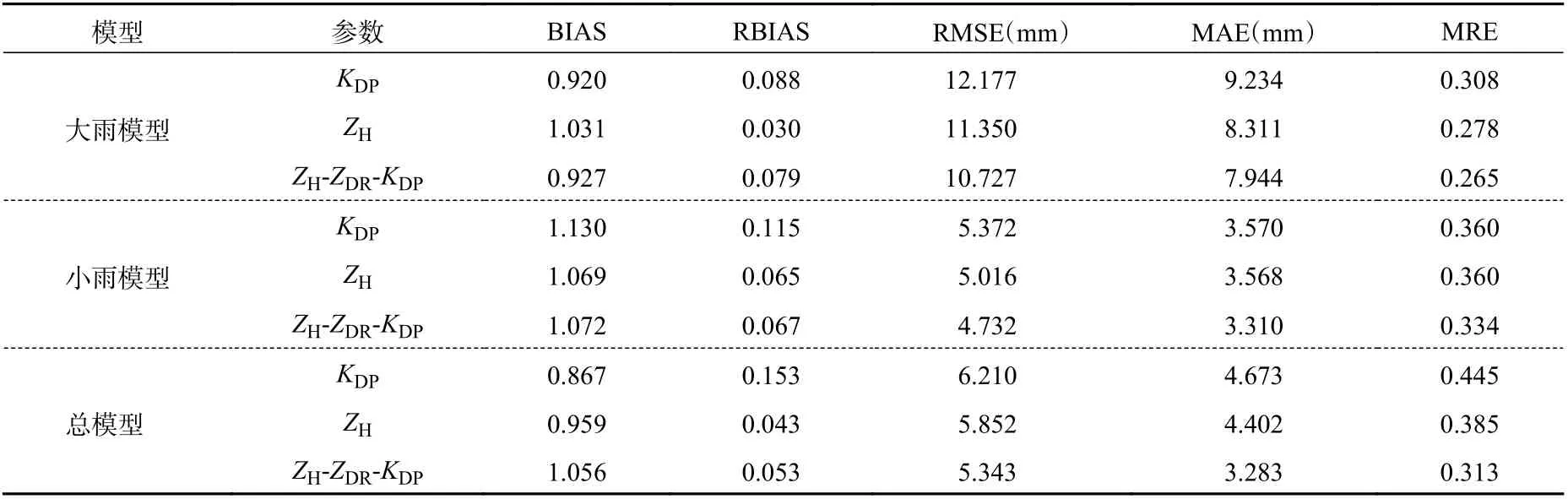
表8 采用均方误差作为损失函数的评估结果Table 8 Evaluation results by using MSE as the loss function
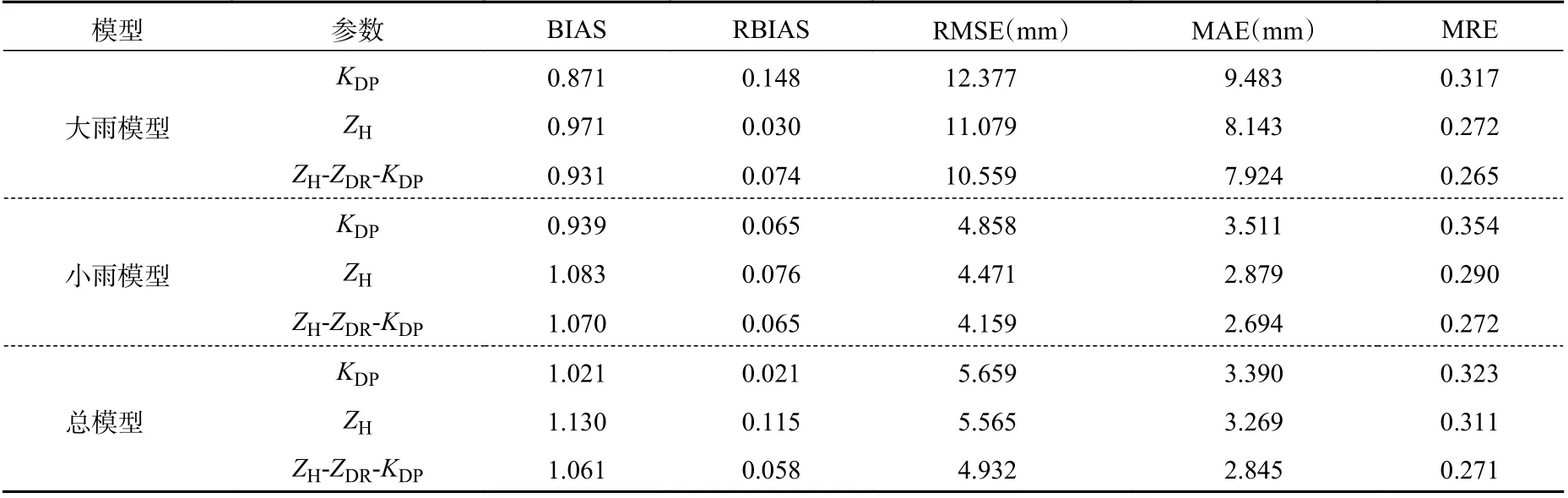
表9 采用自定义损失函数的评估结果Table 9 Evaluation results by using self-defined loss function
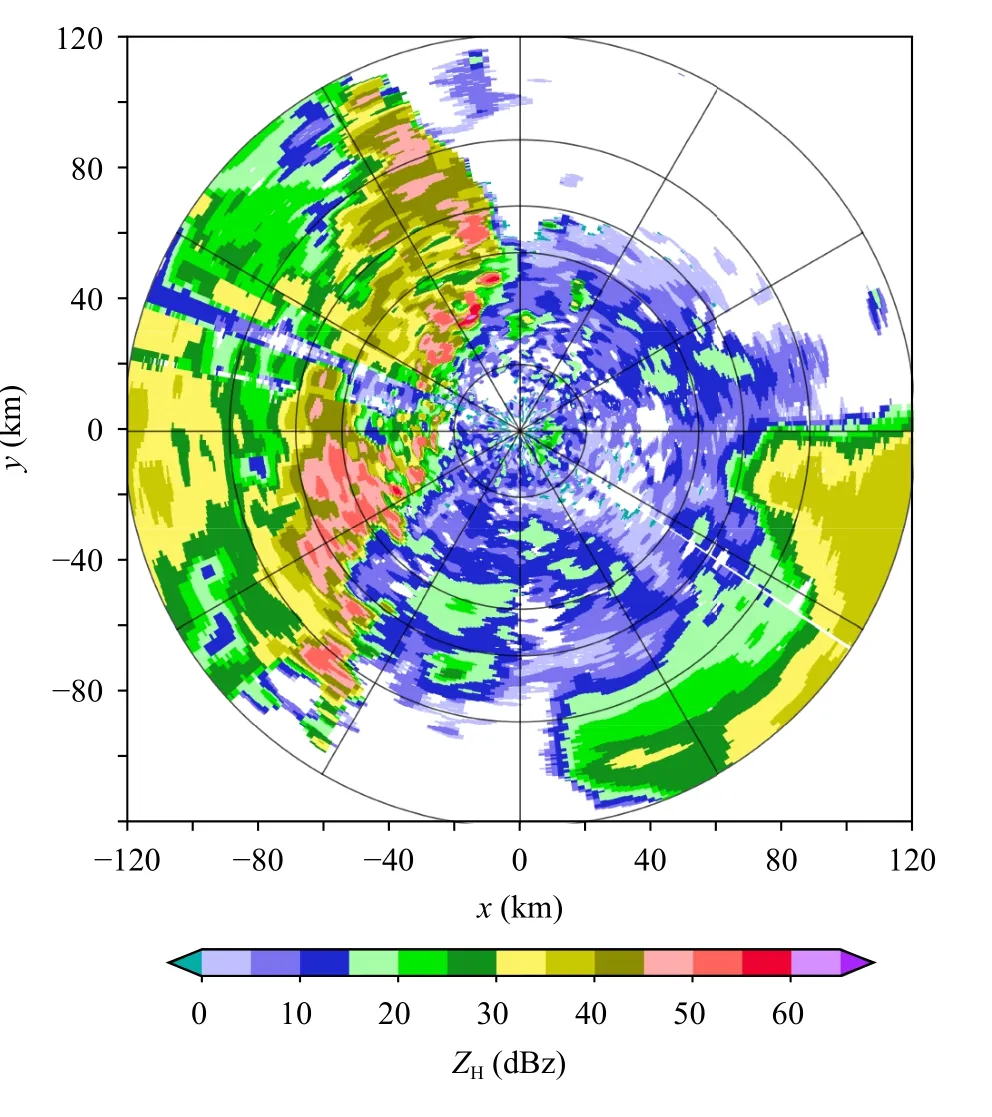
图10 2020 年6 月9 日10 时48 分0.5°仰角雷达PPIFig.10 Radar PPI of 0.5° elevation at 10:48 UTC 9 June 2020
5.3 层状云降水为主的个例
本次过程选取时间为2018 年9 月16 日00—23 时,主要受到台风“山竹”的影响,最大雨强为113.0 mm/h,平均雨强为10.58 mm/h,使用240 个体扫数据,40560 个分钟雨量,其中雨强大于5 mm/h的有20700 个,占总数的51.04%。
图11 是2018 年9 月16 日06 时30 分 的 雷 达回波,该个例以层状云降水为主,回波强度主要在15—35 dBz。表10 和11 分别是模型采用均方误差作为损失函数和自定义损失函数的效果。从定量角度分析,在以均方误差作为损失函数的模型中,区分大、小雨的模型采用不同因子效果不同:对于大雨模型,参数ZH-ZDR-KDP作为输入因子的效果最好,说明对强降水进行估测时,加入偏振因子ZDR和KDP会对效果有很大的提升;对于小雨模型,采用KDP作为输入因子的效果没有采用ZH作为输入因子的效果好,说明对于小雨进行估测时,ZH作为输入因子对小雨的估测效果更好。在自定义损失函数模型中,其均方根误差、平均绝对误差和平均相对误差的效果均有明显提升,其在雨强4—13 mm/h 的估测效果最好,说明对于以层状云降水为主的天气中估测效果较好。整体上看,在强降水占比不高的天气个例中,采用KDP作为输入因子的效果不理想,使用3 参量架构效果会有明显提升。
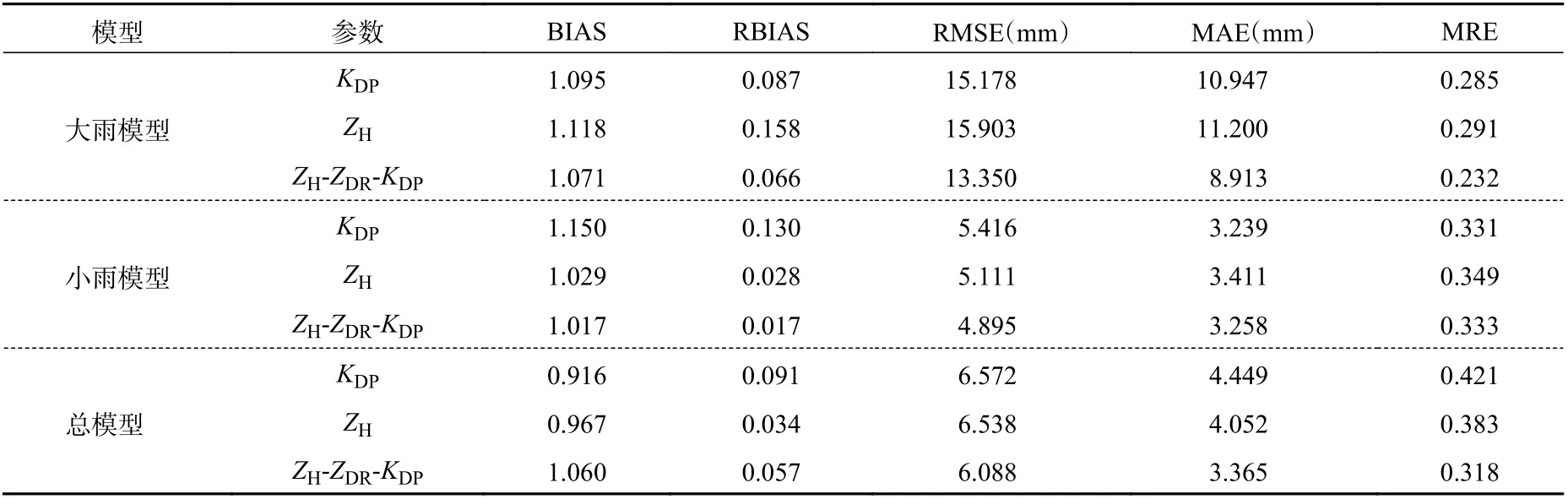
表10 采用均方误差作为损失函数的评估结果Table 10 Evaluation results by using MSE as the loss function
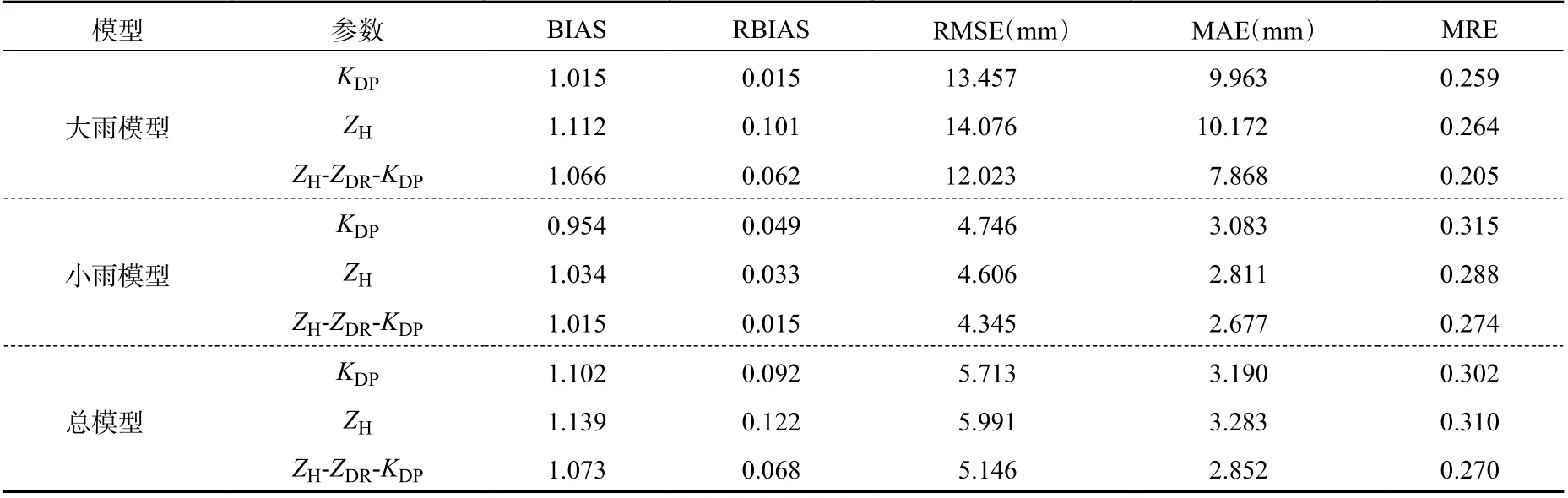
表11 采用自定义损失函数的评估结果Table 11 Evaluation results by using self-defined loss function
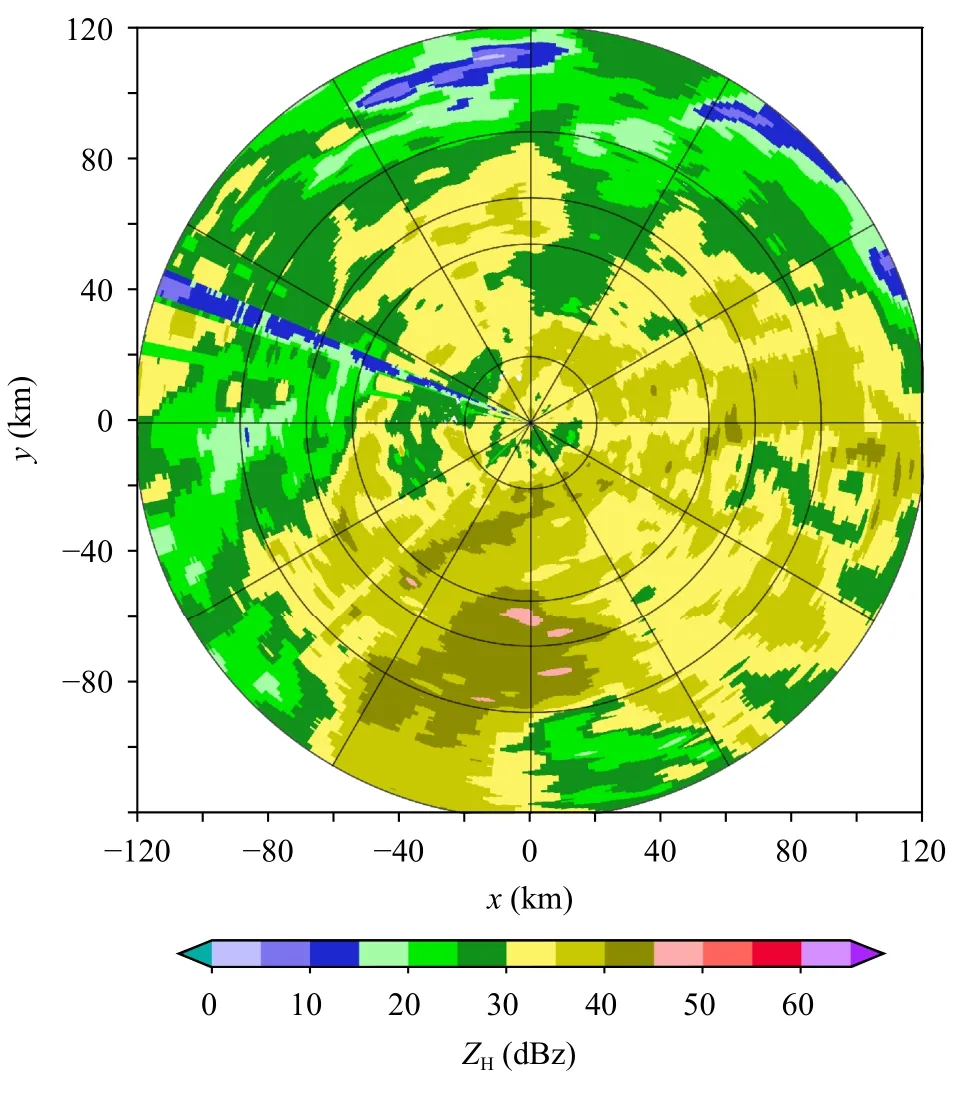
图11 2018 年9 月16 日06 时30 分0.5°仰角雷达回波PPIFig.11 Radar PPI of 0.5° elevation at 06:30 UTC 16 September 2018
6 讨 论
以广州S 波段双偏振雷达为例,构建了偏振雷达定量降水估测的单参量(Z-Rnet、KDP-Rnet)、3 参量网络架构(Pol-Rnet),并通过KDP阈值,分别训练大雨、小雨、总模型,同时提出了自定义损失函数增加强降水的权重,并采用比率偏差、相对偏差、均方根误差、平均绝对误差和平均相对误差作为评价指标,与采用均方误差作为损失函数进行对比,结果表明:
(1)利用深度学习开展定量降水估测有较好的估测效果。区分雨强大、小的模型要比不分雨强的模型效果好。单参量网络架构在使用ZH作为参数时,对小雨的估测效果比KDP好,3 参量网络架构对大雨模型的估测效果比单参量网络架构的效果好。
(2)通过对不同雨强区间给予不同的权重,提出自定义损失函数,其效果优于传统的均方误差作为损失函数的效果。
(3)深度学习主要是利用大数据进行建模,数据的质量至关重要,在建模过程中,文中对雷达数据和雨量数据分别进行了预处理,以降低数据误差对模型的影响。模型中优化器的选择、迭代次数的多少以及验证集的增加都加强了模型的可靠性。
(4)随着中国新一代天气雷达陆续完成偏振升级改造,基于偏振量的多参量模型较基于回波强度的单参量模型定量降水估测的效果有明显改进。
(5)对低仰角存在遮挡的区域,可以先对低层进行填补后再进行定量降雨估测(Yin,et al,2021),在近距离处也可以利用高仰角数据进行降雨估测。
(6)深度学习目前在各行各业呈爆发式发展,随着数据的增多以及更多更好的深度学习算法涌现,未来对模型架构进行优化,可进一步提升模型定量降水估测的能力。
