基于视频识别的飞行训练考核评估方法*
2022-09-06邢宝峻王卫星彭晓明
邢宝峻 殷 哲 王卫星 彭晓明
(空军预警学院 武汉 430019)
1 引言
近年来,随着军事科技的不断发展,越来越多的高技术装备列装部队,对部队训练考核评估手段提出了更高的要求。对于航空兵来说,随着实战化训练深入推进,传统的训练评估手段已无法满足实战化训练考核评估的要求,如何去精准的评估飞行员的训练水平、发现薄弱环节、针对性制定训练计划,成为提升航空兵部队实战化训练水平的关键。目前,世界各国主战飞机普遍装备了座舱视频记录设备,这类设备以视频形式准确记录飞行人员操纵飞机平台和火控、雷达、电子战等装备的流程、参数和效果,但目前主要依赖人工进行视频判读,存在关键事件检索困难、判读时间长、判读效率低等问题,对飞行人员的视力健康也有一定影响。针对这些问题,本文提出一种基于机载视频识别的飞行训练评估方法,通过对机载视频进行分析,自动识别战斗符号和参数,建立关键事件索引,高效量化评估空中格斗和对地打击效果,为航空兵部队提供一种新的广泛适用、高效便捷、客观量化的飞行训练考核评估手段。
目前对视频识别的研究一般分为基于图像的视频识别和基于时空信息的视频识别。基于图像的视频识别是针对视频中的每一帧画面进行识别,通过将视频信息转化为图像信息,尔后利用端到端的自然场景识别方法[1~3]进行识别,不考虑帧与帧之间的相互关系;而基于时空信息的视频识别则是以跟踪算法为基础,通过时空分析和多帧集成等方法从多个视频帧中获得时空信息并进行识别[4~6],来提高识别的准确性。本文主要采取基于图像的视频识别方法进行研究。
2 机载雷达视频的特点
一是较低的分辨率。机载雷达视频通常采用H.263编码模式,通过高精度运动补偿实现精确预测[7]。但是H.263模式设计是用于低码率视频编码,因此视频分辨率比较低。
二是视频图像呈现二值化。为了使飞行员在战斗中更容易在机载雷达视频中快速定位和锁定目标,视频画面以黑白两色为主,使整体视频画面呈现二值化。
三是视频中的字符或符号形式简单。为方便飞行员快速进行识别,战斗机机载雷达视频画面以几何图形、字符为主要形式,内容普遍简捷易懂。
3 基于机载视频识别的评估流程
基于机载雷达视频对飞行训练水平进行评估,首先要完成对机载雷达视频的识别。根据机载雷达视频特点,首先要对视频进行预处理,将视频转化为图像,同时提高图像质量,以提升识别准确率;其次,将得到的图像输入到CTPN网络中,进行文本检测;然后,利用光学字符识别网络完成对文本区域字符的识别,同时将文本输出。此外,根据机载雷达视频内容特点,将机载雷达视频区分为四个关键事件,建立关键事件索引,方便评估时进行检索。最后,根据得到的视频中关键数据和关键事件对飞行训练水平进行评估。
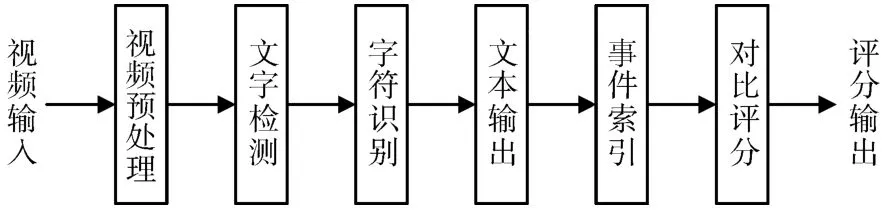
图1 基于视频识别的评估流程图
4 视频识别模型建立
4.1 视频预处理
为提升识别的速率和准确率,首先对机载雷达视频进行预处理。由于机载雷达视频中通常存在一定的冗余信息,为提升识别速率,对视频进行压缩,去除冗余信息。其次,将视频以帧为单位截取成图像,将视频信息转化为图像信息。然后通过图像拼接技术来对转化后的图像进行处理,从而提升识别效率。最后,由于拼接后的图像分辨率较低,为提升识别准确率,可利用形态学中图像的开运算,即先腐蚀后膨胀的操作,去除图像中的噪点,同时使字符表面更加平滑,便于进行分析与识别。
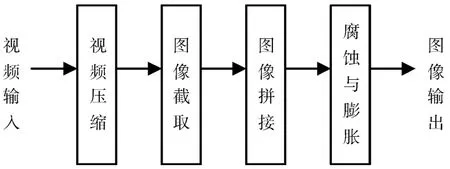
图2 预处理流程图
4.2 文本的检测
CTPN[8](Connectionist Text Proposal Network,连接文本提议网络)是在ECCV在2016年提出的一种基于深度学习的文字检测算法。CTPN结合了卷积神经网络(CNN)与长短时记忆神经网络(LSTM),可以有效地检测出复杂场景情况下的水平分布的字符[9]。CTPN创新性地提出了vertical anchor,运用垂直锚的回归机制,把文本检测任务转化为一系列小规模文本框检测。同时,CTPN还引入了BLSTM(双向长短时记忆神经网络),BLSTM可用于处理和预测序列数据[10],与CNN(卷积神经网络)结合,能够根据前后anchor的序列来提取字符间的排列关系特征,找到文本与文本之间的联系,最终用文本线构造法将各个anchor连接起来,得到文本行,以提升文本检测效果。此外,针对文本检测中文本边缘容易因评分过低而被丢弃的问题,CTPN提出了利用边界细化来提升文本框边界的预测精准度的方法,极大提升了文本检测的精度。
4.3OCR识别
战斗机机载雷达视频识别主要由Tesseract-OCR进行。Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,由惠普实验室在1985年~1995年间开发[11]。Tesseract-OCR属开源系统,且支持调用自定义字符库进行识别,它目前被公认为是最好和最准确的开源OCR系统。
Tesseract-OCR图像识别体系结构如图所示。
对于输入的图像首先进行页面布局分析,提取出文本区域,之后利用识别引擎分析得到Blob区域,然后通过对区域中相邻字符之间的垂直重叠关系可得到文本行,通过检测字符之间的水平关系可以得到字符间隔,通过字符间隔划分文本行可以得到单词。经过自适应分类器两次分析识别后对图像中的模糊区域进行改进,对作为备选分割点的字体形状的几何顶点进行分割,然后根据识别置信度对字符进行识别。如果失败,则默认字符已损坏并且不完整,那么该字符将被修复。然后利用A*算法搜索最优字符组合,将识别结果输出到文本中。
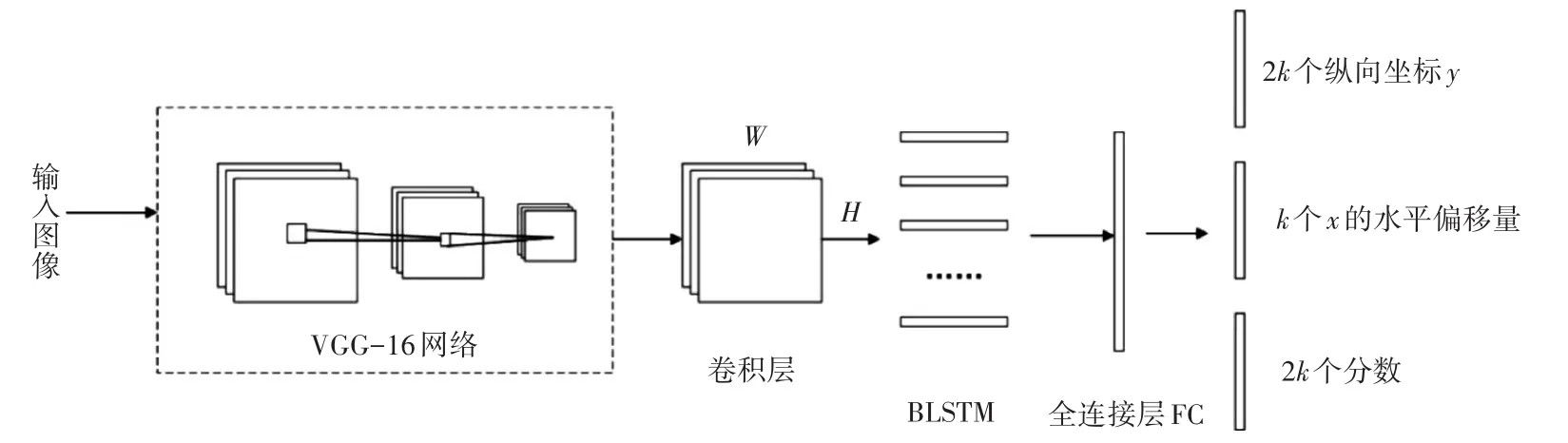
图3 CTPN架构图

图4 Tesseract的架构[12]
4.4 识别结果优化与提高
虽然Tesseract-OCR提供了相应的字符库以满足字符识别的需要,但发现直接调用字符库进行识别的精度达不到要求,这将影响相关数据的分析效果。由于Tesseract-OCR支持调用自定义字符库进行识别,且其自适应分类器具有“学习能力”,因此可以将首先分析满足条件的单词作为训练样本,以提高后续字符识别的准确性。因此,可以通过训练字符库来提高Tesseract-OCR字符识别的准确性,并提高其将图像转换为文本的能力。具体方法如下:
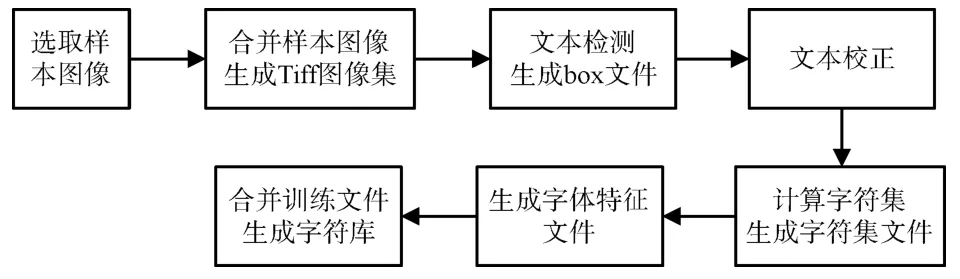
图5 Tesseract-OCR训练字符过程
字符库的训练主要通过jTessBoxEditor进行,最终形成traineddata数据包[13]。通过对比,调用训练的字符库进行识别,准确率明显提升。通过三段机载雷达视频进行识别,对比原视频与识别结果,识别的准确率达到86.25%,且通过不断地学习,准确率会不断提升。
5 基于机载视频的评估
通过机载雷达视频识别模型可以对机载雷达视频进行识别,得出相关数据信息,并以文本的形式输出,文本中包含雷达参数设置、目标搜索、目标截获、导弹发射等数据,将方本输入评估系统,根据雷达的状态对数据进行分类。通过对影响作战效能的关键事件中的参数进行分析,并与标准状态进行对比,可以得出飞行员对雷达操作在各个状态下的操纵评分,从而评估出飞行员的雷达操纵水平。此外,在建立视频识别模型时,加入了关键事件的索引功能,通过对识别的字符与原视频中的内容进行关联,评估人员可以快速定位关键事件发生的时段,同时通过对关键参数出现的时长计算出关键事件发生时长,进而判断出飞行员对紧急情况的处置是否恰当、是否及时做出正确反应,正确评估飞行员的雷达操纵熟练度。
6 结语
本文通过建立机载雷达视频识别模型,实现了对机载雷达视频的自动识别,通过对机载视频进行分析,自动识别战斗符号和参数,建立关键事件索引,高效量化评估空中格斗和对地打击效果,进而评估飞行员的飞行训练情况,有利于发现飞行员在训练中的薄弱环节,完成飞行训练复盘和飞行训练效果评估的需要,从而提高航空兵实战化训练水平。该模型适用于所有装备座舱视频记录器的飞机,为航空兵部队提供一种新的广泛适用、高效便捷、客观量化的飞行训练考核评估手段。
